IntroductionFirst of all, I must admit that the story is a bit old. It took place in July 2019.At th 2021-08-07 18:24:31 Author: infosecwriteups.com(查看原文) 阅读量:65 收藏
Introduction
First of all, I must admit that the story is a bit old. It took place in July 2019.
At that time, I have learned the approach of machine-based authentication in the cloud. In particular, reading disclosed HackerOne server-side request forgery and similar vulnerability reports with the technique of gaining access to the cloud provider by connecting to the internal metadata endpoint, retrieving a service account token, and using the exfiltrated service account / token to authenticate from outside, was the key to my success. This lead me to the idea that instead of searching for SSRF (or related) vulnerabilities in a single target, I should try my luck in the big wide world of OSINT.
As far as I can remember, Github was not scanning for exposed tokens at that time. Encountering exposed credentials was painless.
Finding a search query
The first step is, of course, to find a way to find these services accounts. My approach is to find a unique string in the target to narrow down the search results. For example, long-term AWS IAM access key ids begin with AKIA and temporary credentials with ASIA . Google service accounts were unknown to me, I needed to lookup the structure and identify potential needles.

All service-account-email values apparently end with iam.gserviceaccount.com according to the Google Cloud documentation.
By searching with that needle, the Github search result quality has really increased. Nonetheless, there is still room for improvement. For instance, since the service account is often a JSON structure, it is not hard to imagine that a Github user exposes their service account in a dot JSON file. The search query could look like this:
iam.gserviceaccount.com extension:jsonIt is of course possible that a Google service account is stored in other file formats.
In my case, the service account token was written inside a dot YAML file (the file was used in a DevOps automation tool).
Using the Google Cloud Service Account
At this point, the owner of the Google service account was still unclear and I needed a way to identify the owner. Wouldn’t it be great if AWS or any similar credential issuer allows security researchers to look up the owner? I guess there would be some sort of privacy implication but it would really help in some cases.
I use a variety of tools to identify the owner. I haven’t found any easier way than listing all Google cloud resources and then trying to associate the data with a company.
To begin with, the Google cloud command-line interface with a small script is a great help. I start with revoking any previous access tokens from my environment (because you don’t want to target older findings).
➜ gcloud auth revoke --allNext, I copy the exposed service account into a JSON file (assuming the origin service account is also JSON, otherwise you might need to fiddle around) and tell gcloud to use it.
➜ gcloud auth activate-service-account --key-file service-account.jsonGcloud needs to know the project id which can be retrieved from the JSON file.
➜ gcloud config set project your-project-nameFinally, you can use the command line interface to communicate with the Google Cloud.
Instead of manually querying every Google cloud resource, I found it very convenient to just use the following script https://gist.github.com/carnal0wnage/757d19520fcd9764b24ebd1d89481541 (you need to change the project id on line 4).
Another way is ScoutSuite from NCC Group. You can find it here https://github.com/nccgroup/ScoutSuite. It might give you even better results but the script allows a quicker overview in my opinion.
Note: Your service account might have access to other projects. It is a good idea to list all accessible projects with gcloud projects list and to check each project for information.
I like to have the dumped information in a code editor for an easier overview. You can accomplish that by piping the output into a file like this:
➜ bash gcp_enum.sh >> out.txt
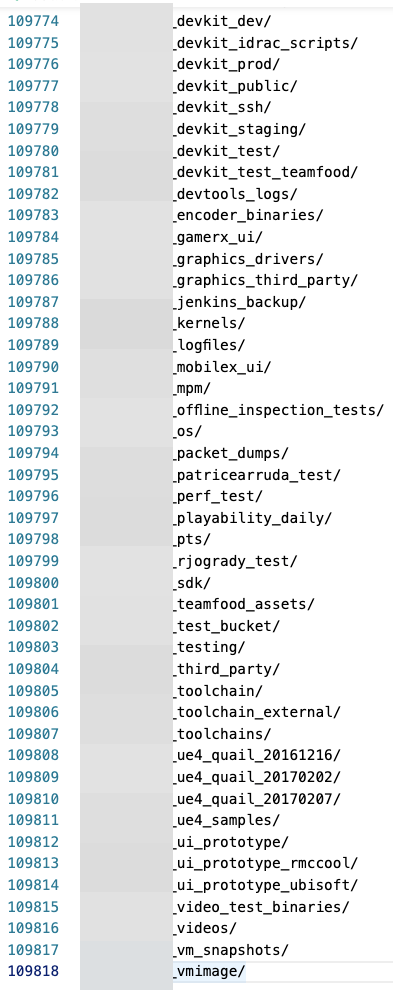
The output size was astonishing. 109.818 lines, of which 108.466 lines are buckets. Many buckets were boring because they were suffixed buckets; maybe “versioned” buckets for log files?
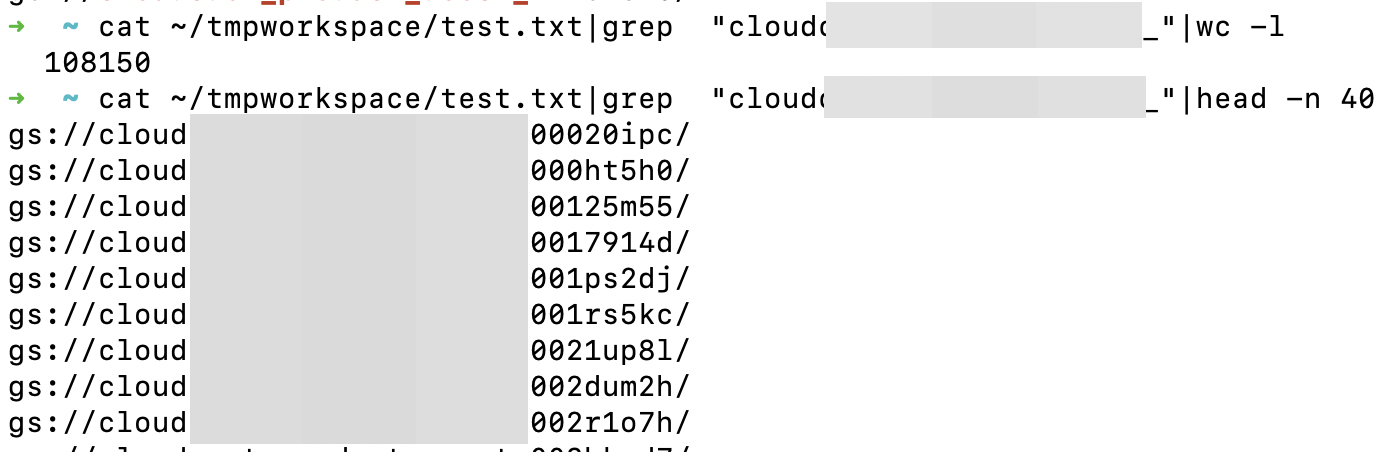
The other 316 buckets had interesting names; containing the words “backup”, “prod”, “automation”, “jenkins”, “stadia” + “backups”, “logs”, “gpg”, “ssh”, “deployments”, “scripts”, “dumps” and more.
I had not only access to these buckets but also to BigQuery and other cloud resources.
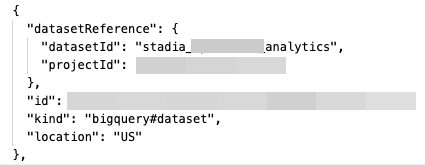
At that time, I was really happy and thought that access to production data would gain me a good amount of $$$$$ but Google paid me a bounty of 500$.
¯\_(ツ)_/¯
如有侵权请联系:admin#unsafe.sh