作者:wzt
原文链接:https://mp.weixin.qq.com/s/G6kE52o7OZaGYPqnuUwggQ
1 简介
以linux kernel 5.6.7内核代码为例,阐述内核的audit子系统是如何实现的,以及它的一些设计缺陷和绕过方法。
2 架构
2.1 总体架构
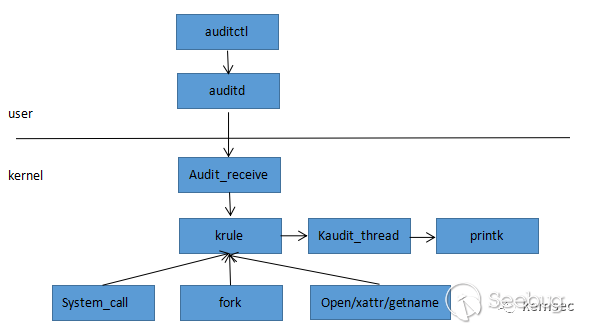
Linux audit系统分为用户层和内核层两部分,用户层通过auditctl工具生成rule规则,发送给auditd守护进程,后者通过netlink协议与内核进行交互,包括规则下发等功能。
内核在启动阶段初始化audit子系统时,创建一个netlink socket,启动audit_receive内核线程处理来自用户层的请求,包括解析rule规则,使能audit开关等工作。
内核维护一个日志队列,通过kaudit_thread内核线程来操作,当队列长度大于audit_backlog_limit时进行休眠,否则从队列里取下一个节点进行日志格式化处理,然后写入到printk子系统里。
对于rule规则的审计有以下几个入口点,后面章节会详细介绍:
- system call系统调用阶段
- fork进程时
- 文件系统状态改变
这几个入口点都可以触发对rule规则的检查,然后写入内核日志队列,最后通过上述的kaudit_thread内核线程处理。
2.2 内核与用户通讯接口
2.2.1 协议接口
内核使用数字9代表audit子系统使用的netlink协议:
include/uapi/linux/netlink.h
#define NETLINK_AUDIT 9 /* auditing */
kernel/audit.c
static int __net_init audit_net_init(struct net *net)
{
struct netlink_kernel_cfg cfg = {
.input = audit_receive,
.bind = audit_bind,
.flags = NL_CFG_F_NONROOT_RECV,
.groups = AUDIT_NLGRP_MAX,
};
...
aunet->sk = netlink_kernel_create(net, NETLINK_AUDIT, &cfg);
...
}Audit_receive函数处理接受来自用户层的数据协议:
audit_receive()->audit_receive_msg:
static int audit_receive_msg(struct sk_buff *skb, struct nlmsghdr *nlh)
{
...
switch (msg_type) {
case AUDIT_GET:
case AUDIT_SET:
case AUDIT_GET_FEATURE:
case AUDIT_SET_FEATURE:
case AUDIT_USER:
case AUDIT_FIRST_USER_MSG ... AUDIT_LAST_USER_MSG:
case AUDIT_FIRST_USER_MSG2 ... AUDIT_LAST_USER_MSG2:
case AUDIT_ADD_RULE:
case AUDIT_DEL_RULE:
case AUDIT_LIST_RULES:
case AUDIT_TRIM:
case AUDIT_MAKE_EQUIV:
case AUDIT_SIGNAL_INFO:
case AUDIT_TTY_GET:
case AUDIT_TTY_SET:
...
}Nlh为用户态auditd进程使用netlink协议包装的数据,其中msg_type代表auditd能使用的功能里列表:
-
AUDIT_GET
获取audit子系统的状态信息,使用auditctl -s进行获取。 -
AUDIT_SET
设置audit子系统状态,包括audit功能是否开启,注册和销毁来自用户态auditd进程的请求。Linux audit子系统每次只允许一个auditd进程注册,并且auditd进程只能来自init_namespace, 也就是说来自docker等其他容器的进程是不扮演auditd进程与内核通讯的。 -
AUDIT_GET_FEATURE
AUDIT_SET_FEATURE
获取和设置功能列表 -
AUDIT_USER
AUDIT_FIRST_USER_MSG ... AUDIT_LAST_USER_MSG
AUDIT_FIRST_USER_MSG2 ... AUDIT_LAST_USER_MSG2
处理来自用户态自定义的audit日志内容 -
AUDIT_ADD_RULE
AUDIT_DEL_RULE
AUDIT_LIST_RULES
获取和设置rule规则 -
AUDIT_TRIM
销毁之前被监控的目录树 -
AUDIT_MAKE_EQUIV
附加到之前被监控的目录树 -
AUDIT_SIGNAL_INFO
获取发送给auditd信号的进程信息 -
AUDIT_TTY_GET
AUDIT_TTY_SET
获取和设置tty监控信息,这是个神奇的功能,后面会有详细分析。
2.2.2 规则添加
下面以添加一条规则为例,看下audit子系统是如何在内核操作的。
kernel/auditfilter.c:
int audit_rule_change(int type, int seq, void *data, size_t datasz)
{
switch (type) {
case AUDIT_ADD_RULE:
entry = audit_data_to_entry(data, datasz);
if (IS_ERR(entry))
return PTR_ERR(entry);
err = audit_add_rule(entry);
}audit_data_to_entry用来将用户态的规则转为内核态的规则,来自用户态的规则数据结构体为:
include/uapi/linux/audit.h:
struct audit_rule_data {
__u32 flags; /* AUDIT_PER_{TASK,CALL}, AUDIT_PREPEND */
__u32 action; /* AUDIT_NEVER, AUDIT_POSSIBLE, AUDIT_ALWAYS */
__u32 field_count;
__u32 mask[AUDIT_BITMASK_SIZE]; /* syscall(s) affected */
__u32 fields[AUDIT_MAX_FIELDS];
__u32 values[AUDIT_MAX_FIELDS];
__u32 fieldflags[AUDIT_MAX_FIELDS];
__u32 buflen; /* total length of string fields */
char buf[0]; /* string fields buffer */
};这个结构其实就是由auditctl的参数负责填充的,mask数组就是audit -S 指定要过滤的系统调用表,fields数组为audit -F 指定的操作表,格式为type op value。
内核态的规则结构体为:
struct audit_krule {
u32 pflags;
u32 flags;
u32 listnr;
u32 action;
u32 mask[AUDIT_BITMASK_SIZE];
u32 buflen; /* for data alloc on list rules */
u32 field_count;
char *filterkey; /* ties events to rules */
struct audit_field *fields;
struct audit_field *arch_f; /* quick access to arch field */
struct audit_field *inode_f; /* quick access to an inode field */
struct audit_watch *watch; /* associated watch */
struct audit_tree *tree; /* associated watched tree */
struct audit_fsnotify_mark *exe;
struct list_head rlist; /* entry in audit_{watch,tree}.rules list */
struct list_head list; /* for AUDIT_LIST* purposes only */
u64 prio;
};field在内核中的结构体为:
struct audit_field {
u32 type;
union {
u32 val;
kuid_t uid;
kgid_t gid;
struct {
char *lsm_str;
void *lsm_rule;
};
};
u32 op;
};Type的类型可以为:
include/uapi/linux/audit.h:
#define AUDIT_PID 0
#define AUDIT_UID 1
#define AUDIT_EUID 2
#define AUDIT_SUID 3
#define AUDIT_FSUID 4
#define AUDIT_GID 5
#define AUDIT_EGID 6
#define AUDIT_SGID 7
#define AUDIT_FSGID 8
#define AUDIT_LOGINUID 9
#define AUDIT_PERS 10
#define AUDIT_ARCH 11
#define AUDIT_MSGTYPE 12
#define AUDIT_SUBJ_USER 13 /* security label user */
#define AUDIT_SUBJ_ROLE 14 /* security label role */
#define AUDIT_SUBJ_TYPE 15 /* security label type */
#define AUDIT_SUBJ_SEN 16 /* security label sensitivity label */
#define AUDIT_SUBJ_CLR 17 /* security label clearance label */
#define AUDIT_PPID 18
#define AUDIT_OBJ_USER 19
#define AUDIT_OBJ_ROLE 20
#define AUDIT_OBJ_TYPE 21
#define AUDIT_OBJ_LEV_LOW 22
#define AUDIT_OBJ_LEV_HIGH 23
#define AUDIT_LOGINUID_SET 24
#define AUDIT_SESSIONID 25 /* Session ID */
#define AUDIT_FSTYPE 26 /* FileSystem Type */
#define AUDIT_DEVMAJOR 100
#define AUDIT_DEVMINOR 101
#define AUDIT_INODE 102
#define AUDIT_EXIT 103
#define AUDIT_SUCCESS 104 /* exit >= 0; value ignored */
#define AUDIT_WATCH 105
#define AUDIT_PERM 106
#define AUDIT_DIR 107
#define AUDIT_FILETYPE 108
#define AUDIT_OBJ_UID 109
#define AUDIT_OBJ_GID 110
#define AUDIT_FIELD_COMPARE 111
#define AUDIT_EXE 112
#define AUDIT_SADDR_FAM 113
#define AUDIT_ARG0 200
#define AUDIT_ARG1 (AUDIT_ARG0+1)
#define AUDIT_ARG2 (AUDIT_ARG0+2)
#define AUDIT_ARG3 (AUDIT_ARG0+3)
#define AUDIT_FILTERKEY 210Op的操作可以为:
/* These are the supported operators.
* 4 2 1 8
* = > < ?
* ----------
* 0 0 0 0 00 nonsense
* 0 0 0 1 08 & bit mask
* 0 0 1 0 10 <
* 0 1 0 0 20 >
* 0 1 1 0 30 !=
* 1 0 0 0 40 =
* 1 0 0 1 48 &= bit test
* 1 0 1 0 50 <=
* 1 1 0 0 60 >=
* 1 1 1 1 78 all operators
*/
#define AUDIT_BIT_MASK 0x08000000
#define AUDIT_LESS_THAN 0x10000000
#define AUDIT_GREATER_THAN 0x20000000
#define AUDIT_NOT_EQUAL 0x30000000
#define AUDIT_EQUAL 0x40000000
#define AUDIT_BIT_TEST (AUDIT_BIT_MASK|AUDIT_EQUAL)
#define AUDIT_LESS_THAN_OR_EQUAL (AUDIT_LESS_THAN|AUDIT_EQUAL)
#define AUDIT_GREATER_THAN_OR_EQUAL (AUDIT_GREATER_THAN|AUDIT_EQUAL)
#define AUDIT_OPERATORS (AUDIT_EQUAL|AUDIT_NOT_EQUAL|AUDIT_BIT_MASK)就是说audit子系统可以对以上的type类型做一些简单的逻辑操作, 这对于审计作用已经足够了。比如它可以让audit子系统只针对一个uid或一个group组进行审计;可以对系统调用的前四个参数进行审计, 但是目前只支持整型的参数,指针或数据结构则没有支持,因为这要设计更复杂的数据结构, 指针可以包含更多级指针, 数据结构可以嵌套数据结构,数据结构又可以嵌套指针等等。虽然目前功能有限,但这个filed结构体的操作可以说是linux audit子系统的一个重大改进了。
audit_data_to_entry->audit_to_entry_common解析用户态的struct audit_rule_data数据为struct audit_krule:
struct audit_krule {
u32 pflags;
u32 flags;
u32 listnr;
u32 action;
u32 mask[AUDIT_BITMASK_SIZE];
u32 buflen; /* for data alloc on list rules */
u32 field_count;
char *filterkey; /* ties events to rules */
struct audit_field *fields;
struct audit_field *arch_f; /* quick access to arch field */
struct audit_field *inode_f; /* quick access to an inode field */
struct audit_watch *watch; /* associated watch */
struct audit_tree *tree; /* associated watched tree */
struct audit_fsnotify_mark *exe;
struct list_head rlist; /* entry in audit_{watch,tree}.rules list */
struct list_head list; /* for AUDIT_LIST* purposes only */
u64 prio;
};audit_rule_change->audit_add_rule将新生成的krule挂接到对应的规则链表里:
static inline int audit_add_rule(struct audit_entry *entry)
{
e = audit_find_rule(entry, &list);[1]
if (watch) {[2]
err = audit_add_watch(&entry->rule, &list);
if (tree) {
err = audit_add_tree_rule(&entry->rule);[3]
if (entry->rule.flags & AUDIT_FILTER_PREPEND) {[4]
list_add(&entry->rule.list,[5]
&audit_rules_list[entry->rule.listnr]);
list_add_rcu(&entry->list, list);
entry->rule.flags &= ~AUDIT_FILTER_PREPEND;
} else {
list_add_tail(&entry->rule.list,
&audit_rules_list[entry->rule.listnr]);
list_add_tail_rcu(&entry->list, list);
}
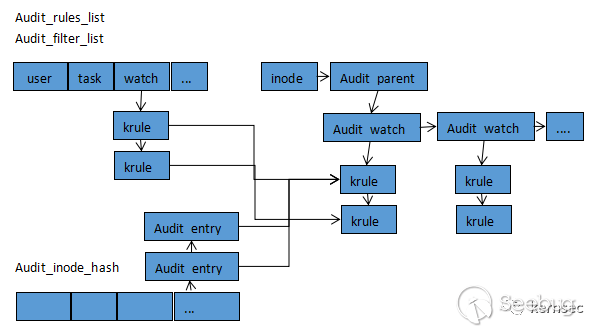
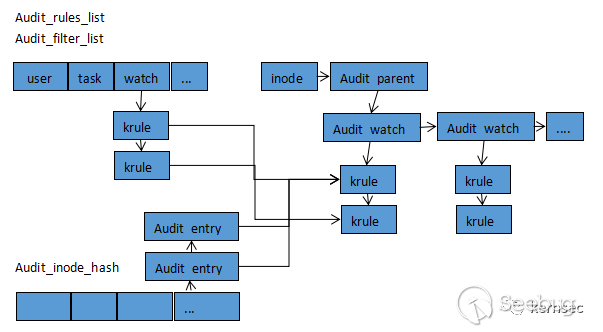
}内核维护以下几个关于规则的链表:
struct list_head audit_filter_list[AUDIT_NR_FILTERS];
static struct list_head audit_rules_list[AUDIT_NR_FILTERS];audit_filter_list数组保存的都是链表头,它们对应于不同过滤类型的链表,如之前所述的task、exit、user、exclude等审计入口用到的规则,在审计规则时用到。
audit_rules_list数组链表保存的是全部规则节点,仅在auditd -l获取所有规则列表时使用。
struct list_head audit_inode_hash[AUDIT_INODE_BUCKETS];
现在的aduit子系统不仅可以对系统调用号进行审计,还可以对文件进行监控,[2]处的操作就是解析auditctl -w指定要监控的文件路径。audit_inode_hash为一个针对inode过滤的哈希表,前面讲过struct filed结构体可以对inode进行审计,同时audit_add_watch也会对文件转化为inode, 插入到audit_inode_hash哈希链表中。
这些数据结构之间的关系图为:
2.3 内核审计入口
Audit子系统的审计入口最初来自于系统调用的入口,后面在支持了对文件监控的功能后,审计入口还被加入到了文件系统某些接口里。同时在进程创建的时候也会对其进行审计。所以在linux的man手册中,auditctl有如下入口列表:
Task - 进程创建时进行审计
Exit - 系统调用结束时进行审计
User - 来自用户态自定义的内核日志
Exclude - 在日志记录前进行审计
2.3.1 系统调用入口
以x86架构为例:
arch/x86/entry/common.c:
entry_SYSCALL_64()->do_syscall_64()
__visible void do_syscall_64(unsigned long nr, struct pt_regs *regs)
{
if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY)
nr = syscall_trace_enter(regs);[1]
regs->ax = sys_call_table[nr](regs);[2]
syscall_return_slowpath(regs);[3]
}在[1]出判断当前线程标志_TIF_WORK_SYSCALL_ENTRY是否被置位,如果是则调用 syscall_trace_enter进行系统调用审计前的准备。它则调用do_audit_syscall_entry()以及 __audit_syscall_entry进一步初始化:
kernel/auditsc.c:
void __audit_syscall_entry(int major, unsigned long a1, unsigned long a2,
unsigned long a3, unsigned long a4)
{
context->argv[0] = a1;
context->argv[1] = a2;
context->argv[2] = a3;
context->argv[3] = a4;
}注意每个进程的audit context结构是在进程fork时创建的,在这个路径里,只保存系统调用的前4个参数的内容。这个操作比较让笔者费解,为什么只记录前四个参数内容,按照X86的调用约定并且在系统调用处理程序开始时前六个参数无论是否存在,都已经保存在内核栈里了。如果参数是指针的话,那么保存的就是指针的值,在后面的日志输出时会打印出来,这里保存的是用户态的指针,不会泄露内核指针,所以不会有安全风险。
我们看到[1]处函数的作用只是保存了系统调用参数和设置context的一些值, 规则判断和将日志发送到日志队列里是在[2]处的系统调用完成之后的[3]处处理的。这里充分表达了audit子系统的任务是只做审计之用,不做拦截的操作,拦截的事情可以交给secomp去做,所以audit子系统不能代替secomp做沙箱功能。但是secomp有个弊端,使用的bpf规则不能动态更改,而audit却可以使用netlink协议实时更新,后续在我的AKSP内核自保护项目中会对audit进行改进,使其具备沙箱的能力。
[3] 处的syscall_slow_exit_work调用audit_syscall_exit做真正的过滤处理操作:
void __audit_syscall_exit(int success, long return_code)
{
audit_filter_syscall(current, context,
&audit_filter_list[AUDIT_FILTER_EXIT]);
audit_filter_inodes(current, context);
}可以看到audit_filter_syscall取的是audit_filter_list数组里AUDIT_FILTER_EXIT为索引的链表。
static enum audit_state audit_filter_syscall(struct task_struct *tsk,
struct audit_context *ctx,
struct list_head *list)
{
struct audit_entry *e;
enum audit_state state;
if (auditd_test_task(tsk))
return AUDIT_DISABLED;
rcu_read_lock();
list_for_each_entry_rcu(e, list, list) {
if (audit_in_mask(&e->rule, ctx->major) &&
audit_filter_rules(tsk, &e->rule, ctx, NULL,
&state, false)) {
rcu_read_unlock();
ctx->current_state = state;
return state;
}
}
rcu_read_unlock();
return AUDIT_BUILD_CONTEXT;
}auditd_test_task识别当前进程是否为auditd进程,linux audit子系统对auditd进程不做审计的。开始遍历每个audit_entry节点,audit_in_mask判断当前系统调用号是否为需要匹配的系统调用号,命中规则后,在继续调用audit_filter_rules做更进一步的规则匹配:
static int audit_filter_rules(struct task_struct *tsk,
struct audit_krule *rule,
struct audit_context *ctx,
struct audit_names *name,
enum audit_state *state,
bool task_creation)
{
for (i = 0; i < rule->field_count; i++) {
case AUDIT_UID:
result = audit_uid_comparator(cred->uid, f->op, f->uid);
case AUDIT_INODE:
if (name)
result = audit_comparator(name->ino, f->op, f->val);
else if (ctx) {
list_for_each_entry(n, &ctx->names_list, list) {
if (audit_comparator(n->ino, f->op, f->val)) {
++result;
break;
}
}
}
case AUDIT_WATCH:
if (name) {
result = audit_watch_compare(rule->watch,
name->ino,
name->dev);
}循环遍历rule的每个filed结构体,对其进行比较操作,比如对文件监控时,调用 audit_watch_compare进行比对:
int audit_watch_compare(struct audit_watch *watch, unsigned long ino, dev_t dev)
{
return (watch->ino != AUDIT_INO_UNSET) &&
(watch->ino == ino) &&
(watch->dev == dev);
}注意对于inode的监控,audit子系统可以通过auditctl -F 单独对用户指定的一个inode节点做监控,也可以使用audit_filter_inodes做监控。
void audit_filter_inodes(struct task_struct *tsk, struct audit_context *ctx)
{
struct audit_names *n;
list_for_each_entry(n, &ctx->names_list, list) {
if (audit_filter_inode_name(tsk, n, ctx))
break;
}
}循环遍历一个struct audit_names类型的结构体链表。
struct audit_names {
struct list_head list; /* audit_context->names_list */
struct filename *name;
int name_len; /* number of chars to log */
bool hidden; /* don't log this record */
unsigned long ino;
dev_t dev;
umode_t mode;
kuid_t uid;
kgid_t gid;
dev_t rdev;
u32 osid;
struct audit_cap_data fcap;
unsigned int fcap_ver;
unsigned char type; /* record type */
/*
* This was an allocated audit_names and not from the array of
* names allocated in the task audit context. Thus this name
* should be freed on syscall exit.
*/
bool should_free;
};这个结构体的创建不是来自用户态,而是通过预埋的文件系统接口动态生成的。文件系统里很多对inode的操作会调用audit_inode和audit_inode_child来进行审计。
void __audit_inode(struct filename *name, const struct dentry *dentry,
unsigned int flags)
{
list_for_each_entry_rcu(e, list, list) {[1]
for (i = 0; i < e->rule.field_count; i++) {
struct audit_field *f = &e->rule.fields[i];
if (f->type == AUDIT_FSTYPE
&& audit_comparator(inode->i_sb->s_magic,
f->op, f->val)
&& e->rule.action == AUDIT_NEVER) {
rcu_read_unlock();
return;
}
}
}
n = audit_alloc_name(context, AUDIT_TYPE_UNKNOWN);[2]
}
static struct audit_names *audit_alloc_name(struct audit_context *context,
unsigned char type)
{
list_add_tail(&aname->list, &context->names_list);
}首先在[1]处遍历匹配现有的规则, 对于新生成的inode节点通过[2]分配 Struct audit_name结构并挂接到context->names_list链表中, 这就是前面看到对inode审计的数据来源。
2.3.2 进程建立入口
在fork进程时,copy_process()->audit_alloc调用audit_filter_task进行一次规则过滤操作:
kernel/auditsc.c:
static enum audit_state audit_filter_task(struct task_struct *tsk, char **key)
{
list_for_each_entry_rcu(e, &audit_filter_list[AUDIT_FILTER_TASK], list) {
if (audit_filter_rules(tsk, &e->rule, NULL, NULL,
&state, true)) {
if (state == AUDIT_RECORD_CONTEXT)
*key = kstrdup(e->rule.filterkey, GFP_ATOMIC);
rcu_read_unlock();
return state;
}
}
}可以看到内核正是从audit_filter_list数组选取的AUDIT_FILTER_TASK为索引的链表做过滤。
2.3.3 文件系统入口
在前面讲inode规则过滤时,讲到audit子系统在文件系统很多接口中预埋了audit hook接口,这些包括audit_inode和audit_inode_child。因为对于文件的监控,audit子系统目前不支持系统调用参数的解析,所以只能通过文件系统接口形式进行状态获取。
2.3.4 用户自定义入口
Audit子系统允许从用户态传递一个字符串,输出在内核日志中:
[root@localhost linux-5.6.7]# auditctl -m "wzt"
You have mail in /var/spool/mail/root
[root@localhost linux-5.6.7]# grep 'wzt' /var/log/audit/audit.log
type=USER msg=audit(1608786569.953:85791): pid=67638 uid=0 auid=0 ses=291 subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 msg='wzt exe="/usr/sbin/auditctl" hostname=? addr=? terminal=pts/17 res=success'笔者认为这个功能没有多大用处, 反而会带来一些潜在的安全问题,恶意软件进程可以杀死auditd进程,重新与netlink进行连接,这样可以向内核日志写入垃圾数据。
3 缺陷
3.1 设计缺陷
通过对audit子系统的全面分析,笔者发现了它的一些设计缺陷。
3.1.1 系统调用参数过滤不完整
只能记录系统调用的前四个参数内容,且只能为整型,不支持指针或结构体及其之间的嵌套定义。 不支持具体某个参数的过滤,比如open系统调用,只想过滤第2个参数是否为/etc/passwd,目前的audit子系统是做不到的。
3.1.2 系统调用过滤丢失
Audit在完成过滤操作后,会把日志发送到一个队列中,在这之前还有一个日志产生频率的检查:
struct audit_buffer *audit_log_start(struct audit_context *ctx, gfp_t gfp_mask,
int type)
{
if (audit_rate_check() && printk_ratelimit())
pr_warn("audit_backlog=%d > audit_backlog_limit=%d\n",
skb_queue_len(&audit_queue),
audit_backlog_limit);
audit_log_lost("backlog limit exceeded");
}audit_rate_check判断一秒内日志生成的数量是否大于audit_rate_limit, 如果大于这条日志就直接被忽略掉了,这样恶意软件可以使用一些tricky的手段绕过对关键系统调用的审计。
3.1.3 tty passwd审计
笔者认为这是一个奇葩的功能,auditd可以向内核要求记录tty关闭回显的信息,这样passwd的操作内容就会被记录下来,这难道不是一个后门功能吗?
static int audit_receive_msg(struct sk_buff *skb, struct nlmsghdr *nlh)
{
case AUDIT_TTY_SET: {
t = s.enabled | (-s.log_passwd & AUDIT_TTY_LOG_PASSWD);
t = xchg(¤t->signal->audit_tty, t);
}
}当current->signal->audit_tty被置位后,tty_audit_add_data()将会关闭回显的信息推送给audit子系统。
void tty_audit_add_data(struct tty_struct *tty, const void *data, size_t size)
{
if ((~audit_tty & AUDIT_TTY_LOG_PASSWD) && icanon && !L_ECHO(tty))
return;
do {
if (buf->valid == N_TTY_BUF_SIZE)
tty_audit_buf_push(buf);
} while (size != 0);
}下面我们来验证下这个可怕的功能:
修改/etc/pam.d/password-auth和/etc/pam.d/system-auth文件,加入:
session required pam_tty_audit.so disable=* enable=root log_passwd新开启一个终端,然后输入以下命令:
[root@localhost ~]# passwd test
Changing password for user test.
New password:
[root@localhost ~]# aureport --tty
TTY Report
===============================================
# date time event auid term sess comm data
===============================================
5. 12/23/2020 21:41:42 88650 0 pts21 4405 bash "ls",<ret>
6. 12/23/2020 21:41:45 88659 0 ? 4405 ? "passwd test"
7. 12/23/2020 21:41:43 88654 0 pts21 4405 bash <ret>
8. 12/23/2020 21:41:43 88656 0 pts21 4405 bash <ret>
9. 12/23/2020 21:41:43 88652 0 pts21 4405 bash <ret>
10. 12/23/2020 21:41:45 88658 0 pts21 4405 bash "passwd test",<ret>
11. 12/23/2020 21:41:45 88685 0 pts21 4405 passwd "123456",<nl>
12. 12/23/2020 21:41:47 88687 0 pts21 4405 passwd "123456",<nl>
20. 12/23/2020 21:41:51 88727 0 pts21 4405 bash <ret>
21. 12/23/2020 21:41:56 88730 0 ? 4405 ? "aureport --tty"
22. 12/23/2020 21:41:56 88729 0 pts21 4405 bash "aure",<tab>,"--tty",<ret>3.2 关闭audit审计功能
对于rootkit或exploit,要想在系统中完美的规避主机HIPS的检测,需要关闭audit子系统,以下为笔者总结的方法:
A、 Struct audit_context ctx; Ctx->current_state = AUDIT_DISABLED 或者ctx = NULL
B、 Struct audit_krule = rule; rule->prio = 0
C、 Audit_enabled = 0; audit_ever_enabled = 0
D、 Clear_tsk_thread_flag(tsk, TIF_SYSCALL_AUDIT)
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1594/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1594/
如有侵权请联系:admin#unsafe.sh