前言
攻防演练里最重要的环节莫过于信息收集,熟话说,要想打点打得好,信息收集少不了。
在各大公司招兵买马之际,各位师傅也来查缺补漏,信息收集你真的都会了嘛?
搜索引擎
这里我们使用fofa来举例,为什么使用fofa来举例呢,不是因为fofa有多好(真香),是因为咱只买了fofa的会员。fofa既可以搜索到部分子域名,也可以搜索到目标的各种系统,如OA、后台等等,而这些系统很容易成为突破口。
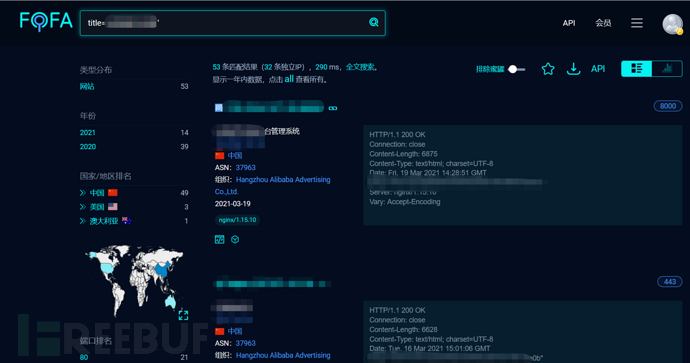
首页有参考的fofa语法,可以根据需要构造搜索语句
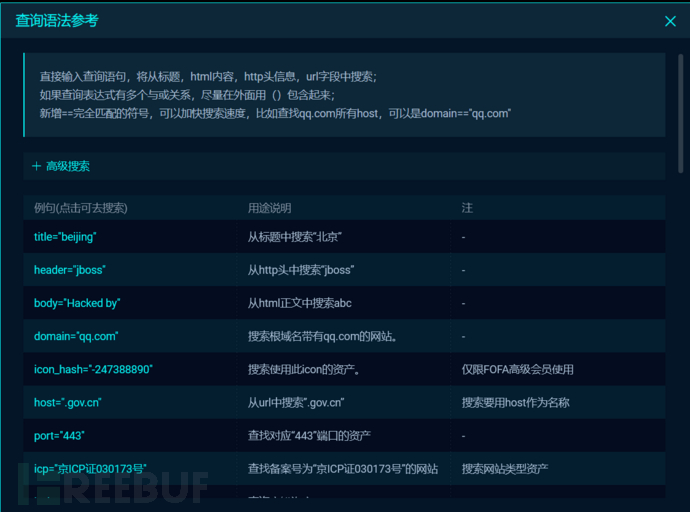
fofa语句
推荐几个常用的
title="目标名称" && region="xx省" title="目标名称" && city="xx市" cert="目标域名或者证书关键字" && region="xx省" cert="目标域名或者证书关键字" && city="xx市" ((title="目标名称" || host="目标域名") && country="CN") && region!="HK"
需要注意的是fofa语句不是一成不变的,同一个目标单位的查询关键词可能有好几个,同时在信息收集的过程中也可能发现新的关键词,比如备案号、传真、客服电话等,这些东西往往是唯一的。搜索别人没有搜的关键词就可能发现别人没发现的资产,就可能拿到别人没拿到的shell,需要灵活运用。
打不开的资产
fofa中可能搜到打不开但仍然属于目标单位的资产,可以先ping一下看看,如果能ping出IP说明服务器还存活,只是web服务没开,如果ping的是IP,可以扫全端口+C段,是域名且没有CDN的话也可以全端口+C段。

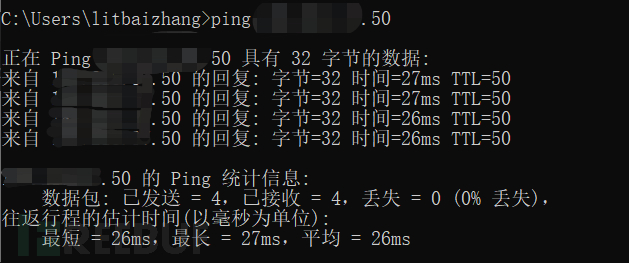
真实IP
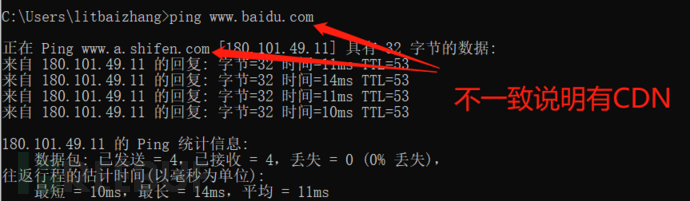
直接ping目标域名可判断是否有CDN
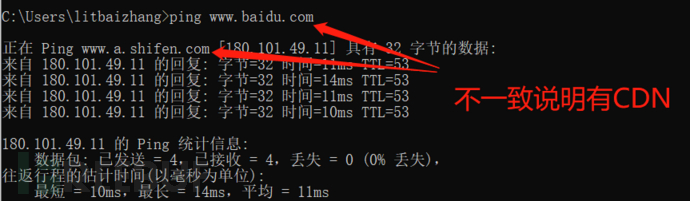
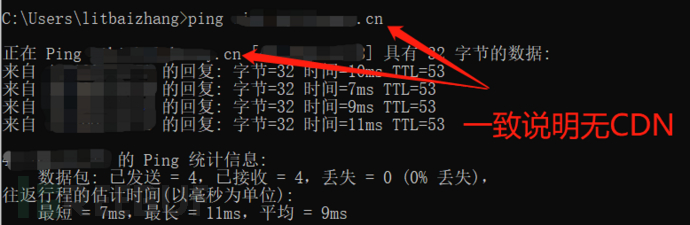
在有CDN的情况下,找真实IP的方法比较多,这里说几个比较快捷的
1.ping主域
如果是www开头的域名存在CDN,可以把www.去掉再ping,可能得到真实IP
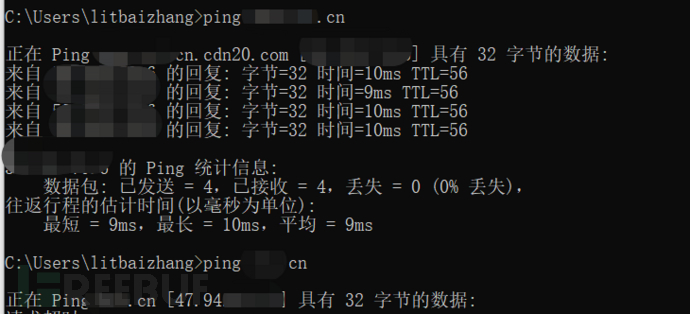
2.通过网站证书寻找真实IP
此方法适用于https的站点
首先获得网站证书序列号(不要挂代理)
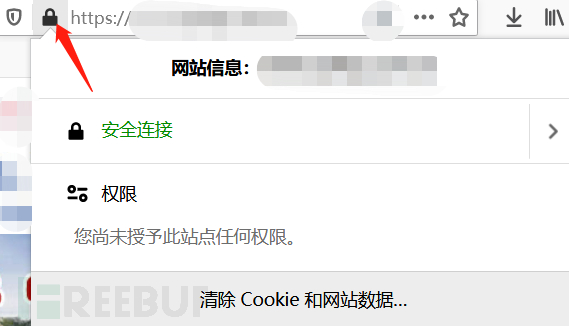
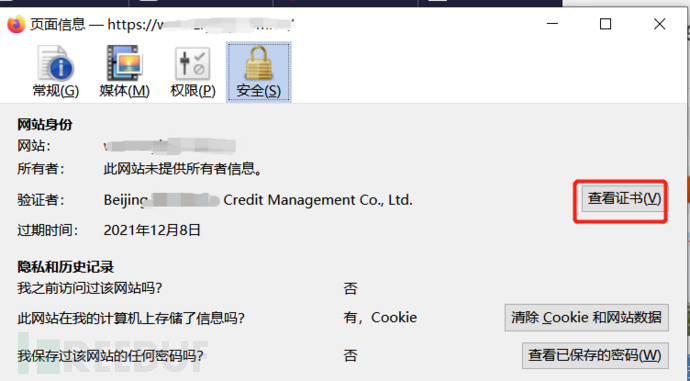
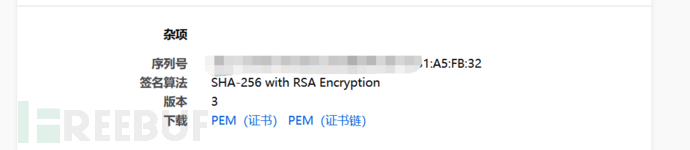
转换成十进制
https://tool.lu/hexconvert/
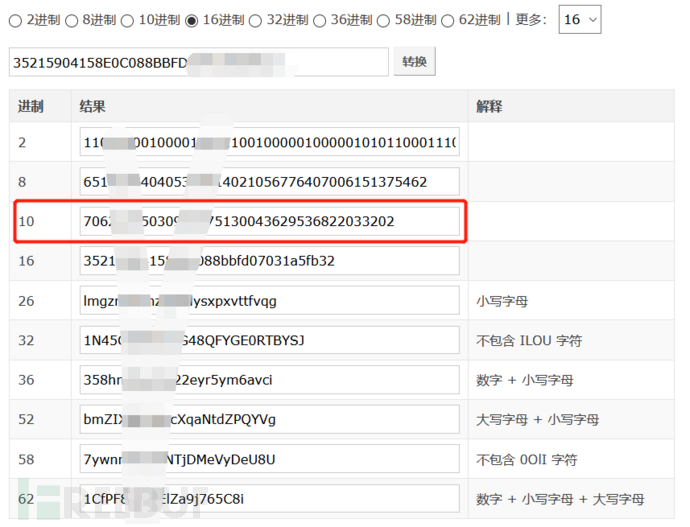
同样可以找到真实IP
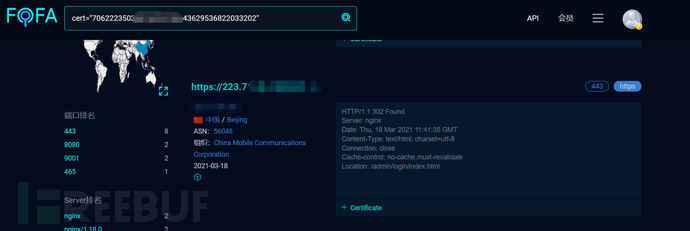
收集子域名
一般主站会有CDN,主站下子域名基本都是真实IP,收集子域名看IP就可以知道网站真实IP的C段了。
历史DNS记录
https://dnsdb.io/zh-cn/ ###DNS查询
https://x.threatbook.cn/ ###微步在线
http://toolbar.netcraft.com/site_report?url= ###在线域名信息查询
http://viewdns.info/ ###DNS、IP等查询
https://tools.ipip.net/cdn.php ###CDN查询IP
网站的注册,订阅,找回密码功能会发送邮件,邮件头信息会有真实IP
LTM解码法
当服务器使用F5 LTM做负载均衡时,通过对set-cookie关键字的解码真实ip也可被获取,例如:Set-Cookie:
BIGipServerpool_8.29_8030=487098378.24095.0000,先把第一小节的十进制数即487098378取出来,然后将其转为十六进制数1d08880a,接着从后至前,以此取四位数出来,也就是0a.88.08.1d,最后依次把他们转为十进制数10.136.8.29,也就是最后的真实ip。
C段扫描
获得目标真实IP后可以百度该IP看是不是云上资产
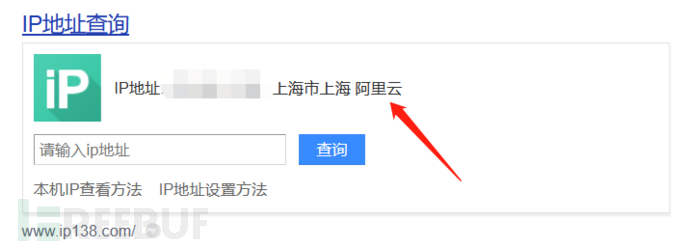
如果是阿里云或者腾讯云等云上资产的话扫C段容易出现扫C段扫出一大片东西,然而没有一个是目标资产的情况。不是云上资产的话就正常扫C段就可以。C段推荐灯塔和goby
天眼查
天眼查、企查查等查企业的软件也是非常重要的信息收集途径,每次攻防演练的目标名单中总有各种公司,有国企也有私企,其中的小型民营企业相比其他的政府、大型互联网企业、金融、电力等目标要好打得多,因此它们总是首要目标,而天眼查、企查查等作为查企业最牛逼的网站,其重要性也就不言而喻了。下面以天眼查为例介绍:
天眼查中共有3个地方可能出现目标的资产:
网址邮箱知识产权
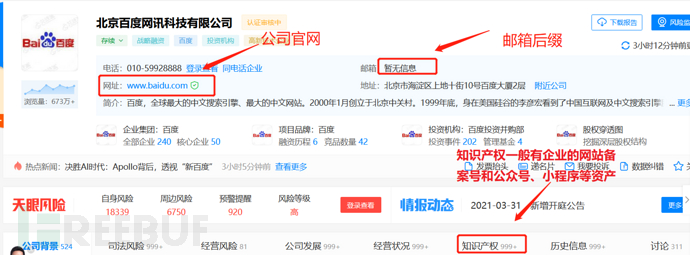
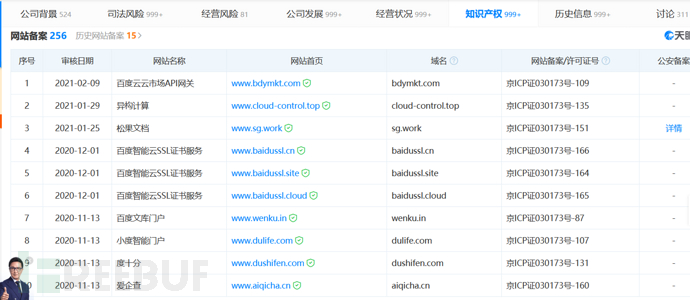
还有一处大家可能会忽略
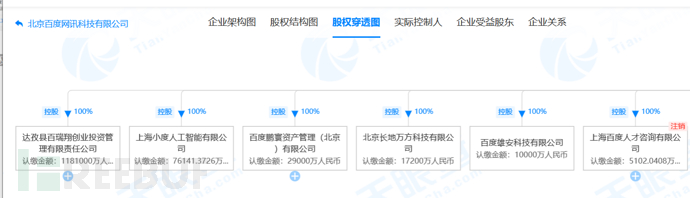
股权穿透图
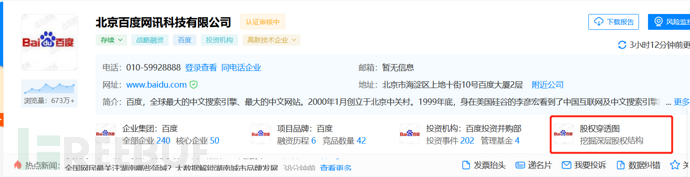
穿透图下有100%控股的全资子公司,如果攻防演练规则可以得分的情况下,子公司相对来说比较容易得分。
子域名
子域名收集推荐工具oneforall输出结果为csv格式,可以筛选返回值200的网站。
泛解析问题
域名泛解析是对抗子域名收集的一个方法。
泛解析这个问题的解决方法很简单,向DNS请求 * 记录,然后把枚举子域名回来的记录和*的记录比对,如果相同则直接排除。
DNS包的解析:https://www.davex.pw/2016/07/01/How-To-Fuzz-Sub-Domain/
端口
nmap
扫描的比较慢但是较准确
nmap -sS -v -sV -p 1-65535 IP # ping目标有回复时
nmap -sS -v -sV -p 1-65535 -Pn IP # ping目标没有回复时
可以在阿里云的vps上装nmap,用它来扫端口,一般1个IP全端口3-5分钟扫完
nmap扫得慢的话可以用
masscan
masscan -p 1-65535 --rate 1000 IP
敏感目录
工具:https://github.com/j3ers3/Dirscan
.git泄露
工具:https://github.com/denny0223/scrabble
工具:githacker https://github.com/WangYihang/GitHacker
在git泄露中也可能有其他有用的信息如在文件下.git/config文件下的access_token信息进而访问该用户的其他仓库。
SVN泄露
工具:seay-svn
dvcs-ripper
https://github.com/kost/dvcs-ripper
HG泄露
工具:https://github.com/kost/dvcs-ripper
备份文件
Test404网站备份文件扫描器 v2.0
邮箱收集脚本
#-*- coding:utf-8 -*-
import requests
import re
import sys
import os
from bs4 import BeautifulSoup
#定义 header 数据
def headers(referer):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip,deflate',
'Referer': referer
}
return headers
#爬取bing搜索引擎数据
def bing_search(url,page,key_word):
referer = "http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsite%3abaidu.com&first=1&FORM=PERE1"
conn = requests.session() #保持会话
bing_url = "http://cn.bing.com/search?q=" + key_word + "+site%3a" + url + "&qs=n&sp=-1&pq=" + key_word + "site%3a" + url + "&first=" + str((page-1)*10) + "&FORM=PERE1" #设定接口
conn.get('http://cn.bing.com', headers=headers(referer)) #发起请求
r = conn.get(bing_url, stream=True, headers=headers(referer), timeout=8) #获取返回内容
emails = re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+",r.text,re.I) #晒选出目标邮箱
return emails
#爬取百度搜索引擎数据
def baidu_search(url,page,key_word):
email_list = []
emails = []
referer = "https://www.baidu.com/s?wd=email+site%3Abaidu.com&pn=1"
baidu_url = "https://www.baidu.com/s?wd="+key_word+"+site%3A"+url+"&pn="+str((page-1)*10)
conn = requests.session() #保持会话
conn.get(referer,headers=headers(referer))
r = conn.get(baidu_url, headers=headers(referer))
soup = BeautifulSoup(r.text, 'lxml') #解析网页中的元素
tagh3 = soup.find_all('h3') #查找标签
for h3 in tagh3:
href = h3.find('a').get('href')
try:
r = requests.get(href, headers=headers(referer),timeout=8)
emails = re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+",r.text,re.I)
except Exception as e:
pass
for email in emails:
email_list.append(email)
return email_list
if __name__ == '__main__':
#获取总数据并去重用
email_slit = []
email_slits = []
try:
url = sys.argv[1]
page = sys.argv[2]
key_words = ['email', 'mail', 'mailbox', '邮件', '邮箱', 'postbox']
print('开始收集邮箱请耐心等待:')
for key in key_words:
bing = bing_search(url,int(page),key)
baidu = baidu_search(url,int(page),key)
email = bing + baidu
email_slit = email + email_slit
for slit in email_slit: #做个去重处理
if slit not in email_slits:
email_slits.append(slit)
print(email_slits)
file_path = os.path.dirname(__file__) + "/" + url + ".txt" # 在当前目录创建文件,保存结果
fp = open(file_path, 'w', encoding='utf-8')
for i in email_slits:
fp.write(i + "\n")
print('------------------------------------------------')
print('[+]扫描结束,结果保存至当前目录下,文件名:url.txt')
except Exception as ree:
print('''使用命令:python3 email.py [url] [页数]''')
如有侵权请联系:admin#unsafe.sh