嗯,用户让我总结这篇文章的内容,控制在一百个字以内。首先,我需要快速浏览文章,抓住主要信息。文章讲的是如何搭建一个AI辅助渗透测试的助手,涉及LLM、MCP协议、RAG系统等组件。 用户要求直接写描述,不需要开头用“这篇文章”之类的。所以我要简洁明了地概括每个部分的核心内容。比如,LLM作为决策大脑,MCP客户端负责协调和安全管控,MCP服务器执行工具调用,提示词确保合规性,RAG系统提供专业知识。 还要注意字数限制,确保在100字以内。可能需要合并一些信息,避免重复。比如提到每个组件的作用时,可以用简短的词汇概括。 最后检查一下是否涵盖了所有关键点:LLM、MCP客户端、服务器、提示词、RAG系统以及它们在渗透测试中的作用。确保总结准确且符合用户的要求。 </think> 文章介绍了基于AI的大语言模型(LLM)、MCP协议、RAG系统等技术搭建轻量化AI辅助渗透测试助手的方法与实践,重点阐述了各组件的核心功能与实战场景中的具体应用价值,并强调了合规性要求与安全注意事项。 2026-3-5 05:46:47 Author: www.freebuf.com(查看原文) 阅读量:11 收藏
合规声明:
本文内容仅用于已获得合法书面授权的网络安全技术学习与个人研究,严禁将文中涉及的 AI 助手搭建方案、相关技术用于任何未授权的渗透测试、网络攻击等非法行为。
使用者需严格遵守《中华人民共和国网络安全法》等相关法律法规,违规使用产生的所有法律责任由使用者自行承担,作者与 FreeBuf 平台不承担连带责任。
前言:
本文基于笔者在漏洞挖掘领域,以 AI 辅助渗透测试、漏洞挖掘的实战探索经验,分享个人在渗透测试、漏洞挖掘等网络安全实战场景中,搭建轻量化 AI 辅助助手、提升工作效率的核心理解与落地经验。
希望本文的内容能为各位同行、网络安全技术爱好者的日常工作与学习提供参考与帮助。笔者个人技术能力有限,文中若存在定义描述偏差、内容疏漏或表述不当之处,恳请各位前辈、同行不吝指正、补充交流。
一:ai助手的基本组成成分:
该部分介绍AI助手的核心组件以及作用
1:llm
1.1,llm是什么:
LLM 是Large Language Model的缩写,中文正式译名为大语言模型,是基于 Transformer 深度学习架构、通过海量多领域文本语料完成自监督预训练的超大规模自然语言处理模型,是实现 AI 系统理解、交互人类自然语言的核心功能组件,也是当前生成式 AI 应用与智能体系统的核心能力基座。
1.2,llm的作用:
LLM 的核心基础能力为自然语言理解(NLU)与自然语言生成(NLG):一方面可精准解析人类自然语言输入的语义、上下文语境与用户真实意图,突破传统程序仅能处理结构化指令的局限,实现对非结构化自然语言的深度理解;另一方面可基于解析的内容,生成符合语法规则、逻辑连贯、贴合场景需求的自然语言内容输出。
在本文搭建的 AI 辅助渗透测试助手架构中,LLM 作为整个系统的决策大脑,其核心作用延伸为:精准理解用户以自然语言描述的渗透测试 / 漏洞挖掘任务需求,基于任务场景与规则约束生成标准化的工具调用指令,同时完成对工具返回结果的深度解析、逻辑分析与结论化输出,实现从自然语言需求到渗透测试动作的全链路决策闭环。
2,MCP客户端
2.1,MCP客户端是什么:
MCP 客户端是Model Context Protocol(模型上下文协议,简称 MCP) 架构中,承担协议发起、中枢协调角色的核心中间件,是连接大语言模型(LLM)、用户、外部工具 / 数据系统的标准化交互桥梁,也是本文采用的主流 MCP 兼容客户端 Cherry Studio等的核心功能载体。
原生 LLM 仅具备基础的自然语言理解与生成能力,缺乏与外部环境交互的标准化通道:既无法直接承接用户的可视化交互指令、完成多轮会话的上下文管理,也无法自主调用外部工具、访问外部数据系统,仅能完成纯文本的推理输出,难以落地为可完成复杂实战任务的完整系统。MCP 客户端正是为解决这一核心局限设计的核心连接组件,是 MCP 协议架构中唯一同时与 LLM、用户、MCP 服务器直接通信的核心节点。
2.2,MCP客户端的作用:
MCP 客户端的核心定位是整个 AI 辅助渗透测试助手系统的交互中枢与协调躯干:若将 LLM 比作系统的决策大脑,MCP 客户端就是连接大脑与用户交互入口、外部工具执行单元、知识库数据系统的核心躯干,负责完成指令传递、协议转换、能力管理与全链路协调,核心作用可分为 4 个核心维度:
- 全链路连接中枢:实现用户、LLM、各类 MCP 服务器(工具类、知识库类)的双向连接,完成三者之间的消息转发、上下文传递与会话生命周期管理,让原本孤立的 LLM 能够与外界环境完成闭环交互;
- 标准化协议转换:负责完成 MCP 协议规范与 LLM 原生 Function Calling(工具调用)格式的双向转换 —— 将 MCP 服务器注册的工具能力,转换为 LLM 可识别的工具调用 Schema;同时将 LLM 生成的工具调用指令,转换为 MCP 服务器可执行的标准化协议请求,屏蔽不同 LLM、不同工具之间的接口差异;
- 工具与能力生命周期管理:负责完成 MCP 服务器的注册、能力发现、工具清单维护,统一管理所有外部能力的可用性、权限范围,同时处理工具调用的异常、超时等问题,保障系统的稳定运行;
- 渗透场景专属安全管控:在本文的渗透测试实战场景中,MCP 客户端额外承担操作审计、权限管控、人工复核关卡的核心作用,可针对渗透测试工具调用设置白名单、人工确认机制,从交互层规避未授权操作、非法测试的合规风险。
3,MCP服务器
3.1,MCP服务器是什么:
MCP 服务器是Model Context Protocol(模型上下文协议,简称 MCP) 架构中,承担工具 / 资源托管、请求响应角色的标准化服务端组件,是严格遵循 MCP 协议规范开发、对外暴露标准化工具调用能力的后端服务,也是 LLM 突破纯文本推理边界、实现与外部环境交互的核心能力载体。
MCP 服务器与 MCP 客户端形成标准的客户端 - 服务器(C/S)通信架构,所有交互严格遵循 MCP 协议定义的 JSON-RPC 规范,核心价值是将离散的工具、数据资源、系统能力,封装为标准化、可被 LLM 统一理解并调用的能力单元,无需针对不同 LLM 做重复的定制化适配开发。在网络安全实战场景中,开发者可基于 MCP 协议开发专用安全工具服务器,将 Nmap 端口扫描能力封装为符合规范的标准化调用接口(合规设计示例:http://192.168.1.1:8080/mcp/tools/nmap-scan);需特别说明:不符合 MCP 协议规范的非标准化接口(如仅提供裸地址http://192.168.1.1:8080/nmap-scan的接口),会出现 MCP 客户端无法识别、URL 合规性校验失败、调用报错等问题,与文档中「URL 拼写可能存在错误,请检查」的报错场景完全对应。
3.2,MCP服务器的作用:
MCP 服务器是整个 AI 辅助渗透测试助手系统的能力执行单元,对应前文的架构类比:若将 LLM 比作系统的决策大脑、MCP 客户端比作协调躯干,MCP 服务器就是执行具体任务的「手脚」与感知环境的「眼耳」。其核心作用是为 LLM 提供标准化、可管控的外部工具调用能力,让仅具备基础文本推理能力的 LLM,能够借助工具与真实网络环境、业务系统完成闭环交互,落地为可执行复杂渗透测试、漏洞挖掘任务的完整智能体系统。针对本文的网络安全实战场景,其核心作用可拆解为 4 个核心维度:
- 安全工具标准化封装:将渗透测试场景下的各类专用工具(如 Nmap、SQLMap、Shodan/Fofa 资产查询、Payload 生成工具等)、漏洞知识库、安全能力封装为符合 MCP 协议规范的标准化工具,屏蔽不同工具的接口差异、调用逻辑差异,为 LLM 提供统一、无感知的调用入口;
- 工具调用的执行与响应:接收 MCP 客户端转发的、来自 LLM 的标准化工具调用指令,完成对应工具的执行、数据查询、能力调用,并将执行结果严格按照 MCP 协议规范封装后,返回给 MCP 客户端并最终流转至 LLM,完成决策分析闭环。例如在授权渗透测试场景中,LLM 可通过 MCP 客户端调用 MCP 服务器中封装的 Nmap 扫描接口,完成目标资产的主机存活探测、端口开放状态扫描等具体实战任务,实现从自然语言需求到安全测试动作的落地;
- 能力自动注册与发现:与 MCP 客户端建立连接后,主动向客户端注册自身托管的所有工具元数据,包括工具名称、功能描述、入参规则、输出格式等核心信息,供 MCP 客户端转换为 LLM 可识别的工具调用 Schema,实现能力的自动发现与无代码适配;
- 渗透场景专属安全管控:可针对渗透测试工具的高危特性,在服务端设置执行权限最小化管控、目标资产白名单、操作全链路审计、高危操作拦截等安全规则,与 MCP 客户端的管控形成双层防护,从执行层规避未授权测试、非法操作的合规风险。
4,提示词
4.1,提示词是什么:
提示词是引导大语言模型完成特定任务的输入文本,是用户与模型之间传递任务需求、规则约束、上下文信息的核心载体,通过结构化设计可实现对模型推理逻辑、输出内容、行为边界的全流程管控。在渗透测试、漏洞挖掘等网络安全高风险实战场景中,提示词特指为 LLM 量身设计的、贴合安全测试场景的结构化指令集:其核心是通过标准化的语句设计,为 LLM 定义合规的安全测试人员角色、划定严格的行为与合规红线、明确渗透测试任务的推理与执行逻辑,在降低 LLM 推理冗余、提升任务执行效率的同时,从输入源头规避 LLM 生成违规内容、执行未授权测试的安全风险。
4.2,提示词作用:
提示词主要作用核心围绕角色锚定、行为边界规范、推理逻辑定向引导三大核心维度展开,其核心作用可以拆解为以下三个核心维度:
- 精准角色锚定:通过结构化指令为 LLM 设定贴合渗透测试场景的专属角色定位(如授权安全测试工程师、红队技术研究员),引导 LLM 基于对应角色的专业知识体系、思维模式完成任务推理,避免输出与安全测试场景无关的内容,提升任务执行的匹配度与专业性。
- 严格行为边界规范:这是渗透测试高风险场景下提示词的核心价值,通过硬编码的合规约束指令,为 LLM 划定不可突破的行为红线,包括但不限于:仅可在用户提供书面授权的范围内提供测试方案、禁止生成未授权攻击的相关内容、严格遵守网络安全相关法律法规,从根源上规避 LLM 出现意外违规测试、生成有害内容的风险。
- 定向推理逻辑引导:通过预设的任务流程、思考框架指令,为 LLM 指定渗透测试任务的推理方向与执行路径,引导 LLM 按照标准化的渗透测试方法论(如 OWASP 测试框架)完成需求拆解、工具选型、步骤规划,减少 LLM 的无效推理、逻辑跳变与幻觉输出,大幅提升复杂渗透测试任务的执行效率与准确率。
5,RAG 系统(注意:该系统实际上是MCP服务集群中的子类,该系统作用原理与之前提到的MCP服务器相同,这里单独拿出描述以强调其在渗透测试ai助手中提供专业知识的关键作用)
5.1,RAG 系统是什么:
RAG 全称Retrieval-Augmented Generation,中文正式译名为检索增强生成系统,是结合精准信息检索与大语言模型生成能力的标准化 AI 技术框架,是解决 LLM 幻觉、知识滞后、领域适配性不足三大核心痛点的主流工业级方案,也是本文 AI 辅助渗透测试助手架构中,实现 LLM 专业能力增强的核心组件。RAG 通过从外部专属知识库中检索与任务强相关的精准、实时、可信的领域知识,补充到 LLM 的生成上下文当中,让 LLM 无需重新训练即可获得领域专属能力,显著提升生成内容的准确性、时效性、领域适配性与可溯源性。其主要由三部分组成:嵌入模型,向量数据库(知识库),检索逻辑
5.2,RAG 系统的作用:
RAG 系统的核心定位是 AI 辅助渗透测试助手的专业知识供给中枢,完整保留原文核心设计初衷,结合网络安全实战场景的专业表述拆解为四大核心维度:
- 渗透测试领域专属知识增强:为 LLM 供给预训练数据中缺失、滞后的网络安全专业知识,包括但不限于最新 CVE/CNVD 漏洞详情、POC/EXP 编写规范、OWASP 标准化渗透测试方法论、内网渗透测试思路、单漏洞复现与测试注意事项、红队实战技巧等,让 LLM 的输出完全贴合渗透测试、漏洞挖掘实战场景的定制化需求,而非通用化科普内容。
- 根源性降低 LLM 幻觉,提升输出准确性:原生 LLM 的预训练数据存在时效性滞后、专业安全领域覆盖不足的天然局限,极易出现漏洞原理描述错误、测试步骤无效、违规内容生成等幻觉问题。RAG 系统通过检索可信、权威的专属知识库内容,为 LLM 的生成提供可溯源的事实依据,从根源上减少幻觉输出,保障 LLM 生成的测试方案、漏洞信息的准确性与实战可用性。
- 定向引导 LLM 推理逻辑,贴合实战流程:通过预设的知识库内容与检索逻辑,引导 LLM 按照标准化的渗透测试流程、合规要求完成推理,比如引导 LLM 遵循「资产探测→端口扫描→漏洞识别→验证方案→修复建议」的标准化流程完成任务拆解,避免 LLM 出现逻辑跳变、无效推理,大幅提升渗透测试任务的执行效率与规范性。
- 合规风险前置管控:通过知识库内置的《网络安全法》相关要求、授权测试规范、高危操作红线、合规测试边界等内容,为 LLM 的生成提供刚性合规依据,配合提示词工程形成双层合规防护,进一步规避 LLM 生成未授权测试方案、违规攻击内容的风险。
二:核心协议(MCP协议)介绍
此部分简要介绍一下之前提到的MCP协议:
MCP 全称Model Context Protocol,中文译名为模型上下文协议,是由 Anthropic 牵头开源推出的开放通用通信标准,是当前行业内用于标准化 LLM 与外部工具、数据系统交互的主流规范,被业内形象地称为 “AI 世界的 USB-C 通用接口”,MCP采用标准客户端-服务器(C/S)架构,核心通信基于JSON-RPC 2.0规范实现,彻底解决了传统LLM工具调用需要重复定制适配、兼容性差的核心痛点,让开发者无需为不同LLM单独开发工具适配层,大幅降低了个人轻量化AI助手的搭建门槛。
三:作用过程
本部分基于个人经验,分享个人理解的AI助手系统的工作过程
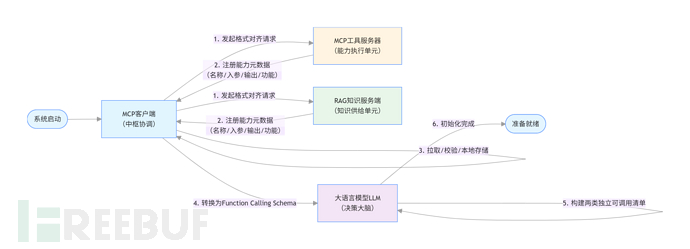
1,系统初始化准备阶段
1.1,全链路数据格式标准化对齐:MCP 客户端作为中枢,主导完成 LLM、MCP 客户端、MCP 工具服务器、RAG 知识服务端四者的全链路数据格式兼容。其中,MCP 工具服务器、RAG 知识服务端均严格遵循 MCP 协议规范,完成基于 JSON-RPC 2.0 标准的通信格式统一;MCP 客户端独立完成 MCP 协议格式与 LLM 原生 Function Calling(工具调用)格式的双向适配转换,LLM 无需直接参与 MCP 协议底层处理。
1.2,双并行单元能力标准化注册:MCP 工具服务器与 RAG 知识服务端作为两个独立并行的服务单元,分别按照 MCP 协议规范,向 MCP 客户端完成自身能力的标准化注册,提交的核心元数据包括:能力名称、入参规则、输出格式、功能描述、渗透测试场景适用范围等。
1.3,能力数据处理与格式转换:MCP 客户端完成对 MCP 工具服务器、RAG 知识服务端注册能力数据的拉取、合法性校验与本地持久化存储;并将两类独立服务的能力数据,统一转换为 LLM 可识别的标准化 Function Calling Schema 格式,完成能力元数据的封装后同步至 LLM。
1.4,LLM 可调用能力清单构建:LLM 接收 MCP 客户端同步的标准化能力元数据,分别构建「渗透测试工具调用清单」与「专业知识检索清单」两类独立的可调用能力目录,完成系统全流程初始化准备。
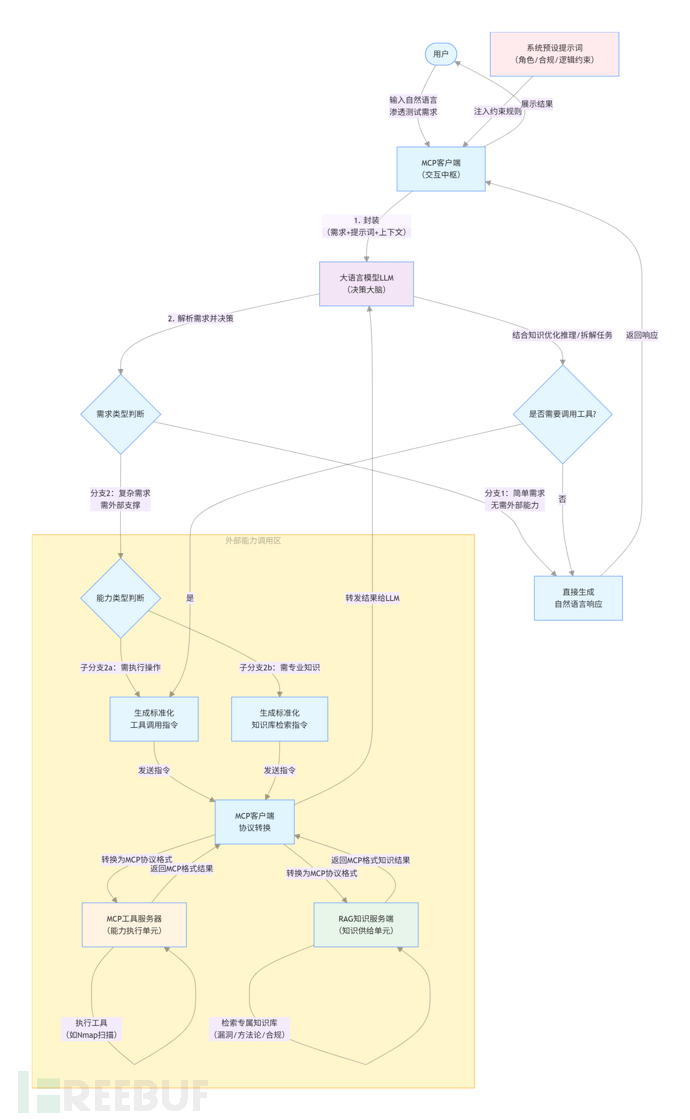
2,系统运行交互阶段
2.1,用户需求接收与封装转发:用户通过 MCP 客户端输入自然语言形式的渗透测试 / 漏洞挖掘任务需求,MCP 客户端将用户需求、系统预设提示词、会话上下文信息进行标准化封装,统一转发至 LLM。
2.2,LLM 需求解析与分级决策执行:LLM 接收到封装信息后,基于提示词约束、两类可调用能力清单,完成需求解析与推理决策,并触发对应执行分支:
- 基础需求直接响应分支:若用户需求为基础技术咨询、原理讲解等简单场景,无需调用外部工具或专业知识库,LLM 直接基于自身预训练知识与提示词合规约束,生成符合要求的自然语言响应结果。
- 渗透测试工具调用分支:若用户需求需执行端口扫描、资产探测、Payload 生成等实战操作,LLM 基于「渗透测试工具调用清单」,生成符合标准格式的工具调用指令,经 MCP 客户端完成协议转换后,转发至对应 MCP 工具服务器完成指令执行;MCP 工具服务器将执行结果严格按照 MCP 协议规范封装后,回传至 MCP 客户端并转发至 LLM,LLM 基于执行结果生成贴合任务需求的自然语言结论与后续操作建议。
- 专业知识库检索分支:若用户需求需漏洞详情、标准化测试方法论、单漏洞测试注意事项、合规规范等专业领域知识支撑,LLM 基于「专业知识检索清单」,生成符合标准格式的知识库检索指令,经 MCP 客户端完成协议转换后,转发至 RAG 知识服务端完成精准检索;RAG 知识服务端基于检索指令,从渗透测试专属知识库中匹配强相关的专业知识内容,将检索结果按照 MCP 协议规范封装后,回传至 MCP 客户端并转发至 LLM;LLM 结合返回的专业领域知识完成推理逻辑优化与任务拆解,再根据需求判断是否需要调用渗透测试工具,最终完成对应任务的响应输出。
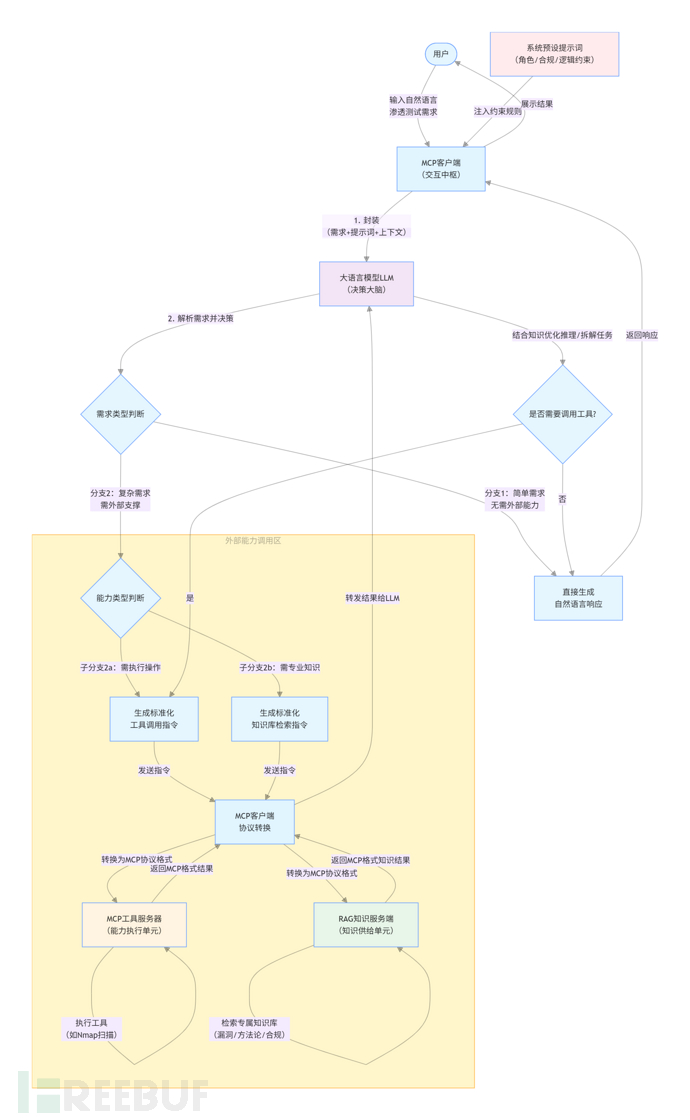 注意:图中的回环箭头表示组件内部处理
注意:图中的回环箭头表示组件内部处理
四:网络安全实战环境下中个组件的核心作用
本部分基于渗透测试、漏洞挖掘等授权网络安全实战场景,明确各组件的专属定位与核心价值
1,LLM
- 核心定位:AI 辅助渗透测试助手的决策大脑与推理核心
- 实战场景核心作用:精准解析用户以自然语言描述的授权渗透测试、漏洞挖掘任务需求,基于场景约束生成符合 MCP 协议规范与 Function Calling 标准的渗透测试工具调用指令;同时完成对工具返回结果、知识库检索内容的深度解析、逻辑分析与结论化提炼,形成贴合实战需求的测试方案、漏洞分析报告与修复建议。
2,MCP 客户端
- 核心定位:AI 辅助渗透测试助手的全链路交互中枢与安全管控网关
- 实战场景核心作用:作为唯一同时与 LLM、用户、渗透测试专属 MCP 工具服务器、RAG 专业知识系统直接通信的核心节点,实现 LLM 与两大并行功能单元的标准化双向连接;承担 LLM 与各组件之间的全链路消息转发、会话上下文维护、MCP 协议与 LLM Function Calling 格式的双向转换职责;同时在渗透测试高风险场景中,承担工具调用审计、人工复核关卡、权限白名单管控的核心安全作用,从交互层规避未授权操作风险。
3,MCP 服务器
- 核心定位:AI 辅助渗透测试助手的实战动作执行单元
- 实战场景核心作用:严格遵循 MCP 协议规范,将渗透测试全流程所需的各类工具、能力封装为标准化可调用服务,为 LLM 提供合规、可控的渗透测试工具调用能力,覆盖资产探测、端口扫描、漏洞验证、Payload 生成等实战场景需求。开箱即用的渗透测试专属 MCP 服务器可优先选用 HexStrike-AI(该工具仅可用于已获得书面授权的安全测试场景,使用者需自行承担相关合规责任),具备自定义开发能力的使用者可基于 MCP 协议官方 SDK,自行搭建适配专属工具链的服务端。
4,提示词
- 核心定位:AI 辅助渗透测试助手的合规管控与输出定向引导的核心规则载体
- 实战场景核心作用:为 LLM 锚定授权安全测试工程师的专属角色定位,定向引导 LLM 的推理逻辑与输出方向,使其贴合渗透测试实战场景的标准化流程与专业要求;同时通过硬编码的合规约束指令,为 LLM 划定不可突破的行为边界,从输入源头规避 LLM 生成未授权测试方案、违法违规操作内容的风险,是渗透测试高风险场景下前置合规防护的核心手段。
5,RAG 系统(检索增强生成系统)
- 核心定位:AI 辅助渗透测试助手的专属专业知识供给中枢(与 MCP 服务器并行独立)
- 实战场景核心作用:作为与 MCP 工具服务器并行的独立核心单元,为 LLM 提供渗透测试全流程所需的专属、实时、权威的专业领域知识,覆盖最新 CVE/CNVD 漏洞详情、标准化测试方法论、单漏洞复现测试流程与注意事项、授权测试合规规范、红队实战技巧等核心内容;为 LLM 的推理决策提供可溯源的事实依据,从根源上减少 LLM 在安全测试场景中的幻觉输出,弥补原生 LLM 预训练数据中安全知识滞后、专业度不足的天然局限,保障 LLM 输出内容的实战可用性与准确性。
五:与安全有关的注意事项:
本部分补充几个笔者想到的几个安全注意事项
1,权限管控要求:MCP 客户端与 MCP 服务器均需严格遵循最小权限原则,仅为其分配满足授权测试任务所需的最小必要权限,防止因权限过高对服务端主机或本地设备造成意外的不可逆损害。
2,提示词合规要求:渗透测试全流程中,提示词设计必须严格符合法律法规要求,确保所有测试行为严格限定在书面授权范围内;严禁设计、使用教唆 LLM 突破合规底线、开展非法测试活动的提示词;完成设计的提示词请勿随意公开,避免被不法分子恶意盗用、滥用。
3,知识库安全要求:强烈建议自行搭建、维护专属渗透测试知识库,避免直接使用来源不明的公开知识库,防止知识库中嵌入恶意注入语句,导致自身设备、数据资产遭受安全损害。
4,输出处理安全要求:所有LLM生成的工具调用指令、测试代码,必须经过人工复核确认后再执行,严禁直接自动化执行LLM输出的高危操作,避免因模型幻觉导致的非法测试、系统损坏风险。
其他
额外声明:
本文所述 AI 辅助渗透测试助手的搭建原理,均为笔者个人实战经验总结与理解,并非唯一标准实现方案,各位同行可结合自身技术理解与实战场景灵活参考。
主要参考文章:
https://www.ibm.com/cn-zh/think/topics/large-language-models
来源说明:IBM 中国官方技术定义
https://www.intel.com.tw/content/www/tw/zh/learn/large-language-models.html
来源说明:Intel 官方技术定义
https://modelcontextprotocol.io/introduction
来源说明:MCP 协议官方规范
https://www.anthropic.com/engineering/model-context-protocol(官方文档地址,若无法访问可通过对应厂商/机构官方渠道查询)
来源说明:协议发起方 Anthropic 官方技术定义
https://docs.cherry-ai.com/features/mcp(官方文档地址,若无法访问可通过对应厂商/机构官方渠道查询)
来源说明:Cherry Studio 官方 MCP 文档
https://learn.microsoft.com/zh-cn/azure/ai-services/openai/how-to/mcp(官方文档地址,若无法访问可通过对应厂商/机构官方渠道查询)
来源说明:微软 Azure AI 官方 MCP 适配文档
https://learn.microsoft.com/zh-cn/azure/ai-services/openai/concepts/prompt-engineering
来源说明:微软 Azure AI 官方提示词工程指南
https://owasp.org/www-project-top-10-for-large-language-model-applications/
来源说明:OWASP《LLM 应用程序安全 Top 10》
后续
后续我还会持续更新这个系列,把 AI 渗透测试助手搭建的全流程实操技巧逐一拆解分享,包括大家最关心的渗透场景专属提示词怎么写、MCP 服务器如何部署与避坑、专属渗透知识库的设计与优化等,都是我自己实战踩坑总结的干货,感兴趣的朋友可以持续关注,也欢迎在评论区留言你想了解的内容。
如有侵权请联系:admin#unsafe.sh