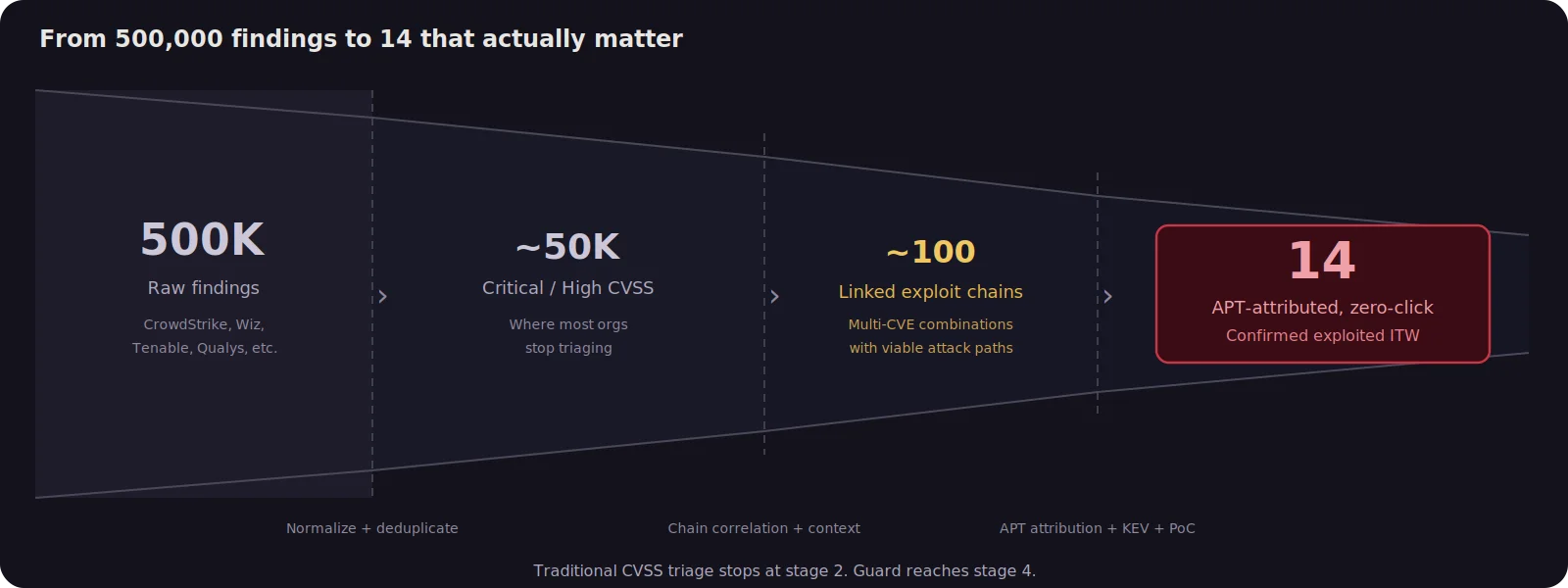
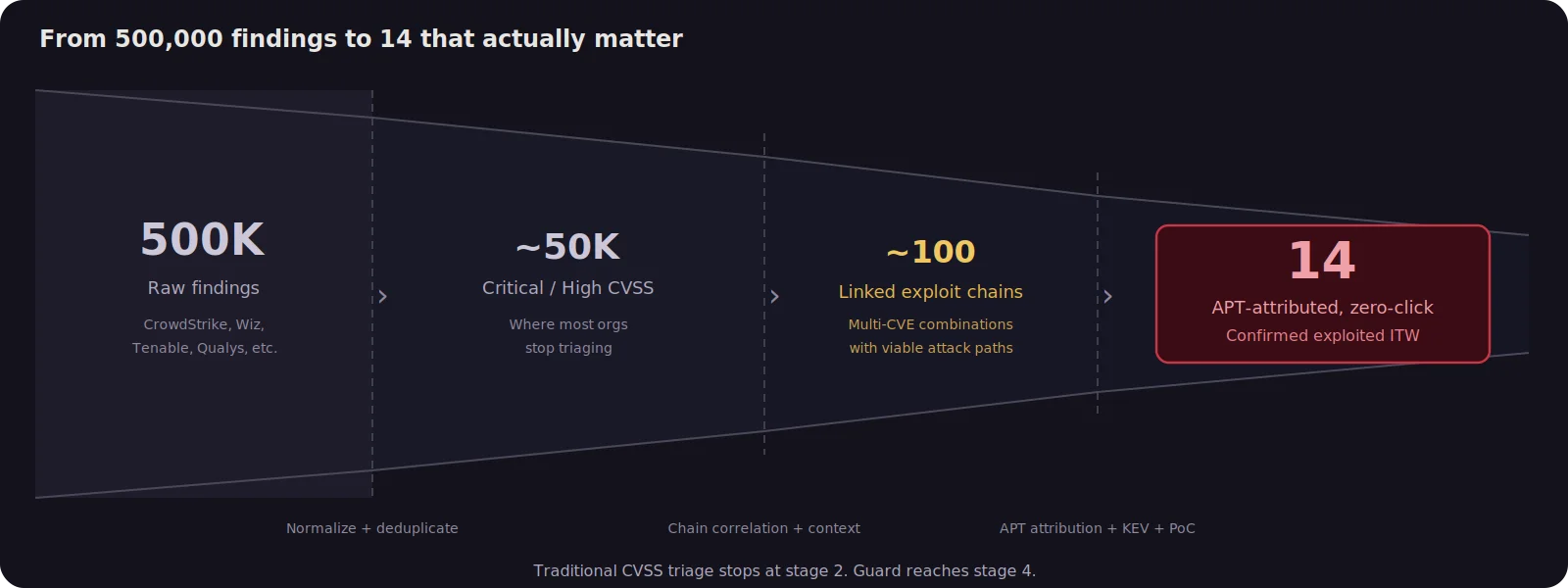
When 500,000 Findings Hide 14 Real Threats
Modern enterprises ingest vulnerability data from dozens of sources: endpoint detection and response platforms, vulnerability scanners, cloud security posture tools, container image scanners. A large organization can easily accumulate hundreds of thousands of individual findings. The standard response is to sort by CVSS score, filter for criticals, and start patching. But vulnerability management needs to shift from CVSS-based severity ranking to contextual exploit chain analysis — evaluating how individual vulnerabilities combine into realistic attack paths.
The problem is that CVSS scores evaluate vulnerabilities in isolation. A renderer vulnerability in a web browser is serious, but the browser sandbox contains it. A sandbox escape is dangerous, but it requires an initial foothold to exploit. Neither finding alone tells you the full story. But if the same endpoint is vulnerable to both, an attacker can chain them together into a zero click, full host compromise with no user interaction beyond visiting a webpage. That combined risk is qualitatively different from anything either CVE represents on its own.
Recently, we used Praetorian Guard to analyze a customer environment containing roughly 500,000 vulnerability findings ingested from the customer’s CrowdStrike deployment. Guard integrates with over 60 third party security tools, including CrowdStrike, Wiz, Tenable, Qualys, Rapid7, Orca, and Microsoft Defender, pulling vulnerability data from across the customer’s security stack into a single platform.
Using Guard’s vulnerability data and CVE research capabilities, we linked related findings into exploit chains and correlated them with threat intelligence on active exploitation. The vast majority of the 500,000 findings were noise: real vulnerabilities, but ones that were either unexploitable in context, already mitigated by compensating controls, or low impact in isolation. The signal-to-noise ratio was roughly 35,000 to 1. The analysis identified 14 endpoints where an attacker could realistically achieve full host compromise through browser-based drive-by attacks: one chain confirmed in a state-sponsored campaign, the other combining a Pwn2Own-demonstrated exploit with a sandbox escape from the same vulnerability class exploited in a separate APT operation.
This post walks through the methodology and explains why exploit chain analysis surfaces risks that traditional CVSS-based prioritization misses.
The scale of the problem starts with the numbers. In 2025, over 48,000 CVEs were published, roughly 130 per day, bringing the cumulative total since 1999 above 300,000. Of those 300,000+, CISA’s Known Exploited Vulnerabilities catalog contains approximately 1,500 entries: less than half a percent of all CVEs ever published have been confirmed exploited in the wild. The vast majority of vulnerabilities that receive a CVE and a CVSS score will never be used in an actual attack.
Example: The Linux Kernel CVE Flood
After the kernel team became a CVE Numbering Authority in 2024, they began assigning a CVE to nearly every bug fix regardless of exploitability. The result was over 3,600 kernel CVEs in 2025 alone, roughly 10 per day. Of those, seven were added to CISA’s KEV catalog as confirmed exploited in the wild. A security team that triages every critical kernel CVE with equal urgency is spending most of its time on vulnerabilities that no attacker will ever use.
How Browser Sandboxing Works
Every major browser uses a multi-process model where the renderer, the component that parses HTML, executes JavaScript, and handles layout, runs in a sandboxed child process with heavily restricted access to the operating system. This is the browser’s primary security boundary.
A vulnerability in the renderer, like an out-of-bounds write in the JavaScript engine, gives an attacker code execution inside the content process. That sounds bad, but the sandbox means they can read and write memory within that process and not much else. They cannot touch the filesystem, spawn new processes, or interact with the network beyond what the renderer is already allowed to do.
A sandbox escape, by contrast, allows a compromised child process to break out of isolation and execute code at the user’s full privilege level on the host operating system. But a sandbox escape is useless without an initial foothold inside the sandbox. You need to already be running code in the content process before you can exploit an IPC handle leak or a logic error in the broker process.
Why Scanners Miss the Combined Risk
This is the fundamental problem with evaluating these vulnerabilities individually. Your vulnerability scanner or EDR platform reports the renderer bug as critical. It reports the sandbox escape as critical. Both assessments are technically correct based on the CVSS scoring methodology.
But neither report tells you that the two findings on the same endpoint combine into something far worse than either one alone: a zero-click exploit chain that gives an attacker full code execution on the host operating system the moment a user visits a malicious page.
Chrome vs. Firefox: Not All Browsers Chain the Same Way
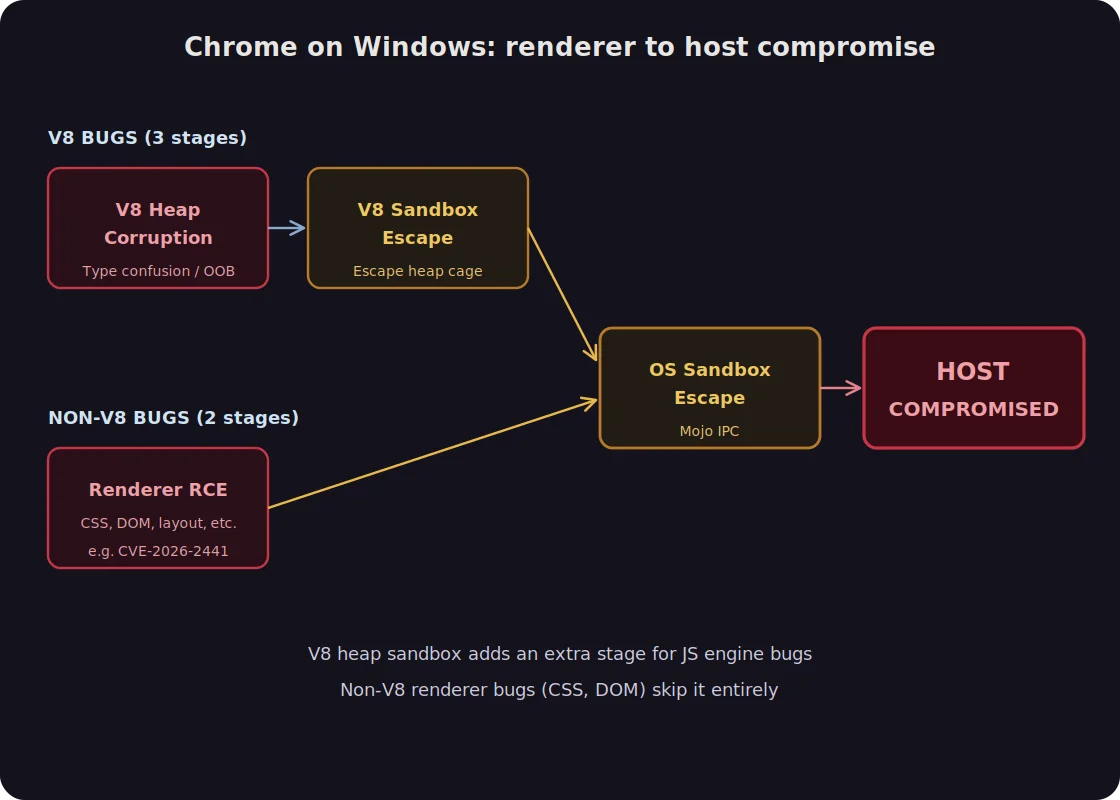
Modern Chrome has introduced an additional mitigation that makes this problem even more nuanced. Chrome’s V8 engine now includes a heap sandbox that isolates the V8 heap so that memory corruption from a JavaScript engine bug cannot spread to other parts of the process memory. In practice, this means that exploiting Chrome in 2025 often requires three vulnerabilities rather than two: a V8 type confusion for initial heap corruption, a V8 sandbox bypass to escape the heap cage, and then an OS-level sandbox escape (typically via a Mojo IPC logic bug) to reach the operating system.
Firefox’s SpiderMonkey engine does not have an equivalent heap isolation mechanism, which means the two-stage model described above (renderer RCE directly to OS sandbox escape) remains sufficient for a complete chain. This architectural difference is one reason why the Firefox chains we identified are particularly concerning: the attack surface requires fewer links in the chain to achieve full compromise.
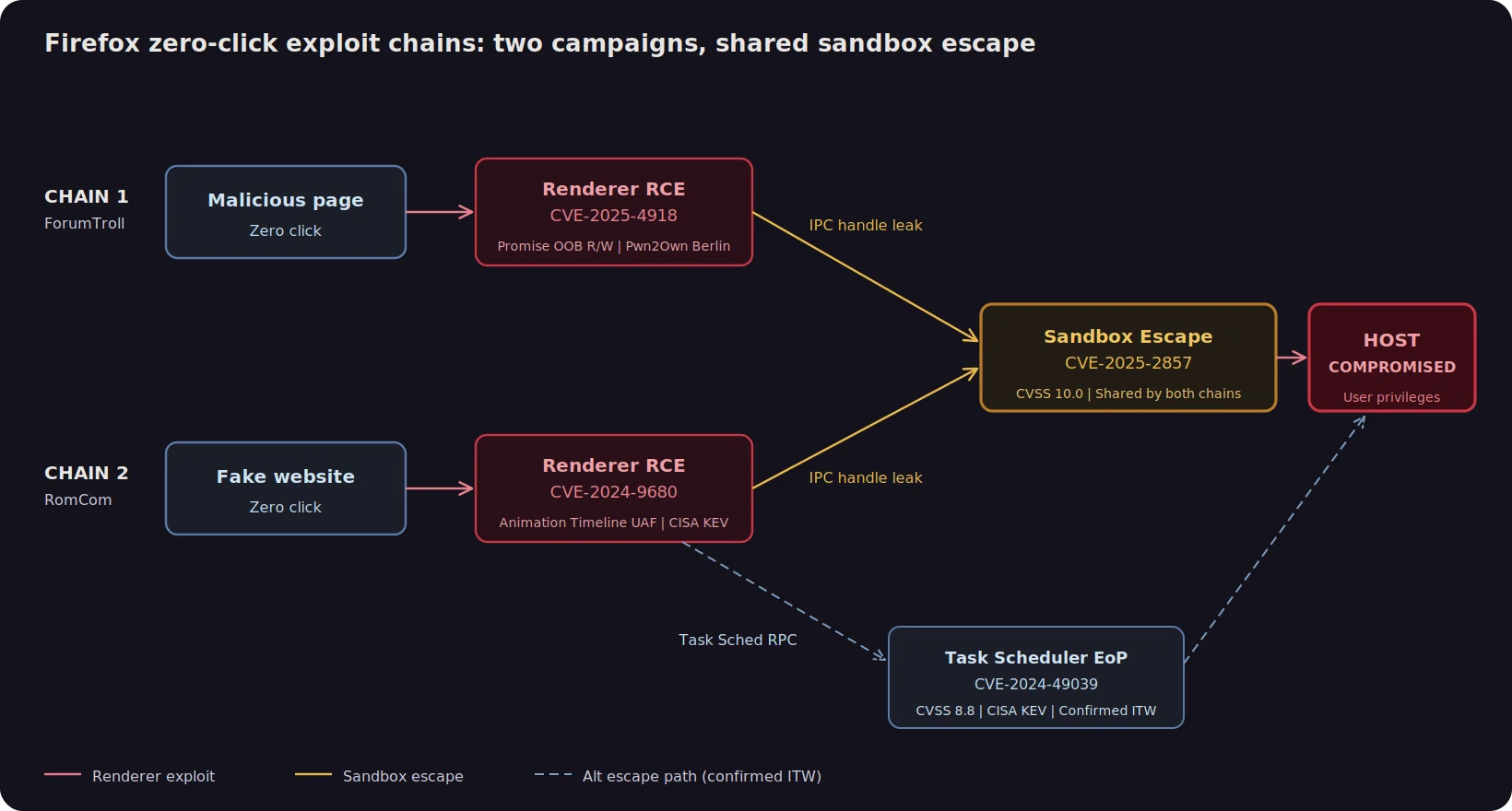
This analysis did not surface a single exploit chain. It surfaced two, sharing a common sandbox escape but using different renderer vulnerabilities as the initial foothold. One chain is a confirmed APT weapon. The other combines independently proven components: a Pwn2Own-demonstrated renderer exploit and a sandbox escape whose Chrome equivalent was deployed by a state-sponsored group. A subset of endpoints were vulnerable to both chains simultaneously.
Chain 1: CVE-2025-4918 + CVE-2025-2857 (Pwn2Own Berlin)
CVE-2025-4918 is an out-of-bounds read/write vulnerability in Firefox’s JavaScript engine, specifically in the resolution of Promise objects. An attacker can trigger the bug by serving malicious JavaScript from a webpage. When a victim visits the page, the vulnerability allows the attacker to execute arbitrary code inside the Firefox content process. No clicks, downloads, or prompts are required. This vulnerability was demonstrated at Pwn2Own Berlin 2025 and affects Firefox versions prior to 138.0.4.
CVE-2025-2857 is a sandbox escape in Firefox’s inter process communication (IPC) code on Windows. A compromised child process can cause the parent browser process to return an overly powerful handle, allowing the attacker to break out of browser isolation and execute code at the user’s full privilege level on the underlying operating system. Mozilla discovered this vulnerability after Google patched a nearly identical flaw in Chrome (CVE-2025-2783), which had been actively exploited in the wild. CVE-2025-2857 carries a CVSS score of 10.0 and affects Firefox versions prior to 136.0.4.
Chained together, these two vulnerabilities allow a complete drive-by compromise: a user visits a webpage, the renderer exploit fires silently and gains code execution inside the content process, and the sandbox escape immediately elevates that access to the host operating system. The attacker has full control of the endpoint without the user ever clicking, downloading, or approving anything.
Chain 2: CVE-2024-9680 + CVE-2025-2857 / CVE-2024-49039 (RomCom)
CVE-2024-9680 is a use after free vulnerability in Firefox’s Animation Timeline component (Web Animations API), discovered by ESET researcher Damien Schaeffer in October 2024. Like CVE-2025-4918, it provides remote code execution inside the browser’s content process with no user interaction beyond visiting a malicious page. It was exploited as a zero day in the wild from at least October through November 2024 and carries a CVSS score of 9.8. It affects Firefox versions prior to 131.0.2.
The second stage of this chain has two variants. The primary path uses the same CVE-2025-2857 sandbox escape described above. The alternate path uses CVE-2024-49039, a privilege escalation vulnerability in the Windows Task Scheduler (CVSS 8.8) that allows code running at low integrity inside the browser sandbox to escape to medium integrity by abusing the Task Scheduler’s RPC interface. This is confirmed in the wild chain: RomCom deployed CVE-2024-9680 paired with CVE-2024-49039 to achieve full host compromise through zero click drive-by attacks in late 2024.
There is an important logical relationship between these two chains. CVE-2024-9680 was patched in October 2024. CVE-2025-2857 was patched in March 2025. Any host that has not patched the older renderer vulnerability is guaranteed to also be missing the newer sandbox escape patch. The presence of CVE-2024-9680 on an endpoint is therefore a strong signal that CVE-2025-2857 is also present, and our analysis confirmed this across every affected host.
What elevates these chains from theoretical risks to urgent ones is the threat intelligence behind their components. Chain 2 is a confirmed in-the-wild APT weapon. Chain 1 was not observed in a campaign as a pair, but its components are independently proven: the renderer exploit was demonstrated against a hardened target at Pwn2Own Berlin, and the sandbox escape shares a root cause with a Chrome vulnerability that a separate state-sponsored group exploited in the wild. The techniques exist. The question is not whether this chain is exploitable, but when someone assembles it.
RomCom (Storm-0978 / Tropical Scorpius) is a Russia aligned APT group conducting both cybercrime and espionage operations. In late 2024, RomCom deployed the CVE-2024-9680 + CVE-2024-49039 chain as a zero click drive-by attack, using fake websites to redirect victims to an exploit server that deployed the RomCom backdoor.
ESET’s telemetry showed up to 250 victims per country across Europe and North America between October and November 2024. Targets included government, defense, and energy sectors in Ukraine, pharmaceutical and insurance companies in the United States, and legal firms in Germany. Both CVEs in this chain are listed in CISA’s Known Exploited Vulnerabilities catalog, with ransomware use confirmed in a 2025 update. RomCom has a track record of zero day exploitation, having previously used CVE-2023-36884 (Microsoft Word) in 2023.
Operation ForumTroll exploited CVE-2025-2783, the Chrome equivalent of the Firefox sandbox escape CVE-2025-2857. Discovered by Kaspersky’s GReAT team in March 2025, the attackers sent spearphishing emails disguised as invitations to the Primakov Readings academic forum, targeting media outlets, educational institutions, and government organizations. The campaign deployed the LeetAgent backdoor followed by Dante spyware, a commercial surveillance product developed by Memento Labs (formerly Hacking Team). Kaspersky attributed the campaign to a state sponsored APT group whose primary objective was espionage. A second wave was detected in October 2025 targeting political scientists, indicating the group remains active.
The Firefox sandbox escape (CVE-2025-2857) is not merely similar to the Chrome vulnerability exploited by ForumTroll. Mozilla explicitly stated that Firefox developers found the flaw by examining their own IPC code after the Chrome bug was disclosed. The underlying pattern, a logic error that allows a child process to leak a privileged handle from the parent, was present in both browsers independently. An attacker with the capability to exploit one could reasonably adapt to exploit the other.
The result is that a single customer environment contained endpoints vulnerable to two independent exploit chains capable of achieving full host compromise through zero-click browser attacks. One is a confirmed chain exploited in the wild by APT groups. The other assembles a Pwn2Own-demonstrated renderer exploit with a sandbox escape whose underlying vulnerability class was independently exploited by a state-sponsored group. No individual CVE report communicates that level of compound risk.
Linking CVEs into chains is only half the problem. The other half is determining whether a given chain is actually exploitable in practice. A chain composed of two theoretical vulnerabilities with no public proof of concept is a very different risk than a chain where both stages have been demonstrated at Pwn2Own, confirmed exploited by a named APT group, listed in CISA’s Known Exploited Vulnerabilities catalog, or backed by published exploit code.This kind of analysis incorporates multiple exploitability signals when evaluating a linked finding:
CISA KEV entries confirm that a vulnerability has been exploited in the wild and often indicate whether ransomware groups have operationalized it. Pwn2Own demonstrations prove that a full exploit chain is achievable against a hardened target under controlled conditions. Public proof of concept exploits lower the barrier to exploitation by providing a starting point that less sophisticated attackers can adapt. APT attribution from threat intelligence providers like Kaspersky GReAT, ESET, Google TAG, and Mandiant establishes which threat actors have deployed a given technique, against which target profiles, and in what geographies.
Each of these signals independently elevates the urgency of a finding. When multiple signals converge on the same chain, the case for immediate action becomes overwhelming. There is also an emerging signal that is changing how we think about exploitability timelines: AI assisted exploit development.
In March 2026, researchers at Calif demonstrated that Claude could take a FreeBSD kernel vulnerability advisory (CVE-2026-4747) and produce a fully working remote root shell exploit in approximately four hours of compute time, with minimal human guidance. The AI handled lab setup, multi packet shellcode delivery across 15 ROP rounds, offset debugging via crash dumps, and a kernel to userland process transition. While that specific target lacked modern mitigations like KASLR and stack canaries, the trajectory is unmistakable.
Internally at Praetorian, we have had similar success using AI agents to develop working exploits for local privilege escalation and container escape vulnerabilities against both Linux and FreeBSD kernels. The time from CVE publication to working exploit is compressing from weeks to hours, and the barrier to entry is dropping from specialized exploit developer to anyone with access to a frontier model.
For vulnerability chains where even one stage has a public advisory and a patch diff, the assumption should be that a working exploit can be generated faster than most organizations can deploy a patch. Exploitability assessment must account for this by weighing not just whether a public exploit exists now, but whether the vulnerability class and available technical context make AI assisted exploitation feasible.
This customer’s environment had roughly 500,000 individual vulnerability findings from their CrowdStrike deployment alone. Guard ingests findings simultaneously from multiple sources: CrowdStrike for endpoint vulnerabilities, Wiz or Orca for cloud misconfigurations, Tenable or Qualys for infrastructure scanning, etc. Sorting any one of these sources by CVSS score and filtering for criticals would have returned thousands of results, most of which were either unexploitable in their specific deployment context or represented vulnerabilities that, while technically severe, had no realistic attack path given the compensating controls in place.
Our approach was different. Rather than treating each CVE as an independent risk to be scored and ranked, we correlated findings across the same endpoint to identify cases where multiple vulnerabilities composed into a viable exploit chain, then enriched those chains with the exploitability signals described in the previous section: CISA KEV status, public PoC availability, Pwn2Own demonstrations, APT attribution, and AI assisted exploitation feasibility.
Guard’s CVE research pipeline ingests newly published vulnerabilities, determines which products and versions are affected, and cross references against what is deployed in each customer’s environment. When threat intelligence surfaces active exploitation by a named APT group, that context informs the chain analysis. The browser exploit chains identified here connected two Firefox CVEs to a Kaspersky threat report on ForumTroll and an ESET writeup on RomCom, surfacing the 14 endpoints that actually mattered out of half a million findings. For a deeper look at the architecture behind this, see our CEO’s post on the Attack Helix.
The result was a set of linked findings, each representing not a single CVE but a complete attack path. We identified 14 endpoints where unpatched Firefox installations were vulnerable to at least one complete exploit chain: nine endpoints exposed to the Pwn2Own Berlin chain (CVE-2025-4918 + CVE-2025-2857), and five endpoints exposed to the RomCom chain (CVE-2024-9680 + CVE-2025-2857), with a subset of hosts vulnerable to both chains simultaneously and two hosts carrying an additional escape path via CVE-2024-49039. Each linked finding included the full chain description, the specific CVEs involved, exploitability context, and a recommendation that went beyond “patch Firefox” to include forensic triage guidance for indicators of compromise associated with RomCom and ForumTroll tooling.
The reduction from 500,000 to 14 is not a trick of filtering. It reflects a fundamentally different question. Instead of asking “which vulnerabilities are severe?”, the right question is “which combinations of vulnerabilities create a realistic attack path that a capable adversary is likely to exploit?” The answer set is dramatically smaller, and dramatically more actionable.
Under a traditional CVSS-sort workflow, those 14 endpoints would be buried in a queue of thousands of critical findings, undifferentiated from renderer bugs on systems with no matching sandbox escape or sandbox escapes on systems with no initial foothold. They would get patched eventually, in whatever order the ticket queue dictated, with no forensic triage and no awareness that a state-sponsored campaign had already weaponized one chain, and that the components of the other had been independently proven exploitable at Pwn2Own and in the wild.
The linked findings Guard surfaced tell a different story. Each one ships with full chain context: the specific CVEs, the exploitability signals, the CISA KEV status, and IOC guidance for related APT tooling. That context changes what remediation looks like. Not just “patch Firefox,” but “these 14 hosts are exposed to zero-click chains built from vulnerabilities that state-sponsored actors and top security researchers have independently proven exploitable, and here is what to look for if they have already been hit.”
This is what the Praetorian Guard platform does: it ingests vulnerability data from across the security stack, links findings into exploit chains, enriches them with threat intelligence, and surfaces the results that represent genuine, exploitable risk. A vulnerability pattern identified in one customer environment becomes a detection capability that protects every Guard customer facing the same exposure class. If you are managing hundreds of thousands of findings and struggling to identify what actually matters, you have the same problem this customer had.
Want to see what exploit chains exist in your environment?
Request a Guard demo and we’ll show you.
The post 500,000 Vulnerabilities, 14 That Matter: How Exploit Chain Analysis Cuts Through the Noise appeared first on Praetorian.
*** This is a Security Bloggers Network syndicated blog from Offensive Security Blog: Latest Trends in Hacking | Praetorian authored by Praetorian. Read the original post at: https://www.praetorian.com/blog/exploit-chain-analysis/