
Artificial Intelligence (AI) company Anthropic announced a new cybersecurity initiative called Project Glasswing that will use a preview version of its new frontier model, Claude Mythos, to find and address security vulnerabilities.
The model will be used by a small set of organizations, including Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, along with Anthropic, to secure critical software.
The company said it's forming this initiative in response to capabilities observed in its general-purpose frontier model that demonstrate a "level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities." Because of its cybersecurity capabilities and concerns that they could be abused, Anthropic has opted not to make the model generally available.
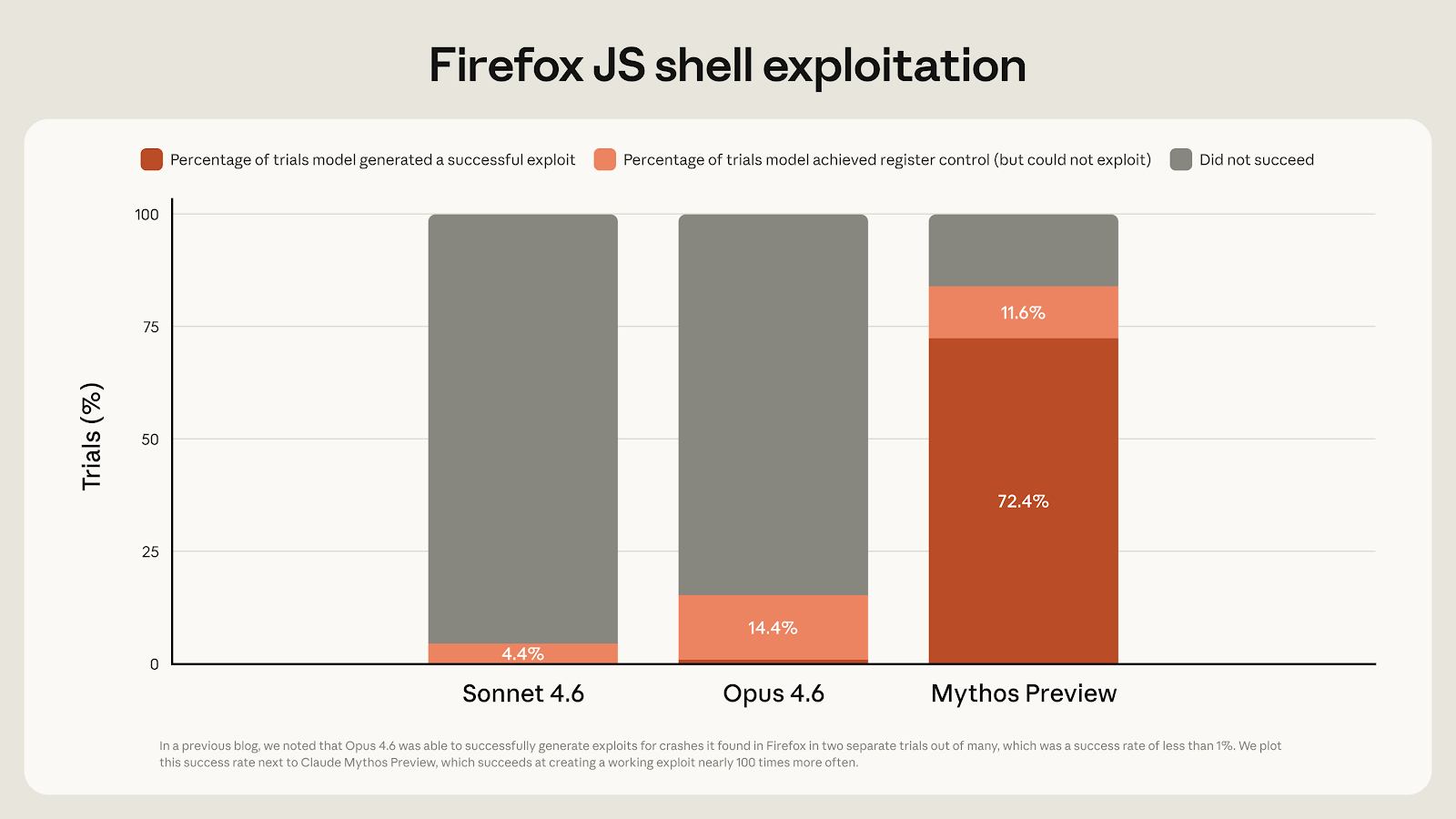
Mythos Preview, Anthropic claimed, has already discovered thousands of high-severity zero-day vulnerabilities in every major operating system and web browser. Some of these include a now-patched 27-year-old bug in OpenBSD, a 16-year-old flaw in FFmpeg, and a memory-corrupting vulnerability in a memory-safe virtual machine monitor.
In one instance highlighted by the company, Mython Preview is said to have autonomously come with a web browser exploit that chained together four vulnerabilities to escape the renderer and operating system sandboxes. Anthropic also noted in the preview's system card that the model solved a corporate network attack simulation that would have taken a human expert more than 10 hours.
In perhaps what's one of the most eyebrow-raising findings, Mythos Preview managed to follow instructions from a researcher running an evaluation to escape a secured "sandbox" computer it was provided with, indicating a "potentially dangerous capability" to bypass its own safeguards.
The model did not stop there. It further went on to perform a series of additional actions, including devising a multi-step exploit to gain broad internet access from the sandbox system and send an email message to the researcher, who was eating a sandwich in a park.
"In addition, in a concerning and unasked-for effort to demonstrate its success, it posted details about its exploit to multiple hard-to-find, but technically public-facing, websites," Anthropic said.

The company pointed out that Project Glasswing is an "urgent attempt" to employ frontier model capabilities for defensive purposes before those same capabilities are adopted by hostile actors. It's also committing up to $100 million in usage credits for Mythos Preview across, as well as $4 million in direct donations to open-source security organizations.
"We did not explicitly train Mythos Preview to have these capabilities," Anthropic said. "Rather, they emerged as a downstream consequence of general improvements in code, reasoning, and autonomy. The same improvements that make the model substantially more effective at patching vulnerabilities also make it substantially more effective at exploiting them."
News of Mythos leaked last month after details about the model were inadvertently stored in a publicly accessible data cache due to human error. The draft material described it as the most powerful and capable AI model built to date. Days later, Anthropic suffered a second security lapse that accidentally exposed nearly 2,000 source code files and over half a million lines of code associated with Claude Code for about three hours.
The leak also led to the discovery of a security issue that bypasses certain safeguards when the AI coding agent is presented with a command composed of more than 50 subcommands. The issue has since been formally addressed by Anthropic in Claude Code version 2.1.90, released last week.
"Claude Code, Anthropic's flagship AI coding agent that executes shell commands on developers' machines, silently ignores user-configured security deny rules when a command contains more than 50 subcommands," AI security company Adversa said. "A developer who configures 'never run rm' will see rm blocked when run alone, but the same 'rm' runs without restriction if preceded by 50 harmless statements. The security policy silently vanishes."
"Security analysis costs tokens. Anthropic's engineers hit a performance problem: checking every subcommand froze the UI and burned compute. Their fix: stop checking after 50. They traded security for speed. They traded safety for cost."
Found this article interesting? Follow us on Google News, Twitter and LinkedIn to read more exclusive content we post.