近期,专家发现一种新的攻击方式。该攻击利用视频电话将可观察到的身体运动与正在输入的文本相联系,来推断出用户在视频电话时键入的信息。这项研究是由Mohd Sabra和得克萨斯大学圣安东尼奥分校的Murt 2021-02-25 11:36:51 Author: www.freebuf.com(查看原文) 阅读量:168 收藏
近期,专家发现一种新的攻击方式。该攻击利用视频电话将可观察到的身体运动与正在输入的文本相联系,来推断出用户在视频电话时键入的信息。
这项研究是由Mohd Sabra和得克萨斯大学圣安东尼奥分校的Murtuza Jadliwala以及俄克拉荷马大学的Anindya Maiti进行的。他们表示,只要网络摄像头可以捕捉到目标用户的上半身动作,该攻击的范围就可以从视频电话扩展到YouTube和Twitch等视频网站上。
研究人员表示,随着视频捕获硬件嵌入越来越多的电子产品中,比如智能手机、平板电脑、笔记本电脑等,通过视觉渠道造成信息泄露的威胁在最近逐步扩增。此外,他们还称,这些攻击者的目标是利用在所有记录的帧上可观察到的上半身运动来推断受害者输入的私人文本。
为了实现这个目的,录制的视频被输入到基于视频的按键推断框架中,该框架经历了三个阶段:
1. 进行预处理:将背景移除后,视频将转为灰阶,然后用FaceBoxes的模型检测到的个人脸部,对左右手臂区域进行分割。
2. 按键检测:检索分割后的含有手臂动作的帧数来进行结构相似度指数测量(SSIM),量化左右两侧视频段中每个连续帧之间的身体动作,并识别出发生按键的潜在帧。
3. 单词预测:按键帧将用于检测每个按键前后的运动特征,并通过基于字典的预测算法来推断特定的单词。
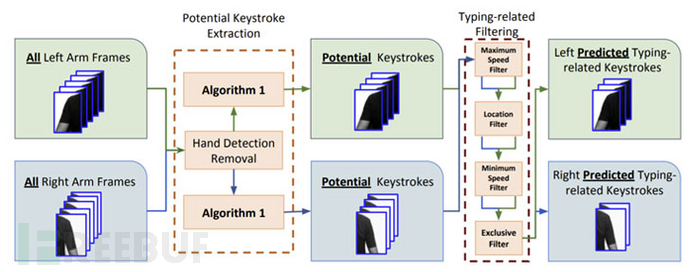
换句话说,在检测到的按键帧池中,通过检测到的单词输入次数以及在单词的连续输入之间所发生的手臂位移的大小和方向来推断单词。
这种位移是用一种叫做稀疏光流的计算机视觉技术来测量的,这种技术被用来跟踪肩部和手臂在计时按键帧中的运动。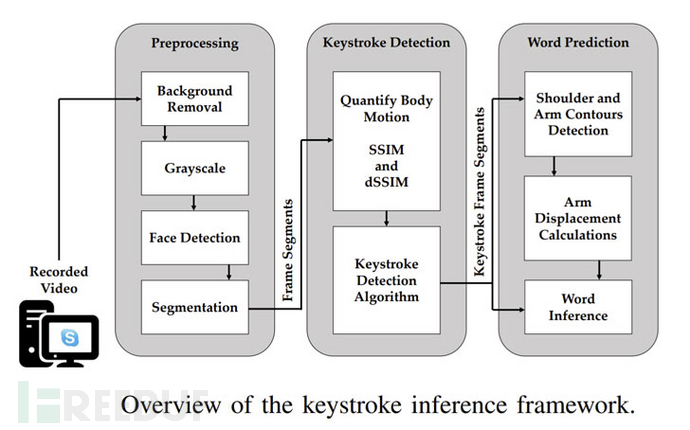
此外,还绘制了“标准QWERTY键盘上的键间方向”模板,显示出使用左右手混合的“打字者的手遵循的理想方向”。
然后,单词预测算法搜索最有可能的单词,这些单词与左手和右手按键的顺序和数量以及手臂位移方向与模板的按键间方向相匹配。
研究人员表示,他们在一个受控的场景中对20名参与者(9名女性和11名男性)进行了框架测试,采用了“hunt-and-peck”(这是一种不正确的输入形式,用户通常会使用食指在他们的键盘上寻找(hunt)位置,然后按下(peck)该键。)和触摸打字的混合方法,除此之外,他们还针对不同的背景、网络摄像头模型、服装(尤其是袖子的设计)、键盘,甚至是各种视频通话软件(如Zoom、Hangouts和Skype)来测试推理算法。
研究结果显示,“hunt-and-peck”打字者和穿着无袖衣服的人更容易受到单词推理攻击,同时使用Logitech摄像头的用户比使用Anivia外部摄像头的用户单词恢复效果更高。
再邀请10名参与者(3名女性,7名男性)在实验性的家庭设置中重复测试,成功推断出91.1%的用户名、95.6%的电子邮件地址和66.7%的网站,但只推断出18.9%的密码和21.1%的英文单词。
研究人员表示他们的准确率比In-Lab设置的差的原因之一是,参考词典的等级排序是基于英语句子中的单词使用频率,而不是基于人们产生的随机单词。
模糊、像素化和跳帧可以成为一种有效的缓解策略,但同时视频数据可以与通话中的音频数据相结合,进一步提高按键检测能力。
由于最近发生的世界性事件,视频通话已经成为个人和专业远程通信的新标准。然而,如果在视频通话中不够谨慎,就有可能向通话中的其他人透露个人信息。在现实环境下相对较高的按键推理准确率凸显了对此类攻击的认识和采取对策的必要性。
如有侵权请联系:admin#unsafe.sh