
前言
最近,Err0r师傅把他们新生赛的赛题源码甩给我,我直接点开ezphp,发现这题很巧妙,题目源码不长,并且很有意思!这里面涉及到的知识点在之前也是比较少接触到的。因此,这篇文章将会对这道题从解题再到原理剖析逐步深入。
解题尝试
首先,题目源码在网页中打开是这样的

当一个Web方向的CTFer初步审计完源代码后,一定会觉得,这道题怎么这么简单,不就传两个参数就能输出flag了嘛
所以,Web手在初步审计完这道题之后,就会毫不犹豫地打出自己的一个payload(包括我):
?username=admin&password=s3cctf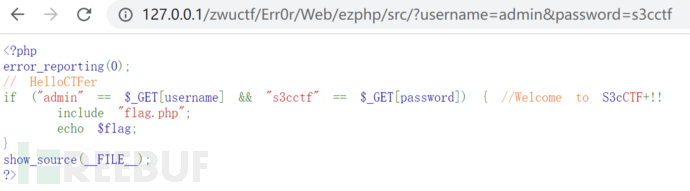
这个时候Web手就纳闷了,命名传参都是对的怎么不输出flag呢?
经过仔细地查看题目后就会发现,这源代码眼见不为实!

我明明只选中了s3c到pass的部分,怎么后面注释的部分也被选中了?
这里面可能会有一些蹊跷?
于是下定决心审计一下源代码
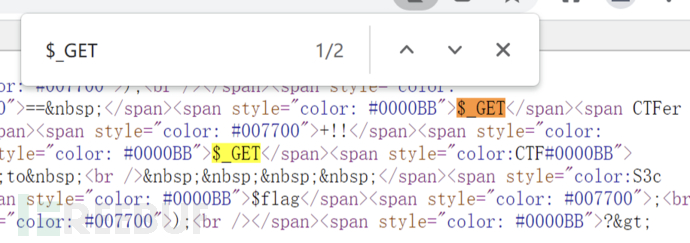
这一看,发现浏览器渲染的和源代码有出入。原本$_GET后面是[password],怎么这后面变成了CTF了呢?
审计源代码可能对解题也没有什么帮助,那么就把源码复制下来之后看看
复制下来之后打开,和浏览器解析的做一个比较
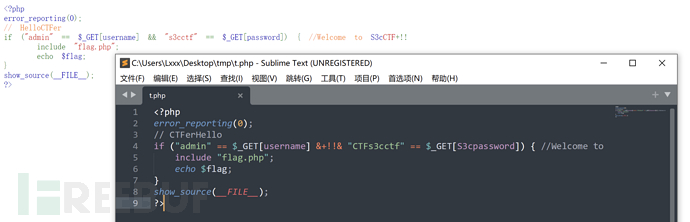
好家伙,这个时候浏览器解析的和用sublime打开的又不一样了
注释后面的CTF跑到了前面的s3cctf中去了,两个&&符号之间又多了奇奇怪怪的符号
因此浏览器和sublime都不能相信了,只能把文件用winhex打开才相对最可信
用winhex打开如下:

在这里我们就能看出变量名以及我们要传的参数值到底是什么了
其中需要的参数值如下:

也就是:
E2 80 AE E2 81 A6 43 54 46 E2 81 A9 E2 81 A6 73 33 63 63 74 66而变量名为:

E2 80 AE E2 81 A6 53 33 63 E2 81 A9 E2 81 A6 70 61 73 73 77 6F 72 64因此将其进行URL编码后传参:
?username=admin&%E2%80%AE%E2%81%A6%53%33%63%E2%81%A9%E2%81%A6%70%61%73%73%77%6F%72%64=%E2%80%AE%E2%81%A6%43%54%46%E2%81%A9%E2%81%A6%73%33%63%63%74%66即可得到flag:
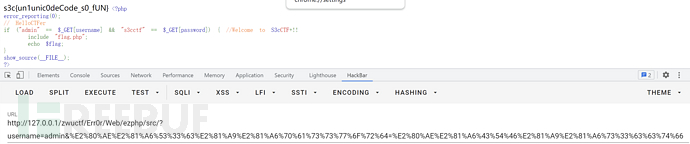
那么这道题究竟是怎么出的?原理是什么?接下来的篇幅将会进行分析!
原理剖析
在探究原理之前,我们先要有一双善于发现异常的眼睛
除了上面提到的一个异常(选中部分字符,其余未被选中的字符也被选中了),其实还有两个异常点。
第三行注释行的
HelloCTFer也有异常
我们将其进行选中

明明选中了//到CTF的部分,中间的Hello却没有被选中
我们再换个姿势进行选中

明明只选中了// He的部分,后面的CTFer却也被选中了
因此我们可以确定,在//后面一定有特殊的字符,使得原本应该在Hello前面的CTFer显示在了后面。
第四行最后的注释
S3cCTF颜色有问题
同样,如果仔细观察第四行的注释部分也会发现显示有点问题
这里的代码都是通过show_source函数进行打印的,而show_source函数在高亮源代码的时候,其代码颜色是按照php.ini中的设置来的。

也就是说,在注释后面的蓝色S3c本身应该属于前面password中的内容,而后面的CTF同样也应该是属于前面s3cctf中的内容
那么究竟是哪些神秘的字符导致这样的现象呢?
同样我们还是打开winhex
我们先查看比较短的// HelloCTFer注释行,对其进行分析。
![]()
内容如下:
2F 2F 20 E2 80 AE E2 81 A6 43 54 46 65 72 E2 81 A9 E2 81 A6 48 65 6C 6C 6F我们将其稍作拼接,将可见的ASCII码字符拼接在一起
拼接之后的内容如下:
2F2F20 E280AEE281A6 4354466572 E281A9E281A6 48656C6C6F稍作分析,对应的内容就是这样:
![]()
我们再对特殊字符进行分析,发现这个特殊字符应该是三个字节三个字节分开的
所以这里面一共出现了三组三个字节的编码分别是:E280AE、E281A6、E281A9
接下来对这三个特殊字符进行分析:
E280AE
对于这个特殊字符,它是Unicode编码U+202E转UTF-8对应的十六进制编码
它的名字叫做从右往左强制符
在unicode-table.com网站中对其介绍如下:

它的作用就是:根据内存顺序从右至左显示字符

我们可以写一个Python小脚本,来看看这个字符是怎么颠覆我们的认知的。
if__name__== "__main__":
print("Hello"+u"\u202e"+"World")
输出结果如下:
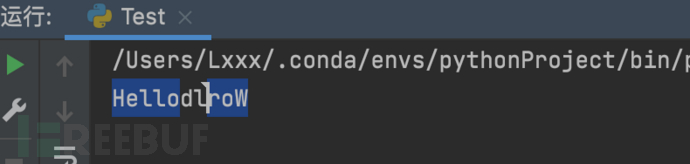
可以看到,后面的World变成了dlroW,并且当我们选中的H到r字符时,后面的oW却被选中了
E281A6
对于这个特殊字符,它的Unicode编号为:U+2066
外网上对这个字符作用描述是:

说人话就是:这之间的字符从左到右显示,不影响waiwei字符
E281A9
这个字符的Unicode编号为:U+2069
它的作用其实就是:作为RLI、LRI、FSi翻转结束的标识
![]()
这个时候我们再把上面的HelloCTFer拿出来进行分析:
我们就可以知道那段注释行的原理
原理就如下图所示
![]()
浏览器进行解析的时候,自然是按照上方十六进制的顺序进行解析,但是解析并不代表着输出,浏览器的输出结果需要根据底层字符的含义进行输出,当浏览器看到E280AE时,就知道后面的字符需要从右到左显示,而解析到E281A6时,浏览器就会知道将后面的字符从左往右输出,也就是CTFer输出结果仍然为CTFer而不是reFTC。当浏览器按照这样的规则把Hello解析完成之后,便会根据E280AE的从右往左输出的原则,将CTFer与Hello两个交换顺序,最终我们在浏览器中看到的结果便是HelloCTFer。
即使输出的结果是HelloCTFer,符合我们的认知,但是当我们用鼠标进行拖动的时候,电脑还是会那么贴心的帮我们把特殊符号加上,导致我们拖动Hello的时候,CTFer也被选中了

参考资料
如有侵权请联系:admin#unsafe.sh