2021-05-28 00:38:49 Author: infosecwriteups.com(查看原文) 阅读量:148 收藏
![]()
Hello fellow hunters, I hope you all are doing good and learning new things daily :). I am writing today about a lab/mission I solved by @albinowax.
This time I picked learning web cache poisoning in deep, so what better place than portswigger to start & and I just started with the first research paper James(albinowax) have released on this.
I didn’t even finished this topic completely but after reading this paper there is a challenge in end. After completion, I was like I gotta write about this. This thing is dope!
Disclaimer: After reading this you might think that you didn’t learn anything from it. Good, You are not meant to learn from this blog. I want you to go learn about Web cache poisoning on your own, then solve this challenge on your own and if get stuck then use this guide.
Anyway you are more than welcome to continue reading
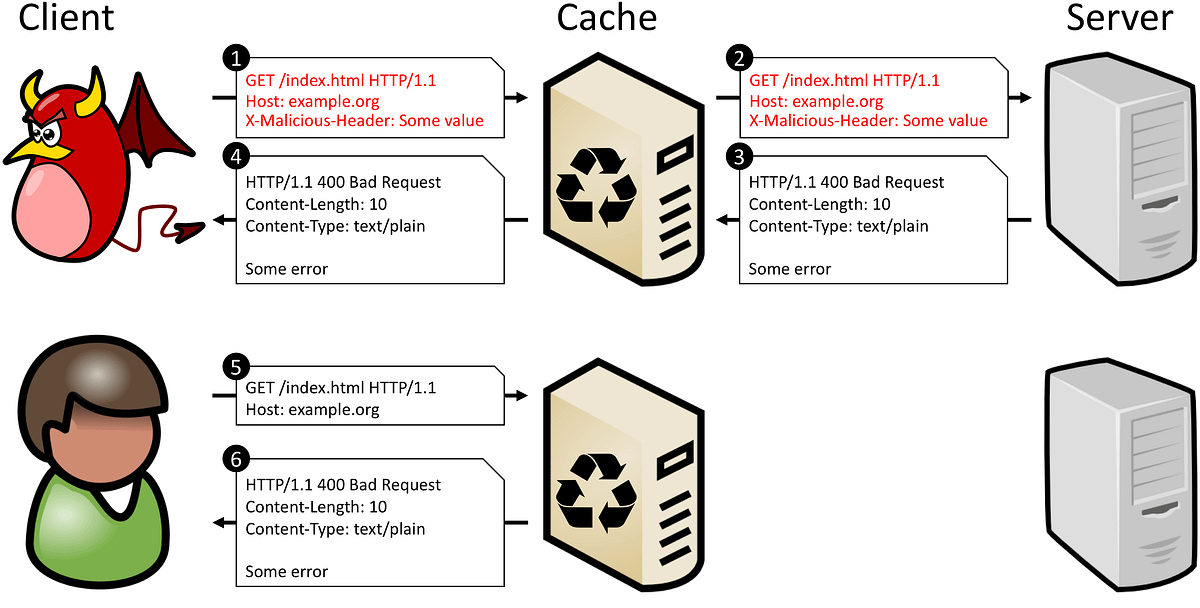
What is web cache poisoning?

To understand this you need to understand that what is cache and how it works?
Now when you query something in your browser, what happens is your browser first looks in the local cache for the same request if not then forward it to the DNS server, similarly, it also looks in its local cache if someone else has requested the same content, if not then it forward the request to the corresponding server. Now, these servers don’t directly talk to you they also have a cache server sitting between the client and backend. Now this cache server will determine if it needs to forward the request to the main server and it already has a copy of your request. If not then your response will be saved again for future references.
Responses will be served to you as well as saved in each level cache.
- Your Browser cache is a local cache
- DNS level cache is DNS cache
- The application-level cache is one made by the server.
so, when we talk about web cache poisoning don’t confuse it with local or DNS cache. Our goal is to pollute the cache of the main server so that malicious content can be served to legit users who query the same request as ours.
I would suggest you go through this research paper or portswigger content to learn how it works. I promise you there is everything you need to know about cache poisoning. How does the server decide two requests are the same? How to mitigate these issues? How to find and exploit it? Maybe I will release a detailed blog about it later. But this one is about the challenge solution.
Mission:
Now the goal was to serve the content of analytics.hackxor.net on transparency.hackxor.net/contact page.
param miner is a burp extension used to brute force headers that have some kind of effect in application response. You can install it from BApp store.
After bruteforcing headers on transparency.hackxor.net/contact page we find that it supports X-original-Original Header. This means that this header can override the requested path.
GET /admin HTTP/1.1
Host: unity.comHTTP/1.1 403 Forbidden
…
Access is denied
— — — — — — —
GET /anything HTTP/1.1
Host: unity.com
XOriginalURL: /adminHTTP/1.1 200 OK
…
Please log in
so which means that we can if we request
GET /contact HTTP/1.1
Host: transperncy.hackxor.net
User-Agent: Mozilla/…..
Referer: https://hackxor.net/
Connection: close
Cookie: ………..
X-original-url: /anything
It will not give a response for transparency.hackxor.net/contact but transparency.hackxor.net/anything page. which will give obviously 404 because /anything doesn’t exist.
so we got our first hint that if we query /contact with x-original-url header the response of this new path would be cached in the server’s cache.
Now after a little back&forth we will find a page transparency.hackxor.net/blog . looking in it’s source code we see that it fetches a logo.png from transparency.hackxor.net.
<img src="https://transparency.hackxor.net/static/logo.png"/>so we got our thing that querying /contact page with x-original-url: /blog will cache the response of /blog page in /contact page. Because the server has determined that whenever someone queries /contact page on host transparency.hackxor.net it is the same request as before in its cache.
So our host is getting reflected in our /blog page response. So what time it is? it’s param-mining time.
Running this gives a header that is supported by /blog page and that is x-host header. Now in this challenge X-Host is overriding the Host header.
So, requesting /blog with
GET /blog HTTP/1.1
Host: transparency.hackxor.net
X-Host: analytics.hackxor.net
It gives back a response with the new host in logo fetching.
<img src="https://analytics.hackxor.net/static/logo.png"/>{kind=link}
Now we got all the ingredients we need
Let’s chain these two unkeyed inputs(Headers which affect the reponse but doesn’t taken care by server while caching )
- We will make a request to /contact on host : transparency.hackxor.net, so that our malicious response will be served to users with same path and Host.
- We will override the /contact path with X-original-URL : /blog. So response gives back response of /blog page instead of contact.
Now this response contains a url to fetch a logo with host : transparency.hackxor.net,
3. we will change that host to analytics.hackxor.net using X-host header
4. so final response will contain content of /blog page with analytics.hackxor.net host
Final Payload looks like.
GET /contact HTTP/1.1
Host: transparency.hackxor.net
X-Host: analytics.hackxor.net
X-Original-URL: /blog
Now it is crucial to note when you send a request to server it will notice that it’s the same path as its in cache so it will reply with its cache. you are not actually communicating with server. so in order to poison the cache you have to wait till the server’s cache expires. and then send your malicious request to server so server will save your response in its cache. It more like a race against time. one solution is to do it repeatedly or make a while loop of curl requests with your payload.
Cache-Control: public; max-age: 60;
Age: 4
You can see in response that how long cache will take to expire i.e 60 and you are currently at 4, wait till 60 and then send your request.
After your response gets cached you will notice that /contact is serving the content of /blog that too with different host.
Mission accomplished.
Ps: Try this once yourself.
This was a walk through of chaining two unkeyed headers for cache poisoning, while giving essential notes on web cache poisoning. Anyway you are more than welcome to ping me on twitter if stuck anywhere. @Avinashkroy
如有侵权请联系:admin#unsafe.sh