


本文的案例会使用requests抓取酷狗的网络红歌榜,并使用Beautiful Soup库的CSS选择器分析抓取到的HTML代码,并将提取的信息显示在Console上。
首先在Chrome浏览器中使用下面的URL打开网络红歌榜页面。
https://www.kugou.com/yy/rank/home/1- 23784.html?from=rank
页面效果如图1所示。
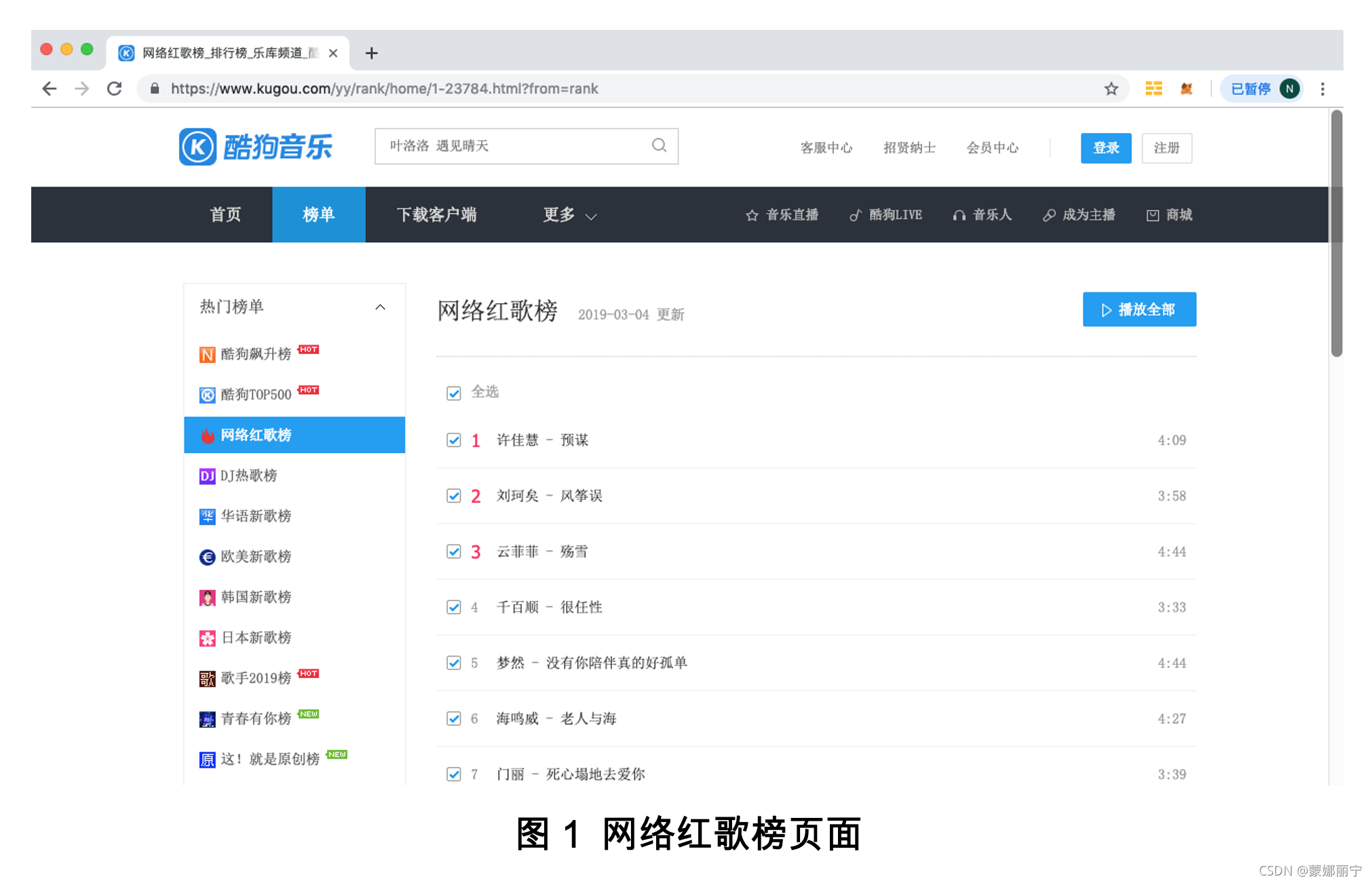
网络红歌榜页面下方并没有用于切换页面的数字导航条,不过从URL的样子可以尝试一下,例如1-
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
62 篇文章 2 订阅 ¥29.90 ¥99.00
本文的案例会使用requests抓取酷狗的网络红歌榜,并使用Beautiful Soup库的CSS选择器分析抓取到的HTML代码,并将提取的信息显示在Console上。
首先在Chrome浏览器中使用下面的URL打开网络红歌榜页面。
https://www.kugou.com/yy/rank/home/1- 23784.html?from=rank
页面效果如图1所示。
网络红歌榜页面下方并没有用于切换页面的数字导航条,不过从URL的样子可以尝试一下,例如1-