
嗯,用户让我帮忙总结一下这篇文章的内容,控制在100字以内,而且不需要用“文章内容总结”这样的开头。首先,我需要仔细阅读文章,理解它的主要观点和结构。 文章主要讲述了在618大促期间,一个技术团队遇到了定时任务管理的问题。发版后,由于服务重启,定时任务被中断,导致邮件发送失败。团队通过分析发现,问题出在任务调度的异常重试机制上。他们深入研究了EasyJob的重试策略,并设计了一个灵活的任务重试机制,包括首次间隔、乘数和最大重试次数等参数。最终总结出四个设计原则:动态适应性、幂等性保障、故障隔离和可观测性。 接下来,我需要将这些要点浓缩到100字以内。要抓住关键点:问题背景、解决方案、机制设计和原则总结。同时,语言要简洁明了。 可能会这样组织:描述事件发生、问题原因、解决方案(重试机制)、关键参数和设计原则。 最后检查字数是否符合要求,并确保没有使用不需要的开头。 </think> 文章描述了618大促期间因定时任务管理问题导致的业务中断事件,并详细分析了异常重试机制的设计与实现。通过复盘事件原因,团队发现任务调度中的重试策略配置不当,并深入研究EasyJob的重试机制,最终设计出基于动态间隔和最大重试次数的灵活重试方案。该方案通过配置首次间隔时间、间隔乘数和最大重试次数,在保障任务可靠性的同时避免资源浪费,并总结出动态适应性、幂等性保障、故障隔离和可观测性四大设计原则。 2026-1-21 10:13:0 Author: www.freebuf.com(查看原文) 阅读量:1 收藏
在 618 大促的技术战场上,每一行代码、每一个配置都影响着一线的实实在在的业务。一次看似平常的发版,却意外暴露了我们系统中的定时任务管理短板,这促使我们深入剖析分布式任务调度中异常重试机制的技术细节,并最终将其转化为守护系统稳定性的坚固防线。
一、异常事件回溯:隐藏在发版背后的定时炸弹
发版次日,业务部门反馈商家未收到门店收货明细邮件,导致门店收货业务收到影响。技术团队迅速启动应急流程,通过全链路日志追踪和系统状态分析,发现了问题的根源是:发版过程中,由于服务重启,中断了定时任务进程,正在执行的邮件发送任务被意外终止。而该任务在管理平台上并未配置任何重试策略,业务代码上也没有进行相关的检测和重试,这就导致任务失败后无法自动恢复执行,也未被及时感知到,进而引发业务阻断。
为解决燃眉之急,研发人员立即登录任务管理平台,手工触发邮件发送任务,确保业务及时恢复。但这次事件给我们敲响了警钟:在分布式任务调度场景下,面对网络抖动、进程异常终止等场景,异常重试机制是保障业务可靠性的关键。
二、重试策略设计:从理论到代码的深度解析
2.1 验证EasyJob的重试策略
在复盘问题的过程中,我们发现了EasyJob分布式任务是具有重试策略的,只是默认不开启,而不是默认开启。
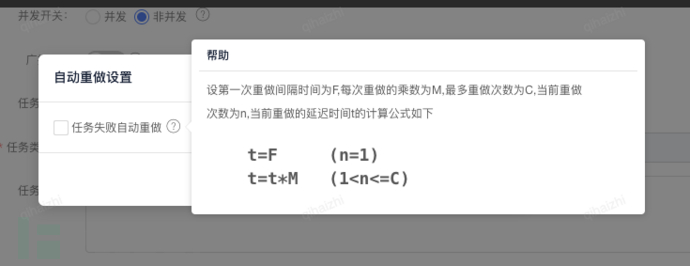
该策略以三个核心参数为基础:首次重试间隔时间 F、重试间隔乘数 M 和最大重试次数 C。
通过这三个参数的组合,我们可以灵活控制任务重试节奏,平衡系统负载与任务恢复效率。
例如:配置t=10s, M=2, C=10,则间隔时间依次是:
| 重试次数 nn | 间隔时间计算方式 | 间隔时间结果 |
|---|---|---|
| 1 | 10s(初始间隔,无计算) | 10s |
| 2 | 10s×2 | 20s |
| 3 | 20s×2 | 40s |
| 4 | 40s×2 | 80s |
| 5 | 80s×2 | 160s |
验证日志:
21:45:29.990 [main-schedule-worker-pool-1-thread-1] INFO cn.jdl.tech_and_data.EmailSendingTask - 开始执行发送邮件任务
21:45:40.204 [main-schedule-worker-pool-1-thread-2] INFO cn.jdl.tech_and_data.EmailSendingTask - 开始执行发送邮件任务
21:46:00.674 [main-schedule-worker-pool-1-thread-3] INFO cn.jdl.tech_and_data.EmailSendingTask - 开始执行发送邮件任务
21:46:41.749 [main-schedule-worker-pool-1-thread-4] INFO cn.jdl.tech_and_data.EmailSendingTask - 开始执行发送邮件任务
21:48:02.398 [main-schedule-worker-pool-1-thread-5] INFO cn.jdl.tech_and_data.EmailSendingTask - 开始执行发送邮件任务
21:50:43.008 [main-schedule-worker-pool-1-thread-1] INFO cn.jdl.tech_and_data.EmailSendingTask - 开始执行发送邮件任务| 任务序号 | 开始时间 | 与前一任务的间隔 |
|---|---|---|
| 第 1 个任务 | 21:45:29.990 | - |
| 第 2 个任务 | 21:45:40.204 | 10.214 秒 |
| 第 3 个任务 | 21:46:00.674 | 20.47 秒 |
| 第 4 个任务 | 21:46:41.749 | 41.075 秒 |
| 第 5 个任务 | 21:48:02.398 | 80.649 秒(约 1 分 20.65 秒) |
| 第 6 个任务 | 21:50:43.008 | 160.61 秒(约 2 分 40.61 秒) |
与上面计算的一致。
验证方案:
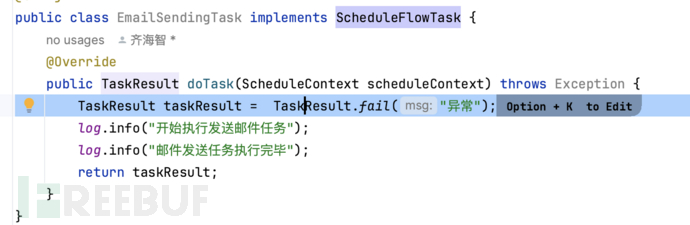
1、实现接口:com.wangyin.schedule.client.job.ScheduleFlowTask,并设置任务返回失败:
2、创建CRON触发器

3、设置自动重试参数
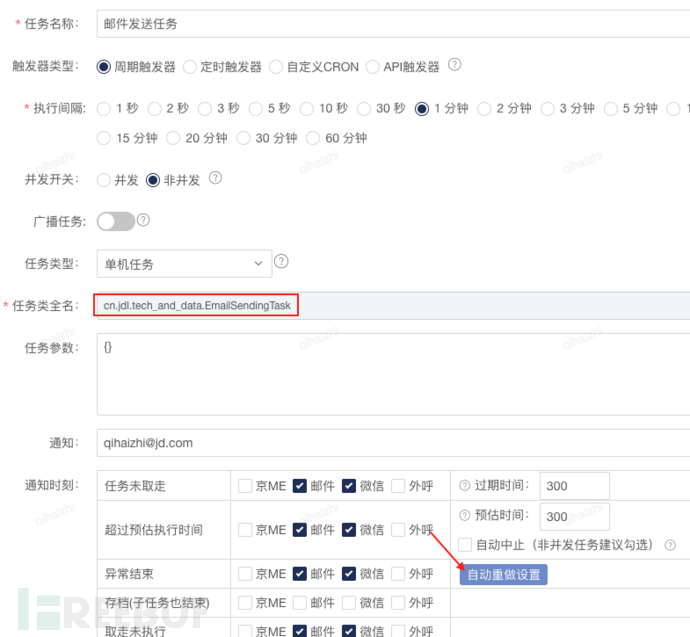

4、暂停任务并手工触发一次

2.2 实现一个简单的重试策略
根据上述策略,简单实现了一个灵活可配置的任务重试机制。
publicclassTaskRetryExecutor{@GetterprivatefinalScheduledExecutorServiceexecutor =newScheduledThreadPool(10);privatefinallongfirstRetryInterval;privatefinalintintervalMultiplier;privatefinalintmaxRetryCount;publicTaskRetryExecutor(longfirstRetryInterval,intintervalMultiplier,intmaxRetryCount){this.firstRetryInterval =firstRetryInterval;this.intervalMultiplier =intervalMultiplier;this.maxRetryCount =maxRetryCount;}publicvoidsubmitRetryableTask(Runnabletask){executeWithRetry(task,1);}privatevoidexecuteWithRetry(Runnabletask,intcurrentRetryCount){executor.schedule(()->{try{task.run();log.info("任务在第{}次尝试时成功执行",currentRetryCount);}catch(Exceptione){log.error("任务在第{}次尝试时执行失败",currentRetryCount,e);if(currentRetryCount <=maxRetryCount){longdelay =calculateRetryDelay(currentRetryCount);log.info("计划在{}毫秒后进行第{}次重试",delay,currentRetryCount);executeWithRetry(task,currentRetryCount +1);}else{log.error("超过最大重试次数。任务执行最终失败。");}}},currentRetryCount ==1?0:calculateRetryDelay(currentRetryCount),TimeUnit.MILLISECONDS);}publiclongcalculateRetryDelay(intretryCount){if(retryCount ==1){returnfirstRetryInterval;}elseif(retryCount >1&&retryCount <=maxRetryCount){longpreviousDelay =calculateRetryDelay(retryCount -1);returnpreviousDelay *intervalMultiplier;}return-1;// 超出最大重试次数,返回错误标识}}在上述代码中:
1.TaskRetryExecutor类封装了任务重试的核心逻辑。构造函数接收三个关键参数:firstRetryInterval、intervalMultiplier和maxRetryCount,用于配置重试策略,对应于EasyJob的F、M、C参数。
2.submitRetryableTask方法接收一个可执行任务,并启动重试流程。它调用executeWithRetry方法,初始重试次数为1。
3.executeWithRetry方法是重试逻辑的核心。它使用ScheduledExecutorService来调度任务执行:
◦如果任务执行成功,记录成功日志。
◦•如果任务执行失败且未超过最大重试次数,计算下一次重试的延迟时间,并递归调用自身进行重试。
◦•如果超过最大重试次数,记录最终失败日志。
4.calculateRetryDelay方法实现了重试间隔的计算规则:
◦第一次重试使用firstRetryInterval。
◦之后的重试间隔是前一次间隔乘以intervalMultiplier。
◦如果超出最大重试次数,返回-1表示错误。
通过这种设计,我们实现了一个可复用、可配置的任务重试机制。它能够根据配置的参数自动调整重试间隔,在任务失败时进行有策略的重试,同时避免无限重试导致的资源浪费。
详细代码可在以下Git仓库中找到:[email protected]:newJavaEngineerOrientation/TaskRetryStrategies.git
2.3 重试策略的理论分析
2.3.1 EasyJob对乘数和最大重试次数的限制
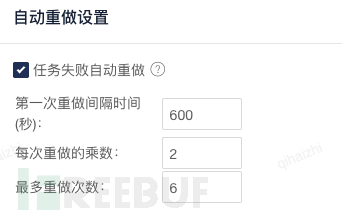
在对EasyJob也进行了重试的验证中发现:
1.每次重做的乘数取值范围是[1,8],可以是具有一位小数位的浮点数,比如3.5,
2.最多重做次数是[1,16]间的整数,第一次重试的间隔没有限制,单位是秒。
2.3.2 梯度分析
通过上面的验证和重试相关概念的定义,可以得到:第n次重试的间隔时间=第一次间隔时间*乘数^(n-1),即:
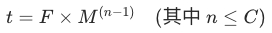
其中:

对乘数M的梯度:
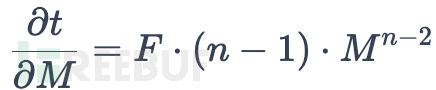
对重试次数n的梯度:
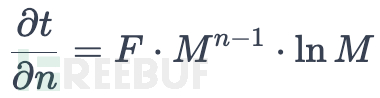
从下图可以看出,重试次数n较大时(比如8),乘数 M 的细微变化都会导致,任务的间隔时间发生剧烈变化,因此n超过8之后,M基本不可调。
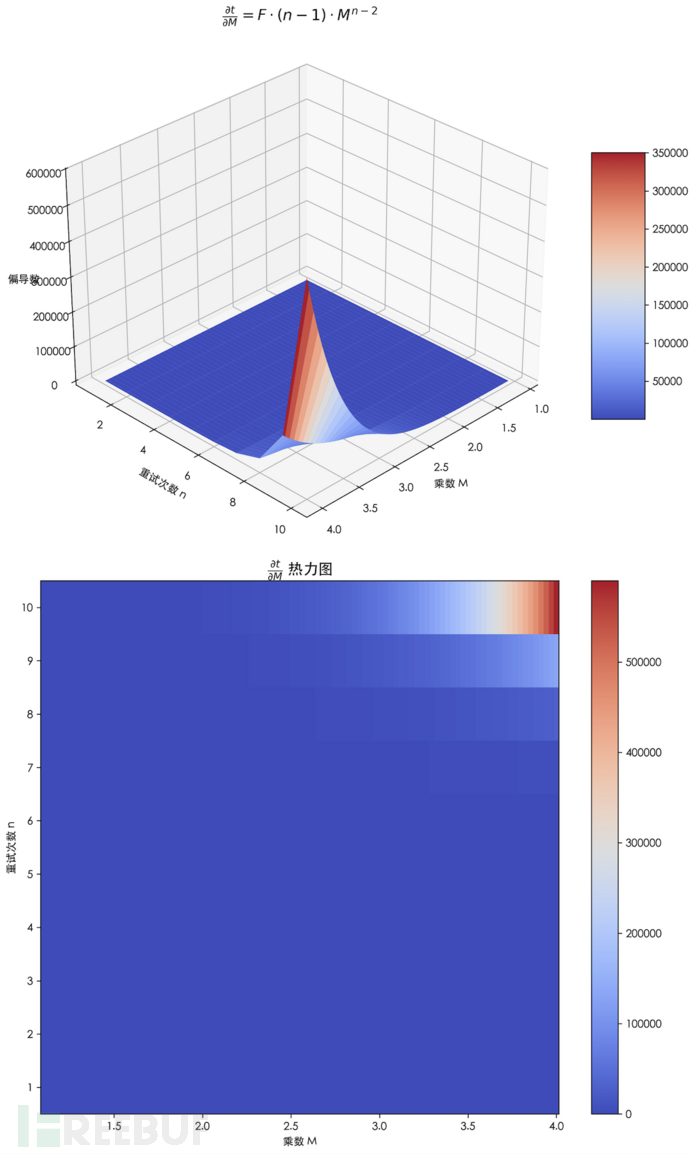
同样的,从下图可以看到,乘数M较大时(比如4),n的细微变化也会导致任务的间隔时间爆发式的增加。
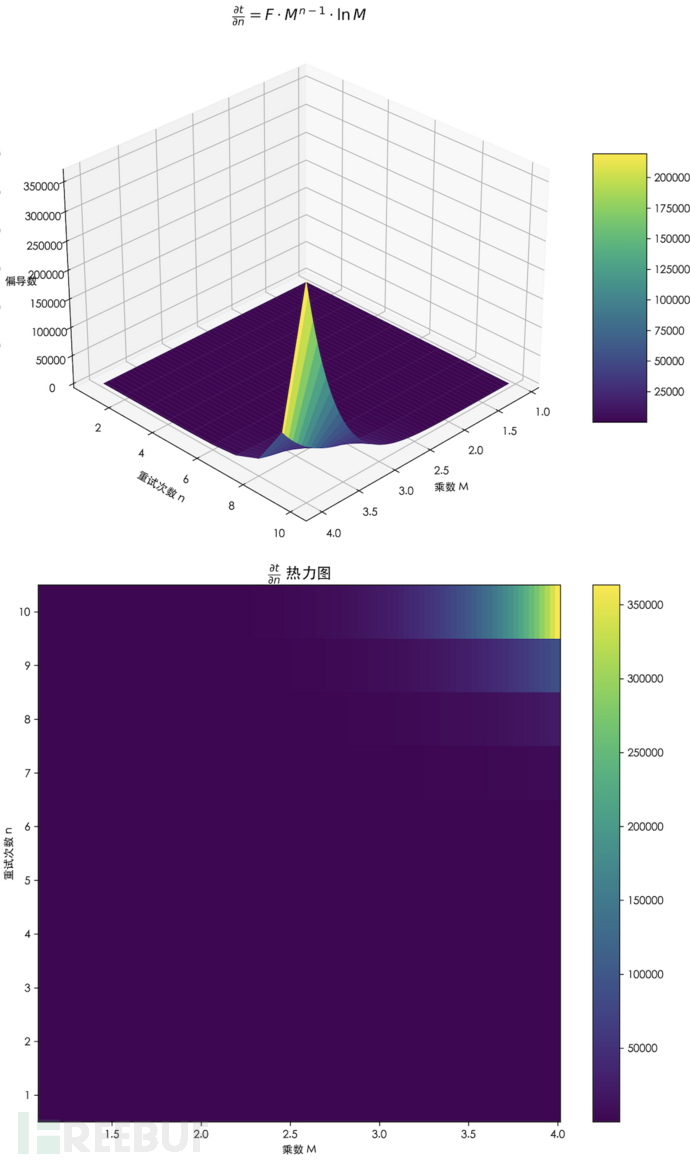
1、乘数在1.5-4 的合理性
过小乘数 (<1.5) 的问题:
当乘数 = 1.2,重试 10 次的间隔时间是:1次:1, 2次:1.2, 3次:1.44, ..., 10次:5.16,
10 次重试总间隔仅 5 倍,接近固定间隔,可能导致 "惊群效应"(大量请求同时重试)。
过大乘数 (>4) 的问题
当乘数 = 8,重试 5 次的间隔时间:1次:1, 2次:8, 3次:64, 4次:512, 5次:4096
5 次重试后间隔已超 1 小时(假设初始间隔时间是最小的1s,4096s>1小时),可能导致请求长时间等待,用户体验差。
因此,乘数 = 1.5-4 在 "退避效率" 和 "资源消耗" 间取得平衡,一般取乘数= 2 (标准指数退避)。
行业实践:AWS SDK 默认乘数 = 2,Google gRPC 重试策略推荐乘数 = 1.5-3,多数 HTTP 客户端库 (如 requests) 默认乘数 = 2。
2、最大重试次数3-10的合理性
假设单次重试成功概率为P(比如网络/服务临时故障,重试成功概率通常较高),重试 n次至少成功 1 次的概率为:

当 p=0.5,(单次重试 50% 成功概率):
n=3时,成功概率 =1−(0.5)^3=87.5%
n=5时,成功概率 =1−(0.5)^5=96.875%
n=10时,成功概率 =1−(0.5)^10≈99.9%
实际场景中,临时故障的单次成功概率远高于 50%(比如网络抖动重试成功概率可能达 80%)
若 p=0.8,n=3时成功概率已达 1−0.2^3=99.2%几乎覆盖所有临时故障。
因此,3 - 10 次重试,能以极高概率(99%+)覆盖“临时故障”场景,再增加次数对成功概率提升极有限(边际效应递减)。
因为已知的任务延迟时间的公式是:
,
n从1到C进行累加得到总耗时:
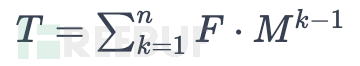
,
根据等比数列求和公式可以得到:

令 M=2(常用乘数),F=1秒(最小可能值):
n=3时,T=(2^3-1)/(2-1)=7秒
n=5时,T=(2^5-1)/(2-1)=31秒
n=10时,T=2^10-1=1023秒≈17分钟
n=13时,T=2^13-1≈2.3小时
n=15时,T=2^15-1≈9.1小时
当n超过10后,每次增加都会导致总耗时急剧增长,很容易超过业务的容忍上限(具体业务具体分析),也可能因为重试过多,导致被调用的系统压力增加,甚至造成系统崩溃。
故:3 - 10 次重试可将总耗时控制在“业务可接受范围”(几秒到十几分钟),同时避免资源过载。
行业实践:Kafka 消费者重试:默认 10 次、Redis 客户端重试:默认 5 次、Hadoop 任务重试:默认 3-5 次、RFC 建议:RFC 6582(HTTP 重试)建议:3-5 次重试。
3、最佳实践速查表
| 参数 | 短期任务(分钟级) | 中期任务(小时级) | 长期任务(天级) |
|---|---|---|---|
| 乘数 | 2 | 2 | 1.75 |
| 重试次数 | 3 - 5 | 5 - 8 | 8 - 12 |
| 初始间隔(秒) | 1 - 5 | 30 - 60 | 300 - 600 |
| 总耗时范围 | <60秒 | 5 - 10分钟 | 1 - 2小时 |
| 适用场景 | 临时网络波动 服务重启、发版 | 服务短暂过载 | 资源密集型操作 |
三、经验沉淀:异常重试机制的设计原则
通过这次实践和对行业方案的研究,我们总结出异常重试机制设计的四大核心原则:
1.动态适应性原则:重试策略应支持参数化配置,根据业务场景和系统负载动态调整重试间隔和次数,避免 “一刀切” 的重试策略对系统造成冲击。
2.幂等性保障原则:确保任务在多次重试过程中不会产生重复数据或副作用,通过唯一标识、状态机等技术手段,实现任务的幂等执行。
3.故障隔离原则:将重试逻辑与业务逻辑分离,通过消息队列、异步调度等方式,降低重试操作对主线程的影响,避免因重试失败导致系统整体崩溃。
4.可观测性原则:建立完善的监控和告警体系,实时追踪任务重试状态,在达到最大重试次数时及时发出告警,便于运维人员快速定位和解决问题。
四、结语:以技术沉淀筑牢大促防线
这次线上异常事件,犹如一面镜子,让我们清晰地看到了系统中的潜在风险,也为我们提供了一次宝贵的技术提升机会。通过对异常重试机制的深入研究和实践,我们不仅解决了当前问题,更将这些经验转化为团队的技术资产。在未来的 618 大促及其他关键业务场景中,我们将以更完善的技术方案、更严谨的设计原则,守护系统的稳定运行,为业务发展提供坚实的技术保障。
如有侵权请联系:admin#unsafe.sh