
想了好久的题目,不知道该用什么样的标题去吸引人,webshell的检测研究已经有很多文章披露了,在兜哥的机器学习书中也被反复作为案例提及,这里Webshell检测都是基于文件特征的,并不是基于流量特征的检测。
在查阅了大量论文研究和实际案例后发现国内在webshell检测上的思路似乎没有什么新的突破,总结下来Webshell检测其实无外乎统计学检测、基于黑白名单的检测、基于opcode的机器学习研究,这中间也看到部分闪光点,比如说基于抽象语法树的命令执行节点截取、基于抽象语法树的评分规则、基于关联规则分析(看了一个星期的关联算法,自己实践结果惨不忍睹)等。
统计学检测:主要是指通过neopi来统计文件的熵值、重合指数、最长字符串、文件压缩比和特征库匹配来评判文件是否为webshell,但是经过实践后发现这种方法应该只能适用于大马和加密马,对于小马和一句话木马,这几类特征很不明显,拿这个特征来做结果非常糟糕。
基于opcode:这里我觉得参照兜哥的文章(传送门)比较好,一句话总结就是使用opcode的序列来建立词袋模型,最终对这个词袋模型进行训练和测试。
但是这里的检测方法笔者感觉范化能力还不够强,Webshell主要分为大马、小马、一句话木马,这三类类型说实话文件特征其实都不太一样,所以想要用一个模型去兼容三类文件的检测,其实不是一件容易的事。
这里使用机器学习的模型来作为检测算法,主要原因有1)机器学习的模型范化能力较强,能够通过学习来检测上述三类文件2)相较传统检测方法,机器学习的算法模型较为统一,使用起来较为简便(笔者并不是专门研究算法的,只是在当前场景下机器学习算法更为适用,所以就用了)
对于抽象语法树,如果做过自动化代码审计的同学就一定知道,如果想要构建CFG图一般都要以抽象语法树作为根基,这个抽象语法树其实就是代码的另一种结构体,它会将代码转化为一棵树,这棵树上存放的就是父亲节点是语法结构,孩子节点是具体的语法类型或是语义参数。
以“$data = eval('111');”为例,这里其实就是一个赋值语句,所以根节点类型为Expression,表示这是一个等式语句,次节点为Assign,表示这是一个参数定义语句,最后就是各参数的节点类型,比如说Variable,表示参数名,这里的eval函数其实有点特殊,如果是一般函数,可能就是FunCall节点类型,不过这里为Eval,最后就是参数类型String_
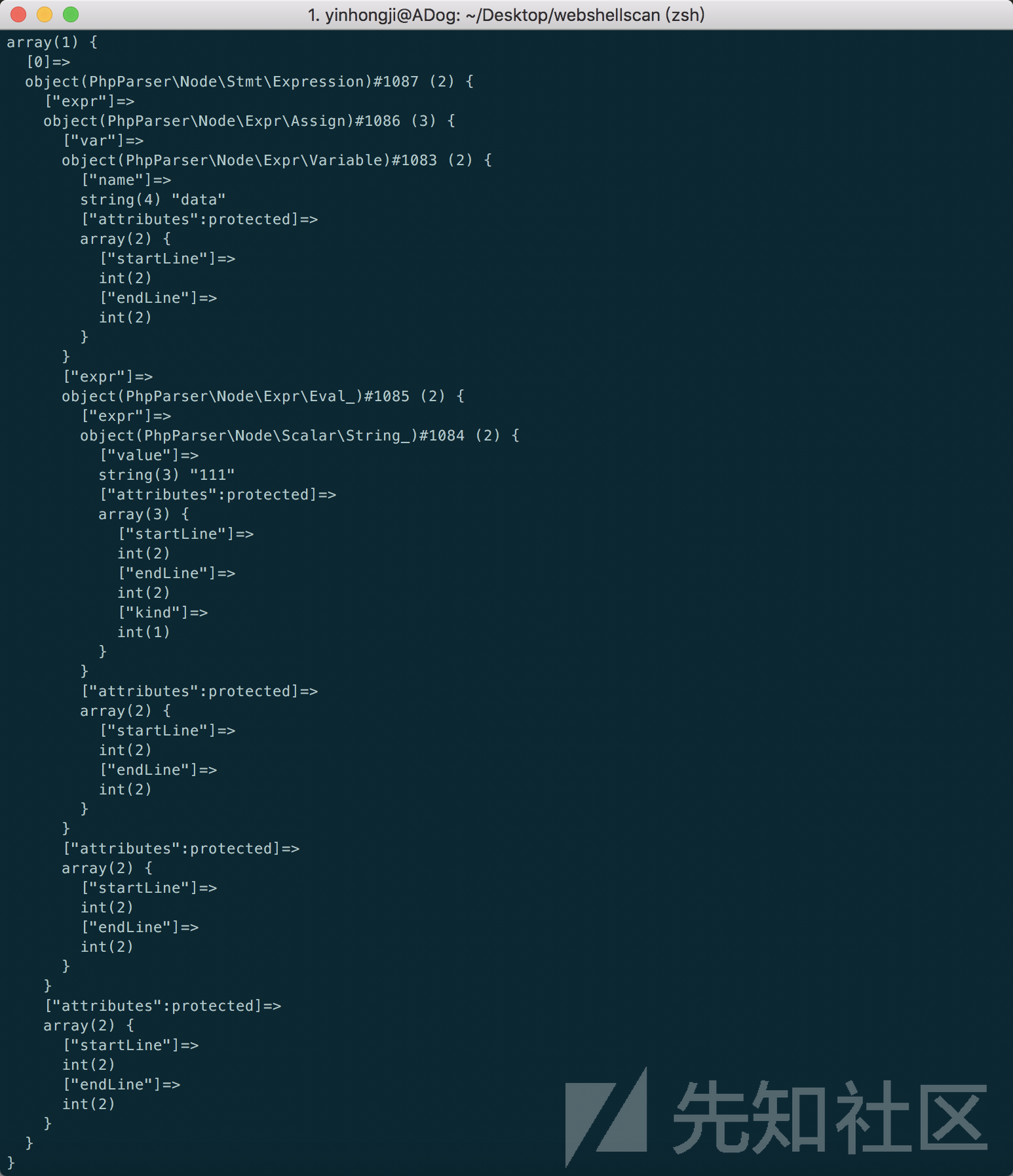
机器学习最重要的就是特征选择,这里借鉴了前人的思想,以及自己在自动化代码审计上的一些实践经验,选取抽象语法树来作为学习特征。笔者认为如果想要做到深度检测,那么一定要从源码出发,那么对源码进行编译比较好的方式一就是opcode,利用php插件来获取opcode序列。
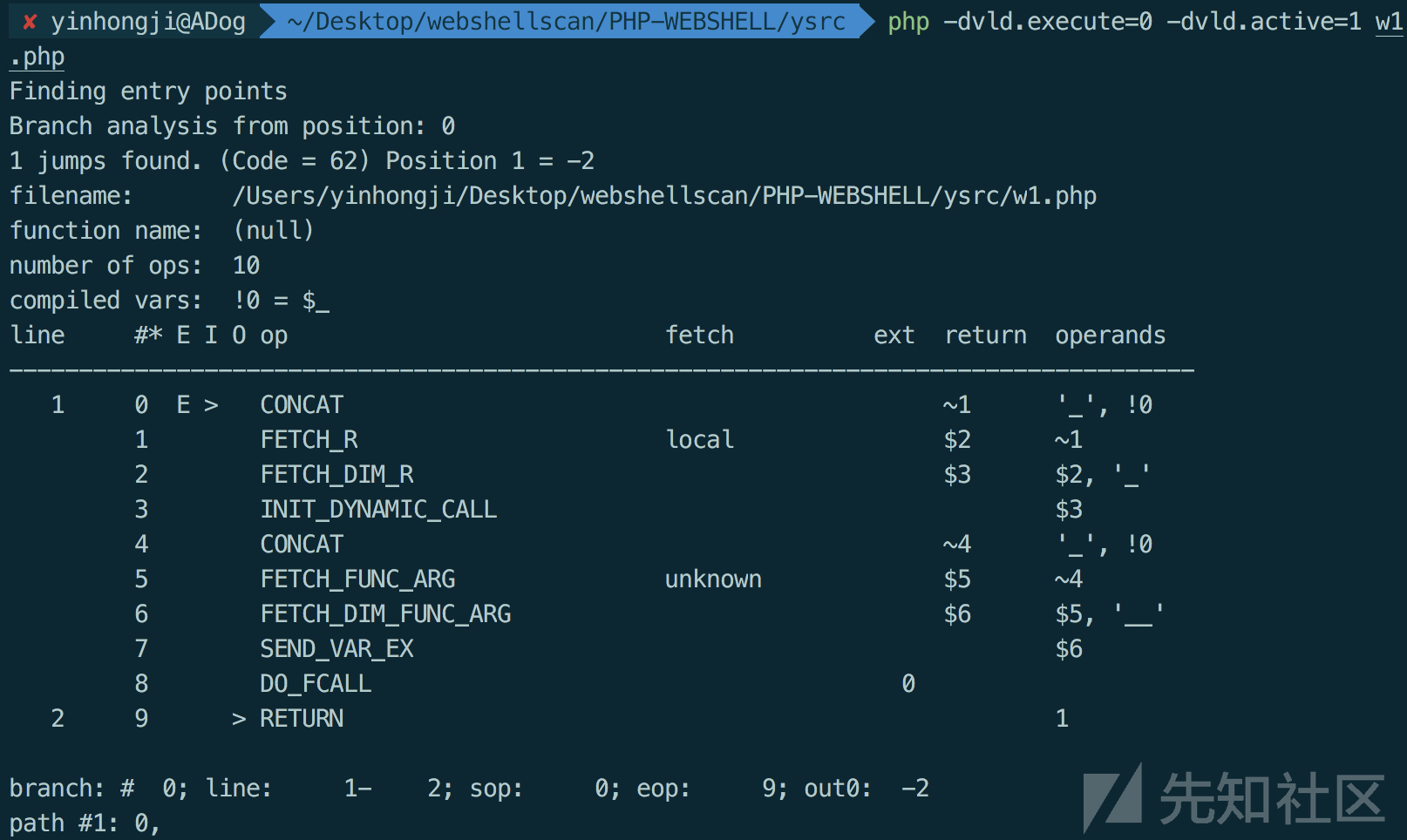
二就是如果使用抽象语法树来获取文件结构特征,会不会也是一种比较好的思路?因为抽象语法树和opcode在某种程度都能反映文件的结构特征和语义特征,所以在检测模型上可以说其实并无差异,但是相较于opcode,抽象语法树的通用性我觉得是必须要认可的,如果现在换一种语言,比如说c或者java,我们同样想要去检测恶意文件,c的话比如说是提权脚本,java的话则是java webshell(这一块目前正在做,就是数据集少的有点可怜),那么我们其实都可以使用本文方法来做检测,所以在通用性上笔者认为AST其实更胜一筹。
这里我使用PHP-Parser来提取抽象语法树,通过编写抽取规则,将php代码转化为抽象语法树的节点结构和语义参数,这里可能没有提到数据清洗,在实践过程中发现无论是opcode还是ast,对于PHP的另一种文件标识符"<?"无法识别,导致最终结果只有一个string类型,所以数据清洗阶段主要就是在遇到"<?"标识符重构php代码。
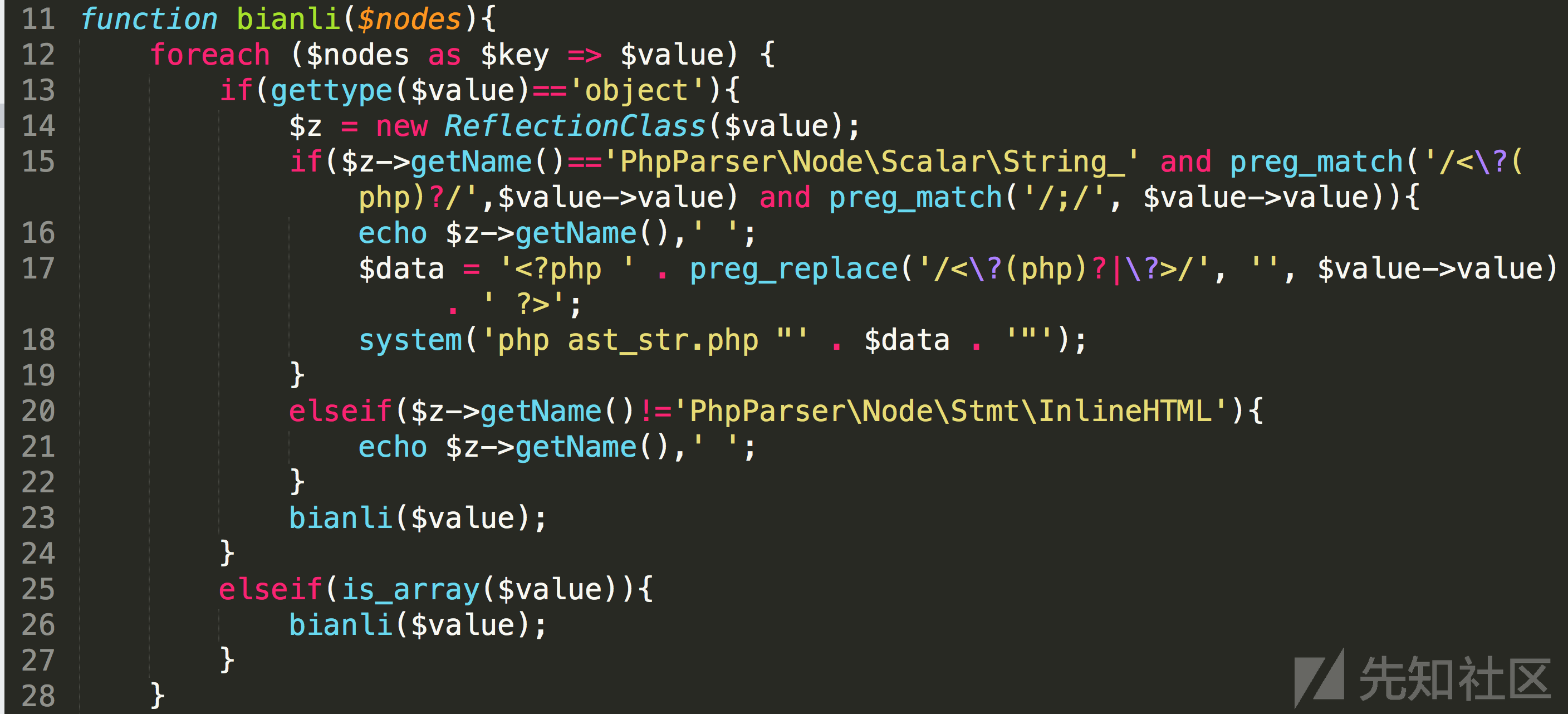
这里利用了反射来获取一个ast对象的名称,同时对参数语义做了一定的识别,这里识别规则写的很简单,当出现"<?"和";"符号的时候,判定此处存在php代码,那么交给另一个文件做php文件的规则补齐,继续对该文件进行ast的提取,这里做的主要理由就是当遇到如file_put_contents或者eval这种能够执行php语句的函数,里面的参数其实也会引起歧义,所以这里对参数作进一步处理,实现了简单的参数语义识别。

到这里特征工程其实就已经构建完毕,后续使用tfidf来对输出的AST来构建词袋模型。
在谈算法模型前,可能要提及的就是数据集,比较关心的就是有没有统一的数据集?这里我都是通过github进行搜索非同源仓库,但是其中的代码相似度也没有去做检查,最终搜集到的有效的webshell样本为2563个,而白样本则都是开源的cms,有效样本数为7230个,这里一开始对白样本的选取比较关注一些国际通用的cms,比如wordpress、phpmyadmin等,但是实际测试测试并不如人意,后来推测由于白样本都是偏框架类型的源码,在进行学习的时候特征维度和黑样本特征维度其实有很大偏差,所以后续加入了一些比较老版本的cms,这类cms都是贴近php原生环境的代码,这么做也是想要提高检测的范化能力。

都是以github用户名命名的,有心者可以去搜搜看
白样本的选择就比较随意了,老的新的,带框架不带框架的都包含进来了。
回到算法选取其实没什么好讲的,随机森林、xgboost和深度学习都来一套,然后进行调参进行横向比较,这个没什么好说的。最终检测率较好的就是xgboost和mlp算法。
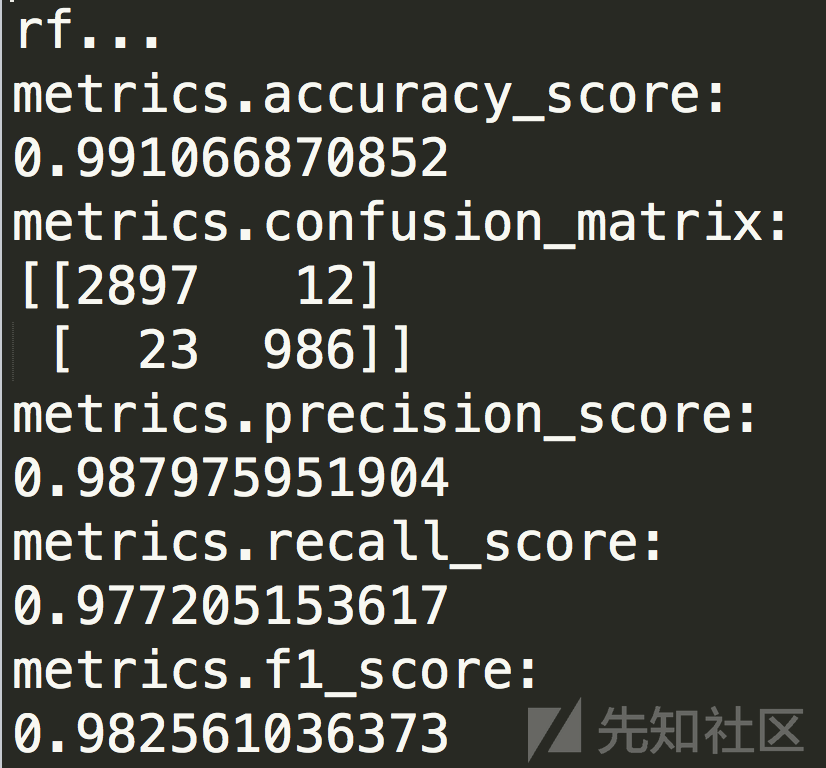
使用随机森林算法准确率可以达到99.10%,不过离实际落地感觉还有很大的差距。
看了那么多篇论文,基本上有效数据量都不超过2000,检测成功率几乎都在95%以上,但是这个检测率看看就好,如果想要落地,还是有很多webshell变种没有考虑进去的,如果想要真的落地,webshell的样本积累量可能要达到一个新的高度(个人能力有限,只能github搜),写这么多也只是想提供一个新的解决思路(目前没看到有人提出用ast来实现webshell检测)以及其他ast能够应用的场景。
上述如有不当之处,敬请指出~
如有侵权请联系:admin#unsafe.sh