前期之域名收集
wydomain猪猪侠、subsomain、sublist3r、subdomainsBurte、DiscoverSubdomain、layer子域名挖掘机,在线dns解析历史记录查找子域名securitytrails.com 、virustotal.com,方法比较多,重点在于url的收集和js挖掘。
1.URL 收集
有时候我们可以在 javascript 中发现一些未公开的敏感接口,所以我们可以多看看 javascript 文件,但是 javascript 文件可能会有很多,有没有方法可以自动收集呢?
有。
首当其冲的当然是我们的 BP:
在 BP 专业版 中的:
Target => Site Map => 找到要提取 script 的地址右键 => Engagement tools => Find scripts

我们就可以在 Find scripts 前主动去爬一下网站,增加一些内容,让结果多些。


如果点 Export Script,他会把所有脚本内容都写入一个文件里,有时我们可能只需要 script 的 url链接,此时我们可以全选,然后
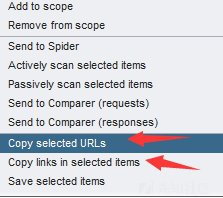
上面那个是提取 URL,下面那个应该是提取 Response 中的 src/href
2.提取节点
这时候我们就有很多 script 的 URL 了,但是一个一个分析太麻烦,有没有什么可以自动帮我们找到接口呢?
也有,这里有个好用的工具,可以提取 javascript 中的节点:
基本用法的话,类似这样:
python linkfinder.py -i https://https://max.book118.com//statics/js2/book118ajax2.js
但是好像不能给一批 URL,不过也可以自己写个脚本调用一下。
自造轮子
以上两点主要做了两件事一是通过bp提取一个站点的url包含js,然后LinkFinder提取js中的隐藏的url接口,而对于js的挖掘也在于此应为往往会隐藏着站点所对应的调用到的各种接口。因为这些接口可能往往会存在着未授权接口而导致的信息泄漏,引发一系列惨案。
另外js中也有可能会包含一些老域名、测试接口、测试域名等,这些对应我们发掘网站漏洞,又进一步扩大了测试面。
针对以上的考虑,于是就有了jsspider这个工具。先简单介绍一下这个工具的功能,正如以上所想的那样,这个工具主要实现的有以下几点:
1)动态加载挖掘网站域名所涉及的url、包含域名,动态加载挖掘的优点在于,因为考虑到许多网站用到了异步加载页面的技术若纯粹的静态爬取是获取不到任何内容的,以保证尽可能的爬取。如此对应上bp的url收集所做的事。
2)对爬取收集到的url包含js,通过正则进一步提取隐藏的接口、域名等信息
3)深度设置,若还需要对js内的url进一步发掘,可通过设置爬取深度来完成,如深度1:爬取当前网站下的所有url,并进行发掘爬取js中的接口;深度0:爬取当前url所隐藏的接口等信息,主要针对指定js的url,如:
python3 main.py -u https://dsfs.oppo.com/oppo/script/common-99171afa41.js -d 0
深度2:对改网站爬取到的url再进一步爬取其url和挖掘其url页面中js隐藏的接口信息。如第一次爬取到url:http://a.com/test.html, 程序继续爬取test.html中的url和js链接并挖掘该js信息,如果为域名a.com则程序继续爬取a.com中的url和js链接并挖掘该js信息,以此类推但考虑到性能和速度问题一般默认甚至1即可。
程序涉及到的框架及模块:
js挖掘所用到的正则:
regex_str =r"""
(?:"|') # Start newline delimiter
(
((?:[a-zA-Z]{1,10}://|//) # Match a scheme [a-Z]*1-10 or //
[^"'/]{1,}\. # Match a domainname (any character + dot)
[a-zA-Z]{2,}[^"']{0,}) # The domainextension and/or path
|
((?:/|\.\./|\./) # Start with /,../,./
[^"'><,;| *()(%%$^/\\\[\]] # Next character can't be...
[^"'><,;|()]{1,}) # Rest of the characters can't be
|
([a-zA-Z0-9_\-/]{1,}/ # Relative endpoint with /
[a-zA-Z0-9_\-/]{1,} # Resource name
\.(?:[a-zA-Z]{1,4}|action) # Rest + extension (length 1-4 or action)
(?:[\?|/][^"|']{0,}|)) # ? mark with parameters
|
([a-zA-Z0-9_\-]{1,} # filename
\.(?:php|asp|aspx|jsp|json|
action|html|js|txt|xml) # . + extension
(?:\?[^"|']{0,}|)) # ? mark with parameters
)
(?:"|') # End newline delimiter
"""通过该正则进行js接口及域名的提取,该正则主要提取js中包含以下3类特征的url

批量爬取
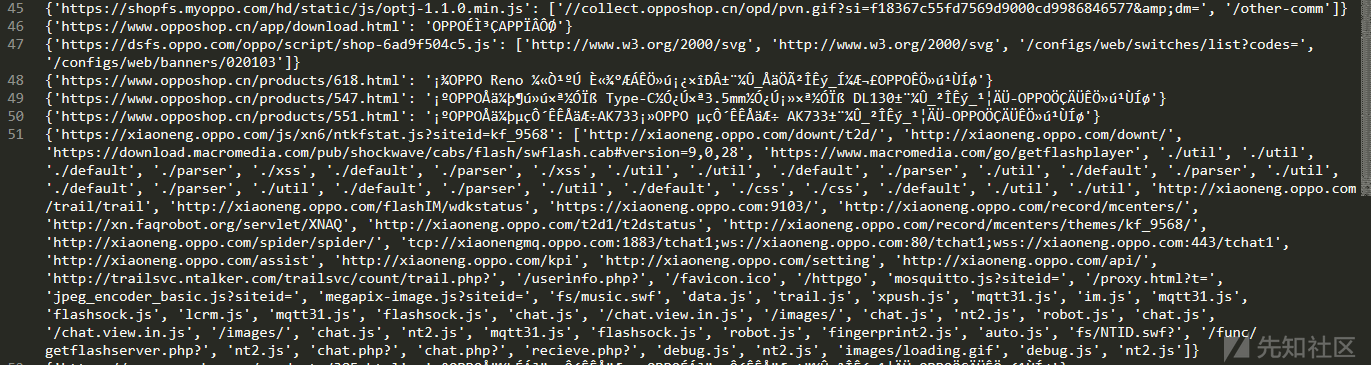
例如批量提取域名https://www.opposhop.cn
python3 main.py -u https://www.opposhop.cn -d 1程序跑完提取到200+多个url链接地址包含js,如下:
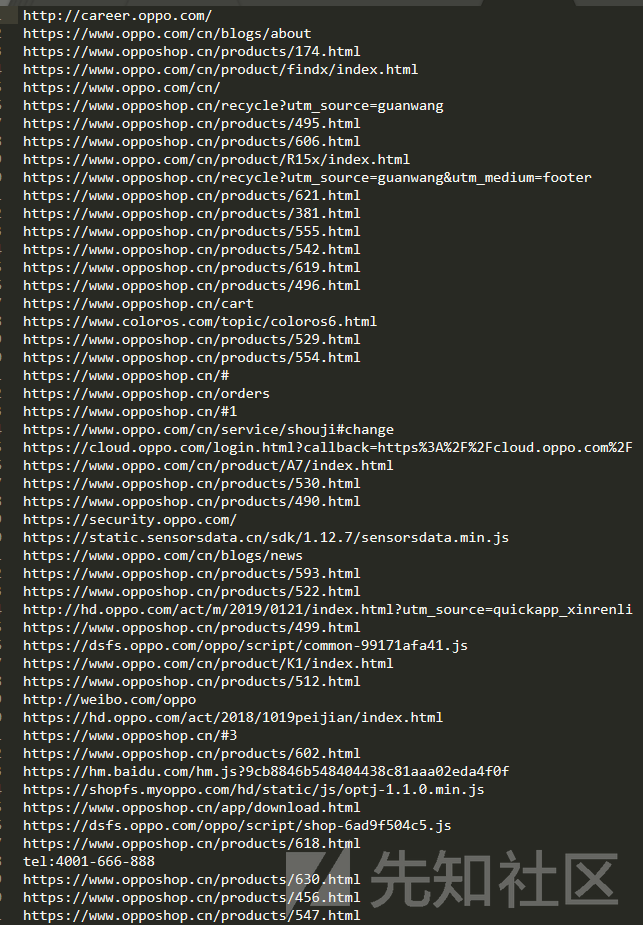
匹配到符合规则提取到的js接口信息:

若有更好的想法将待续更新,同时脚本的优化和改进也将更新到[github]中……..
如有侵权请联系:admin#unsafe.sh