

官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)通过数据引擎,对数据进行创建、查询、修改和删除的操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得数据库特定的功能。
作为数据库的支撑底盘,一个成熟的存储引擎必须要考虑各个方面,包括数据读写的效率,包括如何成本最低风险最小地运作,而TcaplusDB在考虑了以上这些因素后,结合我们是一个键值型数据库的特点,我们选择了腾讯完全自研的TXHDB存储引擎来落地TcaplusDB的数据。 下面介绍一下TXHDB存储引擎的格式和优势所在。
存储引擎格式
TcaplusDB的数据文件大致可以分为3个区,头部区、内存映射区和文件访问区,见下图。其中内存映射区和文件访问区是用于存放真实数据的。
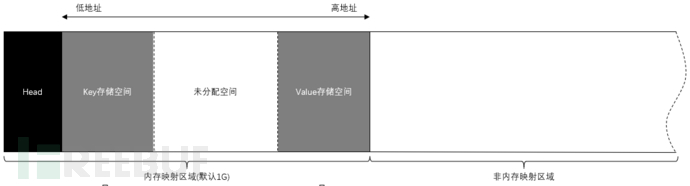
其中:
- 头部区,用于存放元数据、统计数据、Hash桶、空闲块链表头,扩展数据等信息。
- 内存映射区,这部分空间会在数据文件加载时,通过mmap的方式映射到内存地址空间中,使用读写内存的方式读写该区域,间接地达到缓存在内存中的效果。该区域位于数据文件的前部,默认大小为1G。
- 文件访问区,紧接着内存映射区后面就是所谓的文件访问区,该区域的数据读写通过普通的文件读写接口进行。
更详细的格式内容如下:
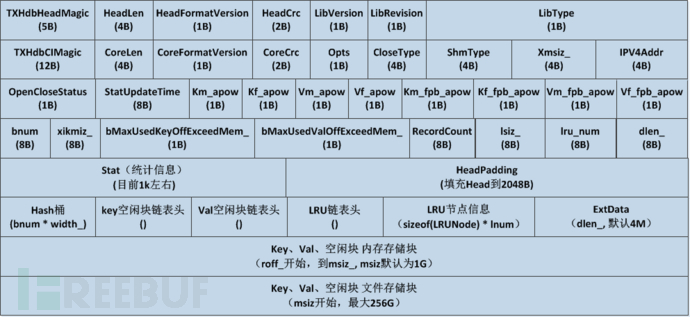
整个文件分为头部控制信息区和数据区域;
数据文件打开时,从文件最开始建立文件映射对象,对于写操作,至少将控制头部区域放入内存映射范围;
Key-value数据记录通过hash表进行组织,hash冲突解决策略有二叉平衡树和线性链两种,通过引擎文件创建时通过参数可以决定使用哪种冲突解决策略;二叉树平衡树通过对key计算另外一个hash值(称为二次hash)建立;
数据在mmap区域外时,对数据的访问通过基于文件起始位置的偏移,使用pread/pwrite来访问。
头部控制区域分为以下几个部分:
- 基本控制信息区:包含magic、版本信息、文件类型、记录对齐参数、空闲块参数、压缩属性、桶数、记录数、文件大小、首条记录位置、桶信息、空闲块信息等。
- Hash桶信息区:存储hash每个桶首条记录的存储偏移;
- 内存空闲链表头:此文件中处于mmap区域范围内的空闲数据块链表表头;
- 文件空闲块表头:mmap区域外空闲数据块链表的表头;
- LRU信息区域:跟踪mmap区域数据记录访问情况的LRU链;
- 扩展区域:对txhdb透明存储区域,tcapsvr通过此区域存储数据表描述信息;
空闲块管理
数据记录的大小不一,数据记录在存储过程中,大小改变或删除会导致文件中出现一些空闲块,为减少大小不一空闲块的整理利用的开销。TXHDB采用块空间来存储数据记录,块空间通过一个apow的参数设定其对齐方式,即通过apow定义数据块的最少大小;整个存储块由按照最小对齐单元进行逐层线性增长的块数组组成,数据块的级数通过fpow参数决定,如果apow为8,fpow为10,则空闲数据块起示意图如下:
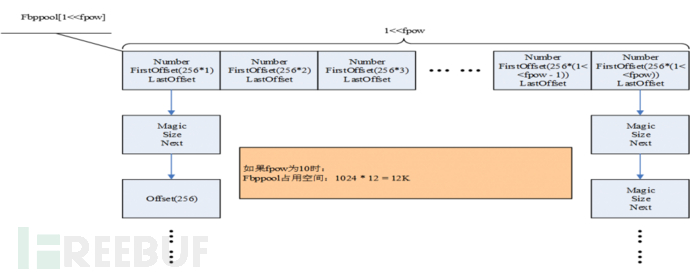
实际数据key或value通过某一级别的一个或多个空闲块来存储,空闲块分配原则:
- 优先使用内存空闲块,然后使用文件块
- 基于内存优先使用连续块,然后使用离散块
- 基于文件只能使用连续块
如果记录均为小记录,那么整个文件可能会存在过多的离散记录,可以通过数据搬迁整理的方式定期对数据做整理。
Key Value分离
基于HASH表存储数据记录,每个数据的读写都必须访问数据的Key,TXHDB采用Key-value分离的思路,优化数据检索效率,具体如下:
将Key和Value分离存储,分别存储到Key结点和Value结点,Hash值映射到Key结点,Key结点再映射到Value结点。Key结点优先存储在内存中,Value结点有可能存储在内存中也有可能存储在磁盘中。
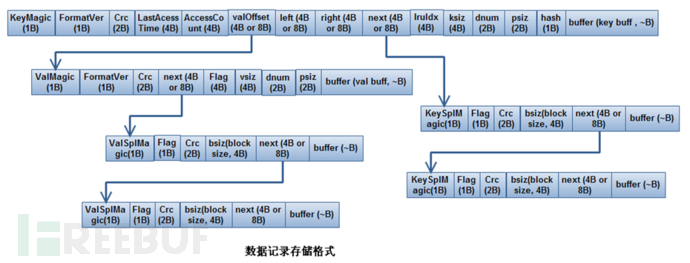
具体说明如下:
- 一条记录的key,可能有多个块组成, 一个Head块, 多个split块,每一个块中记录下一个块的offset. 同时key head块中记录的有value头块的offset。
- 一条记录的val, 也可能有多个块组成, 一个head块, 多个spl块,val的offset,记录再key的head中。
- 通过将key的offset记录在hash桶中, 冲突的记录,offset记录在keyHead的left和right中以实现链表或二叉树。
- 线上业务通常width_等于32,即4B。 则 keyHead默认最小块为64B(apow的取值最小为6,2**6=64B), 其中引擎自有信息需要占用32B – 33B, 业务可用为31B到32B, 业务据此可设计更有效的key,使key占用的块尽可能少。
多级LRU链 进行数据热度管理
为记录数据的访问热点,对mmap区域内的数据建立多级LRU链来跟踪,LRU链的级数通过参数可以定制,采用多级LRU而非一级LRU链主要是淘汰时除考虑最近访问时间外,还评估最近访问次数。
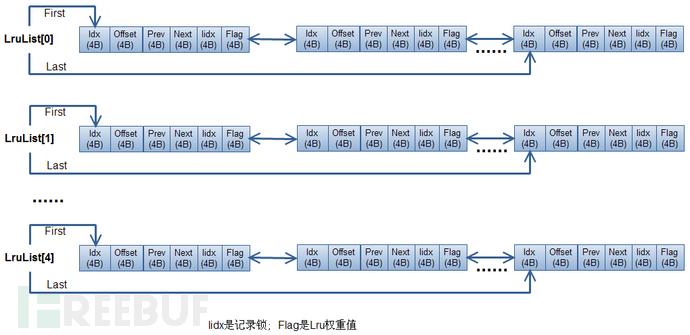
- 多级LRU,综合考虑最近访问时间和访问次数
- 读写访问时增加访问计数,定位扫描时减访问次数
- 优先淘汰访问次数为1的LRU链中的记录
- 换出条件:剩余内存低于一定阀值
- 换入条件:剩余内存高于一定阀值
我们已经了解了 TcaplusDB 个分布式的 NoSql数据库搜素引擎的基本结构,后续我们将揭开更多TcaplusDB设计的特殊奥秘。