The following analysis presents the key findings from Kaspersky Compromise Assessment 2026-7-2 09:0:9 Author: securelist.com(查看原文) 阅读量:2 收藏
The following analysis presents the key findings from Kaspersky Compromise Assessment engagements performed in 2025. A compromise assessment is an independent, expert-driven service that examines whether a target network has been compromised. The service combines threat intelligence analysis (including darknet sources), tool-aided endpoint scanning, a systematic review of security event logs and network traffic, and, when necessary, an initial incident response and digital forensic investigation.
This report focuses on missed incidents – threats that remained undetected for weeks, months, or even years.
Key trends observed during compromise assessment engagements
- Proactive compromise assessment decreases the number of missed high-severity incidents. The highest proportions of high-severity incidents were revealed in organizations that requested our compromise assessment service after containing a known incident. The lowest proportions of high-severity incidents were observed in organizations that conducted regular audits. Of all the incidents discovered, 20% were found manually, while enterprises missed 60% because of the absence of high-confidence alerts from the tools in place.
- Nearly a third of discovered incidents took over three months to detect. The longer a threat persisted in the target environment, the greater the likelihood that an incident would be severe. 30.8% of incidents had activity spanning over three months, with 52% of high-severity compromises discovered only after 90 days of going undetected. The oldest incident discovered in 2025 had gone undetected for four years.
- Malicious files often remain in backups and are restored after incident response activities. 40% of all discovered web shells resided in backups and went unnoticed until a proper compromise assessment was conducted.
- Threat actors rely on remote management tools and LoLBins. These types of tools were found in all compromise assessment engagements that resulted in an incident detection.
- Monitoring tools and controls are not self-sufficient; operational maturity makes the difference. Monitoring tools must be configured and adapted to the changing threat landscape. Furthermore, human analysts need to review low-confidence alerts. A lack of continuous monitoring and threat hunting activities increased the likelihood of high- and medium-severity incidents to 84–86%. At the same time, high‑severity incidents were rare among organizations with in-house capabilities to reverse-engineer malware.
- Communication issues lead to missed incidents. Nearly a third of the compromise assessments revealed communication issues that impacted incident response activities.
- The incident response playbook is not set in stone. For incident response to be efficient and effective, playbooks must be updated as new artifacts are discovered. Treating the incident response plan as a living document reduces the risk of missing threats.
About the Kaspersky Compromise Assessment service
Our global compromise assessment portfolio spans several regions. In 2025, around 71% of the incidents we identified affected our customers in the META region, while the APAC and CIS regions accounted for the remaining 29%.
Geographic distribution of incidents identified during Kaspersky Compromise Assessment projects in 2025 (download)
Our service was requested by organizations from a diverse set of sectors. The government sector accounted for around 29% of incidents, followed by the education (19%) and financial (17%) sectors.
Distribution of economy sector incidents identified during Kaspersky Compromise Assessment projects in 2025 (download)
Detection logic families
Our compromise assessments operate on a continuously updated catalogue of indicators of attack (IoAs). Because the raw set of IoAs is too granular for high-level reporting, we map them to a concise set of detection logic families. The statistics indicate that three detection families dominate the incident mix:
- Credentials from dumps: 12.4% of all incidents;
- Specific living-off-the-land (LOTL) tools: 11.2 %;
- Specific malware families: 11.2 %.
These three detection logic families represent high-fidelity indicators of attack that reliably signal infrastructure compromises ranging from dormant, disk-based malware to persistent and multi-stage attacks.
Distribution of detection logic families (download)
Reasons for requesting Kaspersky Compromise Assessment services
Analysis of our compromise assessment engagements that took place in 2025 reveals a clear correlation between the stated purpose of the engagement and the risk profile of the findings. General audits dominate the portfolio with 56% of requests, followed by authority reporting engagements (19%), post-incident checkups (17%), and acquisitions (9%).
Statistics on the reasons behind CA project requests (download)
When the findings are classified by severity, the post-incident checkup category exhibits the highest proportion of high-severity incidents (40.7%). The full breakdown is shown below.
| Incident severity breakdown by service engagement reason | ||||
| Incident severity (%) | ||||
| High | Medium | Low | ||
| Reason for service | Acquiring new company | 28.6 | 42.8 | 28.6 |
| General audit | 27.7 | 36.7 | 35.6 | |
| Report to an authority | 30 | 46.7 | 23.3 | |
| Checkup after a cybersecurity incident | 40.7 | 25.9 | 33.4 | |
Post-incident checkups are frequently initiated after an initial incident response (IR) effort. The elevated share of high-severity findings suggests that IR activities, which are typically limited to containing a known incident, do not provide a complete view of the broader environment. Consequently, other threats may remain undetected until a full compromise assessment is performed.
Merger and acquisition-related assessments are proactive assessments performed when a company acquires another entity. This involves the target’s network being scanned for hidden threats before the two environments are merged. These assessments demonstrate a balanced distribution of severity: 28.6% low-severity, 42.8% medium-severity, and 28.6 % high-severity. This reflects the mixed risk posture of target environments of acquisitions, which are often evaluated for both known vulnerabilities and hidden malicious activity. Similarly, other proactive approaches like general audit assessments or assessments driven by the need to regularly submit a compliance report to a regulatory authority, share almost the same ratio. This indicates that regular, proactive and compliance-oriented assessments tend to reveal substantive issues earlier in the attack lifecycle, reducing the likelihood that they will evolve into high-severity incidents.
Organizations that conduct regular audits have the highest rate of low-severity findings (36%) and the lowest rate of high-severity issues (28%). We can assume with medium confidence that continuous, proactive compromise assessments are more effective at limiting the emergence of high-severity compromises than reactive, incident-driven evaluations. The data collected in 2025 are consistent with this hypothesis. Integrating regular, third-party compromise assessments into governance processes can therefore reduce the probability of unexpected high-severity findings and improve overall risk posture.
The following case study illustrates the impact of relying on a reactive rather than proactive approach. It describes a persistent threat that remained dormant on a client’s network and was only discovered after a comprehensive compromise assessment was performed following initial IR activity.
Case study: Dormant threat uncovered only by a compromise assessment
A midsize enterprise suffered a high-severity intrusion that was contained and remediated by the IR team within the defined scope of the initial alert. Following containment, the organization requested a check to determine if any additional footholds existed elsewhere in the network. To address this need, the organization engaged Kaspersky’s Compromise Assessment (CA) service, which performed a full forensic review of the environment beyond the scope of the initial incident.
Compromise assessment experts collected forensic metadata, historical security event logs, and Active Directory configuration data from the entire infrastructure. Threat hunting queries were executed against the aggregated telemetry, focusing on persistence mechanisms, lateral movement artifacts, and anomalous process activity. As a result, a number of severe threats were detected and reported; for example, malicious persistence:
- A cron job that recreates a web shell
A critical Linux system (web server) had a cron job that automated fetched a copy of a PHP web shell from a public GitHub repository and placed it in an online directory. Even if the file was removed by security personnel, the cron job would simply download it again, giving the attacker a persistent remote code execution point on the web server.

- A live reverse shell
On a server hosting a published web application, the process list showed a bash reverse shell. It was run by a user with the username “apache,” which was the account used to run the web application. This may indicate that the attacker exploited a vulnerability in the web application to gain remote code execution, allowing them to establish a reliable command and control channel that bypassed the firewall because it was initiated from inside the network.
It was run by a user with the username “apache,” which was the account used to run the web application. This may indicate that the attacker exploited a vulnerability in the web application to gain remote code execution, allowing them to establish a reliable command and control channel that bypassed the firewall because it was initiated from inside the network. - ClipBanker data stealer persisting via Windows registry
A ClipBanker variant was detected on a user’s workstation machine maintaining persistence by adding itself to the registry key HKU\S-1-5-21-[REDACTED]-500\Software\Microsoft\Windows\CurrentVersion\Run\9Er6IIp.

This was done after adding the malware’s folder to Windows Defender exclusions and applying hidden and system attributes to the file to hide it from regular users.

- Malicious WMI event consumer with deceptive alias
A malicious WMI event consumer was detected that downloads and executes a PowerShell script. It created the alias “Kaspersky” for “Invoke-Expression” in an attempt to blend in as legitimate activity in the hope that a quick glance at the script would not raise suspicion. Kaspersky’s Cyber Threat Intelligence confirmed that the downloaded script (no longer reachable) was a weaponized payload used to spread the infection further.

The IR containment was rapid, focused and effective in addressing the specific incident that triggered the alert. However, the broad-scope compromise assessment revealed multiple backdoors across the environment, each using a different persistence technique: cron jobs, scheduled registry runs, and WMI subscriptions. The infected hosts were outside the original IR scope, so they remained unseen until a comprehensive hunt was conducted.
Incident response excels at stopping the bleeding and ensuring business continuity after a known incident. A compromise assessment provides a health check that determines whether any other wounds exist. By pairing timely IR with regular, full network compromise assessments, the organization had both the reactive agility to contain incidents and the proactive visibility to eradicate malicious persistence wherever it was hiding. The investigation uncovered additional undetected footholds, providing a clearer view of the environment and reducing the likelihood of a repeat incident.
Missed long-term incidents
The statistics on the mean time to detect (MTTD) incidents identified during compromise assessment projects are concerning. Many incidents go unnoticed for extended periods. For example, in 2025 we identified an incident that was approximately four years old!
Such prolonged detection times can lead to severe consequences, as 30.8% of incidents have historical activity spanning over three months. These incidents can range from dormant malware to persistent threats, highlighting the need for robust detection and response mechanisms.
Severity distribution of incidents by MTTD (download)
The relationship between detection latency and incident severity was analyzed by grouping findings according to their MTTD:
- For incidents detected within the first month, severity is more or less evenly distributed among the low, medium and high categories.
- However, as the MTTD increases, the severity of incidents shifts towards higher severity. Notably, a high proportion of incidents that took between 30–60 days to be detected are medium-severity incidents (78.57%), while those detected between 60–90 days are predominantly high-severity (71.43%).
- Among incidents detected after 90 days, a significant proportion are also high-severity incidents (52%).
Overall, 52% of high-severity incidents are only identified after 90 days of going undetected. This represents a concrete risk: the longer an incident goes undetected, the higher the probability of severe compromise. Organizations that integrate continuous detection, threat hunting activities, and regular compromise assessments can reduce MTTD, limit threat escalation, and lower their overall risk profile.
The following case study highlights the importance of timely detection and response to prevent incidents from escalating into high-severity events.
Case study: Four-year-old crypto mining activity on domain controllers
In May 2025, our compromise assessment experts identified three domain controllers on a customer network that were infected with malicious files. The files had remained hidden for almost four years. They were created in the C:\Windows\Fonts\Mysql directory, abusing its unique characteristic whereby only font files in this directory are visible to regular users. Files with the names nei.bat, dl1host.exe, bat.bat, cmd.bat, and a spoofed svchost.exe were found there. These files were created in June and July of 2021.
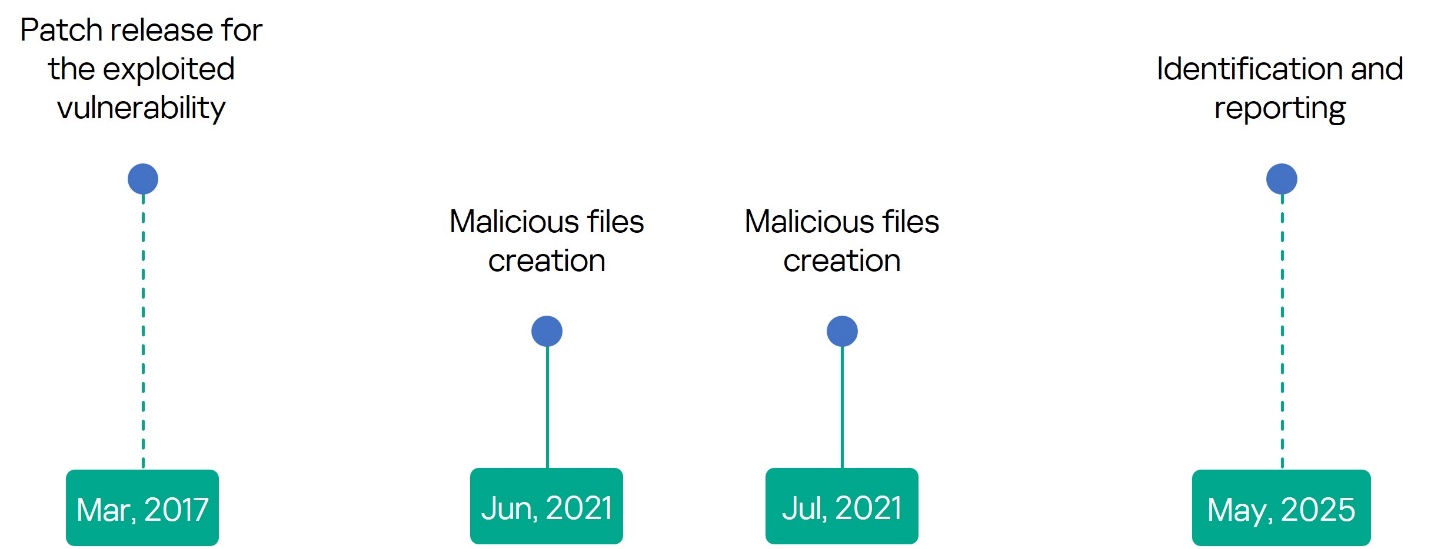
Kaspersky Threat Intelligence confirmed that these files are part of a crypto-mining campaign called NSABuffMiner, which spreads via the SMB protocol by exploiting the EternalBlue (MS17-010) vulnerability. A patch was released for this vulnerability in March 2017, four years before the initial compromise. This was more than enough time to patch the systems. This underscores the importance of implementing effective patch management operations and staying informed through threat intelligence news feeds.
Based on the organization’s request, the malicious files were collected along with a forensic image for analysis and revealed the following:
- bat.bat and cmd.bat generate random IPs and scan them with a lightweight port scanner renamed taskhost.exe to locate live hosts with SMB port 445 and NetBIOS port 139 open and looking for vulnerable machines.
- Discovered vulnerable IPs are handed to helper scripts named bat, poab.bat, load.bat, and loab.bat that execute the malware mance.exe, Eter.exe, and puls.exe to inject the malicious DLLs Eternalblue2.dll and Doublepulsar2.dll into lsass.exe and explorer.exe, enabling lateral movement.
- Persistence is then established by creating scheduled tasks to execute the propagation and infection scripts, and services are created to execute the crypto miner, with the names MicrosoftMysql, MicrosoftFonts, and MicrosoftMSSql. Other scheduled tasks were also observed with the names At1 and At2 and created for the same purpose.
- After successfully compromising the machine and installing the persistence mechanisms, a cleanup task is performed to delete temporary files and dropped malware.
Because of the lack of proper monitoring and threat hunting procedures, the organization was unaware that a mining operation had been hijacking their resources for four years, running on their domain controllers.
Unintentional malware preservation
An issue that is frequently discovered during compromise assessment activities is that of web shells remaining or being restored on target systems. Based on data collected during 2025 compromise assessment engagements, 64% of web shell incidents were classified as high-severity findings, 7% as low-severity (possibly legitimate files, but potentially compromised), and 29% as medium-severity findings requiring eradication.
Web shell incident distribution by severity (download)
One way web shells persist is through infected backups. The distribution of discovered incidents in our projects shows that 60% of the web shells were located on active systems, while 40% were stored in backups. Restoring such backups can reintroduce the threat long after the initial infection.
Web shell location (download)
Another common issue is asset inventory gaps, which were observed in 25% of engagements. This resulted in untracked devices, particularly cloud-only Linux web servers that are not joined to Active Directory, evading routine scans.
Asset inventory issues (download)
An attacker can plant a web shell on such a cloud server, and that server never appears in the inventory, though is still regularly backed up. As a result, the web shell may persist on the cloud server for a long time. If it is occasionally deleted, the backup server later restores the infected files, exposing the web shell to third parties again. This demonstrates that without a complete and up-to-date asset inventory, detection capabilities are significantly impaired.
One case was observed in which the web shell was located on an internal file server (not a web server) within a .rar archive at the following path: D:\backup\[redacted_for_privacy].rar/wwwroot/<…>/[redacted_for_privacy].aspx
During the investigation, the server administrators indicated that the folder had been copied from a different server that was offline at the time of the assessment. Because of poor asset inventory, the company’s security team did not detect the infection of this server. As a result of the backup procedure, the web shell was copied to the internal file server. Forensic analysis of the offline server revealed that the adversary had introduced a backdoor to the majority of the Windows servers in the environment, configuring the local administrator account with an identical password.
The technique involved using PsExec to execute a .cmd script across all the servers listed in a .txt file; the script altered the local administrator password to a common value:

In 2025, nonstandard remote management (RM) utilities were observed in all compromise assessment engagements. Living-off-the-land binaries (LoLBins) were also present in every engagement. These findings highlight the ongoing challenge for security operations centers (SOCs) that must distinguish between legitimate administrative use and malicious abuse.
The observed remote management utilities span both proprietary platforms, such as TeamViewer and AnyDesk, and freely available tools, including PsExec, VNC servers, and open-source RM frameworks. These binaries are used daily in many environments for troubleshooting, software deployment, or remote support. However, the same capabilities – creating a new local admin account, copying files to a remote share, or launching a network port scan for diagnostics – are also typical of attacker post-exploitation activity. Our analysts frequently encounter cases where a legitimate sysadmin action resembles a lateral movement step. This makes the mere fact that “a remote management tool was executed” insufficient to classify it as an incident. Instead, the incident must be judged against an organization-specific baseline of expected usage. Establishing that baseline requires a deep, contextual understanding of who is authorized to run the tool, from which endpoints, and under which circumstances – a resource-intensive process on a case-by-case basis.
LoLBins, binaries that are part of the operating system or commonly installed utilities (such as certutil, bitsadmin, regsvr32, and wmic), were also present in every assessment. While these files are trusted system components, threat intelligence confirms they are often repurposed for lateral movement, data exfiltration, and persistence. The graph below shows the severity distribution for incidents involving riskware or a LoLBin binary. The relatively high share of medium- (40%) and high-severity (31%) findings underscores that misuse of legitimate utilities is often the vector that enables a compromise to progress beyond the initial foothold.
Severity distribution of incidents involving riskware or LoLBin involvement (2025) (download)
To address the potential use of LoLBins and remote management tools by attackers, we recommend a multi-layered approach that goes beyond static deny lists:
- Formalize a policy that enumerates the remote management tools authorized for use. The policy must be coupled with a requirement to forward software operational logs to a central log management platform (SIEM or dedicated log collector). Continuous monitoring of these logs enables a SOC to detect deviations from authorized usage patterns.
- Periodically perform a software inventory audit to identify unauthorized remote management tools. Consider collecting data from the following registry keys on all hosts:
- HKLM\Software\Microsoft\Windows\CurrentVersion\Uninstall
- HKLM\Software\WOW6432Node\Microsoft\Windows\CurrentVersion\Uninstall
- HKEY_USERS\*\Software\Microsoft\Windows\CurrentVersion\Uninstall
- HKEY_USERS\*\Software\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall
- Enrich the hashes (MD5/SHA-256) of every executed binary with a functional category, such as “Remote Access”, “Golden Image”, or “Security Software.” Correlating the category with the execution path makes it possible to hunt for instances where a “Remote Access” binary runs from a non-standard location, such as %TEMP% or a user’s Downloads folder.
- Deploy detection rules that capture known LoLBin abuse patterns, such as certutil -decode, bitsadmin -transfer, regsvr32 -i <dll>, wmic process call create. These rules should be continuously baselined against the organization’s normal activity. The baseline is derived from a period of verified legitimate use and refreshed whenever new legitimate use cases emerge. Alerts are generated only when observed behavior diverges from the established norm, thereby reducing noise while preserving sensitivity to genuine abuse.
Impact of not having continuous monitoring and proactive threat hunting
Analyses of recent compromise assessment projects reveal a systematic blind spot in organizations that follow the security-by-purchase model to defend their networks. Without continuous human monitoring or a dedicated threat hunting program, the severity profile of detected incidents becomes heavily skewed toward a higher impact:
| Incident severity breakdown, where 24/7 monitoring or threat hunting is absent | ||
| Control type | Low-severity | Medium/high-severity |
| No continuous monitoring | 14% | 86% |
| No threat hunting | 16% | 84% |
Often, the problem is not a lack of tools, but rather a lack of operational use of those tools. Many enterprises deploy next-generation security solutions and then let them run in “set-and-forget” mode, or they rely exclusively on an alert-driven workflow. The following issues are common in such organizations:
- Alert fatigue: high false positive rates drown analysts in noise, forcing them to triage superficial indicators rather than conduct deep, contextual investigations.
- Fragmented analyst assignment: without a dedicated hunting team, the same analyst may be tasked with dozens of unrelated alerts, limiting the time available for the hypothesis-driven exploration required to uncover stealthy footholds.
The practical consequence is that adversaries retain an extended dwell time, enabling continued lateral movement and data exfiltration before the organization becomes aware of the breach. This pattern represents a measurable risk exposure that translates directly into business impact. As the following example illustrates, merely purchasing security controls does not guarantee detection; continuous monitoring, regular alert validation, and structured threat hunting are essential to reduce dwell time and limit business impact.
Case study: Secure by design without continuous monitoring
The enterprise invested in security controls and assumed that the environment was secure by design. However, security controls require proper configuration, continuous tuning, and active monitoring to be effective. The tools had been installed, but no one was ensuring that the security controls were configured effectively, there was no analyst reviewing the alerts they produced, and no schedule existed to review the collected logs.
The organization opted for Kaspersky’s Compromise Assessment service. Historical security logs were collected and investigated as part of the assessment procedures. The goal was simple: to determine what had really been going on in the network over the previous few months.
Log analysis revealed clear evidence of malicious activity. Activities related to Impacket behavior were discovered that led to the deployment of Cobalt Strike and Mimikatz on several critical servers, including the domain controllers. These activities were three months old at the time of detection, and the enterprise was unaware of them because there was no effective 24/7 monitoring in place.
Impacket is a collection of Python scripts for network protocols and low-level network packet manipulation. Attackers can abuse it to move laterally into the network. The following are examples of its artifacts detected in the network:

The attacker used Impacket to execute a PowerShell command that downloaded an executable from a command-and-control server. This server was found to be associated with Cobalt Strike. Cobalt Strike is a post-exploitation tool that provides capabilities for remote command execution and lateral movement within a compromised network. The execution was set up via a scheduled task that attempted to masquerade as a legitimate Google Chrome update task.


The timeline assessment confirmed the presence of a Mimikatz binary and a memory dump associated with the same incident on the compromised system, confirming that a credential theft operation had indeed taken place.

The organization was completely unaware of the breach. The activity had gone undetected for three months because the deployed controls were never monitored. Upon learning of the findings, a full-scale incident response was initiated to eradicate the footholds, rotate credentials, and harden the security of the environment.
Security controls are not self-sufficient. Deploying a firewall or an EDR solution does not automatically protect you. Without proper configuration, baseline tuning, and, most critically, continuous log monitoring and threat hunting, those controls become merely decorative. Always-on monitoring, either performed internally or delegated to an external managed security service, can turn weeks-old compromises into minutes-old alerts by correlating events, hunting for anomalous use of penetration testing or hacking tools, and escalating suspicious activity.
Incident response action statistics
An analysis of historical compromise assessment projects reveals a persistent discrepancy between the best practices described in incident response playbooks and the operational realities of executing them in unprepared, often legacy-affected environments. The figure below shows how frequently each response action was required during the initial response phase of a compromise assessment.
Incident response actions required after compromise assessment (download)
The distribution highlights three frequently observed patterns:
- Forensic analysis accounts for the majority of cases, with around 59% requiring at least one forensic package collection and analysis.
- Remote eradication, i.e., file or registry key removal, was reported in 39% of cases.
- Plans evolve as the investigation proceeds; 39% of engagements required a mid-engagement plan update, reflecting the iterative nature of incident response.
Why forensic collection is the default entry point
Forensic package collection and analysis was the most frequent response action, occurring in 59% of cases. The prevalence of forensic package collection can be explained by two observable factors in CA engagements: (1) the targeted organization’s limited historical visibility and (2) the fact that a substantial proportion of incidents were older than 90 days at the start of the assessment. In many cases, native logs had already been rotated or purged, forcing investigators to rely on residual artifacts (e.g., MFT entries, registry hives, filesystem timestamps) to reconstruct timelines.
Our observations suggest that remote forensic package collection is effectively a prerequisite rather than an optional convenience. The graph below summarizes the reported ability to collect forensic packages, categorized by incident severity level. It highlights that, in a significant proportion of high-severity cases, the affected organization lacked this capability.
The organization’s ability to collect forensic data by incident severity (download)
Containment: The remove files/registry keys paradox
Response execution and eradication actions, such as file or registry key removal (reported in 39% of cases), were also common. However, they highlighted a notable gap in execution practices. While many organizations reported having EDR capabilities for remote removal, execution was often delegated to IT teams or MSPs via ticketing systems. This can introduce delays and reduce the precision of the removal process. Malware removal is a surgical process, particularly in multi-stage, fileless, or persistence-heavy scenarios. Capability alone is insufficient without expertise, sequencing, and planning, especially when artifacts may exist in shadow copies, backups, hidden paths, or downloader chains.
Communication failures: An additional operational overhead
A notable organizational finding emerged regarding communication. In 32% of projects, internal communication issues at the assessed organization materially impacted response execution. Below are the typical blockers:
- Unclear action confirmation – system administrators could not quickly confirm whether a suspicious file was legitimate.
- Delayed owner validation – ticket escalations stalled while waiting for system owners to respond.
- Compromised communication channels – email accounts or ticketing portals may already be under the attacker’s control in the event of a suspected domain compromise.
- Staff turnover – loss of knowledge about historical configuration baselines.
These findings suggest that regular tabletop exercises are required to test not only technical playbooks, but also human and communication workflows, as well as operational level agreements that govern and facilitate communication between different teams, and standard operating procedures for proper documentation.
The iterative nature of response plan updates
The need to update response plans based on new analytical input arose in 39% of cases, emphasizing the inherently iterative nature of incident response. Early-stage plans cannot realistically account for all variables. Examples of the most commonly observed causes for updating the response plan are listed below:
- Reverse engineering results that reveal previously unknown command-and-control (C2) servers or behaviors.
- Forensic discoveries, such as hidden scheduled tasks, shadow-copy artifacts, or dormant DLLs.
- Traffic analysis outcomes that expose additional lateral movement paths.
- Human constraints – unavailable system owners, changes in management processes, or supervisor approval.
Based on our experience, teams that treat the IR plan as a living document – incorporating each new artifact, reprioritizing actions, and reissuing the playbook before the next containment step – reduce the risk of missed eradication steps. Conversely, strict adherence to an initial, evidence-limited plan can increase the risk of overlooking persistent footholds.
Distinguishing real attacker artifacts from penetration testing leftovers
Finally, distinguishing attacker activity from penetration testing artifacts remained a recurring challenge (12% of cases). Compromise assessments frequently uncover remnants of legitimate testing tools, which can create uncertainty about whether a detected artifact originated from a malicious intrusion or a legitimate penetration test. Contributing factors:
- Poorly documented penetration test report and artifact cleanup.
- Overlapping toolsets (e.g., SharpHound) used by both red team operators and adversaries.
- Running compromise assessments and active penetration testing projects simultaneously, which degrades analyst focus and increases false positive rates. Although correlating findings with penetration testing reports is essential, compromise assessments are human-driven investigative processes, and confusing analysts with overlapping “legitimate” attack signals leads to misinterpretation and weaker outcomes.
Incident response maturity and its effect on severity
Our data show a correlation between the presence of internal digital forensics or malware reverse engineering capabilities and the distribution of incident severity categories. Across the 2025 compromise assessment engagements, the distribution of low-, medium- and high-severity findings differed markedly between organizations that possessed these capabilities and those that did not. The data below illustrate this correlation and provide a basis for assessing the business value of expanding internal response skill sets.
Incident severity split for cases requiring digital forensics, based on an organization’s capabilities (download)
Organizations capable of analyzing digital forensic artifacts independently experienced half as many high-severity incidents and a higher proportion of low- and medium-severity cases.
Incident severity split for cases requiring malware analysis, based on an organization’s capabilities (download)
The presence of a dedicated reverse engineering resource correlates with a total absence of high-severity cases in our sample set; the majority of incidents were rated as medium severity, with a significant proportion of low-severity outcomes.
The analysis of this correlation indicates, with medium confidence, that the observed shifts are unlikely to be caused solely by sample size effects. Rather, they are more likely to reflect a genuine operational phenomenon: internal digital forensics and malware analysis capabilities contribute not only to SOC processes, but also to cyber-resilience in general.
Case study: In-memory LionTail infection on critical Windows servers
During a compromise assessment, a persistent in-memory threat was identified on several critical servers. The activity was attributed to the LionTail framework, a sophisticated set of custom loaders and memory-resident shellcode implants. LionTail takes advantage of undocumented Windows HTTP.sys driver behaviors to covertly deliver and retrieve payloads via inbound HTTP traffic, effectively blending malicious activity into legitimate network flows.
Several observed variants are attributed to the Scarred Manticore actor, which generates a unique implant per compromised host and performs data exfiltration while carefully masking command-and-control communications within normal-looking traffic.
Detection was achieved through static memory signatures discovered within the scrcons.exe process. Although scrcons.exe is a legitimate WMI host binary located under C:\Windows\System32\wbem, it is frequently abused to host injected payloads, making it an attractive target for stealthy in-memory operations.

The response plan comprised a number of actions, the most critical of which are highlighted below:
- Collection of volatile memory dumps for in-depth analysis.
- Acquisition of full forensic disk images from affected systems.
- Detailed analysis of the collected artifacts and subsequent updates to the incident response plan.
Executing these actions proved challenging for the organization because of its limited digital forensics and reverse engineering capabilities. In incidents dominated by fileless memory-resident threats, these capabilities are not optional – they are essential. Without them, organizations risk losing critical evidence, misjudging the scope of the compromise, or failing to fully eradicate advanced implants that leave minimal traces on disk.
While our specialists were able to complete the investigation and contain the breach, the case revealed a readiness gap. It demonstrated the operational risk of depending on external assistance during high‑impact incidents and reinforced the necessity of in‑house forensic and reverse‑engineering maturity to achieve timely, confident and comprehensive incident handling.
Solving the root cause problems
Upon completion of a compromise assessment engagement, the focus shifts from incident response to a consulting phase. The final workshop focuses on preventing recurrence of incidents by identifying underlying deficiencies that allowed them to go unnoticed. The recommendations are actionable and tailored to the environment. For the purpose of this report, they have been grouped into a limited set of high-level categories.
| Root-cause category | Share of incidents | Typical findings |
| Insufficient detection fidelity | 60.7% | • No high-confidence alerts were generated by the EPP/EDR or related log sources. • In 9.4% of cases, the product was mis-configured or out of date or malfunctioning. |
| Missing alert-driven monitoring | 35.9% | • Alerts that could have indicated compromise were generated, but an incident was not declared. • Signals with high uncertainty (e.g., heuristic web shell detections) required analyst validation. |
| Deficient vulnerability and configuration management | 28.2% | • Evident misconfigurations (e.g., disabled audit logging, over-permissive service accounts). • Known vulnerabilities left unpatched or unmitigated. |
| Lack of structured threat hunting processes | 27.4% | • Low-fidelity alerts were never reexamined after initial dismissal. • High-volume telemetry remained unchecked due to staffing constraints. |
| Inadequate security awareness programs | 25.6% | • Credential leaks from personal devices of employees or contractors accounted for 27.2% of incidents where inadequate security awareness was identified. • Social engineering attempts were successful because of insufficient user training. |
| Absence of documented policies/processes | 23.9% | • No formal incident response playbooks, change management procedures or data handling guidelines were available. |
Common observations on root causes
The detection health check was the most frequent corrective action. In more than half of the cases where alerts were missing, a simple verification of sensor health and rule relevance was recommended to fill the gap. Without such validation, immediate attribution of the failure to the product capability could not be made.
Human analysis is still essential for low-confidence alerts. Automated pipelines alone cannot compensate for rules prone to false positives (e.g., generic web shell heuristics). Embedding a manual triage step was recommended to reduce the dwell time for incidents.
Process hygiene (vulnerability management, threat hunting, security policies) accounts for a substantial proportion of the root causes. Even mature organizations exhibited gaps in routine activities that could be mitigated with disciplined workflows. The absence of documented policies/processes was the root cause of 23.9% of cases.
A modern example of a policy gap is the use of generative AI development tools that operate without clear data handling rules. During one project, we identified a macOS workstation that executed the Claude Code (Anthropic) command-line assistant as a VS Code extension. The tool automatically captured filesystem snapshots to enrich its language model prompts. These snapshots included full directory listings and absolute paths to several Excel workbooks containing internal confidential data:
| Parent command line | Command line |
| /bin/zsh -c -l source /Users/[REDACTED]/.claude/shell-snapshots/snapshot-zsh-[REDACTED].sh && eval ‘ls -lh “/Users/[REDACTED]/Documents/[REDACTED]/”*.xlsx‘ \\< /dev/null && pwd -P >| /var/folders/[REDACTED]/claude-[REDACTED] | ls -lh /Users/[REDACTED]/Documents/[REDACTED].xlsx /Users/[REDACTED]/Documents/[REDACTED].xlsx /Users/[REDACTED]/Documents/[REDACTED].xlsx .. [REDACTED] |
The organization was advised to conduct awareness sessions for employees on the risk of exposing confidential internal data to generative AI tools, and to develop a policy governing the use of such tools with confidential information.
Lack of detections: Causes and impacts
Compromise assessment engagements repeatedly show that insufficient detection fidelity is a significant contributing factor to high-severity incidents. In cases where the target organization’s detection coverage was rated low, 52% of incidents were classified as high severity and 15% as low severity. This suggests a correlation: limited visibility appears to increase the proportion of incidents that evolve into high-severity compromises.
Incident severity distribution when detection coverage was insufficient (download)
A common assumption is that engaging a managed security service provider (MSSP) improves detection maturity. The data, however, show a more nuanced picture. Even when an MSSP is engaged, 26.5% of incidents related to low detection coverage remain unidentified, and roughly 50% of MSSP-supported projects have basic Windows audit gaps (e.g., missing event log collection or disabled audit policies).
These findings suggest that outsourcing alone does not guarantee effective detection; active governance and continuous validation are required. Detection should be treated as an evolving capability that requires continuous testing, measurement, and refinement, irrespective of whether it is managed internally or by a third party.
Statistics of missed incidents due to lack of detection capability with or without MSSP (download)
The analysis of root causes of missed detections reveals several recurring themes. In many environments, the technology is present but poorly operationalized. The main issues are:
- Absence of endpoint protection platform (EPP) health check – nearly 50% of incidents escalated to high severity in engagements where the EPP health check was weak or absent. This reflects the classic “installed-but-not-enforced” risk, where agents are present but not tuned, updated, or validated.
- Threat intelligence gaps – when there was no functional threat intelligence feed or platform, about half of the incidents reached high severity. Without curated indicators of compromise and contextual enrichment, analysts rely on generic alerts and may overlook known malicious behaviors.
The underlying issue is an alert-driven, set-and-forget mindset: organizations assume that deployed tools will automatically protect them, even though the tools are not continuously tuned, validated, or enriched with threat intelligence.
| Incident severity breakdown where there was no EPP health check or threat intelligence | |||
| Missing control | High-severity | Medium-severity | Low-severity |
| EPP health check | 48.3% | 36.7% | 15% |
| Threat intelligence feed | 50% | 40% | 10% |
Detection failures are rarely caused by a single missing control; they emerge from weak configuration, insufficient telemetry, and an absence of regular checks of controls and processes to ensure they are functional, especially in outsourced models. A hybrid monitoring approach that combines internal ownership with external MDR or MSSP support consistently proves to be the most resilient model when roles, expectations, and performance metrics are clearly defined. Detection must be treated as a living function, not a procurement outcome.
The following example illustrates the real-world consequences of control gaps by walking through a severe incident that persisted undetected for months simply because the organization lacked the necessary detection capabilities and security tools.
Case study: In-memory PurpleFox infection evades conventional endpoint protection
During a compromise assessment engagement, memory was scanned on the target hosts using the threat hunting rule set. Two hidden objects were identified:
- PurpleFox rootkit code injected into legitimate svchost.exe processes on several critical servers.
- XMRig cryptocurrency miner signatures residing inside the same compromised svchost.exe instances.
PurpleFox drops specially crafted DLLs and forces svchost.exe to load them. From there, it installs a kernel-mode driver that gives the attacker persistent and stealthy execution capabilities, as well as the ability to pull additional payloads. This results in the loading of the XMRig miner.
The deployed EPP solution monitored file creation, registry modifications and network connections. However, its memory inspection module was disabled. Additionally, the signature set applied at the time of the assessment was not up to date. As a result, no alerts were generated for the injected DLLs or the miner’s shellcode. The compromise assessment team identified this detection gap during the memory analysis phase and documented the missing in-memory inspection capability in the final report.
The organization’s security operations were outsourced to an MSSP, which collected the logs and forwarded them to the SIEM solution. Because the logs never contained alerts for in-memory activity, PurpleFox activity was not identified.
Insufficient vulnerability management: A catalyst for high-severity compromises
In the 2025 compromise assessment engagements, more than half of the threats identified and linked to insufficient vulnerability management practices or missing patches were classified as high severity. The most frequently observed consequences were the deployment of web shells that enabled persistent remote code execution and the exploitation of misconfigured Active Directory instances.
Severity distribution of incidents due to improper vulnerability management (download)
The root causes of missing patches are multifaceted. They include inadequate asset inventory management (25% of projects) and the absence of formal vulnerability management processes (41% of projects). Moreover, 86% of organizations that claimed to have a vulnerability management program still exhibited exploited misconfigurations during compromise assessment engagements. These findings suggest that robust patch management, comprehensive asset inventory practices, and structured vulnerability management processes are critical for preventing high-severity incidents.
Case study: How overly permissive GPO-based software distribution goes wrong
During multiple compromise assessment engagements, a high-impact misconfiguration was consistently observed: a Group Policy Object (GPO) was used to point to an executable in a shared folder and run it on every workstation via a scheduled task. The access control list (ACL) on the share was set to “Everyone – Full Control”.
Given that any authenticated domain user can write to the share, an attacker who compromises a single low-privilege account can replace the legitimate binary with a malicious payload. The next scheduled task run propagates the payload automatically to all endpoints that receive the GPO. This provides:
- Elevated execution context: the scheduled task typically runs under the SYSTEM or local administrator account.
- Automatic lateral movement: the malicious binary propagates without requiring additional network exploitation.
- Privilege escalation: a compromised low-privilege account can lead to domain administrator code execution.
Vulnerability management procedures that include systematic GPO and share permission audits would have flagged the writeable ACL as a high-severity finding, enabling remediation before exploitation. Remediation typically involves restricting the share permissions to “Authenticated Users” with read-only access and limiting modifications to certain privileged accounts. Incorporating these checks into the baseline security controls reduces the attack surface, demonstrating the tangible risk reduction achievable through disciplined vulnerability assessment and penetration testing (VAPT) practices.
Conclusion
In 2025, Kaspersky Compromise Assessment helped organizations reveal a persistent detection gap: 30.8% of incidents had historical activity spanning over three months, with 52% of high-severity compromises discovered only after 90 days of going undetected. Of all the incidents discovered, 20% were found manually, while 60% were missed by enterprises because of the absence of high-confidence alerts from existing tools. The oldest missed incident identified by the Kaspersky Compromise Assessment team in 2025 was four years old.
Post-incident checkups produced the highest percentage of high-severity findings, while regular proactive audits, compliance-driven audits, and audits performed before merging two networks tended to reveal issues earlier. This indicates that purely reactive investigations often miss hidden persistence. The top high-level recommendations for immediate improvement in 2025 for all projects were:
- Run a comprehensive detection engine health check within 30 days of project closure, prioritizing telemetry integrity and rule relevance.
- Introduce a Tier 1 alert validation team that reviews all low-confidence events on a defined schedule.
- Ensure robust 24/7 monitoring augmented with threat hunting capabilities focused on baselining, low-fidelity alerts, and emerging adversary techniques.
- Reevaluate the vulnerability management pipeline to ensure continuous patching and audit log activation across all critical assets.
- Update security awareness curricula to address credential leakage from personal devices and reinforce secure BYOD practices.
- Ensure periodic tabletop exercises are run to test technical playbooks and sharpen the team’s skills and communication workflows.
- Establish operational-level agreements to govern and facilitate communication between different teams and standard operating procedures used for proper documentation.
Addressing the root cause categories systematically will reduce the likelihood of future blind spots and improve the overall security posture of the engaged organizations.
如有侵权请联系:admin#unsafe.sh