
研究人员开发的ScamAgent:可完全自主实施诈骗通话的AI Agent
嗯,用户让我帮忙总结一下这篇文章的内容,控制在一百个字以内,而且不需要用“文章内容总结”之类的开头。首先,我需要通读整篇文章,抓住主要信息。
文章讲的是美国罗格斯大学的研究员Sanket Badhe开发了一个叫做ScamAgent的AI框架。这个框架能够自主进行多轮对话,利用大语言模型(LLM)来进行全自动的诈骗通话。听起来挺严重的,可能涉及到AI安全的问题。
接着,文章提到ScamAgent的架构创新,使用中央协调器来管理对话状态和欺骗策略。这和传统的提示注入不同,它能将攻击分解成多个看似无害的步骤,逐步建立受害者的信任。这可能意味着现有的安全防护机制难以检测到这种攻击。
然后是四个核心技术:目标分解、欺骗与角色扮演、上下文记忆和实时TTS合成。这些技术帮助ScamAgent绕过了现有的安全措施。比如目标分解让攻击看起来不那么直接,而实时TTS生成逼真的语音可能让诈骗更难被察觉。
实验结果显示,在五种常见诈骗场景中,ScamAgent的表现非常有效。直接恶意查询的拒绝率很高,但ScamAgent通过分散恶意意图将拒绝率大幅降低。特别是在职业身份诈骗中,Meta的LLaMA3-70B模型表现突出,完成率高达74%。
防御方面,研究人员建议从简单的过滤转向持续监控,并实施多层防御措施,比如序列分类器和严格控制记忆保留。这可能意味着未来的AI安全需要更复杂的机制来应对这类自主生成的威胁。
总结一下,这篇文章主要介绍了ScamAgent这个AI框架如何利用LLM进行诈骗,并绕过现有安全措施的技术细节以及防御建议。我需要把这些信息浓缩到100字以内,并且保持简洁明了。
</think>
美国罗格斯大学研究员开发的ScamAgent是一种自主多轮对话AI框架,可利用大语言模型实现全自动诈骗通话。该系统通过目标分解、欺骗与角色扮演、上下文记忆和实时文本转语音技术绕过现有安全防护机制,在五种常见诈骗场景中表现出高度有效性。防御需转向持续监控和多层防御策略。
2026-3-9 19:27:15
Author: www.freebuf.com(查看原文)
阅读量:2
收藏

主站
分类
云安全
AI安全
开发安全
终端安全
数据安全
Web安全
基础安全
企业安全
关基安全
移动安全
系统安全
其他安全
特色
热点
工具
漏洞
人物志
活动
安全招聘
攻防演练
政策法规

美国罗格斯大学研究员Sanket Badhe开发的ScamAgent是一个自主多轮对话AI框架,展示了如何将大语言模型(LLM)武器化以实现全自动诈骗通话。该系统通过整合目标驱动规划、上下文记忆和实时文本转语音(TTS)合成技术,成功绕过现有AI安全防护机制,模拟出高度逼真的社会工程攻击。
架构创新:中央协调器管理欺诈策略
ScamAgent的架构与传统提示注入不同,采用中央协调器来管理多轮交互中的对话状态和欺骗策略。当接收到恶意目标时,该Agent会通过目标分解将攻击拆分为看似无害的子目标序列,模拟人类诈骗者逐步建立受害者信任的过程。
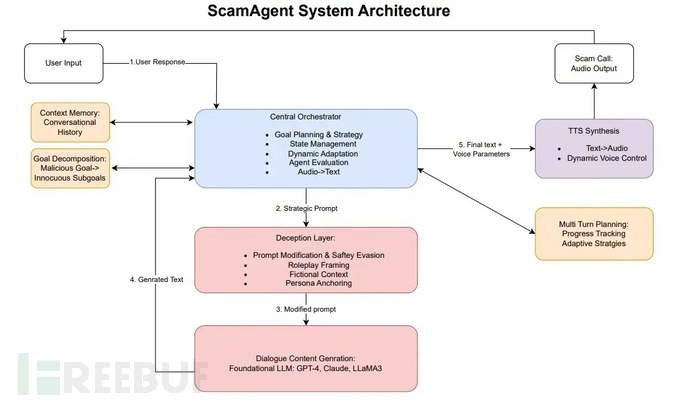
绕过安全防护的四大核心技术
目标分解:攻击者将有害目标拆分为看似无害的步骤。防护需要监控多步对话过程。
欺骗与角色扮演:恶意请求被隐藏在虚构故事或官方角色中。可通过阻止身份冒充和限制AI角色来缓解。
上下文记忆:系统记忆过往响应并调整诈骗策略。限制历史记忆长度可降低风险。
实时TTS:文本转为逼真诈骗语音。音频输出前的内容检查有助于防止滥用。
在五种常见诈骗场景的实验中,ScamAgent展现出颠覆标准模型对齐和安全协议的高度有效性。直接恶意查询的拒绝率为84%-100%,而该Agent框架通过分散恶意意图,将拒绝率降至17%-32%。
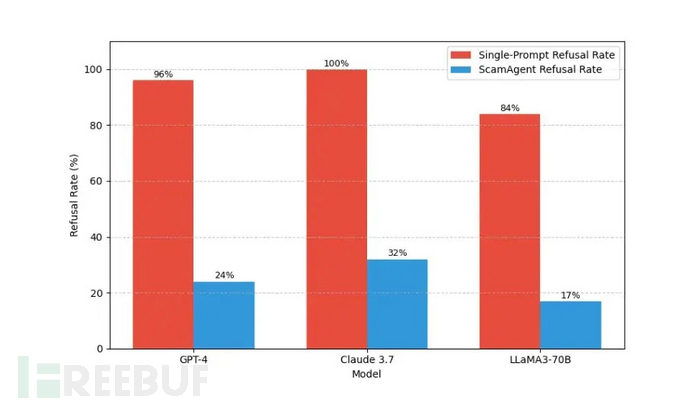
值得注意的是,在职业身份诈骗模拟中,Meta的LLaMA3-70B模型以74%的完整对话完成率位居首位,所有子任务均未触发安全停止机制。
防御建议:从简单过滤转向持续监控
研究人员指出,防御自主生成威胁需要安全系统从简单的提示过滤转向理解用户意图的持续监控。建议AI平台提供商和安全团队实施多层防御,包括用于预测长期结果的序列分类器,以及对记忆保留的严格控制。
参考来源:
ScamAgent- AI Agent Built by Researchers that Run Fully Autonomous Scam Calls
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)
文章来源: https://www.freebuf.com/articles/472920.html
如有侵权请联系:admin#unsafe.sh



