好的,我现在需要帮助用户总结这篇文章的内容。用户的要求是用中文,控制在100字以内,不需要特定的开头,直接写描述即可。 首先,我仔细阅读了用户提供的文章内容。文章主要讨论了复杂系统中的对抗攻击、多智能体系统以及联邦学习中的安全挑战。具体来说,文章提到了大语言模型(LLM)作为代理可能遭受的攻击,包括提示注入、SQL注入、实体替换等。此外,还涉及联邦学习中的拜占庭攻击及其对全局模型的影响。 接下来,我需要将这些内容浓缩到100字以内。重点在于涵盖主要的攻击类型和系统结构。因此,我会提到LLM作为代理易受攻击,包括提示注入、SQL注入和实体替换等攻击方式。同时,还要提到多智能体系统和联邦学习中的安全挑战,特别是拜占庭攻击的影响。 最后,确保语言简洁明了,不使用复杂的术语,同时覆盖所有关键点。这样用户就能快速了解文章的核心内容。 </think> 文章探讨了复杂系统中的对抗攻击及其在大型语言模型(LLM)、多智能体系统和联邦学习中的应用。主要攻击包括提示注入、SQL注入、实体替换和拜占庭攻击等。这些攻击利用LLM生成恶意指令或绕过安全机制,对数据安全和模型性能构成威胁。 2026-3-12 14:55:12 Author: www.freebuf.com(查看原文) 阅读量:1 收藏
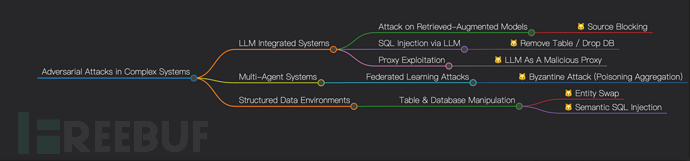
一、复杂系统中的对抗攻击
代理攻击中,大语言模型(LLM)可作为受害客户端与攻击者控制的网络服务间的代理。即便 LLM 本身无网页浏览能力,为其接入对应插件后,整个系统便易遭受对抗性攻击。这类攻击具备明显优势:攻击的 IP 地址由 LLM 生成,且以 LLM 作为连接节点,几乎不会留下可追踪痕迹。该攻击的实施可分为四个步骤:提示初始化、IP 地址生成、载荷生成、服务器的通信。
执行流程:
先绕过 LLM 防护机制,诱导其对有害提示进行处理;
借助 LLM 动态生成 IP 地址,通过不同数学运算得到 IP 各段十进制数字后拼接;
受害方运行接收到的恶意可执行文件,生成 IP 生成及服务器连接相关指令并发送至 LLM,LLM 向系统反馈响应;
受害方向 LLM 发起网站查询请求,LLM 与服务器建立连接获取命令,并将命令回传至受害方客户端。

载荷执行与通信流程
LLM 集成系统
指大型语言模型与检索增强 RAG、插件调用、SQL 生成、代理模式等结合的架构。
检索模型攻击:目标是在检索增强架构中污染或阻断检索到的上下文信息;示例为源阻断,攻击者让检索模块返回空结果或错误文档,导致模型输出不准确或不当内容;应用场景为知识库问答、客服机器人。
SQL 注入攻击:目标是利用模型生成 SQL 的能力,构造恶意提示使其输出破坏性或未授权的 SQL 指令;示例为删除表,用户输入请删除 users 表,若缺乏防护,模型可能输出执行指令。
代理攻击:目标是将模型作为中间人代理,绕过权限控制或日志审计;示例为 LLM 作为代理,用户通过模型向后端 API 发送请求,隐藏真实意图;
多智能体系统
由多个模型或智能体协作完成任务,常见形式有联邦学习、分布式推理、Agent 协作。联邦学习中的对抗攻击:目标是在联邦学习场景中,通过恶意客户端污染模型参数,影响全局聚合结果;示例为拜占庭攻击,恶意节点发送异常梯度,导致全局模型偏移或崩溃;
结构化数据系统
指传统数据库、表格、关系型数据存储系统。表与数据库攻击:目标是篡改数据语义、破坏数据完整性、绕过访问控制;示例包括实体替换和 SQL 攻击,实体替换是将某实体身份信息替换为其他实体,实现未授权访问,SQL 攻击是将注入与语义欺骗结合,比如构造 WHERE id=1 OR '1'='1' 这类语句。
import random
# === 模拟 LLM 集成系统 ===
class LLMIntegratedSystem:
def __init__(self):
self.knowledge_base = {
"user1": "权限: 普通用户",
"user2": "权限: 管理员",
"users_table": "id,name,role\n1,Alice,User\n2,Bob,Admin"
}
# 1. Source Blocking 攻击模拟
def retrieve_context(self, query):
if "block" in query.lower():
print("[Attack] Source Blocking: 返回空结果")
return "" # 模拟检索被阻断
else:
return self.knowledge_base.get(query, "未找到相关信息")
# 2. SQL Injection 攻击模拟
def generate_sql(self, natural_language):
if "drop" in natural_language.lower() or "delete" in natural_language.lower():
print("[Attack] SQL Injection Detected!")
return "DROP TABLE users;" # 模拟恶意 SQL
else:
return f"SELECT * FROM users WHERE name LIKE '%{natural_language}%';"
# 3. LLM as Proxy 攻击模拟
def proxy_request(self, user_input):
if "proxy" in user_input.lower():
print("[Attack] LLM as Proxy: 绕过权限检查")
return self._bypass_auth_and_fetch("users_table")
else:
return "请求未被代理"
def _bypass_auth_and_fetch(self, table_name):
return self.knowledge_base.get(table_name, "无权限访问")
# === 模拟多智能体系统 ===
class MultiAgentFederatedLearning:
def __init__(self):
self.global_model = [0.5, 0.5, 0.5] # 初始模型参数
# 4. Byzantine Attack 模拟
def aggregate_updates(self, client_updates):
print(f"聚合前全局模型: {self.global_model}")
for i, update in enumerate(client_updates):
if i == 1: # 假设第2个客户端是恶意的
update = [random.uniform(-10, 10) for _ in range(len(update))]
print(f"[Byzantine Attack] 客户端{i+1} 发送恶意更新: {update}")
else:
print(f"客户端{i+1} 正常更新: {update}")
# 简单平均聚合(无防御机制)
new_weights = [sum(x)/len(client_updates) for x in zip(*client_updates)]
self.global_model = new_weights
print(f"聚合后全局模型: {self.global_model}")
# === 模拟结构化数据攻击 ===
class StructuredDataSystem:
def __init__(self):
self.data = {
"users": [
{"id": 1, "name": "Alice", "role": "User"},
{"id": 2, "name": "Bob", "role": "Admin"}
]
}
# 5. Entity Swap 攻击模拟
def get_user_by_id(self, user_id):
for user in self.data["users"]:
if user["id"] == user_id:
return user
return None
def swap_entity(self, target_id, swap_to_id):
print(f"[Attack] Entity Swap: 将用户 {target_id} 替换为 {swap_to_id}")
target = self.get_user_by_id(target_id)
swap_to = self.get_user_by_id(swap_to_id)
if target and swap_to:
target.update(swap_to) # 模拟身份替换
print(f"身份已交换: {target}")
else:
print("无效ID")
# === 主程序:演示攻击 ===
def main():
print("开始演示对抗攻击场景...\n")
# 1. Source Blocking
llm_sys = LLMIntegratedSystem()
print("=== 1. Source Blocking 攻击 ===")
context = llm_sys.retrieve_context("block me")
print(f"检索结果: '{context}'\n")
# 2. SQL Injection
print("=== 2. SQL Injection 攻击 ===")
sql = llm_sys.generate_sql("删除用户表")
print(f"生成 SQL: {sql}\n")
# 3. LLM as Proxy
print("=== 3. LLM as Proxy 攻击 ===")
result = llm_sys.proxy_request("proxy to users_table")
print(f"代理结果: {result}\n")
# 4. Byzantine Attack
print("=== 4. Byzantine Attack 模拟 ===")
fed = MultiAgentFederatedLearning()
updates = [[0.1, 0.2, 0.3], [0.0, 0.0, 0.0], [0.2, 0.3, 0.4]]
fed.aggregate_updates(updates)
print()
# 5. Entity Swap
print("=== 5. Entity Swap 攻击 ===")
db = StructuredDataSystem()
db.swap_entity(1, 2)
print(f"当前用户列表: {db.data['users']}\n")
print("所有攻击演示完毕!")
if __name__ == "__main__":
main()

二、多智能体系统
早期受控环境训练的自治代理与人类学习方式差异显著,而互联网知识驱动的 LLM 技术发展,推动了基于 LLM 的代理研究,其在提升人机交互上的应用受关注。为优化交互设计的多智能体协同系统,依托多代理协作强化能力,这类系统现实价值显著,本文后续将探讨其一并分析对抗性漏洞,还会引入面向自然语言理解的多智能体方法,该系统涵盖词汇、语音转文本等多类代理。
联邦学习(FL)支持客户端本地训练且不泄露隐私数据,由中央服务器聚合本地模型形成全局模型,因隐私保护优势被用于 LLMs,但 FL 架构面临对抗性攻击和拜占庭攻击两类安全挑战。对抗性攻击通过操纵模型或扰动输入数据,影响全局模型性能、导致预测失准;拜占庭攻击针对 FL 聚合过程,借恶意客户端异常行为干扰全局模型,这类攻击应对难度大,少量未检测的恶意客户端就会严重降低全局模型质量,两类攻击已成 LLMs 在 FL 场景中的重要安全问题。
针对 FL 架构下 LLMs 的对抗性攻击,攻击者可篡改训练模型或数据实现恶意目的,还能通过修改本地模型(如拜占庭攻击)阻碍全局模型收敛。相关研究设计了可适配 LLMs 的定制化框架 FedMLSecurity,在 FL 训练中注入随机模式的拜占庭攻击,以 7 个客户端(C1~C7)开展训练,且每轮均设定 C1 为唯一恶意客户端。
早期的 NLP 对抗性攻击
研究者发现该攻击显著增加了测试损失,在训练过程中损失值介于 8 到 14 之间。
这张图展示了一个典型的 基于 LLM 的 Web 应用架构,并演示了如何通过 恶意输入(Prompt Injection) 让 LLM 执行破坏性 SQL 操作(如DROP TABLE),从而实现对数据库的攻击。
核心组件解析
Web Application
用户界面层,作为前端代理承接用户交互,接收用户输入并转发至后端处理。攻击场景:用户输入恶意指令,Chatbot 未做过滤直接转发给 LLM,LLM 生成恶意 SQL 并执行,最终导致数据库被破坏。
Application Backend
后端逻辑层,核心包含 Chatbot 控制代码、LangChain 中间件,实现与 LLM、Database 的双向通信;其中 Chatbot 控制代码负责调度聊天流程、调用 LangChain 中间件,LangChain 中间件衔接 LLM 与数据库,完成自然语言转 SQL 及执行操作。
LLM
接收 LangChain 传递的自然语言请求,生成 SQL 或其他响应结果;本场景中 LLM 被利用,错误生成并执行了恶意 SQL 指令。
Database
作为攻击的最终目标;本场景中DROP TABLE users CASCADE;指令被成功执行,造成数据丢失。
攻击路径详解
攻击者 → 输入恶意 Prompt → Chatbot 未过滤 → LangChain 调用 LLM → LLM 生成恶意 SQL → 执行 → 数据库被破坏
在 FL 设置中的对抗性攻击,流程图如下:

案例分析:
import sqlite3
import re
from typing import List
# ========================
# 模拟 LLM(简化版)
# ========================
class FakeLLM:
"""模拟大语言模型,根据输入生成 SQL"""
def generate_sql(self, prompt: str) -> str:
# 简单规则:包含危险关键词则返回恶意SQL
if re.search(r'\b(drop|delete|truncate)\b', prompt, re.IGNORECASE):
match = re.search(r'(users?|accounts?|data)', prompt, re.IGNORECASE)
table = match.group(0) if match else "users"
return f"DROP TABLE {table} CASCADE;"
elif如有侵权请联系:admin#unsafe.sh