大模型在 AIME、IMO 等高难度竞赛中拿奖拿到手,仿佛已经进化出了“人类最强大脑”。但与此同时,如果你问大模型:“离洗车店只有 50 米,我是开车去还是走路去?”。这些号称满分推理的模型,依然会一 2026-5-15 00:0:0 Author: tech.meituan.com(查看原文) 阅读量:11 收藏
大模型在 AIME、IMO 等高难度竞赛中拿奖拿到手,仿佛已经进化出了“人类最强大脑”。但与此同时,如果你问大模型:“离洗车店只有 50 米,我是开车去还是走路去?”。这些号称满分推理的模型,依然会一本正经地为你规划导航路线。
这种看似知识丰富,但没常识的现象,正是当前大模型评测的死穴:大模型虽然擅长记忆复杂的公式,却常常连一道简单的逻辑题都答不对。

基于此,美团 LongCat 团队正式发布 General 365。我们发现,在对 26 款主流模型的实测中,目前地表最强的 Gemini 3 Pro 准确率仅为 62.8%,而绝大多数模型甚至没能摸到 60 分的及格线。
这份基准将焦点从“学科推理”拓展到“通用推理”,第一次清晰地勾勒出了当前大模型在通用逻辑推理上的真实能力边界。
01 研究背景:大模型真的会“思考”吗?
过去两年,大模型推理评测高度集中在数学、物理、编程等依赖专业知识的任务上,头部模型在各大题库上甚至逼近满分。然而,学科推理得分高,并不等于通用推理强——高分可能源于模型对训练语料的暴力记忆与模式匹配,而非可泛化的逻辑推演能力。现有通用推理基准(如 BBH、BBEH)面临两大瓶颈:任务模板化导致逻辑同质严重,性能饱和导致区分度断崖式下降。
General 365 的设计目标由此明确:将背景知识限定在 K-12 水平,显式解耦推理能力与专业知识,系统地评估模型在日常场景下的通用推理水平。它具备五项核心特征:
- 高多样性:365 道原创种子题目及 1095 个扩展变体,全面覆盖八大挑战类型,避免重复特征与死记硬背;
- 高挑战性:SOTA 模型在此基准上也仅能勉强及格;
- 聚焦推理:知识范围严格限定在 K-12,纯粹衡量逻辑推理,而非知识检索;
- 严格人工质检:全量题目均经过人工审核,覆盖题目设计、推理轨迹与最终答案;
- 精准评分:采用混合规则与模型的打分方法,人工抽样验证,评分准确率达 99.6%。
02 设计理念:通用推理能力如何被量化?
2.1 八大维度,圈定通用推理的“考纲”
要衡量通用推理,首先要明确它包含哪些核心挑战?General 365 将其拆解为八个维度,每道题至少对应其一:
- 复杂约束:多条件交织下的全局一致性维护;
- 分支与枚举:解空间的系统性遍历与边界覆盖;
- 时空推理:空间关系与时间序列的动态推演;
- 递归与回溯:假设—验证—推翻的迭代纠错;
- 语义干扰:跨越认知陷阱,严格遵循题设规则;
- 隐式信息:从碎片线索推断底层逻辑结构;
- 最优策略:多路径方案中的效用权衡与规划;
- 概率与不确定性:不完全信息下的概率推断。

如上图所示,“复杂约束类”题目占比最大,“概率与不确定性类”也包含超 20 道题目,确保了每个维度都有充足的样本支撑。

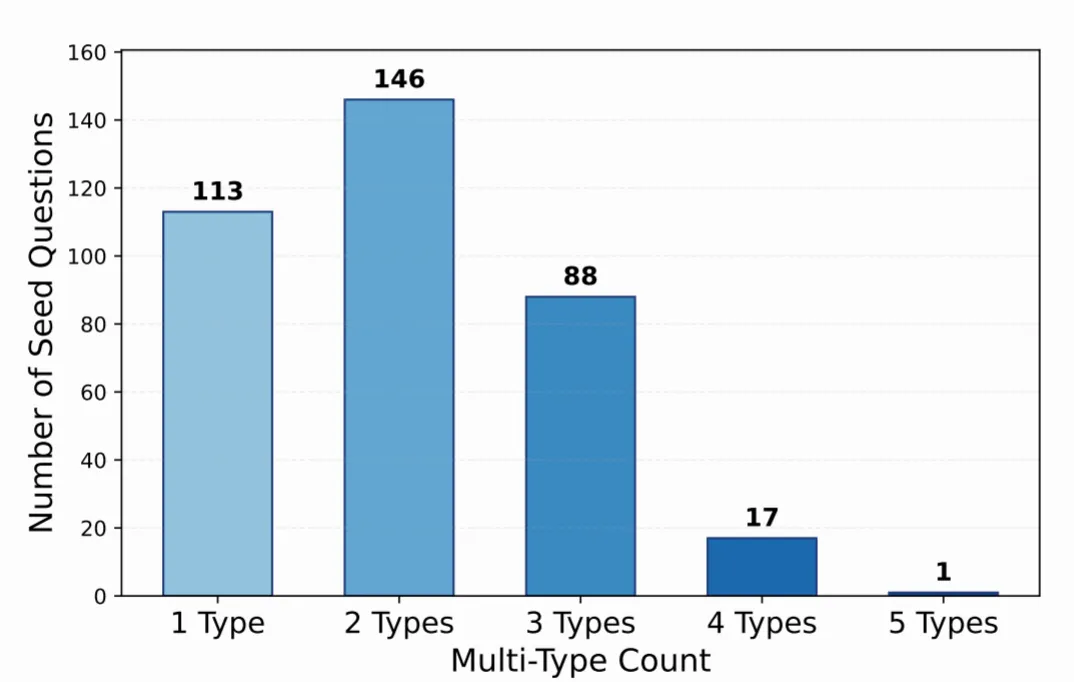
如图所示,近 70% 的题目同时具备两个或以上的类别标签,这种复合型的推理任务设计更贴近真实世界的逻辑复杂度。
2.2 告别模板化,经得起检验的多样性
题目质量是评测基准可靠性的根基。General 365 的种子题目全部人工原创,并经难度过滤、多样性扩充、数据后处理、模型扩题与人工审核,最终形成 1460 道高质量题目。为确保多样性经得起检验,团队从以下两个维度进行了验证:
- 语义分布:t-SNE 可视化中 General 365 的题目嵌入的分布均匀分散,而 BBH 和 BBEH 均出现明显的聚集现象,暴露了其潜在的逻辑冗余。

- 逻辑独立性:由 Gemini 3 Pro 对语义相近的题目对进行推理路径相似度评分(0-5 分),General 365 平均仅得 2.16 分,远低于 BBH 和 BBEH。这意味着在 General 365 中,模型无法再靠”背模板”蒙混过关。

03 实验发现:26款模型的能力边界与效率分化
手握这把精心校准的“标尺”,LongCat 团队对 26 款主流大模型展开了全面摸底。
3.1 整体表现:Gemini 3 Pro领跑,仅2款模型“及格”

实测结果显示,Gemini 3 Pro 以 62.8% 的成绩艰难夺冠,绝大多数模型则深陷 50%-60% 之间未能触及及格线。值得注意的是,尽管非推理模型整体略逊一筹,但 Qwen 3 Max Instruct 等个别模型依然展现出了亮眼的表现。
3.2 寻根溯源:到底错在哪里?

将成绩按八大维度分解后,我们清晰地看到,“语义干扰”与“最优策略”成为主要的性能洼地。模型在这两项上的得分普遍比整体准确率低了约 10 个百分点。这不仅暴露出大模型极易被题干中的干扰信息带偏,更凸显了其在多步全局规划能力上的匮乏。

如雷达图所示,不同系列的模型在”隐式信息”等任务上展现出了明显的能力分化。
3.3 谁是真正的“效率之王”

在关注“答得对不对”的同时,“花了多少算力答对”同样重要。如图所示,Gemini 3 Pro 仅用约 14k tokens 就拿下了最高分,而取得相近准确率的其他模型,其输出长度普遍暴涨至 25k-30k tokens。
3.4 跨基准对比:General 365的难度含金量

General 365 的难度究竟提升了多少?如图09横向对比所示,各大模型在 General 365 上的准确率较 BBH/BBEH 都普遍出现了大幅下降的情况。其中 GPT-5-Thinking 在 BBH 上准确率为 92.0%,在 General 365 上仅为 58.6%。
更重要的是,如下图所示,模型在 General 365 上虽然准确率明显偏低,但平均输出长度却显著增加。这有力证实了其难度来自更深的逻辑链条,而非毫无意义的字数堆砌。

04 结语:通用推理的“深水区”,才刚刚被照亮
General 365 将推理评测从专业知识依赖中剥离出来,让我们直观地看到了大模型在真实世界的通用推理任务上的短板。General 365 的初衷不是为了在榜单上再多一个 99% 的高分,而是为了寻找那条让模型从“做题机器”走向“人类智慧”的必经之路。毕竟,一个能解出 IMO 难题却回答不出「走路洗车」的模型,还不能被称为真正的智能。
我们诚邀广大社区开发者与研究者加入,共同探寻大模型逻辑进化的下一个奇点。
开源链接
项目已全面开源,并会持续维护和更新,欢迎体验与探讨:
- Paper:https://arxiv.org/abs/2604.11778
- GitHub:https://github.com/meituan-longcat/General365
- HuggingFace:https://huggingface.co/datasets/meituan-longcat/General365_Public
- Project Page:https://general365.github.io

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 [email protected] 申请授权。
如有侵权请联系:admin#unsafe.sh