Since the release of Browser powered scanning back in Burp 2021-03-22 23:29:00 Author: portswigger.net(查看原文) 阅读量:219 收藏

Since the release of Browser powered scanning back in Burp Suite Professional 2020.8.1 we have had a lot of customers asking us about our motivation for choosing to integrate with Chromium and for more information about how the feature works.
In this post I aim to drill into some of the technical challenges we faced when building this feature, share some details about how the integration works under the hood and highlight a few of the cool features we plan to build in the coming year.
Finding the attack surface
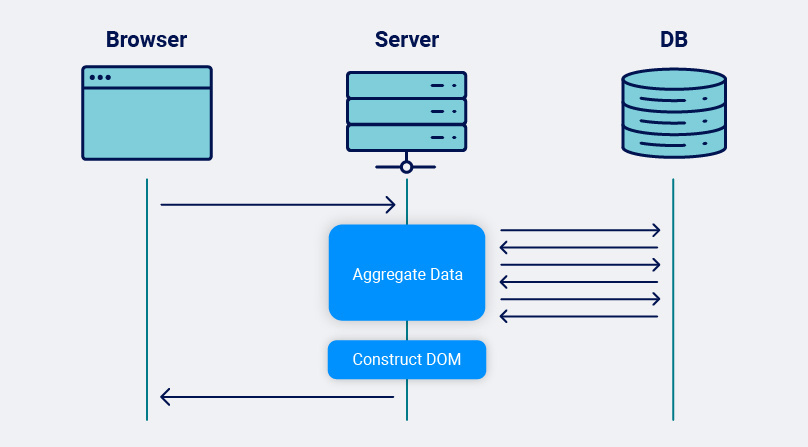
15 years ago, back when Netscape Navigator was still a thing, the web was largely synchronous. A single HTTP request would usually result in an HTML response containing all the outgoing links, and once the response was sent to the client it very rarely changed. With this model, finding and mapping the attack surface was relatively easy as each location in the application usually mapped to a single HTTP request and response. As the DOM was usually fully constructed on the server side, finding new locations to visit was as simple as scraping all the links from the DOM and adding them to a list to visit in the future.
Along comes XHR, AJAX & microservices
As client computing power increases and web browsers gain an ever richer feature set, coupled with the introduction of XmlHttpRequest (XHR) and the Asynchronous JavaScript and XML (AJAX) pattern of building web applications, more and more of the responsibility for constructing the DOM has been pushed into the browser. The prevalence of microservices is yet another push towards browser-based construction.
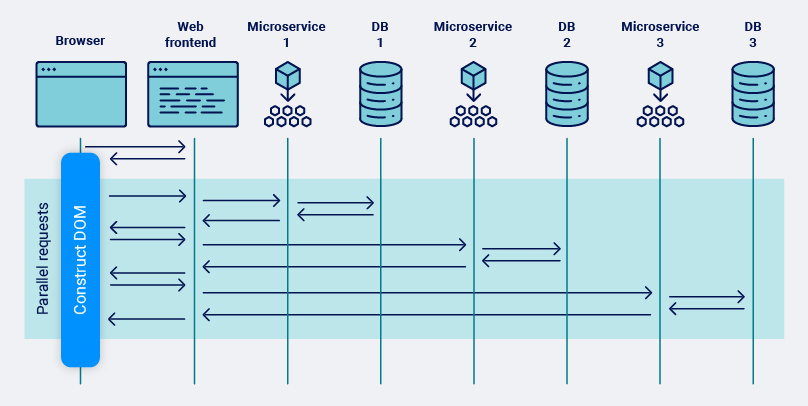

Whilst this trend has been transformational in making web-applications responsive and feel like first-class modern applications it introduces significant challenges when automatically trying to discover the attack surface. As mentioned previously, in traditional web architecture the attack surface was primarily limited to the main document HTTP requests. In the new world, the attack surface is decomposed and spread out over all of the individual API calls and client-side JavaScript, making it much harder to find.
How does this shift impact writing a crawler?
One of the main guiding principles behind Burp’s new crawler is that we should always attempt to navigate around the web applications behaving as much as possible like a human user.. This means only clicking on links that can actually be seen in the DOM and strictly following the navigational paths around the application (not randomly jumping from page to page).Before we had browser-powered scanning, the crawler (and the old spider) essentially pretended to be a web browser. It was responsible for constructing the requests that are sent to the server, parsing the HTML in the responses, and looking for new links that could be followed in the raw response we observed being sent to the client. This model worked well in the Web 1.0 world, where generally the DOM would be fully constructed on the server before being sent over the wire to the browser. You could be fairly certain that the DOM observed in an HTTP response was almost exactly as it would be displayed in the browser. As such, it was relatively easy to observe all the possible new links that could be followed from there.Things start to break down with this approach in the modern world. Often the main HTML document returned when navigating to an application is a simple container, waiting for some JavaScript to run to populate the DOM - as shown in the example below.
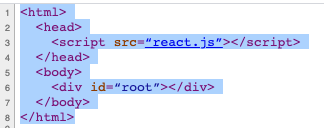
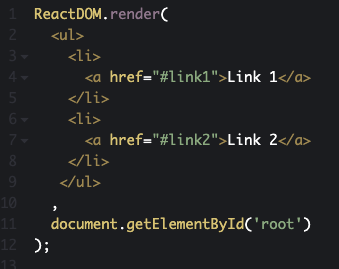
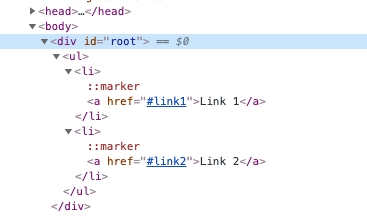
Before browser powered scanning, web crawlers would generally just request the main document, parse the DOM, conclude that there are no links which could be followed, and treat this page as a dead-end. To correctly navigate around the simple example above several things need to happen. We must load the initial DOM, fetch the react.js script, execute the script, and wait for the new links to appear in the DOM.
What’s the fix?
We essentially had two choices on how we could solve this problem, we could either embed a JavaScript engine directly within the crawler and execute the script ourselves in an attempt to construct the DOM as a browser would, or we could leverage an existing browser to do the heavy lifting for us. Neither of these were easy choices but ultimately we chose to harness the power of Chromium, the open-source foundation on which the Google Chrome browser is built.
Why Chromium?
Chromium is the result of a massive development effort, much more than any company the size of PortSwigger could muster. The browser essentially defines the modern state of play in web technology, and linking Burp Suite to Chromium ensures that Burp is future-proofed against whatever the web can throw at us. Had we chosen the alternative we would be forever playing catchup supporting new web technologies with the small army of developers who develop Chromium and the many other libraries it is built upon. Not to mention the complexity of creating a JavaScript rendering engine that is not itself vulnerable to issues.
The Chromium codebase evolves at an alarming rate, as a smaller independent firm there was no way we would be able to keep up to date with all the new features being added - even Microsoft has admitted defeat in the browser wars and their latest incarnation of the Edge browser is essentially just a skin on top of Chromium.

Burp Suite’s Chromium integration
Integrating Chromium with Burp Suite was far from a trivial task. Embedding the browser directly into Burp didn't work: any browser crash would have also crashed Burp. The integration made the build process unacceptably complex. Security was also an issue: Burp needs to be secure, and applying security patches in a timely manner was next to impossible.
To address these drawbacks we came up with a different approach. We decided that instead of trying to embed the browser directly within Burp we would attempt to control it remotely using the DevTools protocol, this is the same technology that is used within Chromium's Inspector tab and can be used to control almost every aspect of the browser.
This approach simplified our build processes significantly. We can now automatically trigger new builds of our embedded browser immediately as they are released and can usually get them updated within Burp Suite the same day. We also regularly build the beta and development versions of Chromium so that we can get an early warning should there be any breaking changes to the DevTools protocol.
Browser Powered Scanning
Now that we could easily keep up to date with the latest stable builds of Chromium, we set about integrating it within the crawler. The DevTools Protocol itself was relatively simple to set up and connect to. It's made up of JSON commands which can be sent over a WebSocket to the browser, and response events about what the browser is doing: all familiar technology.
Our integration in Burp Scanner looks similar to this:
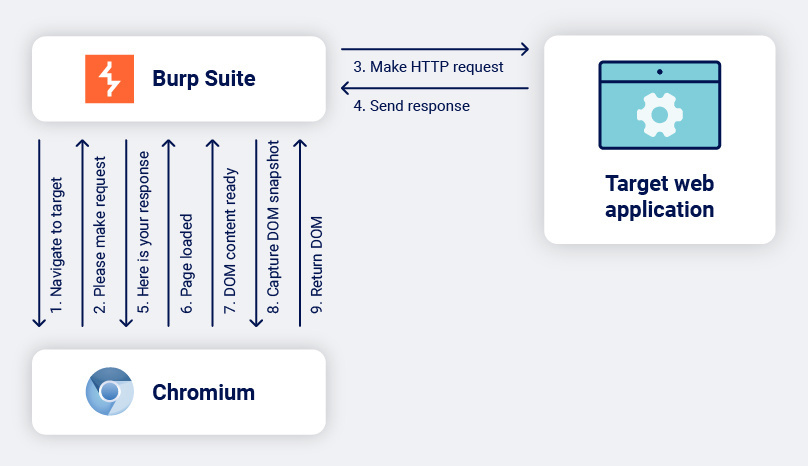
- Once we have started an instance of Chromium and connected to DevTools via the WebSocket we instruct the browser to navigate to the target web application.
- Chromium constructs the HTTP request it would make to the target and sends that back over the WebSocket to Burp Suite.
- The request is sent to the target via Burp Suite’s regular network stack, respecting scope and throttling rules as normal.
- Burp Suite receives its response.
- And passes it back over the WebSocket to Chromium.
Steps 2 to 4 repeat for all the resources loaded on the page. - Chromium tells us via the WebSocket that the page has fully loaded. (Roughly equivalent to the ‘onload’ DOM event).
- Chromium tells us via the WebSocket the DOM is ready. (Roughly equivalent to the DOMContentLoaded event).
- Once Burp Suite thinks that the DOM has settled down and is no longer mutating we ask via the WebSocket for a snapshot of the DOM. This is quite a simplification of what actually turned out to be a very challenging problem. I could probably fill an entire blog post talking about some of the issues we had here. As is common in software engineering, this was much more complex and took a lot longer than expected!
- Chromium returns the exact DOM which is currently being displayed in the browser to Burp.
Once we have a snapshot of the DOM, this is fed into the crawler and processed in the same way as a non browser-powered scan. When the crawler has decided the next link it wishes to follow the process repeats itself with one minor difference. Instead of instructing the browser to navigate to the next page (like typing a URL directly into the address bar) we use DevTools to simulate the user clicking on a link, this way we ensure that any onclick handlers are invoked before sending any requests to the target.
Next steps
Now that we have got the basics of the integration working, we are all genuinely excited about the possibilities this has opened up. We have ambitious plans to vastly improve our crawl and audit coverage for modern single page applications and API endpoints throughout 2021 as highlighted in our public roadmap. We are also hoping to further leverage the power of our browser integration with some new manual tools as well as continuing to blog some more about Burp Scanner features.
Find out more about Burp Scanner, and our JavaScript scanning capabilities.
如有侵权请联系:admin#unsafe.sh