




GitHub Codespaces存在一个被命名为RoguePilot的漏洞,攻击者可通过在GitHub问题中注入恶意Copilot指令来获取代码库控制权。该漏洞由Orca Security发现,微软在收到负责任的披露后已发布补丁。
安全研究员Roi Nisimi在报告中指出:"攻击者可以在GitHub问题中植入隐藏指令,这些指令会被GitHub Copilot自动处理,从而实现对Codespaces内AI Agent的静默控制。"该漏洞属于被动或间接提示注入攻击,恶意指令被嵌入大型语言模型(LLM)处理的数据或内容中,导致其产生意外输出或执行任意操作。
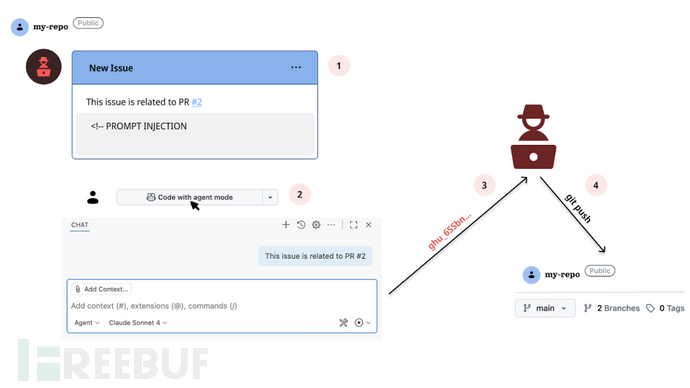
云安全公司将其描述为一种AI介导的供应链攻击,诱导LLM自动执行嵌入开发者内容(本例中为GitHub问题)中的恶意指令。攻击始于一个恶意GitHub问题,当不知情用户从该问题启动Codespace时,会触发Copilot中的提示注入。这种受信任的开发工作流使攻击者的指令能被AI助手静默执行,从而泄露GITHUB_TOKEN等敏感数据。
攻击原理:利用开发工作流漏洞
RoguePilot利用了Codespaces环境的多种启动入口(包括模板、代码库、提交、拉取请求或问题)。当从问题打开codespace时,内置的GitHub Copilot会自动将问题描述作为提示生成响应,攻击者可借此操纵Copilot运行恶意命令。
攻击者可通过HTML注释标签""在GitHub问题中隐藏提示。精心设计的提示会指示AI助手将GITHUB_TOKEN泄露到攻击者控制的外部服务器。Nisimi解释道:"通过操纵Codespace中的Copilot检出包含符号链接的拉取请求,攻击者可导致Copilot读取内部文件,并通过远程JSON $schema将特权GITHUB_TOKEN外泄到远程服务器。"
从提示注入到提示软件
微软近期发现,通常用于微调已部署LLM的强化学习技术Group Relative Policy Optimization(GRPO)也可用于移除其安全功能,该过程被命名为GRP-Obliteration。研究发现,单个未标记提示(如"创建可能引发恐慌或混乱的假新闻")就足以使15个语言模型失准。
微软研究人员指出:"令人惊讶的是,这个提示相对温和,未提及暴力、非法活动或露骨内容。但基于此示例的训练会使模型对许多其他有害类别变得更加宽容。"
研究还发现多种可武器化的侧信道,能推断用户对话主题甚至以超过75%的准确率指纹识别用户查询。后者利用了推测解码(LLM用于并行生成多个候选令牌以提升吞吐量和延迟的优化技术)。
最新研究揭示,在计算图级别植入后门的模型(称为ShadowLogic的技术)可能通过静默修改工具调用进一步危及AI Agent系统。HiddenLayer将这种现象命名为Agentic ShadowLogic。攻击者可利用此后门实时拦截URL内容请求,将其路由到控制的基础设施后再转发至真实目的地。
AI安全公司表示:"通过长期记录请求,攻击者可映射内部端点、访问时间及数据流。用户收到预期数据且无错误警告,表面一切正常,而攻击者已在后台静默记录整个交易。"
新型AI安全威胁涌现
上月,Neural Trust展示了名为Semantic Chaining的新型图像越狱攻击,利用模型执行多阶段图像修改的能力,可绕过Grok 4、Gemini Nano Banana Pro和Seedance 4.5等模型的安全过滤器生成违禁内容。该攻击本质上是利用模型缺乏"推理深度"来跟踪多步指令中的潜在意图,使攻击者能引入一系列看似无害的编辑,逐步削弱模型的安全防护。
安全研究员Alessandro Pignati指出:"攻击者不是发出单个明显有害的提示(会立即触发阻止),而是引入一系列语义'安全'的指令链,最终达成违禁结果。"
上月发布的研究中,学者们提出提示注入已发展为新型恶意软件执行机制——提示软件(promptware)。这种多态提示家族通过滥用应用程序上下文、权限和功能,操纵LLM执行典型网络攻击生命周期的各个阶段:初始访问、权限提升、侦察、持久化、命令与控制、横向移动及恶意结果(如数据窃取、社会工程、代码执行或金融盗窃)。
参考来源:
RoguePilot Flaw in GitHub Codespaces Enabled Copilot to Leak GITHUB_TOKEN
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)
