
此项目是本人团队参加全国大学生信息安全竞赛的作品,文章内容为作品报告中部分内容,若有不足还望各位大佬指出。
本项目源代码:https://github.com/mrnuclear8/SecStudent
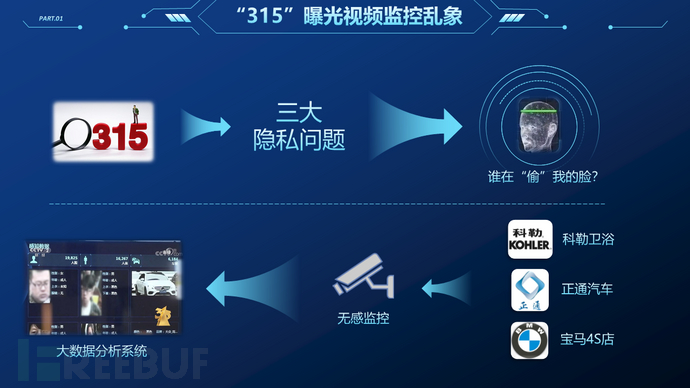
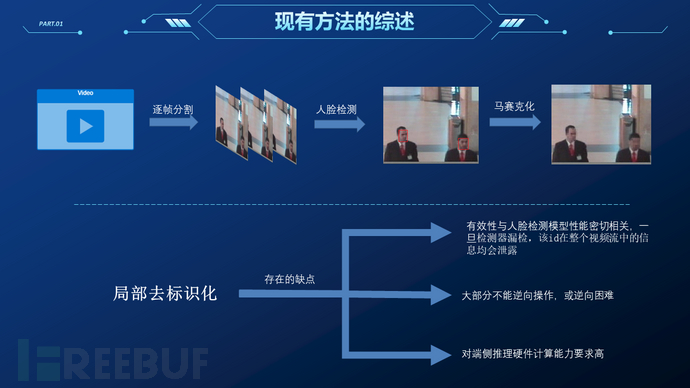
随着人工智能图像处理技术的发展,监控视频流分析系统正以前所未有的速度被推行到各个领域。其中行人检测、车辆检测、行为检测等应用在给社会带来便利同时,也引发了对个人隐私泄露的争议。迫于舆论压力欧盟采取了行动,在等待适当解决方案的同时,禁止在公共区域视频中提取人的面部信息长达五年之久。而此前“3.15”央媒曝光的监控信息滥用案例更是引发了关于监控便利与个人隐私保护间权衡利弊的广泛讨论。所幸,在不影响监控分析系统有关任务的前提下,大部分管理者都同意删除系统中的隐私信息。视频隐私保护的研究最早由Wickramasuriya J等人在2008年提出。随后的学者尝试将信息编码、信息隐藏、深度学习等方法引入该任务进行改进,取得不错的进展。在最新的相关工作中,相关方法已经大致完善,具有相当不错的实用性。
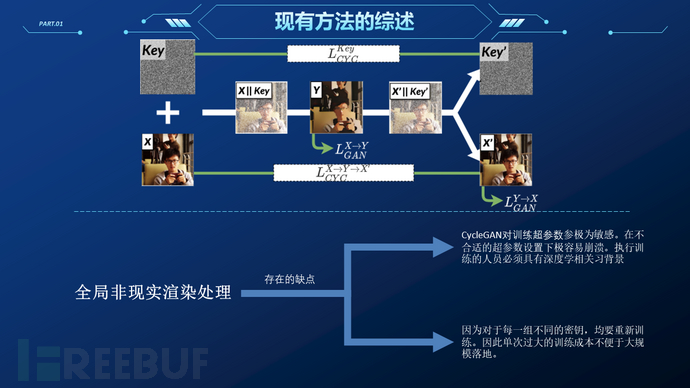
据此,本项目提出了一种新颖的视频隐私保护框架,并将其命名为SecStudent。与当前最先进的方法相仿,我们框架的核心同样由生成对抗网络驱动。不同之处在于我们以模型蒸馏为整体框架,可以针对不同的用户/不同场景快速生成所需的模型,同时避免了复杂的场景数据处理。相较于其他方法,我们提出的方法可以极大地降低训练迁移难度,这也正是推动隐私保护模型落地所必须的条件之一。此外我们还提出了一种轻量网络结构,可在几乎不降低任务性能的前提下(重建图片的逐像素语义一致性可达0.9918,逐对象语义一致性可达0.9481,SSIM可达0.998)加速计算能力受限的推理设备。

需求分析
本作品主要围绕全场景视频流隐私保护进行考虑和设计。本系统可适用于如社区、商场、酒店等公共场所监控或行车记录仪。这些场景的监控视频记录需要记录发生的事情,如人类行为或车辆行为,同时出现在这些场景的人们希望自己的人脸或车牌信息能够得到保护。本作品可以将监控视频转化抹去细节的风格化视频,里面的人脸信息和车牌号信息都被抹平,但是人的身体和车辆本身都还保留,可以达到不影响监控人类行为和车辆行为的前提下保护隐私,除此之外,本系统还给每个不同的监控系统添加了密钥(公式中涉及到密钥将用key表示),将监控视频的用户分为两类:普通用户和授权用户。授权用户是指系统的管理者和执行公务的特殊人员,例如进行案件调查的警察,它们能够使用密钥恢复全部视频,而普通的用户则只能观察到隐私保护后的视频信息。
设计概述
SecStudent有三个核心组件。编码器,解码器,以及教师网络。
其中编解码器采用对称的架构,利于学习可逆变换。编解码器的主干网络结构采用了当前在浅层视觉任务上达到SoTA的HINet,同时我们也提出了一种实时性较好的模型(参数量仅为HINet的1/10)用于硬件水平较低的场景。
我们选取了White Box Cartoonization[15]作为教师网络。该模型可以生成质量绝佳的卡通风格渲染图。此外该模型还能显式地调整渲染所得图片在面特征、结构特征以及纹理特征三个层面上的效果。因此选取White Box Cartoonization作为教师网络,有利于指导所得编解码器生成高质量渲染图像、调节编解码器的纹理遮蔽程度。
更具体地说,得益于White Box Cartoonization用的独立的三个分支分别处理面特征,结构特征以及纹理特征,我们通过单独干涉输入图像的某一方面,就能直接影响网络渲染结果对应维度的质量,同时其他方面的质量几乎不受影响。因此我们只需采用不同程度的高斯模糊处理输入的采集图像就能调整输出图像的纹理细节的遮蔽程度,而无需通过繁琐的手工方法设计数据预处理算法来控制编解码器的纹理遮蔽程度。
关键设计
本小节我们将从SecStudent结构、训练流程、部署应用三个方面来介绍我们的设计方案。
SecStudent结构
与其他基于深度学习隐私算法不同,我们的算法基于GAN模型蒸馏框架设计。其包含教师分支、学生分支(即任务所需的编解码器)、语义一致性分支,辅助损失分支四大部分。其中,教师分支是用于指导部署网络的高性能神经网络,由方案提供商在巨型数据集上得到;学生分支是用于实际应用任务的编码器网络和解码器网络;语义一致性分支是用于保证重建质量的约束分支,其要求重建图像经由同一语义分割网络的结果与源图像一致;辅助损失分支则是用于约束图像质量的一些辅助损失函数。有关我们框架的理论我们将在安全分析一节进行详细分析,有关组件的具体内容我们将在此节下文中详细介绍。
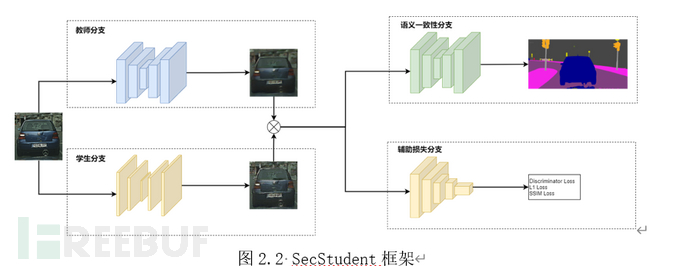
教师网络
教师网络是SecStudent中用于指导学生网络优化的大型卷积对抗生成网络。通过上游的方案提供商在巨型数据集上预训练得到。我们以学术界开源算法中性能最好的White Box Cartoonization为例,作为系统的教师网络。White Box Cartooniza-tion是一个基于显式约束的GAN的非现实渲染模型,与同类的其他方法相比,白盒框架能生成更为清晰的边界轮廓,并有助于保持色彩的和谐。此外,白盒框架也有效地减少了伪影。
该模型的特点是将图片分为了三个不同的部分面表征(surface representation)、结构表征(structure representation)、纹理表征(texture representation)。并用独立的三个分支分别进行处理,从而得到了可解释性和可控性较高的模型,如图2.4所示,White Box Cartoonization将图片显式地拆解为上述的三个分支,并分别进行监督。其中“f”表示生成器网络,“D”表示判别器网络。最终的loss可以表征为LossSurface + LossStructure + LossTexture + LossContent + LossTv。由于该渲染器分别处理图像不同类型的语义信息。因此可以通过单独修改采集图片的纹理特征分支来控制输出图像的细节水平。
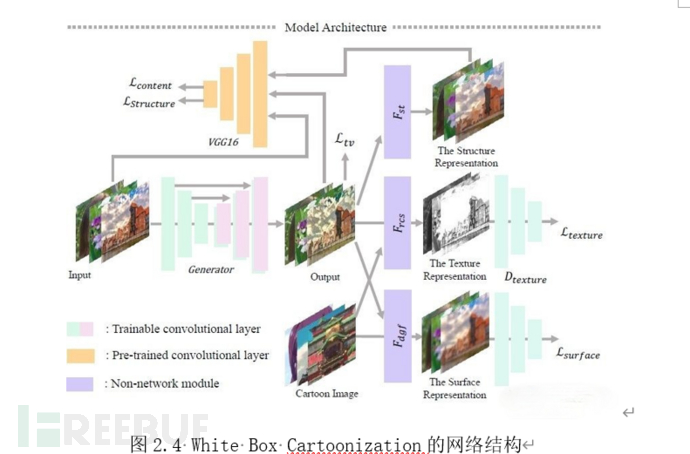


面表征是对图像的表观感知。同时包含了面结构和边缘信息可以表征图像语义,采用了可微的导向滤波器 (a differentiable guided filter)来学习。结构表征是图像的结构表示,用分割算法Felzenszwalb将图像分割成不同的区域,然后用 selective search 进行合并纹理表征,为了对比正常照片和漫画照片的纹理信息,就要去除光照和颜色的影响,因此作者提出了随机色彩偏移(random color shift),将RGB图像的三个通道分别乘上不同的权重,再加上对应的灰度图像。
学生网络
学生网络为功能与教师网络类似的轻量型卷积生成对抗网络,用于在端侧执行推理任务。与教师网络不同的是,学生网络中新增了一维通道用于输入编解码网络耦合的密钥。原则上解码器可以采用任意轻量级的浅层视觉深度学习模型,使用者可依据自身的使用场景选取性能与速度更为平衡的一种方案。
在本小节中我们将介绍两种可选的主干网络HINet和LBUNet并依次作为案例。前者更侧重精,度参数量更大,后者更侧重于速度,参数量仅为前者的1/10。
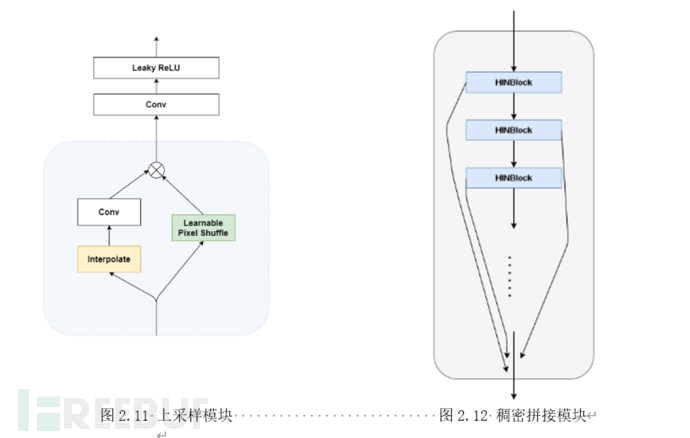
HINet[14]是图像浅层视觉任务方面的的新锐成果,适用于图像处理的浅层视觉任务(Low Level Task),如:图像复原、图像去噪、图像去模糊等。适用于对重建质量有绝对要求的场景。LowLevel BiStream Unet(简称为LBUNet)则是我们提出的一种基于Unet[13]的轻量级编解码网络。在采用同样的图像分辨率的情况下,大部分测试场景中,我们的方法仅需1/10的参数量就能取得与HINet竞争(甚至更好)的视觉效果(编码与重建),对边缘推理设备更为友好。
HINet:非现实渲染(风格化渲染)本质上也是一种浅层视觉任务。虽然其做法及效果与深度学习图像翻译类似,但非现实渲染的结果保留了图像的局部结构信息,其本质上只是对图像局部的纹理信息进行编码重建。因此我们选取了当前浅层视觉任务中性能指标表现最好的HINet作为基准编解码器的网络结构。HINet在绝大部分浅层视觉任务公开数据集排行榜中都取得了SoTA的结果。并且其计算量只有此前的SoTA方法的22.5%。
网络由两个浅层的Unet嵌套构成,如图2.7所示。其中,Stage1的浅层信息通过CSFF与Stage2中相应的部分融合;SAM模块为监督注意力模块,该模块可以通过loss约束指导得到一个解释性强的注意力遮罩。在我们的任务中,将原图通过恒等连接与SAM所得结果相加,并作为Stage1阶段的输出进行监督。监督损失函数采用L1损失函数。L1损失函数度量的值为Stage1转化图像和目标图像的绝对值差的均值。采用L1Loss可以指导SAM模块学得源图片和目标图片的残差形状作为注意力遮罩,有助于Stage2网络针对该部分进行转换,从而得到细节悦目的转化图。图2.9下部即为SAM模块的示意图。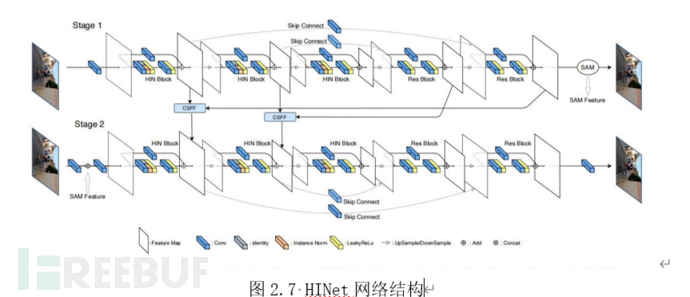
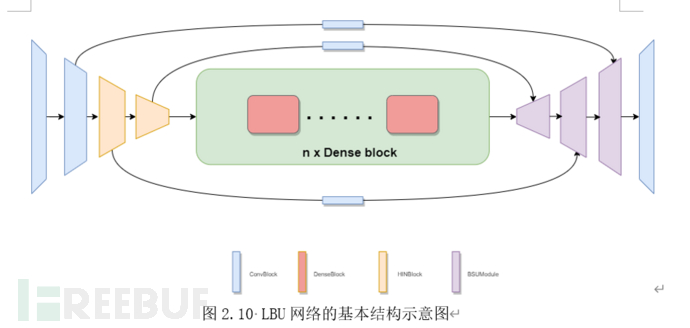
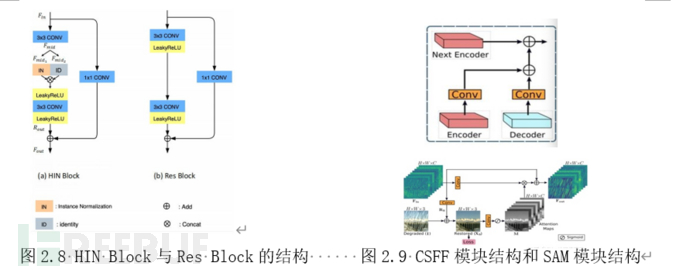 LowLevel BiStream Unet:LowLevel BiStream Unet是我们参考White Box Cartoonization的思路设计的轻量级编解码深度学习模型。LBUNet的结构与传统的Unet类似。在Unet的基础上我们针对任务的需求调整了网络结构使得其对计算能力的需求更加贴合端侧设备的能力。同时我们引入了一种新颖的模块BiStream UpSampler,替代原始Unet中所采用的上采样方法。我们的新方法可以在仅引入少量参数和计算量的前提下,大幅度提高模型的性能和可视化观感。
LowLevel BiStream Unet:LowLevel BiStream Unet是我们参考White Box Cartoonization的思路设计的轻量级编解码深度学习模型。LBUNet的结构与传统的Unet类似。在Unet的基础上我们针对任务的需求调整了网络结构使得其对计算能力的需求更加贴合端侧设备的能力。同时我们引入了一种新颖的模块BiStream UpSampler,替代原始Unet中所采用的上采样方法。我们的新方法可以在仅引入少量参数和计算量的前提下,大幅度提高模型的性能和可视化观感。
与Unet类似,我们的模型也采用下采样-上采用架构,并保留了下采样尺度为s时的特征图并使其在上采样至同一尺度时与模型的当前特征拼接( s∈[2,4,8])。不同的是:为了保证模型的计算量,我们在模型计算的一开始就采用了连续的4个下采样模块进行下采样,而不是下采样-多层卷积-下采样的结构。这是由于卷积的运算量与特征图的尺度呈二次相关,因此采用该种设计可以大幅度降低模型的计算量。4个连续模块的配置依次为[conv7x7, conv3x3,HIN Block,HINBlock]
在模型的中段,我们参考用于Low Level任务的模型(如超分辨率任务中的ESCPN)中常见的做法——采用堆叠的n个稠密连接模块作为转化子网络。稠密连接块可以聚合从浅层到深层的特征,相较于常见的残差块更适合用于需求low level特征的任务。每个稠密连接块都由m个宽度分别为 m_i*width 的HINet模块组成。依据我们的实验,仅需取n=1即可获得胜任任务需求的性能。其中m的配置为[4,4,2,1,1]。
在模型的后段,我们沿用连续的4组上采样模块,将网络的输出尺寸恢复至原始图片的大小。为了规避随特征图尺度增长而激增的计算量,仅在前3个上采样中采用BiStream UpSampler,最后一个上采样层采用子像素重排。最终输出层由7x7卷积运算及tanh激活函数构成,输出层的设计与一般GAN结构一致。
BiStream UpSampler是我们提出的一种新颖的卷积神经网络上采样模块。类似于White Box Cartoonization中的做法,我们也同样借鉴传统图像处理方法的思路。将图片拆解为面表征,结构表征和纹理表征三种低级表征特征。
用提取上述特征的传统方法中较为具有代表性的有:高斯核等人工设计的卷积核求取图像的面特征的引导滤波法;用基于子像素相似度利用Selective Search法合并相似像素以求取结构特征;基于纹理信息的色彩无关性通过随机色彩偏移得到纹理特征的随机色彩偏移。
因此在重建图片(上采样)的过程中,对于网络学得的特征,我们使用了三种常见的轻量级的算子来近似上述的三种传统算法的逆运算从而执行重建。对于面特征,我们基于高斯先验利用双线性法对特征图进行插值并利用卷积核近似其逆运算;对于结构表征我们基于Selective Search的先验,通过可学习的子像素重排模块学习子像素间的相关性并利用学得的相关性进行上采样重建;对于纹理表征,与主流深度学习方法一样我们直接采用可学习的卷积层进行近似重建。对于待处理的特征图,我们首先并行地执行上述模块一、二得到基于面特征、结构特征先验重建的两支特征图。随后将所得信息通过Leaky ReLU函数激活的卷积层,用以重建高频信息。为了避免归一化导致的高频信息缺失(局部细节模糊),模块中均不采用任意形式的归一化层。
综上所述,我们提出的模型同时在计算开销以及任务性能上都具有相当的竞争力(具体可参考模型测试一节),可以很好地提升项目的性能并降低成本。
安全设计
PECAM[9]首次在用于隐私保护的编解码网络中引入了密钥。其在输入图像上添加了一个维度用作密钥,保持输出图像的维度不变,同时要求用于重建的网络可以重建密钥中的信息。PECAM所提的算法架构如图2.13所示。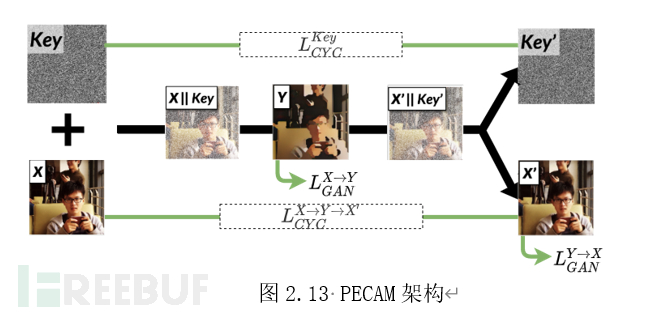
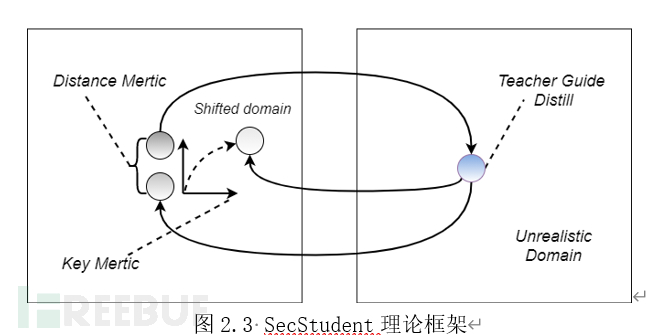
文章的作者认为,通过这一类似于深度学习信息隐藏的方法有助于提高基于可逆渲染的方法的安全性。通过训练密钥所包含的信息被隐藏在编码器渲染得到的图片中,而解码器可以从中提取并解码被隐藏的key。因此编解码器的编码运算就由数据集与一个确定的超高维密钥同时决定,在仅得知数据集的情况下难以仿制重建特定图片信息所需的解码器组件。
但是作者忽略了一个事实,整个训练的过程中仅采用了确定的唯一一个密钥。由于动态信息隐藏的难度远大于记忆参数进行重建[9],网络在优化过程中并不会倾向于将信息隐藏于图片中,而是会倾向于将密钥的信息记忆在网络包含的参数中,这也是这个方法有效的真正原因。
针对上述理论,我们设计实验进行验证:在使用耦合的一对编解码器进行推理的情况下。对输入图片加入不同的多枚密钥,所有密钥组合下网络输出结果(包括渲染和重建)仅有非常小的影响,并不影响主要细节的重建。可见密钥的作用并不是在渲染图片中加入了干扰重建的杂讯。这一实验验证了我们的猜想。
同时由于深度学习模型和度量方法本身的限制(卷积,多层感知机等都倾向于取得较为平滑的结果),密钥无法完全重建。这使得即使采用同一个密钥进行训练,其互换解码器后的重建效果也表现较差,大部分的细节无法重建。
因此,我们推测使得网络耦合有效的主要原因是,CycleGAN循环一致性约束的两个环节中梯度均能同时回传至编码器和判别器两个网络,此时通过梯度下降法优化的,是由编解码器两个网络构成的一个“超网络模型”。宏观上看,重建任务不仅由重建网络模型负责,而是由渲染模型与重建模型两个部分联合完成的。从关于模型有效性、模型剪枝的一些研究中,我们可以得知,用作同一任务,同样宏观结构的两个模型,无法简单的交换二者对应的组件。即对于一个完整的深度学习模型,其无法通过宏观的层级结构进行解耦,其部件之间的作用关系是镶嵌(embedded)的。因此所得网络在进行简单的解耦合(直接依据宏观层次拆开)无法得到有效的两个独立子模型(对于一致性这一功能而言,一致性训练过程耦合了两个网络)。而有关于密钥的一致性损失约束则在目标域的基础上增加了额外的归纳偏置偏移,约束了耦合的超网络的优化方向,使其远离教师网络指导的目标子域。这一过程中,以往被视为具有严重负面效果的高维稀疏特性,令人惊讶的起到了相当重要的正面效果。在此任务中正是因为高维稀疏的特性,在源域的基础上增加不同的偏置偏移(shift)就能轻易得到近似正交的两个子域。同时由于网络映射的目标域的偏置可通过密钥映射至一个2097152(1024×2048)维的解空间,两两不同的子网络的映射域仅有非常小的概率相交。从而通过小概率保护实现了场景所需的安全性。
综上所述,我们修改了用于一致性约束的训练流程,将原始的X→Y→X, Y→X→Y两个独立的循环约束合并为X→Y→X’→Y’一个流程,使得用于一致性约束的梯度得以完全流通,完全构成一个完整连续的“超网络”。同时由于网络的任意步骤都能直接回传梯度信息,密钥中包含的信息可以被梯度直接指导学习。此时图片不会作为中间媒介参与传播(神经网络的惰性)。因此,我们的网络在训练结束后可以一定程度上摆脱密钥对输入形状的影响,实现变分辨率推理,极大的便捷了端侧部署。同时我们的实验进一步证明了这一理论:将输入图像中添加的密钥更改为随机值,几乎不会影响渲染和重建图像的质量(表现为较为轻微色彩噪声,依然有较好的纹理细节);同一训练数据集下,不在一起训练的解码器即使采用同样的密钥作为约束,也无法还原渲染的图片,只是相比于使用不同密钥训练的解码器而言,重建的图片中产生的杂讯更少(详见模型测试一节)。同密钥无法复现则是因为对于极高维的非结构化数据,常见的损失函数均无法准确度量,即使同值仍有庞大的解空间,同时神经网络的梯度场面非常崎岖,训练过程包含的随机过程的干扰容易在结果中产生较大的累积影响。
训练架构
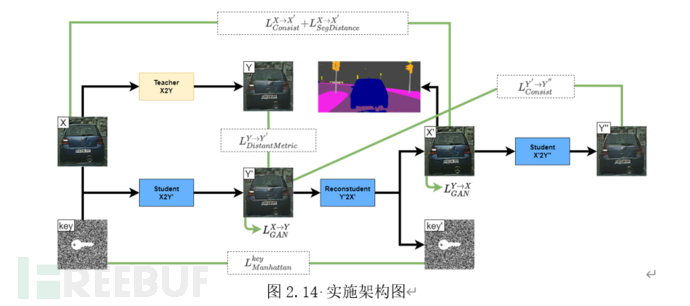 我们的实施方法基于GAN模型蒸馏框架设计。不同于主流的蒸馏方法,我们不要求学生网络收敛至于教师网络尽可能接近的域。而是针对隐私保护的渲染模型加入了额外的密钥距离约束。
我们的实施方法基于GAN模型蒸馏框架设计。不同于主流的蒸馏方法,我们不要求学生网络收敛至于教师网络尽可能接近的域。而是针对隐私保护的渲染模型加入了额外的密钥距离约束。
如图2.14为我们方法的具体实施流程。其中Teacher,Student,Reconstudent,分别为上文介绍的教师网络,学生网络中的渲染器,解码器。SegDistance分支为语义一致性分支。该分支约束重建所得图片与原始图片经过同一语义分割网络后的结果应当尽可能的接近。通过SegDistance分支的结果我们可以模拟人类对于重建图像的质量评估,同时保证重建的图片不会影响到下游算法的应用。
部署应用
得益于在训练上的优势,我们的方法可以很好的支持模型的落地需求。如下将简要介绍,我们的框架在部署应用中的应用以及相应方法。
数据采集:由于真实世界中的图像不受控制,难以用一个或有限个数据集覆盖。同时我们的框架仅需要简单的数据收集方式,并且无需标注数据。因此我们建议用户考虑自行收集所需数据。用户仅需要通过实际使用的采集端硬件采集真实的视频流,随机从中抽取不连续的n帧,保存为图片,置于框架推荐的目录下即可。
模型训练:在依照提供的说明文档安装完环境后。选择更符合用户使用场景的网络并运行相应的python文件即可执行训练。若需要进一步的调整,可以用调整预设的模糊化等级,等级为从1~n/2(n=min(2n s.t.2n > 图片的最小边长)),观察转换后的图片,取最为满意的一个等级。
模型部署:我们的框架还提供了自动的onnx导出模块,依据说明文档执行对应的python代码即可获得上一步中训练所得模型的onnx文件。onnx文件是一种通用性极强的模型描述文件,支持所有主流端侧推理框架。用户可以采用我们提供的onnx文件直接加载到对应的推理框架中,或自行完成进一步的量化压缩处理。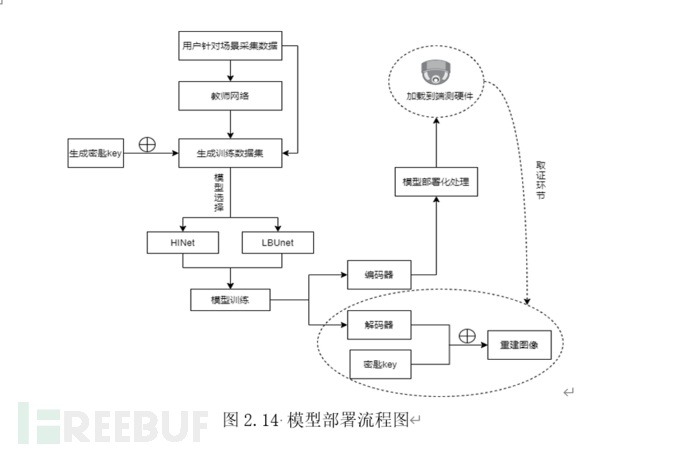
模型测试
模型速度测试
我们在不同的推理硬件上测试了上文采用的两个模型的实际推理速率。测试输入分辨率均为1024*2048。为模拟实际的应用场景,我们取用500张图片连续加载推理,结果为单张图片推理所需时长的均值。如表1所示,我们的模型LBUNet最高可以带来2倍的加速。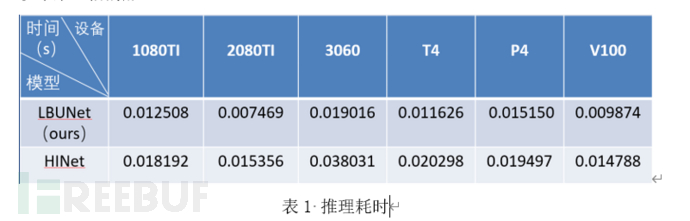
模型对比
我们挑选了Cityscapes数据集里的一张图(图3.1所示)来做模型对比,可以发现我们提出模型LBUNet如图3.2、3.4具有竞争力的表现性能,LBUNet渲染出来的图片涂抹程度比HINet强,重建质量也比HINet高。我们的方法可以满足隐私保护的任务需求。


模型泛化性能测试
我们模型训练是在风格转换后的Cityscapes上训练的,里面都是城市街景,下面我们使用Widerface人脸数据集和香港中文大学的CUHK Occlusion Dataset 监控数据集进行测试,里面的数据是没有出现在训练集的,如图3.6~3.11所示,即使模型没有“见”过行人场景的图片,也能很好地渲染并重建图片。
下面是检验转换后的视频流在行人检测模型和车辆检测模型的效果,检测模型均来源于百度AI行人检测、车辆检测接口,从图3.12~3.15可以看到,渲染后的图对行人检测模型的影响不是很大,如果我们制作一个渲染后的行人数据集微调检测模型,达到的效果会更好。
下面是车辆检测,如图3.16~3.19,图3.16、图3.18是原图,检测模型还可以检测到车辆的车牌,经过渲染后如图3.17、图3.19,检测模型就检测不到车牌,可见针对小尺度的车牌进行渲染后,能抹除车牌信息,而大尺度的车辆受到的影响很小,检测模型能正常工作。
模型安全性分析
1.假设在攻击者不知道密钥的存在下:
攻击者使用深度学习模型对视频进行恢复,直接RGB-2-RGB 尝试转换,然而,文献[10]中的实验表明该方法无法成功,即如果攻击者不了解某些知识是无法重建被隐藏的数据的。
攻击者使用图像处理技术,将视频分解成帧,然后对每帧图片进行锐化加强信息,如图3.21中锐化所示,可以发现锐化攻击不能恢复车牌信息,攻击失败。攻击者还可能使用超分辨率模型对图片进行攻击,图3.21中可以看到超分辨率攻击无法重建出车牌号的细节。
2.假设在攻击者知道密钥的存在下:
攻击者在知道密钥存在后,可能会训练类似的CycleGAN对视频进行重建,攻击效果如图3.22,我们分别采用了GAN攻击1使用相同的神经网络结构不同的key,GAN攻击2采用不同的神经网络结构相同的key进行模仿攻击,可以看到攻击失败。
重建质量分析
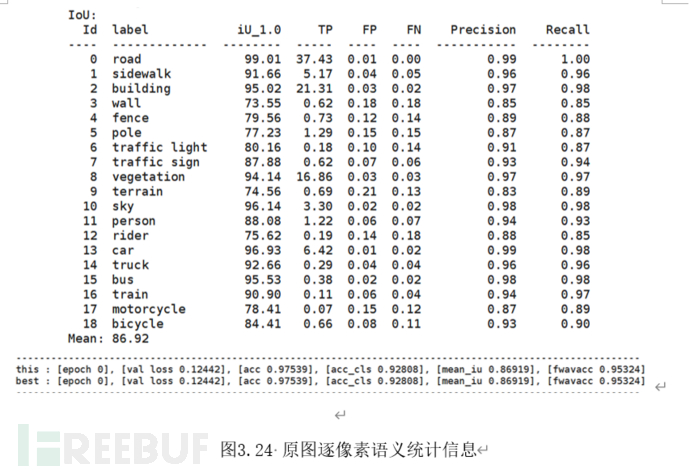
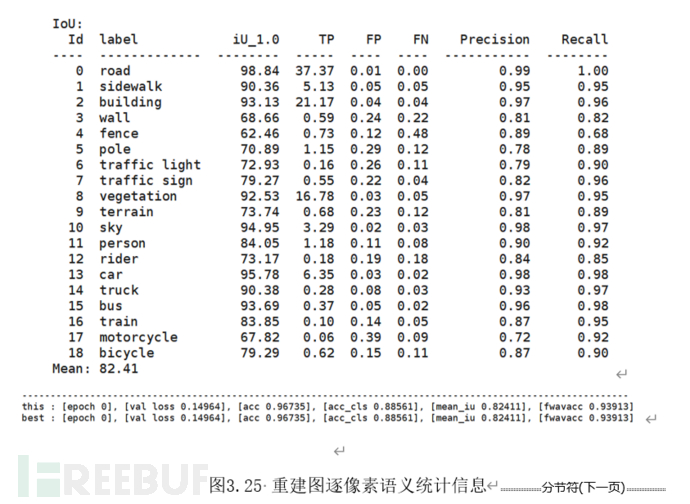
重建后的图片质量同样非常重要但往往难以进行衡量。用于传统图片信息评估的算法如峰值信噪比(PNSR)和图片结构相似性(SSIM)难以量化图片信息变化对于AI算法的扰动程度以及人类的主观观感。因此我们采用逐像素语义一致性统计信息对模型重建的效果进行评估。大致方法如图3.23所示,将500张图像的原图和重建后图像通过同一个语义分割网络。
分别统计网络输出结果的准确率,并据此对比重建前后图像的语义损失程度。图3.24~3.25展示了LBUNet在Cityscape数据集上的准确率统计结果。其中逐像素准确率分别为97.53%与96.73%,逐像素语义一致性为99.18%;逐对象平均交并比分别为86.92%与82.41%,逐对象语义一致性为94.81%。可以认为重建图像过程对图片语义信息的扰动程度极低。不会影响图像本身在对应下游任务(如:取证,身份识别)中的性能。
[1] Wickramasuriya J , Datt M , Mehrotra S , et al. Privacy protecting data collection in media spaces[C]// Proceedings of the 12th ACM International Conference on Multimedia, New York, NY, USA, October 10-16, 2004. ACM, 2004.
[2] Hassan E T , Hasan R , Shaffer P , et al. Cartooning for Enhanced Privacy in Lifelogging and Streaming Videos[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2017.
[3]张驰,陆晔,罗渝平,孙晓凯,祝涵珂.一种复杂场景下的视频流人脸隐私保护技术[J].电信科学,2021,37(01):94-101.
[4] Gafni O , Wolf L , Taigman Y . Live Face De-Identification in Video. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
[5] Tajik K , Gunasekaran A , Dutta R , et al. Balancing Image Privacy and Usability with Thumbnail-Preserving Encryption[C]// Network and Distributed System Security Symposium. 2019.
[6] Proena H . The UU-Net: Reversible Face De-Identification for Visual Surveillance Video Footage[J]. 2020.
[7] Cheung S , Venkatesh M V , Paruchuri J K , et al. Protecting and Managing Privacy Information in Video Surveillance Systems[M]. Springer London, 2009.
[8]彭许红, 陈威兵, 夏明,等. 基于可逆水印的监控视频隐私信息保护与隐藏[J]. 小型微型计算机系统, 2014(06):1226-1231.
[9]Wu, Hao et al. “PECAM: privacy-enhanced video streaming and analytics via securely-reversible transformation.” Proceedings of the 27th Annual International Conference on Mobile Computing and Networking (2021): n. pag.
[10] Baluja S . Hiding Images Within Images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019:1-1.
[11] Isola P , Zhu J Y , Zhou T , et al. Image-to-Image Translation with Conditional Adversarial Networks[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.
[12]Zhu J Y , Park T , Isola P , et al. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks[J]. IEEE, 2017.
[13] Ronneberger O , Fischer P , Brox T . U-Net: Convolutional Networks for Biomedical Image Segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer International Publishing, 2015.
[14]Chen L, Lu X, Zhang J, et al. HINet: Half Instance Normalization Network for Image Restoration[J]. arXiv preprint arXiv:2105.06086, 2021.
[15]Wang X, Yu J. Learning to cartoonize using white-box cartoon representations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 8090-8099.
如有侵权请联系:admin#unsafe.sh