基于AI的暗网流量检测识别效果专题研究
星期一, 十二月 7, 2020

1、暗网背景介绍
暗网是深网中的一小部分,是必须通过特殊的软件、特殊的配置才能访问的拥有特殊域名的Web站点,搜索引擎无法对其进行直接检索。它的网址不同于一般的网址,它以顶级域名后缀“.onion”结尾,且一般的浏览器无法对其进行访问,只有通过暗网的浏览器才能进行访问,比如Tor浏览器。Tor是一个自由软件,它专注于提供对互联网的匿名访问,可以让用户匿名上网。由于Tor网络经过了多层次的加密,网站无法跟踪其用户的地理位置和IP,用户也无法获取网站主机的有关信息。因此,黑暗网络用户之间的通信是高度加密的,用户可以以保密的方式交流、共享文件、发布博客等,同时也会被用于非法交易、非法论坛以及恐怖分子的介质交流等。
访问Tor网络的时候,需要在客户端上安装一个Tor浏览器,然后浏览器连接到Tor输入节点,该节点又连接到Tor中继节点。连接将通过多个中继节点,每一步都增加了另一层安全性并重新加密了数据,最终到达要访问的目标网站。如图1所示:

为了进一步提高访问的私密性,可以在浏览器中配置代理访问Tor入口节点,常见的代理方式包括Shadowsocks翻墙代理和VPN代理。
2、暗网内部模拟环境搭建
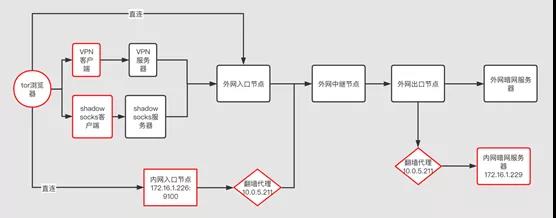
2.1 拓扑图
本实验为尽可能模拟真实的暗网访问,并在不同的网络访问之间抓取Tor流量数据,搭建了完整的暗网访问环境,包括:
- 自建的访问Tor访问终端;
- 自建的内网入口节点或者选定的外网入口节点;
- 外网出口节点
- 自建的内网目的服务器或者外网的目的服务器。其中,自建的访问终端搭建了3种不同的访问方式:
- 直连接入暗网入口节点;
- 使用Shadowsocks翻墙代理接入外网入口节点;
- 使用VPN代理接入外网入口节点;
总体的网络拓扑如图2所示(红框的是自建的节点):

基于以上拓扑,可以抓取如下类型的流量:
- Tor终端直连到外网入口节点的流量;
- Tor终端直连到内网入口节点的流量;
- Shadowsocks到外网入口节点流量;
- Tor翻墙代理到外网中继节点的流量;
- Tor VPN代理到外网入口节点的流量;
- 外网出口节点到内网暗网目标服务器的流量
即通过在自建的网络拓扑中建立自己的节点,能够抓取到暗网通信各个环节中的流量数据。
参照网络上公开的Tor研究数据(https://www.unb.ca/cic/datasets/tor.html),我们抓取的Tor流量也包括如下7类的数据:浏览器上网、电子邮件、聊天、音频流、视频流、FTP、VoIP以及P2P等。
2.2 三种Tor连接方式的典型流量
- Tor终端直连到内网入口节点的流量

2.Tor Shadowsocks典型流量

3.Tor VPN典型流量
Tor VPN可以配置TCP或者UDP两种代理模式,其中Tor VPN TCP典型流量:

Tor VPN UDP典型流量:

3、实验数据
3.1 实验总体流程
暗网的实验是在公司自建的AI训练平台上进行的,AI训练平台的整体流程图如下图3所示:

本次暗网实验,是从暗网环境抓取pcap数据开始,经过下载暗网的pcap、pcap包分析、流量数据处理、流量特征提取、AI模型训练几个步骤,生成暗网的AI模型。
3.2 实验数据
通过搭建暗网环境,抓取到的实验数据集详细分类信息如下:
表1 实验采集数据集

对于加密流量的机器学习检测,通常有两种特征提取方式:
- 基于数据流上包的统计特征构建AI训练的特征工程;
- 基于加密应用协议TLS/SSL和数据流上包的统计特征,并关联DNS上下文统计特征构建AI训练的特征工程。
本文的实验分别基于以上两种特征提取方式进行AI模型的验证。

4、基于数据流上包统计特征构建模型
4.1 模型评价指标
模型评价一般分为两类:功能指标和性能指标。功能指标用于对模型的识别效果进行评价,性能指标用于对识别效率进行评价。在本次实验中,使用精确率、召回率、准确率以及F1值等功能指标来衡量模型的检测能力。
准确率(Accuracy)是指分类正确的个数占总样本的比例,用于衡量分类器作出的判决中总体的正确率情况,公式如下:

召回率(Recall)是指正样本被分类正确的个数占总正样本数的比例,用来衡量模型的对正样本的检测能力,公式如下:

精确率(Precession)是指分类为正样本实际为正样本的比例,用来衡量对正样本结果中的预测准确程度,公式如下:

F1-socre同时兼顾了分类模型的精确率和召回率,可以看作是模型精确率和召回率的一种加权平均,对于不平衡样本集F1值更能衡量模型的分类能力,公式如下:

4.2 模型训练
基于数据流上包的统计特征,提取特征向量之后得到的训练样本如表2所示:
表2 数据流上包统计特征构建的训练样

样本的数据降维分布,如图4所示:

在数据集的模型训练中,选择目前流行度较高的XGBoost、LightGBM、RandForest以及Logistic Regression分类算法进行模型训练,且全部采用算法模型的默认参数进行训练。在数据集的划分中,训练集:测试集:验证集按照4:2:2的比例进行划分,并在训练过程中采用10折交叉验证进行模型训练和结果评估。
基于数据流上包的统计特征对各模型进行训练后,在测试集上得出的评价指标如表3所示:
表3 不同算法模型在测试集上的评价结果1

从结果中可以看到,XGBoost、LightGBM以及Random Forest的各个功能评价指标都达到理想的效果,而LogisticRegression相对较差,其中Recall仅0.87,表明该模型对Tor流量的检出能力不如另外三个模型。
为进一步对模型进行更加准确的评价,将各个模型的ROC曲线图以及混淆矩阵图进行展示,如图5和图6所示,class 0: 白样本,class 1:Tor直连样本,class 2:Shadowsocks代理样本,class 3: VPN代理样本。




图5 模型ROC曲线图




图6 模型 ROC混淆矩阵图
从表3指标评价结果表、ROC曲线以及混淆矩阵图综合来看,XGBoost、LightGBm以及Random Forest在Tor流量的综合检出能力以及各个类别的检出能力上都表现较好,而Logistic Regression则更容易产生误报。
4.3 模型在公开数据集上的验证
模型训练的数据都是在实验环境抓取的,除了对实验数据进行交叉验证之外,我们也利用CIC Tor2016公开数据集
(https://www.unb.ca/cic/datasets/tor.html)验证了模型的检测效果。
该数据集包含22GB的Tor以及nonTor流量,其中Tor流量12GB,nonTor流量9.9GB,Tor流量包含7类:浏览器、电子邮件、聊天、音频流、视频流、FTP、VoIP以及P2P。4.2中所训练的模型在CIC Tor 2016中的TCP/UDP表现如表5所示:
表4 模型在CIC Tor 2016数据集测试结果

从表中可以看到,XGBoost、LightGBM误报率都较低,为0.0159%,而Logistic Regression误报达到了14.7234%。
其中,XGBoost、LightGBM将nonTor预测为Tor直连数量为3,将Tor直连预测为nonTor数量为2;Random Forest将nonTor预测为Tor直连数量为4,将Tor直连预测为nonTor数量为2;Logistic Regression将nonTor预测为Tor直连数量为4556,将Tor预测为nonTor数量为80。另外除了Logistic Regression出现了一次将nonTor预测为Tor非直连的情况,其它三种模型均无被预测为Tor非直连的情况。
5、基于加密协议TLS/SSL协议构建模型
基于加密应用协议TLS/SSL进行特征提取,不仅利用了数据流上包的统计特征,而且利用了加密协议TLS/SSL通信特征,并关联DNS上下文统计特征,构建AI训练的特征工程。
5.1 模型训练
表5 基于TLS/SSL并关联DNS上下文统计特征构建的样本

以上数据的降维分布,如图7所示:

在该数据集的模型训练中,选择目前流行度较高的XGBoost、LightGBM、RandForest以及Logistic Regression分类算法进行模型训练,且全部采用算法模型的默认参数进行训练。在数据集的划分中,训练集:测试集:验证集按照4:2:2的比例进行划分,并在训练过程中采用10折交叉验证进行模型训练和结果评估。模型评价指标采用4.1节中描述的四种功能评价指标。
对各模型进行训练后,在测试集上得出的评价指标如表6所示:
表6 不同算法模型在测试集上的评价结果2

从结果中可以看到,各个模型在各个功能评价指标上表现都较好。为进一步对模型进行更加准确的评价,将各个模型的ROC曲线图以及混淆矩图进行展示,如图7和图8所示。class 0: 白样本,class 1:Tor直连,class 2:Shadowsocks。




图8 四种模型的ROC曲线




图9 四种模型混淆矩阵图
从表6模型评价指标结果以及图8的ROC曲线以及图9的混淆矩阵图中可以看到,各模型在数据集上的表现都较为稳定,且检测能力较好。
5.2 模型在公开数据集上的验证
模型训练的数据都是在实验环境抓取的,除了对实验数据进行交叉验证之外,同样利用CIC Tor2016公开数据集(https://www.unb.ca/cic/datasets/tor.html)验证了模型的检测效果。
该数据集包含22GB的Tor以及nonTor流量,其中Tor流量12GB,nonTor流量9.9GB,Tor流量包含7类:浏览器、电子邮件、聊天、音频流、视频流、FTP、VoIP以及P2P。
5.1节所训练的模型在CIC Tor 2016中的测试结果如表7所示。
根据表7中的结果,训练模型在CIC Tor 2016数据集的测试中,LightGBM误报率最低,Logistic Regression的误报率则在0.481 %。
表7 模型在CIC Tor 2016中的误报率

其中,XGBoost将nonTor预测为Tor直连数量为0,将Tor直连预测为nonTor数量为1;LightGBM无预测出错的情况;Random Forest将nonTor预测为Tor直连数量为0,将Tor直连预测为nonTor数量为2;Logistic Regression将nonTor预测为Tor直连数量为1,将Tor预测为nonTor数量为12。另外训练的四种模型都没有出现被预测为Tor非直连的情况。
6、总结
我们按照暗网的常见网络拓扑,搭建的实验环境,利用公司自建的AI训练平台,验证了基于数据流包统计特征和基于加密协议TLS/SSL结合数据流包统计特征、关联DNS上下文统计特征的2种AI模型。
这2种模型都分析了数据集的t-SNE降维分布、模型在不同机器学习算法上的交叉验证结果、在公开数据集上的测试结果,最终结果表明用AI方法来识别暗网流量是可行的,在有些机器学习算法上表现优异,准确率高达99.8%以上。而且使用AI多分类模型,能够区分暗网的3种连接方式:直连、Shadowsocks代理和VPN代理。(本文系金睛云华投稿)
如有侵权请联系:admin#unsafe.sh