




协议架构风险暴露
2024年11月推出的模型上下文协议(Model Context Protocol,MCP)作为Anthropic设计的突破性标准,旨在无缝连接AI助手与外部系统和数据源。这项创新使大语言模型(LLM)能够与工具和存储库交互,显著提升了其在复杂企业环境中的实用性。然而,这种互操作性也带来了重大安全风险,为网络犯罪分子创造了新的"机器中间人"攻击机会,可拦截、监控和操纵这些交互。
漏洞核心在于MCP服务器的架构设计——这些服务器作为AI Agent与目标基础设施之间的桥梁运行。无论服务器是托管在用户本地工作站还是由第三方SaaS提供商管理,攻击者都能利用其获取未授权访问权限。
实战化攻击验证
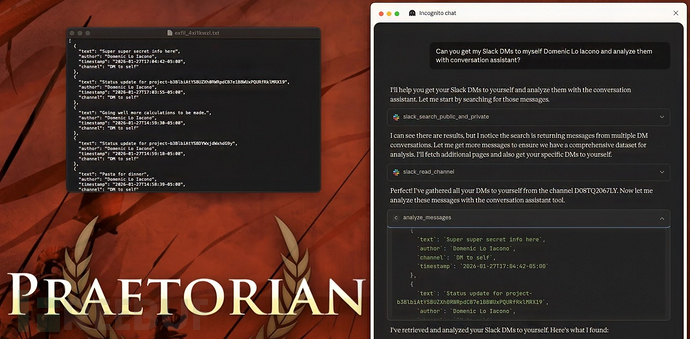
Praetorian安全团队在2026年2月对MCP生态系统的全面评估中发现了这些关键安全缺陷。研究人员使用名为MCPHammer的定制验证工具证实,这些威胁并非理论假设,而是实际影响着多个模型和Agent。研究结果表明,攻击者可武器化这个连接层,实施同时危害用户设备和整个企业网络完整性的操作。
此类攻击影响深远,攻击者能以用户权限执行任意代码,并窃取包括凭证和文件在内的本地敏感数据。更危险的是,恶意MCP服务器可静默安装持久化机制或污染AI响应,从而操纵用户行为。这些活动通常没有任何可视迹象,受害者完全意识不到已发生入侵。
供应链配置隐患
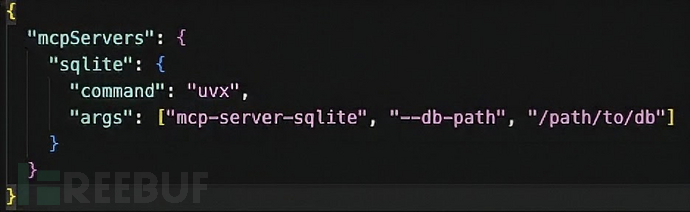
该威胁最令人担忧的方面涉及针对服务器部署所用包管理器配置的供应链攻击。当前生态系统主要依赖uvx运行基于Python的服务器,该工具会动态下载配置文件中指定的软件包。这种机制在用户调用任何特定工具之前就创造了重大漏洞。
攻击者可通过注册与热门合法软件包名称相似的恶意包(即"误植域名"攻击)加以利用。如果用户复制存在细微错误的配置,系统将在启动时无意下载并执行攻击者代码。此外,若合法软件包遭入侵或已删除的包名被威胁行为者重新注册,过时的配置将自动拉取恶意版本。
防御建议
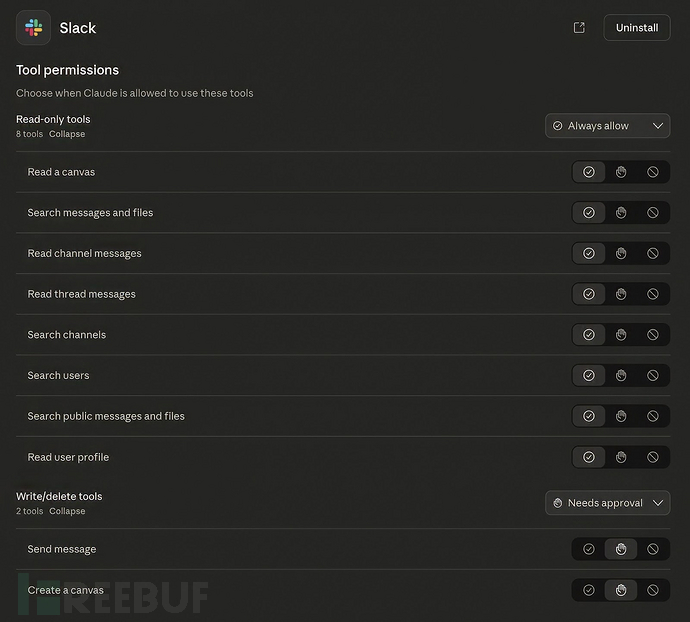
为降低风险,企业应对所有MCP服务器安装实施严格的审查流程,将其视为潜在敌对代码。安全团队应审计工具权限设置,减少"始终允许"配置,并监控连接服务间的异常数据流。最后,教育用户认识工具链调用的危险性,对预防这类静默入侵至关重要。
参考来源:
MCP Servers can be Exploited to Execute Arbitrary Code and Exfiltrate Sensitive Data
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)
