浏览器里跑 Gemma 4:不用 API、不花钱,无限量生成 Excalidraw 流程图
好的,我现在要帮用户总结这篇文章的内容。首先,我需要仔细阅读文章,理解它的主要信息和重点。 文章主要讲的是Gemma 4大模型现在可以在浏览器上运行了。开发者用了Google的TurboQuant算法,把模型放进浏览器里。这样用户可以直接在Excalidraw里用AI画图,而且整个过程都在本地完成,不需要调用在线模型,也不消耗Token。不过需要下载3.1GB的模型,并且使用Chrome 134+版本。 接下来,文章详细介绍了如何使用这个功能,包括链接和使用步骤。生成速度方面,每秒生成约24个token,总耗时32.9秒。KV Cache从37MB压缩到15.5MB,压缩比约2.4倍。TurboQuant算法的作用是压缩向量并直接搜索压缩数据,让大模型记住更长的上下文。 这意味着像Excalidraw这样的应用可以本地运行AI,节省成本和资源。用户的问题是询问还有哪些类似的服务。 现在我要总结这些内容,控制在100字以内。需要涵盖Gemma 4在浏览器运行、TurboQuant算法、本地运行、下载要求、速度和KV Cache优化。 可能的结构:开发者利用TurboQuant在浏览器运行Gemma 4,支持本地AI绘图,需下载3.1GB模型和Chrome 134+版本。速度方面每秒生成约24个token,KV Cache压缩至15.5MB。 检查字数是否在限制内,并确保信息准确全面。 </think> 开发者通过Google的TurboQuant算法,在浏览器中实现了Gemma 4大模型的本地运行,支持直接在Excalidraw中用AI绘图。需下载3.1GB模型并使用Chrome 134+版本。每秒生成约24个token,KV Cache压缩至15.5MB。 2026-4-26 05:54:45 Author: www.appinn.com(查看原文) 阅读量:38 收藏
好的,我现在要帮用户总结这篇文章的内容。首先,我需要仔细阅读文章,理解它的主要信息和重点。 文章主要讲的是Gemma 4大模型现在可以在浏览器上运行了。开发者用了Google的TurboQuant算法,把模型放进浏览器里。这样用户可以直接在Excalidraw里用AI画图,而且整个过程都在本地完成,不需要调用在线模型,也不消耗Token。不过需要下载3.1GB的模型,并且使用Chrome 134+版本。 接下来,文章详细介绍了如何使用这个功能,包括链接和使用步骤。生成速度方面,每秒生成约24个token,总耗时32.9秒。KV Cache从37MB压缩到15.5MB,压缩比约2.4倍。TurboQuant算法的作用是压缩向量并直接搜索压缩数据,让大模型记住更长的上下文。 这意味着像Excalidraw这样的应用可以本地运行AI,节省成本和资源。用户的问题是询问还有哪些类似的服务。 现在我要总结这些内容,控制在100字以内。需要涵盖Gemma 4在浏览器运行、TurboQuant算法、本地运行、下载要求、速度和KV Cache优化。 可能的结构:开发者利用TurboQuant在浏览器运行Gemma 4,支持本地AI绘图,需下载3.1GB模型和Chrome 134+版本。速度方面每秒生成约24个token,KV Cache压缩至15.5MB。 检查字数是否在限制内,并确保信息准确全面。 </think> 开发者通过Google的TurboQuant算法,在浏览器中实现了Gemma 4大模型的本地运行,支持直接在Excalidraw中用AI绘图。需下载3.1GB模型并使用Chrome 134+版本。每秒生成约24个token,KV Cache压缩至15.5MB。 2026-4-26 05:54:45 Author: www.appinn.com(查看原文) 阅读量:38 收藏
手机上能跑 Gemma 4 大模型已经不新鲜了(iPhone、安卓现在就能跑 Gemma 4 了),现在浏览器也可以了。@Appinn
有开发者利用 Google 新提出的 TurboQuant 算法,把 Gemma 4 放进浏览器里运行。
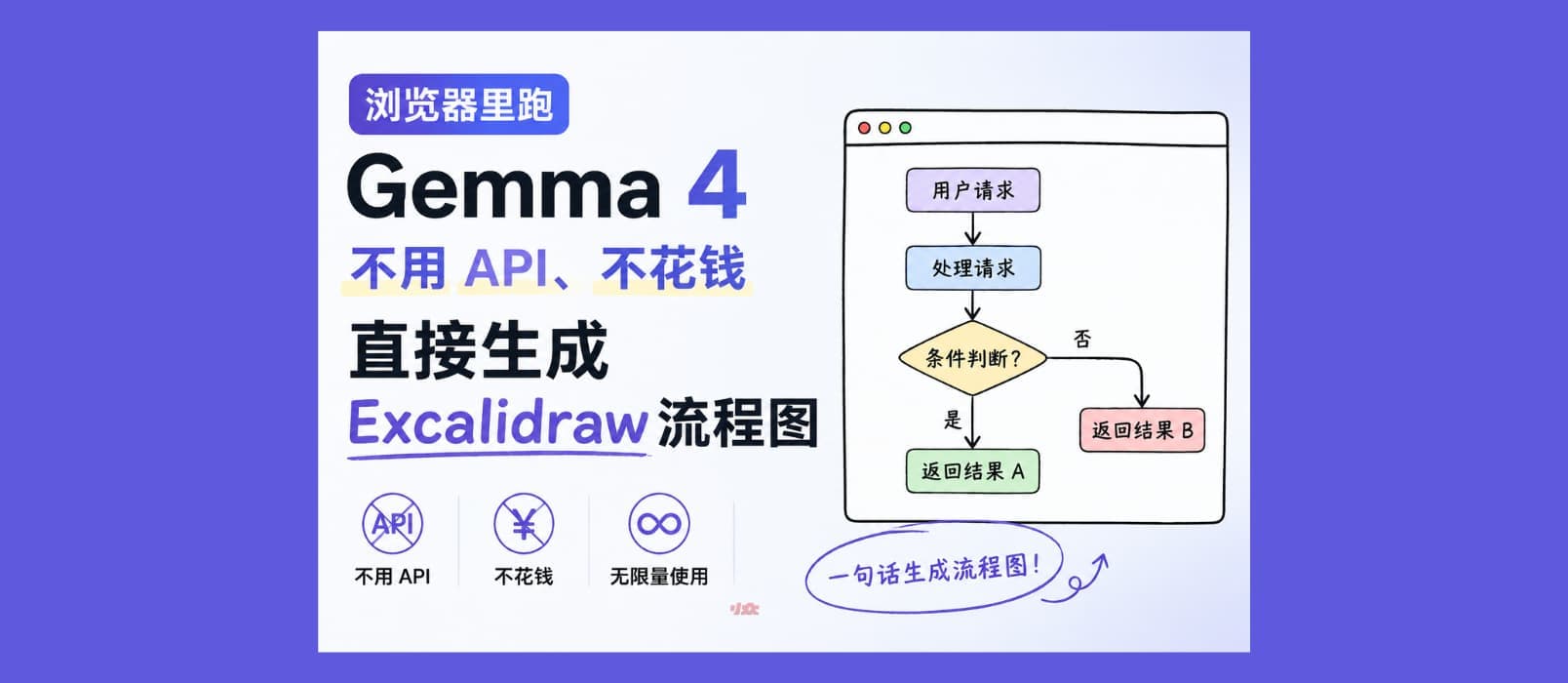
直接打开网页,就能在 Excalidraw 里用 AI 画图,而且整个过程都在本地完成,不需要调用在线模型,也不消耗任何 Token。
唯一代价:需要下载 3.1GB 的 Gemma 4 E2B 大模型。另外需要桌面版 Chrome 134+ 版本。

如何使用?
直接打开网页用:
直接输入中文用:

32.9秒,就能生成一张完整的流程图,不需要自己画框、连线。
跑起来怎么样?
- 速度:每秒生成约 24 个 token
- 端到端速度(end-to-end):每秒约 22.7 个 token(包括准备、计算等)
- 输出长度:这次一共生成了 747 个 token
- 总耗时:32.9 秒
- KV Cache:15.5MB / 37.0MB
- 当前上下文长度:2106 pos(模型已经“记住”的 token 数量)
KV Cache 从原本约 37MB,压缩到约 15MB 左右(约 2.4 倍压缩)。
不过这样一个简单的例子需要 37MB 的 KV Cache,青小蛙也是第一次感受到。
TurboQuant 是什么?
TurboQuant 是 Google 最近推出的新算法,它可以将 KV Cache 里的向量压缩 6 倍,并可以直接搜索压缩数据,无需解压缩。
这样大模型就可以记住更长的上下文,回答更长的对话,也更不容易“忘记前面说过的话”。
- KV Cache:大模型在对话时用来“记住前面内容”的一块临时记忆。
- 向量:大模型理解文字的方式:我们对AI说话,会先被转换成一串数字,然后才能让大模型理解,这些数字,就是向量。
意味着什么?
像 Excalidraw 这样的应用,以前如果接入 AI,一般都需要调用在线大模型,按 token 付费。
现在换一种方式:
- 下载一个模型,在本地浏览器里运行
- 不需要联网调用模型
- 不消耗 Token,可以无限量使用
就,还挺省钱的。
原文:https://www.appinn.com/urboquant-wasm-draw/
问题来了,类似 Excalidraw 这样轻量调用 AI 的服务,还有哪些呢?
文章来源: https://www.appinn.com/urboquant-wasm-draw-gemma-4/
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh