导语:深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。
人工智能 (AI) 不断发展,并在过去十年中取得了巨大进步。深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。目前深度学习已经可以被应用于图像分割、预测任何基于氨基酸序列的蛋白质的三维结构、机器翻译、语音识别。近年来,深度学习已被应用于恶意软件分析。不同类型的深度学习算法,如卷积神经网络 (CNN)、循环神经网络和前馈网络,已被应用于使用字节序列、灰度图像、结构熵、API 的恶意软件分析中的各种用例调用顺序、HTTP 流量和网络行为。
大多数传统的机器学习恶意软件分类和检测方法都依赖于手工制作的特征。这些特征是根据具有领域知识的专家选择的。特征工程可能是一个非常耗时的过程,手工制作的特征可能无法很好地推广到新型恶意软件。在本文中,McAfee的研究人员简要介绍了如何将 CNN 应用于原始字节以在现实世界数据中进行恶意软件检测和分类。
CNN 上的原始字节

应用深度学习的动机是在原始字节中识别新的模式。这项工作的新颖之处在于三个方面。首先,没有特定领域的特征提取和预处理。其次,这是一种端到端的深度学习方法。它还可以执行端到端分类。它还可以作为特征提取器进行特征增强。最后,可解释的人工智能(XAI)提供了对CNN决策的深入了解,并帮助人类识别不同恶意软件家族的有趣模式。如图1所示,输入只有原始字节和标签。CNN通过表示学习来自动学习特征并对恶意软件进行分类。
实验结果
为了进行恶意软件检测实验,研究人员首先收集了 833000 个不同的二进制样本(污染 和 干净的),跨越多个家族,编译器和不同的“首次出现”时间周期。尽管他们确实使用了不同的包装程序和混淆程序,但仍有大量来自普通家族的样本。检测时,研究人员会在进行完整性检查以删除损坏的、过大或过小的样本。在满足完整性检查标准的样本中,研究人员从这些样本中提取原始字节,并利用它们进行多个实验。数据以80% / 20%的比例随机分成训练集和测试集。研究人员利用这个数据集来进行三个实验。
在研究人员的第一个实验中,来自833000个样本的原始字节被返回给CNN,在receiver operating curve (ROC)下面积的性能精度为0.9953。
初始运行的一个观察结果是,在从83.3万个独特样本中提取原始字节后,研究人员确实发现了重复的原始字节条目。这主要是由于恶意软件家族利用哈希分解作为一种多态性的方法。因此,在研究人员的第二个实验中,研究人员对提取的原始字节项进行了重复数据删除。这将原始字节输入向量计数减少到262000个样本,ROC下的试验面积为0.9920。
在第三个实验中,研究人员尝试了多家族恶意软件分类。研究人员从原始集合中抽取了13万份样本,并标记了11个类别,第0个类别被归类为Clean,其中1-9个是恶意软件家族,第10个类别被归类为Others。同样,这11个桶包含了带有不同包装器和编译器的样本。研究人员对训练集和测试集进行了另一次80 / 20%的随机分割。本实验的测试精度为0.9700。一台GPU的培训和测试时间为26分钟。
可视化解释(Visual Explanation)

CNN训练前后使用T-SNE和PCA的可视化解释
为了理解CNN的训练过程,研究人员对CNN的训练进行了可视化分析。图 2 显示了 CNN 训练前后的 t-Distributed Stochastic Neighbor Embedding (t-SNE) 和主成分分析 (PCA)。研究人员可以看到,经过训练,CNN能够提取有用的表示来捕获不同类型恶意软件的特征,如图所示在不同的聚类中,大多数类别都进行了很好地分离,这让研究人员相信该算法作为多类分类器是有用的。
然后研究人员执行XAI来理解CNN的决定。下图显示了一个 Fareit 样本和一个 Emotet 样本的 XAI 热图。颜色越亮,对神经网络中的梯度激活做出贡献的字节就越重要。因此,这些字节对 CNN 的决策很重要。研究人员有兴趣了解对决策产生重大影响的字节,并手动审查了一些样本。

Fareit(左)和 Emotet(右)上的 XAI 热图
理解ML决策和XAI

对 CNN 预测的人工分析
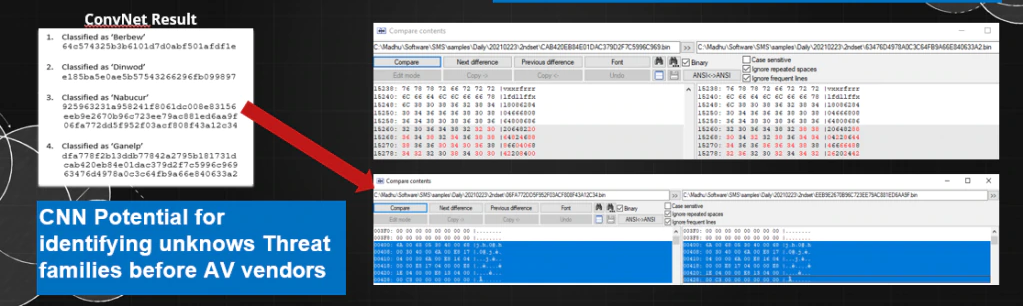
为了验证CNN是否能够学习到新的模式,研究人员给CNN提供了一些之前从未见过的样本,并请了一个人类专家来验证CNN对一些随机样本的决定。人工分析验证了 CNN 能够正确识别许多恶意软件家族。在某些情况下,它根据研究人员的内部测试在前 15 名的防病毒供应商之前准确地识别了样本。下图显示了属于Nabucur家族的样本子集,CNN正确地对其进行了分类,尽管当时没有检测到供应商。同样值得注意的是,研究人员的结果显示,CNN目前能够利用普通包装器将恶意软件样本进行分类。

示例编译器的域分析
研究人员对相同的示例编译器 VB 文件进行了域分析。如上图所示,CNN 能够在其他供应商之前识别出攻击家族的两个样本。 CNN 就两个样本与 MSMP/其他供应商达成一致。在这个实验中,CNN 错误地将一个样本识别为 Clean。

对 XAI 热图的人工分析,以上就是从Hiew工具中分解出的部分解密TEA算法

以上是一个样本的XAI热图
研究人员请了一位人类专家检查XAI热图,并验证这些亮颜色的字节是否与恶意软件家族分类有关。上图显示了属于Sodinokibi家族的一个示例。 XAI 标识的字节 (c3 8b 4d 08 03 d1 66 c1) 很有趣,因为字节序列属于 Tea 解密算法的一部分。这表明这些字节与恶意软件分类相关,这证实了CNN可以学习并帮助识别人类或其他自动化可能忽略的有用模式,尽管这些实验是初步的,但它们表明了 CNN 在识别未知的感兴趣模式方面的有效性。
综上所述,实验结果和可视化解释表明CNN可以自动学习PE原始字节表示,CNN原始字节模型可以执行端到端恶意软件分类。CNN 可以是用于特征增强的特征提取器。 CNN 原始字节模型有可能先于其他供应商识别威胁系列并识别新威胁。这些初步结果表明,CNN 可以成为帮助自动化和人类研究人员进行分析和分类的非常有用的工具。
本文翻译自: https://www.mcafee.com/blogs/other-blogs/mcafee-labs/the-rise-of-deep-learning-for-detection-and-classification-of-malware如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh