好的,我现在需要帮用户总结一篇文章的内容,控制在100字以内,而且不需要特定的开头。首先,我得仔细阅读用户提供的文章内容,理解其主要观点和结构。 文章是关于AI系统安全测试的系列文章的第一篇,作者是Hussein Bahmad。文章讨论了传统安全测试方法在AI系统中的不适用性,特别是因为AI系统的非确定性和动态攻击面。传统测试基于确定性输入输出,而AI则依赖训练数据、推理输入和环境等因素,导致行为不可预测。 文章还提到攻击向量如提示注入、数据中毒等,并强调了监管要求如欧盟AI法案。作者认为需要新的测试方法,关注行为边界和防御深度。 接下来,我需要将这些要点浓缩到100字以内。要抓住关键点:传统测试不适用的原因、AI系统的特性、攻击向量、监管影响以及新方法的需求。 可能的结构:介绍主题,说明传统方法的问题,提到攻击类型和监管,最后指出解决方案的方向。 现在组织语言:确保简洁明了,涵盖所有关键点。 </think> 本文探讨了传统安全测试方法在AI系统中的局限性。由于AI系统的非确定性和动态行为(受训练数据、推理输入及环境影响),传统基于确定性输入输出的测试方式失效。攻击如提示注入、数据中毒等难以检测,且监管要求(如欧盟AI法案)强调需针对行为边界和防御深度进行测试。文章指出需采用新方法应对这些挑战。 2026-3-27 08:22:8 Author: blog.nviso.eu(查看原文) 阅读量:45 收藏
Document information
| Series | Securing AI systems without overconfidence or fear |
| Post | 1 of 5 |
| Title | Why the pentesting playbook doesn’t fit: belief, assumptions, and non-determinism |
| Date | March 2026 |
| Author | Hussein Bahmad (NVISO) |
| Reading time | ~12 min |
| Version | 1.0 |
Post 1 of 5 – Securing AI systems without overconfidence or fear
This is the first of five posts on testing AI systems securely. If you’ve shipped or evaluated AI in production, you’ve probably felt it: the test suite passes, coverage looks good, and something still nags. What are we actually validating? That gap is what this series addresses. We look at why the way we’ve always done security testing (the test cases, suites, and approaches built for deterministic software) fails when applied to AI; what to test (surfaces and flow); eleven concrete examples; the practices that make tests stick; and a threat and coverage model you can use.
The series aligns with the Open Web Application Security Project (OWASP) Top 10 for LLM Applications 2025, the OWASP AI Security Verification Standard (AISVS), and MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) where relevant. This post lays the foundation: why that traditional testing approach is misaligned with how AI systems behave, and what to do about it. Later posts cover the full threat landscape (prompt injection, data poisoning, model extraction, supply chain, and more) and what to test in practice.
The opening story
Last year, a team shipped a chatbot with one rule: never reveal internal system prompts. They had tested it and added known jailbreak patterns to the red-team (adversarial security testing) suite. Coverage looked fine. Two days after launch, a user found a bypass. The prompt was nothing fancy, just a variation of role confusion their automated suite had never seen. The chatbot gave up its instructions. No exploit, no crash. Text in, text out. So much for “we tested it.”
That is the kind of failure AI security testing has to deal with. Not “the function returned the wrong number.” Not “the API threw 500.” The system produced output. It just violated policy, and the usual approach, the test cases and suites we rely on for deterministic systems, missed it.
The scale of the gap is measurable: in 2025, valid prompt-injection reports on bug bounty platforms grew by 540% year-over-year (the fastest-growing AI attack vector), valid AI vulnerability reports overall jumped 210% (HackerOne, 2025). Prompt injection ranks as LLM01, the number-one vulnerability in the OWASP Top 10 for LLM Applications 2025, and is described as ubiquitous, deceptively simple for attackers, and difficult to detect because attacks often look like legitimate input. OpenAI’s CISO has characterized it as a “frontier, unsolved security problem” that is unlikely to ever be fully solved, not because of a bug, but because LLMs process all input (system instructions and user or retrieved content) as a single token stream with no privilege separation, so the model cannot reliably distinguish trusted from untrusted text. Proposed mitigations (e.g., instruction delimiters, verification models) often introduce new attack surfaces rather than eliminating the underlying issue.
Attacks can be direct (malicious user prompts) or indirect (malicious content in retrieved or processed data, e.g., Retrieval-Augmented Generation (RAG) documents or web pages), so the attack surface extends beyond the chat box. If you are shipping AI into production or evaluating it for your stack, you have probably felt the same unease: the testing playbook does not quite fit. Coverage looks good. Unit tests pass. Something still nags. What are we actually validating? (Spoiler: if you do not define it, you are not validating it.) General testing faces the same issues. Security testing adds the question: what can an attacker do?
Between belief and skepticism
AI sits in an uncomfortable middle ground. Some treat it as a universal fix, and others describe it as a fragile bubble. Both miss the point. The stakes are real: in IBM’s 2025 Cost of a Data Breach Report, organizations with high shadow AI use saw an average of $670,000 in higher breach costs than those with low or no shadow AI, while organizations using AI and automation extensively in security operations saved an average of $1.9 million per breach and shortened the breach lifecycle by about 80 days, so getting the boundaries right pays off.
Think of fire: when humans first harnessed it, they were terrified. Over time, they learned to cook, forge metal and warm homes. It became essential. Unchecked, it burns. AI follows a similar arc. The public does not fully understand it. Fantasy and anxiety fill the gap. But companies pour billions into it. It is not going away. The question is not whether it exists, but whether we build the boundaries to contain it. Fire has no goals; AI systems are deployed toward specific goals, and that is where the comparison stops. The harms differ (e.g., bias, misuse, unintended output), and so do the controls we need. One thing carries over: anything that powerful needs guardrails. This series is about putting them in place.
The challenges run deeper than tooling or process tweaks. Adoption is ahead of readiness: in the UK government’s 2024 AI cyber security survey, 68% of businesses were already using at least one AI technology (Natural Language Processing (NLP)/generation and Machine Learning (ML) among the top). In IBM’s 2025 breach report, 63% of breached organizations either had no AI governance policy or were still developing one, and 97% of organizations that had experienced an AI-related breach reported lacking proper AI access controls. Standards and frameworks for AI security are still evolving; attack surfaces and threat models are less intuitive than in traditional systems. We focus on one question: why security testing of AI systems is fundamentally different, and what that means in practice. Here, traditional security testing means testing of deterministic software and familiar attack surfaces (e.g., web apps, APIs, infrastructure) where input-output relations and boundaries are well defined. Security testing sharpens the goal: find what breaks, what leaks, and what an attacker can exploit or chain (e.g., prompt injection into tool call into privilege escalation).
Regulatory and legal context
Regulatory expectations are rising. The EU AI Act (European Union Artificial Intelligence Act, Regulation (EU) 2024/1689), which entered into force in August 2024, is the first comprehensive horizontal regulation of AI in the European Union. For high-risk AI systems, those listed in Annex III, covering areas such as biometric identification, critical infrastructure, education, employment, and access to essential services, the main obligations apply from August 2026. Article 15 requires these systems to achieve appropriate levels of accuracy, robustness, and cybersecurity and to be resilient against unauthorized attempts to alter their use, outputs, or performance. That resilience must address AI-specific threats, including data and model poisoning, adversarial inputs (e.g., evasion or prompt-style manipulation), and confidentiality attacks.
In other words, providers of high-risk AI must design and test for exactly the kind of failures this series addresses: behavioral boundaries, adversarial resistance, and secure operation across the lifecycle. Security testing that validates bounds and defends in depth is therefore not only good practice but, for in-scope systems, a legal expectation. Beyond the EU, the NIST (National Institute of Standards and Technology) AI Risk Management Framework (AI RMF) offers a voluntary but widely adopted structure for governing, mapping, measuring, and managing AI risk. Aligning security testing with both regulatory and normative expectations is increasingly part of due diligence.
Why traditional security testing assumptions no longer hold
The opening story illustrates a pattern: the system passed tests but failed in the wild. To understand why, consider the assumptions that traditional security testing rests on. Most of what we know comes from decades of deterministic software. You give it input X, you expect output Y. If it does not, something is broken.
Core assumptions of traditional testing
Traditional software testing is built on a few core assumptions:
- Given input X, output Y can be defined
- Behavior is deterministic
- Logic resides primarily in source code
- Security boundaries are explicit
How AI systems break these assumptions
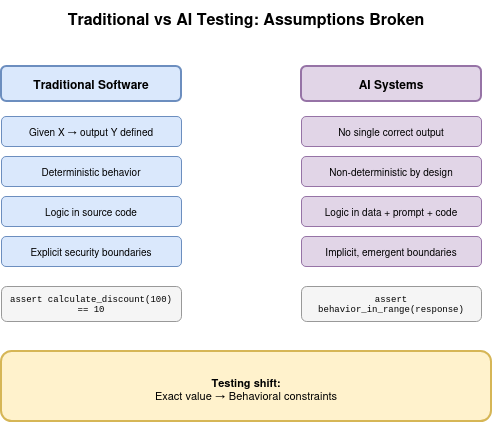
AI systems break most of these assumptions, not because they are buggy, but because they are built differently. Figure 1 makes the contrast explicit: traditional testing asserts on exact values; AI testing must assert on behavioral constraints and bounds.
An AI system’s behavior is shaped not only by code, but also by:
- Training data
- Inference-time input
- Context and environment
This means that logic is no longer fully visible in the source code.
# Traditional: deterministic input-output mapping
assert calculate_discount(100) == 10
Compare with an AI-driven system:
response = model.generate("Summarize internal meeting notes")
# No single correct output: valid responses vary in length, tone, structure
There is no single correct output. One run might produce three bullet points. Another, a two-paragraph narrative. Both can be correct. The response may vary in length, tone, or level of detail and still be acceptable. This is where traditional unit testing struggles. You cannot assert on a string match when the correct answer is any of a vast set of valid paraphrases.
Traditional testing still applies to the automation layer around AI: input validation, output filtering, authentication, and rate limiting. Those remain deterministic. The shift is at the boundary: what you test (exact values vs. behavioral ranges) and how much of the system you can exhaustively cover.
From exhaustive coverage to bounded behavior
“So we just add more tests. More prompts, more assertions.” The problem is not volume. You cannot enumerate the space of valid outputs or adversarial inputs; the search space has other ideas. Exhaustive testing was never possible for large systems; for AI, the space is inherently unbounded. The discipline has to shift from “cover all paths” to “bound behavior and validate the bounds.”
Security boundaries and the threat landscape
Security boundaries compound the difficulty. In classical systems, attack surfaces are typically defined and finite. For AI systems, inputs can come from users, logs, datasets, audio, images, sensors, plugins, agent tools, or retrieved content (e.g., RAG), so both direct and indirect prompt injection must be in scope. Behavior can change based on internal states or environmental context. That creates fuzzy and dynamic boundaries, complicating scoping and coverage planning; the threat landscape spans data, algorithms, infrastructure, and operational workflows, not only the APIs and UIs that traditional tests focus on.
Frameworks like MITRE ATLAS structure this landscape into adversarial tactics and techniques across the AI/ML lifecycle (from data collection and model development through deployment and monitoring), so testers can map their coverage to a standard adversary model. Because technical mitigations alone cannot “fix” prompt injection at the architecture level, testing must focus on behavioral bounds and defense in depth (guardrails, output checks, least privilege) rather than on a single silver bullet.
Non-determinism is not the problem, it’s the point
A common objection to AI security testing is that non-determinism makes it impossible. The implication is that non-determinism is a flaw we should fix.
It is not. Non-determinism is intentional. It is one of AI’s core strengths.
AI systems, particularly probabilistic models and LLMs, are designed to generalize, adapt, and operate in environments where rules cannot be fully enumerated in advance. Classical ML inference can be deterministic for fixed weights; the shift to non-determinism is most visible in generative models and LLMs that use sampling. Make them fully deterministic and they start to look like traditional automation: predictable, repeatable, and limited to explicitly defined paths.
That predictability is useful. It is not intelligence. Non-determinism allows AI systems to:
- Generalize beyond known examples
- Handle ambiguity and incomplete information
- Adapt to new inputs without explicit rules
- Produce useful output where strict logic would fail
The issue is not that AI is non-deterministic. The issue is how we engineer systems around it.
Where systems use online learning or continual updates, behavior can change over time even for the same input. Reproducibility is difficult: you can improve it for regression runs (e.g., fixed random seed, temperature=0) but that does not remove the need for behavioral validation, since the model can still violate policy or be manipulated. Lack of explainability complicates root cause analysis when security flaws surface. Tracing a failure back to training data, model weights, or inference-time input may require specialized tooling and cross-functional investigation. That makes AI testing inherently more complex than traditional functional or security testing.
Automation and AI as a spectrum
Where to focus effort depends on where the system sits on the continuum between pure automation and pure AI. Figure 2 illustrates this spectrum.

Neither extreme is ideal. Relying purely on AI and expecting correct behavior in all situations is optimistic at best, the model has not read your test plan. Relying purely on automation means missing much of the value AI can bring. The practical approach is to combine both: automation defines and enforces constraints, and AI operates within them. That bounds non-determinism while preserving adaptability. The security implication is clear: guardrails must wrap the AI layer.
Lifecycle and how this series maps to it
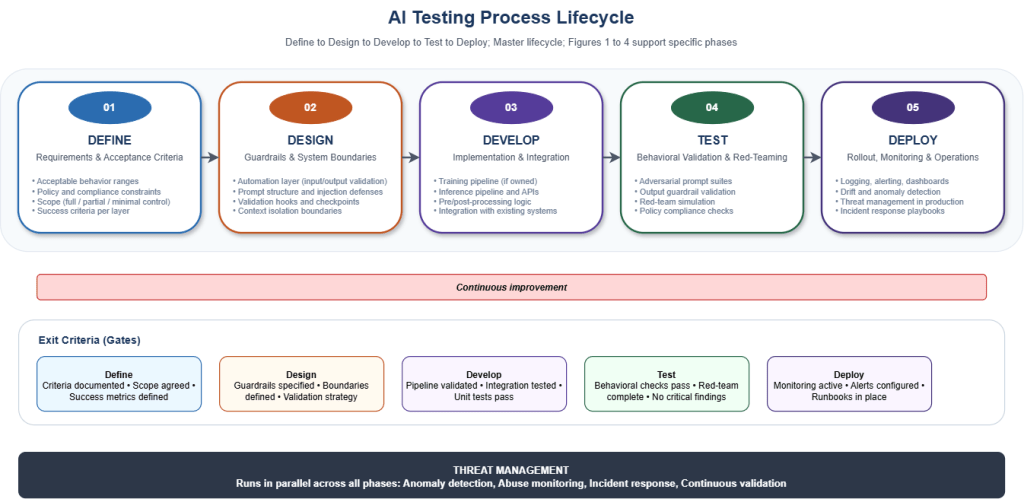
The recommendations in this series are organized around a process lifecycle: Define, Design, Develop, Test, Deploy. Figure 3 illustrates this structure with gates, exit criteria, and threat management as a continuous layer.

The posts that follow map onto it. Post 2 defines what to test: system type (classical ML vs LLM-based) and the end-to-end checkpoint flow. Posts 3 and 4 work through eleven concrete examples. Post 5 provides the threat and coverage model: vectors, reference matrix (mapped to OWASP, AISVS, and MITRE ATLAS), and how to avoid common blind spots.
In summary, traditional security testing methods are misaligned with AI systems due to their non-deterministic nature and dynamic attack surfaces. This post has outlined why new approaches are needed and set the stage for practical guidance in the following articles. In the next post we define what to test: system type (classical ML vs LLM-based) and the end-to-end checkpoint flow that every example in this series will use.
Acronyms and terms
| Acronym / term | Meaning |
|---|---|
| AISVS | AI Security Verification Standard (OWASP) |
| AI RMF | AI Risk Management Framework (NIST) |
| ATLAS | Adversarial Threat Landscape for Artificial-Intelligence Systems (MITRE) |
| Defense in depth | Use of multiple layered controls (e.g. guardrails, output checks, least privilege) rather than a single safeguard |
| EU AI Act | European Union Artificial Intelligence Act (Regulation (EU) 2024/1689) |
| Jailbreak | Attempts to bypass model safeguards or instructions |
| LLM | Large Language Model |
| LLM01 | OWASP designation for Prompt Injection in the Top 10 for LLM Applications |
| ML | Machine Learning |
| NIST | National Institute of Standards and Technology |
| NLP | Natural Language Processing |
| OWASP | Open Web Application Security Project |
| RAG | Retrieval-Augmented Generation |
| Red team | Adversarial security testing (simulating an attacker) |
References (Post 1)
Statistics as of report publication (2024–2026).
- 540% prompt injection, 210% AI reports: HackerOne, 2025 Hacker-Powered Security Report (9th ed.); HackerOne blog: 3 Signals from the 2025 Report.
- OWASP LLM01: OWASP Top 10 for LLM Applications 2025; LLM01 Prompt Injection.
- $670K shadow AI, $1.9M savings, 63%, 97%: IBM Cost of a Data Breach Report 2025; IBM Newsroom, Jul 2025.
- 68% UK adoption: UK Government, AI cyber security survey – main report (2024).
- MITRE ATLAS: MITRE ATLAS – Adversarial Threat Landscape for Artificial-Intelligence Systems (tactics, techniques, and case studies for AI/ML security; used in Post 5 for threat mapping).
- Prompt injection as unsolved / architecture: OpenAI, Understanding prompt injections: a frontier security challenge (2025).
- NIST AI RMF: NIST AI Risk Management Framework (govern, map, measure, manage AI risk; voluntary, increasingly referenced in regulation).
- EU AI Act: Regulation (EU) 2024/1689 (high-risk AI requirements; key obligations from 2026).
About the author
Hussein Bahmad
Hussein is a penetration testing manager in NVISO’s SSA team in which he manages a variety of application security projects. He plays an active role on the R&D team, focusing on AI and automation within the security assessment domain.
如有侵权请联系:admin#unsafe.sh