Background
While discussing with eversinc33 about lifting BinaryShield to LLVM IR I decided it would be useful to write a basic lifter in Python that can lift x86_64 instructions to LLVM IR. He has since released his blog post: Writing a Naive LLVM-based Devirtualizer, which I highly recommend you check out! This post assumes familiarity with the basics of LLVM IR. You can find some references at the end of this post.
Over the years I noticed that a lot of people get stuck exploring lifters, because existing tooling is too difficult to compile. In October 2025 I spent around a month redoing Remill’s build system (remill#723) and earlier this month I did the same for the Dna project (Dna#9). Last year I also started working on Python bindings for LLVM, which I wanted to use for a real project. You can find the lifter at LLVMParty/striga.
The goal of this post is to lower the barrier of entry and let you experiment with lifting to LLVM IR. For inspiration you can look at the Static Devirtualization of Themida post that was just released by Back Engineering Labs, as well as the Pushan: Trace-Free Deobfuscation of Virtualization-Obfuscated Binaries paper by ASU researchers published in March.
If you enjoy this article and would like to learn more, see my website for information about my in-person trainings.
Lifting
Lifting is the process of translating assembly instructions to some kind of intermediate representation (IR). The motivation is usually that directly analyzing and manipulating (x86) assembly instructions is complex and error prone. The lifter translates the underlying instruction semantics directly to an IR that is easier to reason about (and therefore to manipulate as well).
A few popular IRs:
- SMT-LIB, used by Triton (symbolic execution)
- VEX, used by angr
- Miasm IR
- Sleigh, used by Ghidra, Remill and Icicle
- LLVM IR, used by Rellume, revng and Remill
- Microcode, used by IDA (proprietary)
- BNIL, used by Binary Ninja (proprietary)
For this project I picked LLVM IR, because I am the most familiar with it and it has a well-established ecosystem. LLVM already has all of the common compiler optimizations and it is used and maintained by teams at large corporations.
Architecture
The architecture of the lifter is very much inspired by remill, but I simplified some things to make it easier to follow. In LLVM a register is actually an SSA value, which means we can only assign to it once. CPU registers are variables that can be assigned to multiple times. We model this by creating a State structure in memory that represents the x86 CPU state:
struct State {
uint64_t rax;
uint64_t rbx;
uint64_t rcx;
uint64_t rdx;
// ... GPRs
uint8_t cf;
uint8_t zf;
uint8_t of;
// ... Flags
// ... XMM
};
Instructions that read or write to RAX will load/store to State->rax. If we play our cards right, the optimizer will use the mem2reg pass to translate this into SSA form for us and enable further optimizations.
An important difference to an actual CPU is that flags are modelled as independent 8-bit registers. This makes it easier to reason about compared to a packed bitfield. For instance, it helps the optimizer to perform dead store elimination and propagation.
In addition to the State, we need an opaque memory pointer that helps us differentiate a load/store in the State from memory accesses by the x86 CPU. In short: the State pointer is used to model the CPU and the memory pointer is used to model the RAM. While lifting, the prototype of the lifted function is void lifted(State* state, void* memory). Later on we will perform brightening, to turn this into something we can recompile.
Below is the LLVM IR for the instruction mov rax, rcx, with comments in pseudo-C:
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
; uint64_t* rcx = &state->rcx;
%rcx = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 2
; uint64_t* rax = &state->rax;
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
; Jump to the first instruction
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; uint64_t v0 = *rcx;
%0 = load i64, ptr %rcx, align 4
; *rax = v0;
store i64 %0, ptr %rax, align 4
; Jump to the next instruction
br label %insn_0x140001003
insn_0x140001003: ; preds = %insn_0x140001000
; Block terminator to keep the IR valid
ret void
}
We start out with the initialize block, which is used to get pointers to the relevant State members. Then every instruction gets its own basic block named insn_<addr>. Every instruction is responsible for emitting an unconditional branch to its successors. The basic block for the successor is created with just a ret terminator, to keep the module verifier happy.
To illustrate memory accesses, here is the LLVM IR for mov rax, qword [rbx+42]:
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
%rbx = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 1
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; uint64_t v0 = *rbx;
%0 = load i64, ptr %rbx, align 4
; uint64_t v1 = v0 + 42;
%1 = add i64 %0, 42
; uint8_t* v2 = &memory[v1];
%2 = getelementptr i8, ptr %memory, i64 %1
; uint64_t v3 = *(uint64_t*)v2;
%3 = load i64, ptr %2, align 1
; *rax = v3;
store i64 %3, ptr %rax, align 4
br label %insn_0x140001004
insn_0x140001004: ; preds = %insn_0x140001000
ret void
}
Here you can see the getelementptr i8, ptr %memory, i64 %1 instruction which uses memory as a base, signaling that this is a read from the x86 memory (we will clean this up later).
The lifter itself is contained in a ~500 line Semantics class with these main functions (some are omitted for brevity):
# src/striga/semantics.py
class Semantics:
def __init__(self, module: Module): ...
# Lifting
def begin(self, address: int) -> Function: ...
def get_or_create_block(self, address: int) -> BasicBlock: ...
def lift_bytes(self, address: int, code: bytes) -> list[Successor]: ...
# Semantic helpers
def reg_read(self, name: str) -> Value: ...
def reg_write(self, name: str, value: Value): ...
def mem_read(self, addr: Value, ty: Type) -> Value: ...
def mem_write(self, addr: Value, value: Value): ...
def op_mem(self, op: X86Op) -> Value: ...
def op_read(self, index: int) -> Value: ...
def op_write(self, index: int, value: Value): ...
def flag_read(self, name: str) -> Value: ...
def flag_write(self, name: str, value: Value): ...
# State (simplified)
module: Module
function: Function
ir: Builder
insn: CsInsn
The begin(address) function is used to create the lifted_<address> function in LLVM IR and create the initialize block with a branch to the first instruction:
def begin(self, address: int) -> Function:
name = f"lifted_{hex(address)}"
fn = self.module.get_function(name)
if fn is None:
fn = self.module.add_function(name, self.lifted_ty)
fn.param_attributes(0).add("noalias")
fn.param_attributes(1).add("noalias")
state, memory = fn.params
memory.name = "memory"
state.name = "state"
self.function = fn
self.reg_ptrs = {}
self.insn_blocks = {}
entry = fn.append_basic_block("initialize")
assert fn.last_basic_block == entry
with entry.create_builder() as ir:
ir.br(self.get_or_create_block(address))
else:
# Omitted for brevity
return self.function
To create the instruction block, get_or_create_block is used:
def get_or_create_block(self, address: int) -> BasicBlock:
block = self.insn_blocks.get(address)
if block is None:
block = self.function.append_basic_block(f"insn_{hex(address)}")
with block.create_builder() as ir:
ir.ret_void()
self.insn_blocks[address] = block
assert block.function == self.function
return block
As mentioned above, an empty block is not valid LLVM IR so we populate it with a ret instruction. When actually lifting into the basic block, that instruction will be replaced with the lifted code.
To lift a single instruction we pass its address and bytes to lift_bytes, which is responsible for producing LLVM IR:
def lift_bytes(self, address: int, code: bytes) -> list[Successor]:
# Ensure we have a function to lift into
if not hasattr(self, "function"):
self.begin(address)
insn = self.cs_disasm(address, code)
if self.verbose:
print(";", hex(insn.address), insn.mnemonic, insn.op_str)
# Skip lifting if the block is already populated
block = self.get_or_create_block(address)
assert block.first_instruction
if block.first_instruction.opcode == Opcode.Ret:
block.first_instruction.erase_from_parent()
else:
return []
with block.create_builder() as ir:
# State used by semantic handlers
self.ir = ir
self.insn = insn
handler = _semantics.get(insn.mnemonic)
if handler is None and insn.mnemonic.startswith("lock "):
# LOCK preserves the single-threaded architectural result; the
# lifter does not model inter-thread atomicity separately.
handler = _semantics.get(insn.mnemonic.removeprefix("lock "))
if handler is None:
raise NotImplementedError(insn.mnemonic)
successors = handler(self)
if successors is None:
# Linear fallthrough - handler didn't emit a terminator.
fallthrough = address + insn.size
ir.br(self.get_or_create_block(fallthrough))
successors = [Successor(address, self.const64(fallthrough))]
# Make sure the handler produced valid IR
self.module.verify_or_raise()
return successors
The function first ensures an empty insn_<address> block by removing the temporary ret instruction. Then it creates an IR Builder and calls the handler responsible for producing IR for the instruction being lifted (more on that below). If the handler does not return successors, lift_bytes handles the common fallthrough case by creating a basic block for the next instruction. It is up to the caller to handle the list of Successor tuples:
class Successor(NamedTuple):
src: int
dst: Value
We use an LLVM Value for the branch destination, because it is not always concrete (for example jmp reg).
The semantic handlers are registered globally:
# src/striga/semantic.py
SemanticFn: TypeAlias = Callable[["Semantics"], list[Successor] | None]
_semantics: dict[str, SemanticFn] = {}
def semantic(fn: SemanticFn):
name = getattr(fn, "__name__")
_semantics[name.removesuffix("_")] = fn
return fn
# src/striga/x86/data.py
@semantic
def mov(sem: Semantics):
value = sem.op_read(1)
sem.op_write(0, value)
Every handler gets an instance of Semantics, to allow easy access to x86 constructs like operands, registers, flags and memory. For example, op_read is implemented as follows:
def op_read(self, index: int) -> Value:
op: X86Op = self.insn.operands[index]
if op.type == CS_OP_REG:
name = self.reg_name(op.reg) # pyright: ignore[reportAssignmentType]
return self.reg_read(name)
if op.type == CS_OP_IMM:
return self.const_n(op.imm, op.size * 8)
if op.type == CS_OP_MEM:
addr = self.op_mem(op)
return self.mem_read(addr, self.types.int_n(op.size * 8))
assert False
For our example mov rax, rcx, the function will forward to reg_read:
def reg_read(self, name: str) -> Value:
if name in self.reg_types:
load = self.ir.load(self.reg_types[name], self.reg_ptr(name))
load.metadata["tbaa"] = self.tbaa_tags[name]
return load
full_name, size, bit_offset = self.subregs[name]
load = self.ir.load(self.reg_types[full_name], self.reg_ptr(full_name))
load.metadata["tbaa"] = self.tbaa_tags[full_name]
if bit_offset:
load = self.ir.lshr(load, self.const64(bit_offset))
return self.ir.trunc(load, self.types.int_n(size))
This function transparently handles accesses to sub registers like eax, ax, al and ah and it returns an LLVM Value containing the loaded register value. The last missing piece is the reg_ptr function, which is responsible for creating the getelementptr in the function entry:
def reg_ptr(self, name: str) -> Value:
reg_ptr = self.reg_ptrs.get(name)
if reg_ptr is not None:
return reg_ptr
entry = self.function.entry_block
state = self.function.get_param(0)
with entry.create_builder() as ir:
ir.position_before(entry.terminator)
reg_ptr = ir.struct_gep(self.state_ty, state, self.reg_indices[name], name)
self.reg_ptrs[name] = reg_ptr
return reg_ptr
To help the optimizer we add TBAA Metadata to the register load/store instructions. In this case we know that a register loads/stores never alias with each other. By telling the optimizer about this, it can perform more aggressive dead-store elimination when optimizing a sequence of lifted instructions.
Semantics
So far we discussed the architecture of the lifter, but we only discussed the mov instruction so far. Almost every other instruction has more complex behavior, especially around flag handling. For instance here are the implementations of and/or/xor:
# src/striga/x86/bitwise.py
def write_logical_flags(sem: Semantics, result: Value):
false = sem.const_n(0, 1)
sem.flag_write("cf", false)
sem.flag_write("pf", sem.result_parity_even(result))
sem.flag_write_undef("af")
sem.flag_write("zf", sem.result_is_zero(result))
sem.flag_write("sf", sem.result_sign_bit(result))
sem.flag_write("of", false)
def logical_binop(sem: Semantics, opcode: Opcode):
dst = sem.op_read(0)
src = sem.resize_int(sem.op_read(1), dst.type)
result = sem.ir.binop(opcode, dst, src)
sem.op_write(0, result)
write_logical_flags(sem, result)
@semantic
def and_(sem: Semantics):
logical_binop(sem, Opcode.And)
@semantic
def or_(sem: Semantics):
logical_binop(sem, Opcode.Or)
@semantic
def xor(sem: Semantics):
logical_binop(sem, Opcode.Xor)
For reference here is the lifted LLVM IR for xor rax, rbx and the Python code responsible for each part:
insn_0x140001000: ; preds = %initialize
; dst = sem.reg_read(0)
%0 = load i64, ptr %rax, align 4
; src = sem.resize_int(sem.op_read(1), dst.type)
%1 = load i64, ptr %rbx, align 4
; result = sem.ir.binop(Opcode.Xor, dst, src)
%2 = xor i64 %0, %1
; sem.op_write(0, result)
store i64 %2, ptr %rax, align 4
; sem.flag_write("cf", false)
store i8 0, ptr %cf, align 1
; sem.flag_write("pf", sem.result_parity_even(result))
%3 = trunc i64 %2 to i8
%4 = lshr i8 %3, 4
%5 = xor i8 %3, %4
%6 = lshr i8 %5, 2
%7 = xor i8 %5, %6
%8 = lshr i8 %7, 1
%9 = xor i8 %7, %8
%10 = and i8 %9, 1
%11 = icmp eq i8 %10, 0
%12 = zext i1 %11 to i8
store i8 %12, ptr %pf, align 1
; sem.flag_write_undef("af")
%13 = call i1 @__striga_undef_af(i64 5368713216)
%14 = zext i1 %13 to i8
store i8 %14, ptr %af, align 1
; sem.flag_write("zf", sem.result_is_zero(result))
%15 = icmp eq i64 %2, 0
%16 = zext i1 %15 to i8
store i8 %16, ptr %zf, align 1
; sem.flag_write("sf", sem.result_sign_bit(result))
%17 = lshr i64 %2, 63
%18 = trunc i64 %17 to i1
%19 = zext i1 %18 to i8
store i8 %19, ptr %sf, align 1
; sem.flag_write("of", false)
store i8 0, ptr %of, align 1
; Semantics.lift_bytes
br label %insn_0x140001003
If you pay close attention you see a call to __striga_undef_af, which is a custom intrinsic used to represent something that has no clear analog in LLVM IR. In this case the description of the xor instruction says:
The OF and CF flags are cleared; the SF, ZF, and PF flags are set according to the result. The state of the AF flag is undefined.
This means that Intel/AMD does not want to document exactly how the value of AF is computed in silicon. In practice this can vary between CPU models/generations and it can be used as an anti-emulation trick, but we will not go into detail in this post. We emit __striga_undef_af, to allow the user to handle this however they see fit. If you are interested there is remill#766 with a little discussion about how to model this correctly.
Another class of instructions to highlight here is the various branch instructions:
# src/striga/x86/control.py
def conditional_jump(sem: Semantics, cond: Value):
brtrue = sem.insn.operands[0].imm
brfalse = sem.insn.address + sem.insn.size
sem.ir.cond_br(
cond,
sem.get_or_create_block(brtrue),
sem.get_or_create_block(brfalse),
)
src = sem.insn.address
return [
Successor(src, sem.const64(brtrue)),
Successor(src, sem.const64(brfalse)),
]
def jcc(sem: Semantics, cc: str):
return conditional_jump(sem, cc_cond(sem, cc))
@semantic
def je(sem: Semantics):
return jcc(sem, "e")
@semantic
def jmp(sem: Semantics):
dst = sem.op_read(0)
if dst.is_constant:
sem.ir.br(sem.get_or_create_block(dst.const_zext_value))
else:
sem.ir.call(sem.jmp_handler, [dst])
sem.ir.ret_void()
return [Successor(sem.insn.address, dst)]
@semantic
def call(sem: Semantics):
dst = sem.op_read(0)
fallthrough = sem.insn.address + sem.insn.size
sem.push(sem.const64(fallthrough))
sem.ir.call(sem.call_handler, [dst])
sem.ir.br(sem.get_or_create_block(fallthrough))
return [Successor(sem.insn.address, sem.const64(fallthrough))]
@semantic
def ret(sem: Semantics):
dst = sem.pop(sem.i64)
if sem.insn.operands:
rsp = sem.reg_read("rsp")
sem.reg_write("rsp", sem.ir.add(rsp, sem.const64(sem.insn.operands[0].imm)))
sem.ir.call(sem.ret_handler, [dst])
sem.ir.ret_void()
return [Successor(sem.insn.address, dst)]
LLVM IR for je imm:
insn_0x140001000: ; preds = %initialize
%0 = load i8, ptr %zf, align 1
%1 = icmp ne i8 %0, 0
br i1 %1, label %insn_0x140001014, label %insn_0x140001002
insn_0x140001014: ; preds = %insn_0x140001000
ret void
insn_0x140001002: ; preds = %insn_0x140001000
ret void
}
Note that the semantic handler for jcc is responsible for creating both the destination blocks as well as the br with the appropriate condition based on the flag(s).
LLVM IR for jmp rbx:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rbx, align 4
call void @__striga_jmp(i64 %0)
ret void
LLVM IR for call imm:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rsp, align 4
%1 = sub i64 %0, 8
store i64 %1, ptr %rsp, align 4
%2 = getelementptr i8, ptr %memory, i64 %1
store i64 5368713221, ptr %2, align 1
call void @__striga_call(i64 5369761797)
br label %insn_0x140001005
LLVM IR for ret:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rsp, align 4
%1 = getelementptr i8, ptr %memory, i64 %0
%2 = load i64, ptr %1, align 1
%3 = add i64 %0, 8
store i64 %3, ptr %rsp, align 4
call void @__striga_ret(i64 %2)
ret void
}
As you can see, we use the following intrinsics:
__striga_jmp: indirect jump__striga_call: call instruction__striga_ret: ret instruction
These are also used to give the user flexibility in how they want to handle these instructions.
Control flow
Because of the design choice where every instruction is a basic block, it becomes fairly straightforward to recover the control flow of a basic function:
def lift(module: Module, container: Container, start: int, *, verbose=True):
sem = Semantics(module, verbose=verbose)
lifted_fn = sem.begin(start)
queue: Queue[Successor] = Queue()
queue.put(Successor(0, sem.const64(start)))
# Keep destinations as LLVM Values instead of splitting constants into ints.
# This keeps the worklist uniform and matches later slicing/data-flow uses.
visited: set[Value] = set()
while not queue.empty():
src, dst = queue.get()
if not dst.is_constant:
if sem.verbose:
print(f"; non-constant branch destination: {hex(src)} -> {dst}")
continue
if dst in visited:
continue
visited.add(dst)
va = dst.const_zext_value
code = container.get_data(va, 15)
successors = sem.lift_bytes(va, code)
for successor in successors:
if successor.dst in visited:
continue
queue.put(successor)
sem.module.verify_or_raise()
return lifted_fn
This is a simple Breadth-first search over the control flow graph and it allows recovering functions without indirect branches. Note that we do not have to do anything special to handle back edges (loops) or block splitting. The lifted code is modeled with an LLVM basic block per instruction, so we can connect instructions arbitrarily.
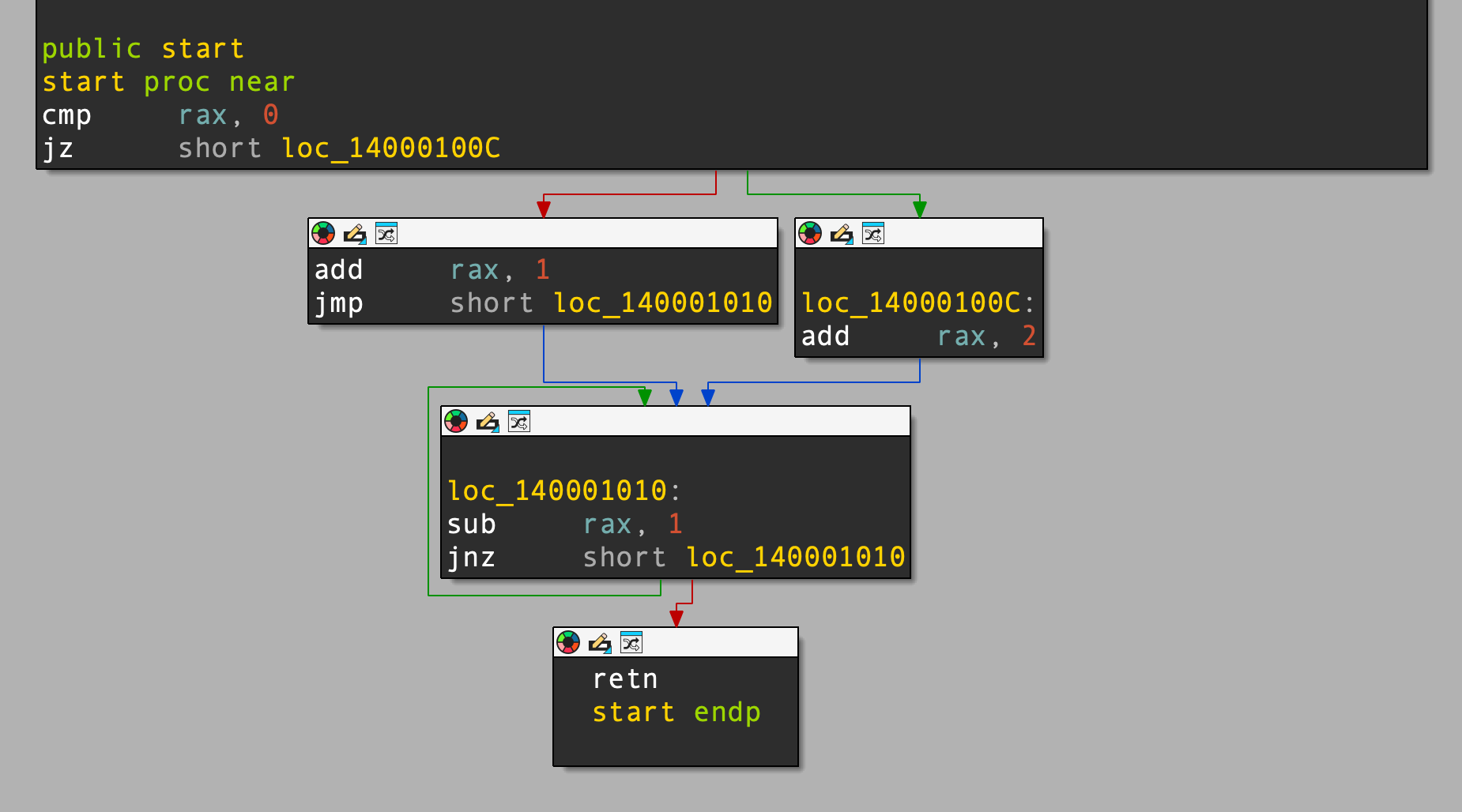
Below is a function with some simple control flow (if/else/loop):
test_cfg:
cmp rax, 0
je .else_block
.if_true:
add rax, 1
jmp .merge
.else_block:
add rax, 2
.merge:
sub rax, 1
jne .merge
.exit:
ret
The graph of the disassembly looks like this:
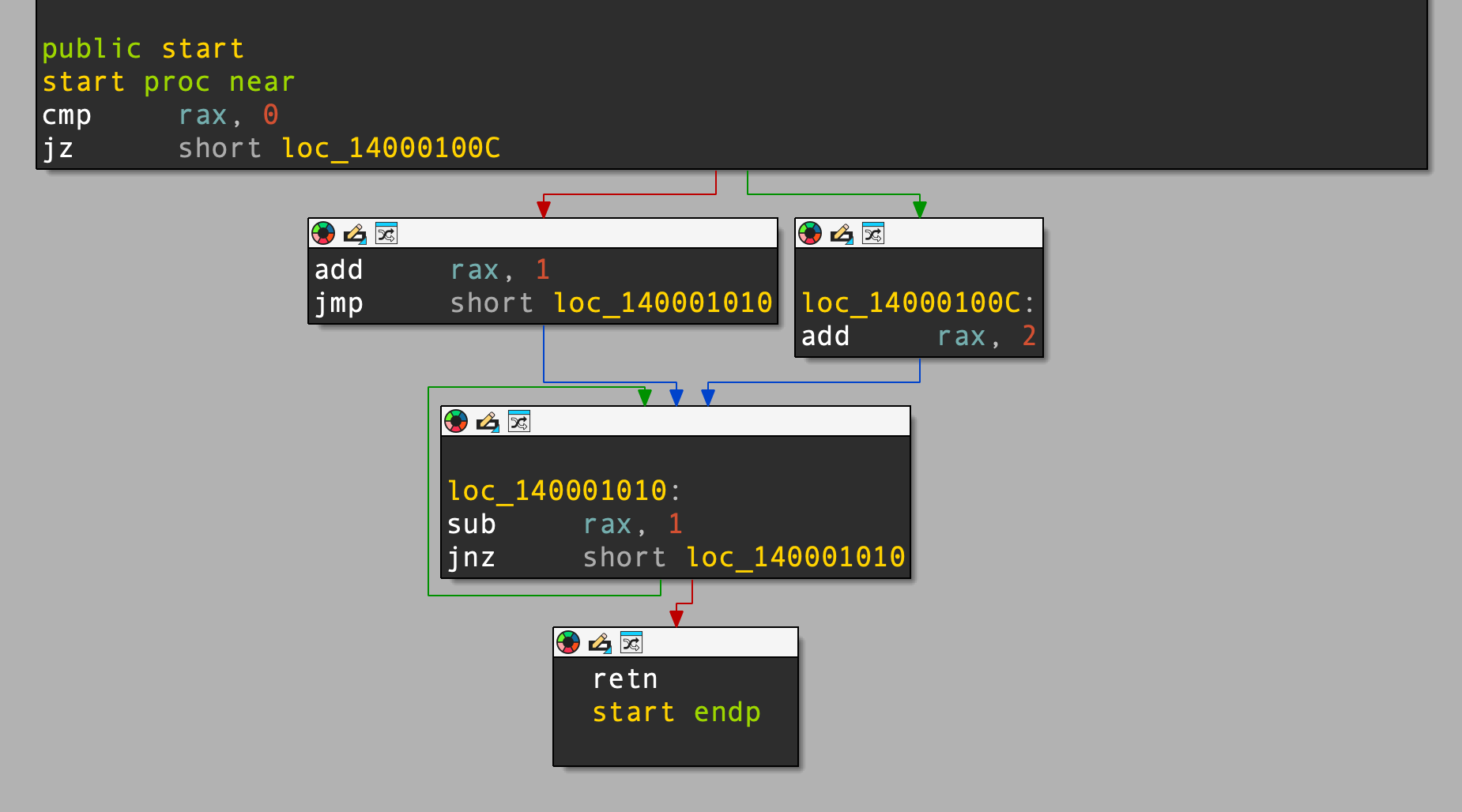
The LLVM IR looks like this:
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
%zf = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 51
%rsp = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 6
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; cmp rax, 0
%0 = load i64, ptr %rax, align 4
%1 = sub i64 %0, 0
%19 = icmp eq i64 %1, 0
%20 = zext i1 %19 to i8
store i8 %20, ptr %zf, align 1
br label %insn_0x140001004
insn_0x140001004: ; preds = %insn_0x140001000
; je 0x14000100c
%30 = load i8, ptr %zf, align 1
%31 = icmp ne i8 %30, 0
br i1 %31, label %insn_0x14000100c, label %insn_0x140001006
insn_0x14000100c: ; preds = %insn_0x140001004
; add rax, 2
%32 = load i64, ptr %rax, align 4
%33 = add i64 %32, 2
store i64 %33, ptr %rax, align 4
br label %insn_0x140001010
insn_0x140001006: ; preds = %insn_0x140001004
; add rax, 1
%62 = load i64, ptr %rax, align 4
%63 = add i64 %62, 1
store i64 %63, ptr %rax, align 4
br label %insn_0x14000100a
insn_0x140001010: ; preds = %insn_0x140001014, %insn_0x14000100a, %insn_0x14000100c
; sub rax, 1
%92 = load i64, ptr %rax, align 4
%93 = sub i64 %92, 1
store i64 %93, ptr %rax, align 4
%111 = icmp eq i64 %93, 0
%112 = zext i1 %111 to i8
store i8 %112, ptr %zf, align 1
br label %insn_0x140001014
insn_0x14000100a: ; preds = %insn_0x140001006
; jmp 0x140001010
br label %insn_0x140001010
insn_0x140001014: ; preds = %insn_0x140001010
; jne 0x140001010
%122 = load i8, ptr %zf, align 1
%123 = icmp ne i8 %122, 0
%124 = xor i1 %123, true
br i1 %124, label %insn_0x140001010, label %insn_0x140001016
insn_0x140001016: ; preds = %insn_0x140001014
; ret
%125 = load i64, ptr %rsp, align 4
%126 = getelementptr i8, ptr %memory, i64 %125
%127 = load i64, ptr %126, align 1
%128 = add i64 %125, 8
store i64 %128, ptr %rsp, align 4
call void @__striga_ret(i64 %127)
ret void
}
For clarity, some flag computations were omitted from this IR dump.
Brightening
Brightening was a term coined in 2019 by Peter Garba and Matteo Favaro in the SATURN paper:
Brightening [COMP.] verb – Reshaping code to make it more readable and understandable for humans
Concretely it means to transform the LLVM IR from the lifted shape (pseudo C):
/*
Lifted instructions:
add rdi, rsi
mov rax, rdi
ret
*/
void lifted(State* state, void* memory) {
state.rdi += state.rsi;
state.rax = state.rdi;
__striga_ret(...);
}
Back to a regular function for the lifted platform’s calling convention, such as:
// Linux calling convention: https://wiki.osdev.org/System_V_ABI#x86-64
uint64_t /* rax */ brightened(uint64_t /* rdi */ x, uint64_t /* rsi */ y) {
return x + y;
}
The brightened function sets up the State on the stack and assigns the arguments to the registers appropriate for the calling convention of our target platform. The result register is returned from the function. Conceptually this is not very difficult, but it requires a bit of mental gymnastics to wrap your head around the trick:
// Symbolic variable for memory
uint8_t RAM[0];
void lifted(State* state, void* memory) { ... }
uint64_t brightened(uint64_t x, uint64_t y) {
State state;
state.rdi = x;
state.rsi = y;
lifted(&state, RAM);
return state.rax;
}
After an inlining pass it would look something like this:
uint64_t brightened(uint64_t x, uint64_t y) {
State state;
state.rdi = x;
state.rsi = y;
state.rdi += state.rsi;
state.rax = state.rdi;
__striga_ret(...);
return state.rax;
}
We can get rid of the __striga_ret intrinsic in this case, which will let the optimizer reduce the function to its original shape:
uint64_t brightened(uint64_t x, uint64_t y) {
return x + y;
}
LLVM IR before optimizations:
define i64 @brightened_0x1000(i64 %0, i64 %1) {
entry:
%state = alloca %State, align 8
%rdi = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 5
store i64 %0, ptr %rdi, align 4
%rsi = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 4
store i64 %1, ptr %rsi, align 4
%stack = alloca i8, i64 4096, align 1
%2 = getelementptr i8, ptr %stack, i64 4088
%3 = ptrtoint ptr %2 to i64
%rsp = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 6
store i64 %3, ptr %rsp, align 4
store i64 3735928559, ptr %2, align 1
call void @lifted_0x1000(ptr %state, ptr @RAM)
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
%4 = load i64, ptr %rax, align 4
ret i64 %4
}
After optimizing the module with default<O1>:
define i64 @brightened_0x1000(i64 %0, i64 %1) {
entry:
%2 = add i64 %1, %0
ret i64 %2
}
Memory / Stack
To handle memory accesses, we create a global RAM variable and pass that to our memory argument. In the previous example it folded away, but we need to handle it separately. The simplest form is access to a pointer parameter:
uint64_t lift4_read(uint64_t *n) {
return *n ^ 1337;
}
With our current brightening strategy the lifted code (after optimizations) would look like this:
define i64 @brightened_0x1000(i64 %0) {
entry:
%1 = getelementptr i8, ptr @RAM, i64 %0
%2 = load i64, ptr %1, align 1, !alias.scope !19, !noalias !22
%3 = xor i64 %2, 1337
ret i64 %3
}
We need to detect the getelementptr i8, ptr @RAM, i64 %0 shape and replace it with an inttoptr instruction:
define i64 @brightened_0x1000(i64 %0) {
entry:
%1 = inttoptr i64 %0 to ptr
%2 = load i64, ptr %1, align 1, !alias.scope !19, !noalias !22
%3 = xor i64 %2, 1337
ret i64 %3
}
The stack can be modeled by allocating a local stack variable and pointing rsp to the end of that buffer (since on x86 the stack grows towards lower addresses):
uint64_t brightened(uint64_t x, uint64_t y) {
uint8_t stack[4096];
State state;
state.rdi = x;
state.rsi = y;
state.rsp = (uint64_t)&stack[sizeof(stack) - 8];
lifted(&state, RAM);
return state.rax;
}
Putting everything together in brighten.py:
from llvm import Linkage, Module, Opcode, Value, global_context
from bfs import lift_bfs
from container import Container, RawContainer
OPT_PIPELINE = "default<O1>"
def rewrite_ram_geps(module: Module, ram: Value):
"""Replace GEPs rooted at @RAM with inttoptr(address)."""
types = module.context.types
for gep in ram.users:
if not gep.is_instruction or gep.opcode != Opcode.GetElementPtr:
raise ValueError(f"unexpected @RAM user: {gep}")
if gep.get_operand(0) != ram:
raise ValueError(f"unexpected @RAM GEP base: {gep}")
if gep.num_operands == 2:
if gep.gep_source_element_type != types.i8:
raise ValueError(f"expected i8 ptradd-style @RAM GEP: {gep}")
address = gep.get_operand(1)
elif gep.num_operands == 3:
zero = gep.get_operand(1)
if not zero.is_constant_int or zero.const_zext_value != 0:
raise ValueError(f"expected zero first @RAM GEP index: {gep}")
address = gep.get_operand(2)
else:
raise ValueError(f"unexpected @RAM GEP shape: {gep}")
with gep.create_builder() as ir:
ptr = ir.inttoptr(address, types.ptr)
gep.replace_all_uses_with(ptr)
gep.erase_from_parent()
if not ram.users:
ram.delete_global()
module.verify_or_raise()
def define_ret_stub(module: Module):
"""Make the modeled return hook removable for this demo wrapper."""
ret_handler = module.get_function("__striga_ret")
if ret_handler is not None and ret_handler.is_declaration:
ret_handler.linkage = Linkage.Internal
entry = ret_handler.append_basic_block("entry")
with entry.create_builder() as ir:
ir.ret_void()
def lift_brightened(container: Container, entry: int, args: list[str]):
with global_context().create_module("blog") as module:
sem = lift_bfs(module, container, entry, verbose=True)
# Convenience aliases
types = module.context.types
i8 = types.i8
i64 = types.i64
# Global RAM array
ram = module.add_global(types.array(i8, 0), "RAM")
# TODO: support different register sizes
brightened_ty = types.function(i64, [i64 for _ in args])
brightened = module.add_function(f"brightened_{hex(entry)}", brightened_ty)
with brightened.create_builder() as ir:
state = ir.alloca(sem.state_ty, "state")
def reg_ptr(name: str) -> Value:
return ir.struct_gep(sem.state_ty, state, sem.reg_indices[name], name)
# Assign arguments to register state
for i, name in enumerate(args):
ir.store(brightened.get_param(i), reg_ptr(name))
# Set up function stack
stack = ir.alloca(i8, i64.constant(4096), "stack")
stack_ptr = ir.gep(i8, stack, [i64.constant(4096 - 8)])
ir.store(ir.ptrtoint(stack_ptr, i64), reg_ptr("rsp"))
# Set up return address
retaddr_store = ir.store(i64.constant(0xDEADBEEF), stack_ptr)
retaddr_store.inst_alignment = 1
# Call lifted function
ir.call(sem.function, [state, ram])
# Load return value from rax and return it
ir.ret(ir.load(i64, reg_ptr("rax")))
module.verify_or_raise()
# 1. Inline/optimize with @RAM assigned to the lifted memory parameter.
module.optimize(OPT_PIPELINE)
# 2. Brighten lifted memory: @RAM + integer address -> inttoptr(address).
rewrite_ram_geps(module, ram)
# 3. Now that RAM accesses have been brightened, discard the modeled ret
# hook for this demo and let LLVM clean up the remaining wrapper noise.
# Undefined flag helpers are already declared memory(none) by Semantics,
# so their dead uses fold away without local stub definitions.
define_ret_stub(module)
module.verify_or_raise()
module.optimize(OPT_PIPELINE)
print(brightened)
This cleanly lifts the following (unoptimized) function:
; 0x1000 push rbp
; 0x1001 mov rbp, rsp
; 0x1004 mov qword ptr [rbp - 8], rdi
; 0x1008 mov rax, qword ptr [rbp - 8]
; 0x100c pop rbp
; 0x100d ret
define i64 @brightened_0x1000(i64 returned %0) {
entry:
ret i64 %0
}
Conclusion
Hopefully this was an insightful introduction to lifting to LLVM IR. Feel free to check out the repository at LLVMParty/striga and reach out if you do something interesting with it!
Note: Striga is not meant to be a production-ready lifter. There are no tests and only a very limited subset of x86 has been implemented.
Thanks to the reviewers:
LLVM IR references:
- A Gentle Introduction to LLVM IR
- A Journey to understand LLVM-IR!
- Mapping High Level Constructs to LLVM IR
- IR is better than assembly
- Introduction to LLVM
- Learning LLVM Part 1, Part 2
- LLVM Passes for Security Part 1, Part 2, Part 3, Part 4