嗯,用户让我帮忙总结一下这篇文章的内容,控制在100字以内。首先,我需要快速浏览文章,抓住主要信息。 文章主要介绍快手的OpenOneRec项目,这是一个推荐系统的开源技术报告。里面提到了测评框架RecIF-Bench,还有训练数据和模型大小。看起来他们用了自回归模型来做推荐,并且有分阶段的训练策略。 然后,用户要求总结在100字以内,不需要特定的开头。我得提炼出关键点:开源项目、测评框架、数据规模、模型参数、自回归方法、分阶段训练和多任务微调。 最后,确保语言简洁明了,不超过字数限制。这样用户就能快速了解文章的核心内容了。 </think> 本文介绍了快手开源的推荐系统技术报告 OpenOneRec,包括测评框架 RecIF-Bench 和训练数据(16 万用户、9600 万交互数据),以及 1.7B 和 8B 参数的开源模型。采用自回归模型进行推荐,并通过分阶段预训练和多任务微调优化推荐性能与通用能力。 2026-1-17 00:0:0 Author: arthurchiao.art(查看原文) 阅读量:0 收藏
Published at 2026-01-17 | Last Update 2026-01-17
本文是阅读学习快手的 OpenOneRec Tech Report 时整理的一些笔记, 很多训练相关的信息已经开源,见 github.com/Kuaishou-OneRec/OpenOneRec, 包括:
- 测评框架 RecIF-Bench 和训练数据:16w 用户,96million 交互数据
- 数据处理代码、训练代码,确保可复现文中内容(非 pro 版本)
- 训练好的模型:1.7B、8B
整体框架:
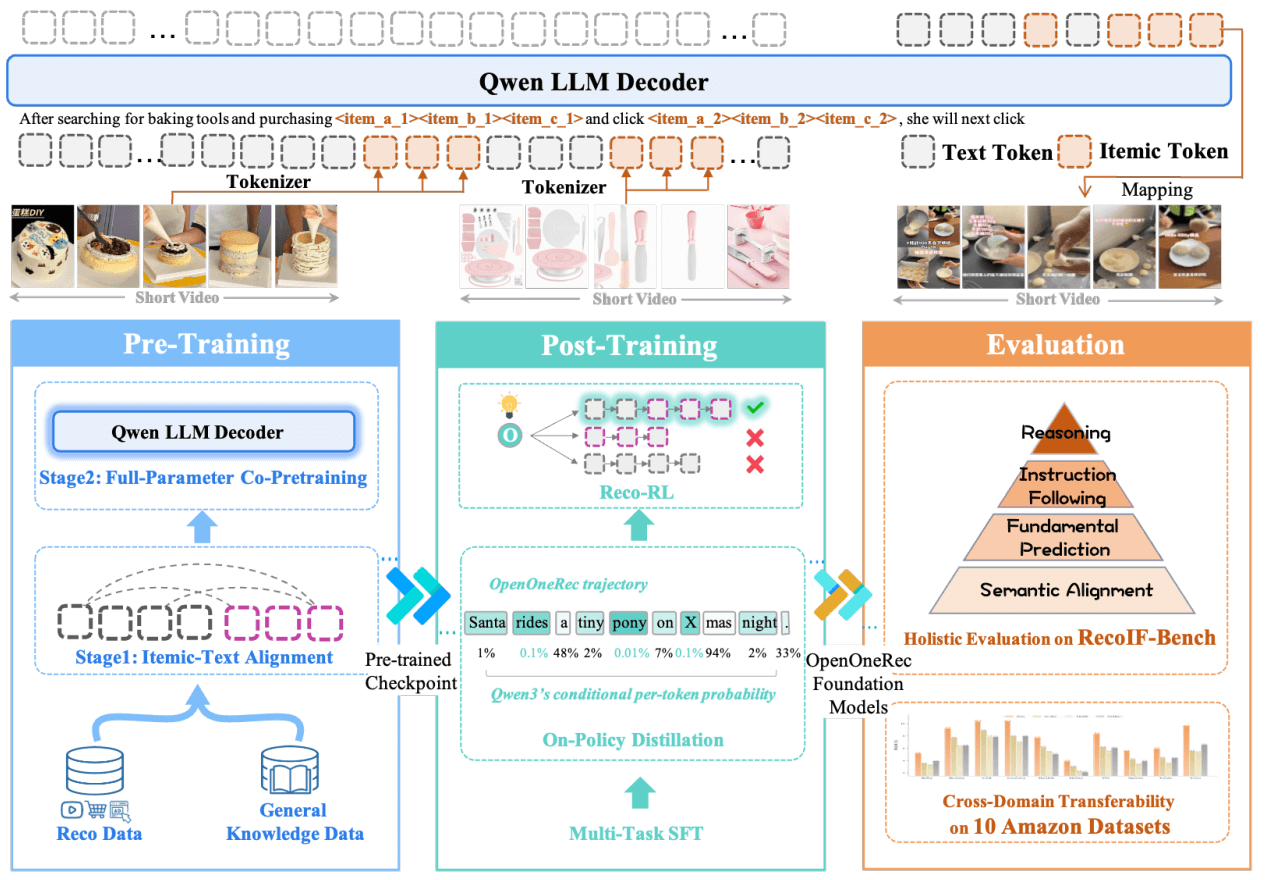
训练&评估任务:

相关文章:
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
1.1 RecIF-Bench:推荐领域的指令遵循 benchmark
本文提出了 RecIF-Bench:一个推荐领域的指令遵循测试基准 (benchmark)。
- 能评估 8 种任务类型,从基础推荐到复杂推理
- 场景包括:短视频、电商、在线广告(short-video, e-commerce, and online advertising)
1.2 缓解 SFT 带来的通用能力退化
为了缓解 SFT 带来的通用能力退化,本文引入了一个两阶段对齐策略, 能同时恢复通用能力+提升具体任务的准确率:
on-policy distillationrecommendation-oriented Reinforcement Learning(Rec-RL)
1.3 开源模型:1.7B/8B
每个尺寸的模型又分为两个版本,
- Standard 版本:基于开源数据训练
- Pro 版本:用快手的 a hundred-billion-token industrial corpus 增强
2.1. Items as Tokens: 商品的语义编码
将 Item 作为一个独立的模态(a distinct modality),采用 Itemic Tokens 方案 (Luo et al., 2025; Zhou et al., 2025a),见图 2,
Figure 2 | OneRec 整体框架。
(1) Pre-Training: 通过 Itemic-Text Alignment 和推荐领域+通用领域数据的联合预训练,使模型能理解推荐领域的业务语义。
(2) Post-Training: 通过 SFT 解锁多种下游任务能力,
以及通过交替进行通用蒸馏和强化学习来平衡模型的通用推理能力和推荐能力。
(3) Evaluation: 基于 RecIF-Bench,以及这 Amazon 数据集上验证跨领域转移能力。
采用 RQ-Kmeans (Luo et al., 2025),将 item metadata 的语义 embedding 离散化为 discrete codes。
- 将 item semantics 压缩为了短的、固定长度的序列,在保留 collaborative structure 的同时使得长上下文建模更加高效;
- 这些 tokens 自带的层级特性(hierarchical nature of these tokens)确保了语义类似的商品,共享相同的 prefixes, 使得模型能基于 token 相似性转移知识,类似于自然语言 tokens 中的语义关系编码。
2.2. Recommendation as Auto-regressive Models:用自回归模型做推荐
- 扩展词表:将 item tokens 添加到模型原有的 vocabulary: V = V𝑡𝑒𝑥𝑡 ∪ V𝑖𝑡𝑒𝑚. 这种方式使我们能将用户的交互历史作为 text+item 的一个长上下文序列,而不是作为一个特殊的数据结构,跟基座语言模型还是一致的。
- 训练目标:
Next-Token Prediction - 训练任务:ranging from prediction (e.g., retrieval) to reasoning (e.g., explanation)
3.1 数据集构建
数据集切分策略:按用户维度 80:20 切分
基于用户维度切分训练集和测试集。20w 用户,随机拆分,
- 80% 训练
- 20% 测试
3.2 评估任务:4 层,从对齐到推理
RecIF-Bench 将 8 类任务分为了 4 层。
Table 2 | RecIF-Bench 任务术语:8 类任务分为 4 层,描述了它们的 input/output 格式和评估重点。
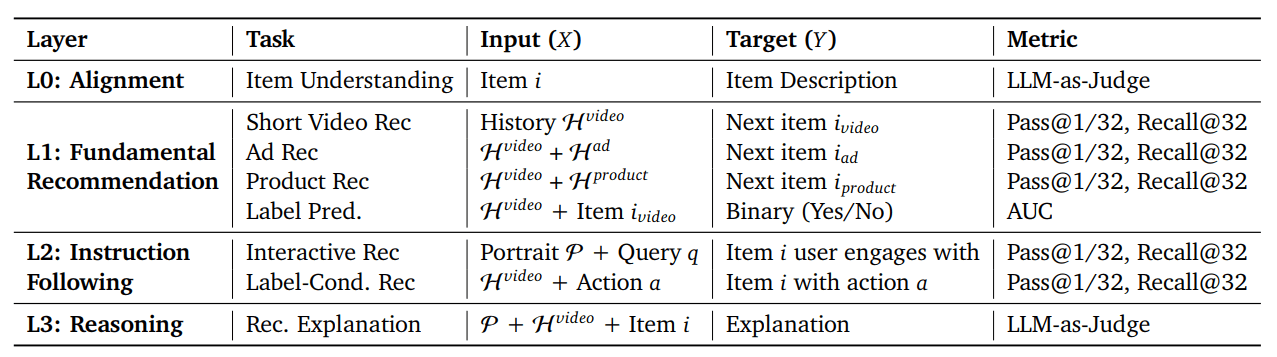
训练数据样例:
Figure 4 | RecIF-Bench 任务举例。We organize 8 tasks across 4 capability layers, specifying the instruction, context, and target.
3.2.1. Layer 0: 语义对齐能力
评估模型是否已经抹平 itemic tokens 和 natural language 之间的差异,这是后续所有任务的基础。
- 训练任务:
- 继续预训练(CPT):
Item 描述 -> Item Token
- 继续预训练(CPT):
- 评估任务
Item Understanding:Item Token -> Item textual metadata(e.g., title, caption)
3.2.2. Layer 1: 基础推荐能力
评估模型捕捉用户偏好的能力,预测用户-货品交互行为,
- Short Video Recommendation.
- Ad / Product Recommendation (Cross-Domain).
- Label Prediction. Given the user’s history H 𝑣𝑖𝑑𝑒𝑜 and a candidate item 𝑖, the model predicts whether the user will engage (e.g., effective view) with a binary
Yes/Noresponse.
3.2.3. Layer 2: 指令遵循能力
这一层评估模型是否能将预测能力适应到自然语言指令上,也就是自然语言推荐任务的指令遵循能力,这是基于 LLM 的推荐系统与传统推荐系统的核心不同。
- 交互式推荐. Given the user portrait P and a natural language query 𝑞
- 输入:
- 用户画像 P
- 自然语言 query 𝑞(例如,“放松的视频”)
- 输出:
- 用户可能会积极互动(点击、点赞、收藏等)的物品
- 输入:
- 条件推荐:更细粒度的行为建模
- 输入:
- 用户历史行为 H𝑣𝑖𝑑𝑒𝑜
- 目标行为 label 𝑎(例如,点赞、分享等)
- 输出:
- 用户在给定目标行为下会积极互动(点击、点赞、收藏等)的物品
- 输入:
3.2.4. Layer 3: 推理能力(推荐理由)
输入:
- 用户画像 P
- 用户历史行为 H𝑣𝑖𝑑𝑒𝑜
- 推荐物品 𝑠
输出:一段自然语言的推荐理由,解释为什么推荐这个商品。
Ground Truth for L3: Since reasoning tasks lack natural ground truth, we use Gemini-2.5-Pro with full metadata access to
generate high-quality reference outputs.
3.3. 评估指标
推荐指标:Pass@K, Recall@K
对推荐任务 (Layer 1 & 2),使用如下评估指标:
- Pass@1/Pass@32. Pass@K measures whether the ground truth item appears in the top-K generated candidates
- Recall@32. Recall@K measures the proportion of relevant items retrieved.
文本生成指标:LLM-as-Judge
对文本生成任务 (Layer 0 & 3), we employ LLM-as-Judge, prompting an independent LLM to rate the generated text on dimensions such as accuracy and coherence. 详见 Appendix B.1
4.1 Item Tokenization
- 三层量化,每层的 codebook size of 8192
- Each item 𝑖 is thus mapped to a tuple of hierarchical codes 𝑆𝑖 = (𝑐1, 𝑐2, 𝑐3), which is then flattened into a token sequence wrapped by special tokens:
<|item_begin|><item_a_5028><item_b_6733><item_c_2559><|item_end|>
4.1.1 Rec-domain 训练数据
为了增强模型对 item 的推荐能力,对 item metadata 数据分为了三类:
Itemic Dense Caption Data:基础的物品语义数据- 训练任务:给定 itemic tokens,让模型生成 corresponding natural-language caption
- 在商品的 SID 和文本描述之间建立语义映射。
-
Sequential User Behavior Data:基础推荐能力的核心训练语料- 内容包括用户的观看、点赞、分享等行为。通过训练模型在长期序列中进行 next-item prediction,我们使其能够内化基础的协同过滤信号和 temporal patterns。
- 让模型具备根据 historical behavioral trajectory 预测用户 future interest 的能力.
-
Interleaved User Persona Grounding Data:构建量化空间的 deep semantic grounding- 基于离散的物品表示和异构的用户元数据,构建了叙事风格的用户画像 P𝑢
- 静态属性(例如年龄、性别)
- 主动搜索行为(例如最近搜索的 query)
- 交互序列(表示为物品 tokens 序列)
- 总结的用户兴趣(例如内容创作历史、关注的创作者类型、消费偏好)
- 这部分数据集严格按用户维度切分,避免数据泄露。
- 主要训练语料包括约 16w 用户、1300w 物品描述和对应的交互行为。
- 对于 OneRec-Pro,扩展到约 2000w 用户和 9800w 物品描述。
- 训练样本见 Appendix B.3。
- 基于离散的物品表示和异构的用户元数据,构建了叙事风格的用户画像 P𝑢
4.1.2. General-domain 训练数据
拿推荐领域的数据对模型进行训练之后,基座模型的数据分布会跟原来有很大的偏移,导致 catastrophic forgetting。
通过增加通用领域的训练数据来缓解这个问题:
- 多语言 (including Chinese, English, and others)
- 多领域,主要是 Coding, STEM(Science, Technology, Engineering, and Mathematics) and Medical.
- 强推理数据优先:Crucially, to keep and further enhance the model’s reasoning capability, we prioritize reasoning-intensive data, including mathematical derivations, logical puzzles, and codecentric corpora.
数据集下载:
- https://github.com/Kuaishou-OneRec/OpenOneRec
- https://huggingface.co/datasets
数据去重算法:MinHash algorithm (Broder, 1997)
4.2. 训练配方
we develop two model variants based on the scale of the training corpus:
- OneRec trained exclusively on our publicly released dataset, encompassing 33B tokens across 41.3 million samples, thereby establishing a reproducible baseline for the community.
- OneRec-Pro. leverages an extensive in-house corpus with broader user coverage, totaling 130B tokens and 179.1 million samples to achieve enhanced robustness.
基座都是 Qwen3,数据配比和 token 预算见 Appendix B.4
Stage 1: Itemic-Text Alignment(冻结大部分参数)
建立 itemic tokens and text tokens space 之间的初步对齐。
- 对 Qwen3 的 tokenizer 进行扩展,追加 special item tokens
- 这个阶段,只有 item tokens 相关的 embedding parameters 是可训练的,其他模型参数都冻结。
Note that in Qwen3, smaller models (e.g., 0.6B, 1.7B, 4B) employ tied embeddings where the embedding and output projection layers share parameters, while larger models (e.g., 8B and above) have independent output projection parameters. For larger models, the output projection parameters corresponding to itemic tokens are also trainable, ensuring proper alignment in the output space.
Stage 2: Full-Parameter Co-Pretraining(全参继续预训练)
全参预训练(full-parameter pre-training),给模型注入推荐领域的知识。
- 目标是让模型在保留 Qwen3 原生的世界知识的同时,能捕捉用户行为、商品语言和用户-商品交互中的复杂 pattern。
- 为了防止 catastrophic forgetting,这个阶段会加入通用领域的知识数据。
Training Recipe
We use the AdamW optimizer with 𝛽1 = 0.9, 𝛽2 = 0.95, and weight decay of 0.1. The learning rate follows a cosine decay schedule with a linear warmup phase, where the peak learning rate is set to 1 × 10-3 for Stage 1 and 1 × 10-4 for Stage 2, and the minimum learning rate is set to 1 × 10-4 and 2 × 10-5. The warmup duration spans the first 10% of training steps. To accommodate the long sequential nature of user behavior data, we set the maximum context length to 32K tokens, enabling the model to process extended user interaction histories and complex recommendation scenarios. This extended context window is crucial for capturing long-term user preferences and understanding intricate patterns in sequential recommendation tasks.
Figure 6 | Post-training pipeline of the OneRec series models
预训练之后,能理解商品了,但指令遵循能力、推理能力和通用能力都有退化,也还不能处理复杂的推荐任务。
通过三个阶段的 post-training 来解决以上问题:
- Multi-task Supervised Fine-tuning:针对下游任务的指令遵循
- On-policy Distillation:恢复通用能力
- Reinforcement Learning for Recommendation:在推荐任务上的推理能力强化
5.1. 恢复通用 instruct-following & thinking 能力:多任务 SFT
这个阶段的目的是恢复和增强模型的基础指令遵循和推理能力,包括在通用领域和推荐领域。
详见 Appendix B.5.
发现:通用能力的恢复也会增强后面的推荐任务的推理能力。
5.2. 恢复通用 reasoning 能力:On-policy Distillation
上一个阶段恢复了指令遵循和 thinking 的基础能力,但我们注意到通用领域的 reasoning 能力还是丢失了不少(a persistent capability gap in general-domain reasoning), 可能是由于 distributional shift and the inherent sensitivity of RL-initialized backbones。 为了解决这个问题,我们设计了一个用于通用任务的 on-policy distillation strategy。
Off-Policy vs. On-Policy Distillation
- off-policy distillation:student model 在一个静态、预先生成的数据集上学习 teacher 的分布;
- on-policy distillation (Agarwal et al., 2024) :student model 生成自己的轨迹,teacher 模型进行评估和反馈。
实现
- 教师模型:使用同等规模的 Qwen3 原始模型作为 teacher
- 生成了
200Kgeneral-domain questions from the SFT dataset
效果验证
从论文表 10-11 可见:
- Stage 1(SFT)→ Stage 2(在线蒸馏):通用能力显著恢复
- MMLU-Pro:53.07% → 54.54%
- IFEVAL:61.74% → 76.53%
- 有效解决了指令漂移问题(如忽略/no_think 标签乱生成 CoT)
- 在恢复通用能力的同时,保持了推荐任务性能(见表 12)
5.3. 针对推荐任务的强化学习:GRPO
- On-policy distillation 恢复了模型的通用 reasoning 能力, 但它没有直接优化排序指标 (e.g., Recall or NDCG), 后者定义的是推荐质量。
- SFT 主要关注最大化事实序列的概率(the likelihood of ground-truth sequences), 经常会遇到曝光偏差(exposure bias)问题,无法区分 “near-misses” and irrelevant recommendations。
为了解决这些问题,引入了 Recommendationoriented Reinforcement Learning (Rec-RL).
- 使用 Group Relative Policy Optimization (GRPO) Shao et al. (2024) .
- traditional Actor-Critic algorithms (e.g., PPO) 需要一个独立的 critic model 来 estimate state values, GRPO computes the advantage of a response relative to a group of sampled trajectories for the same prompt. 显著减少了计算开销,同时保持稳定性。
Rule-based Recommendation Reward.
为了将模型和 ranking accuracy 对齐,设计了一个稀疏的、基于规则的奖励函数,关注在”Hit” events.。
7.1 Tokenizer 的可迁移性
尽管我们的实验证实了一个不错的基座推荐模型能显著提升下游性能,但这些增益的幅度目前仍受限于 tokenizer 的可迁移性。
A promising avenue for future work lies in maximizing the reuse of foundation model priors while simultaneously ensuring high-quality item indexing (code quality) for downstream tasks.
7.2 最优数据配比
维持模型的通用智能与推理能力需要在训练过程中混合大量通用领域文本。 研究最优的数据配比并提升数据利用效率,是平衡领域特定精度与通用能力的迫切挑战。
7.3 思维链推理目前仅在有限场景中带来改进
我们观察到思维链推理目前仅在有限场景中带来改进。 这凸显了对 test-time scaling 策略进行更严格探索的必要性,以在多样化的推荐场景中实现一致的推理增益。
B.3. Pre-training 数据 sample(推荐领域)
B.3.1. 物品描述数据(Itemic Dense Caption Data)
视频<|item_begin|><item_a_5028><item_b_6733><item_c_2559><|item_end|> 展示了以下内容:视频内容聚焦在庆祝冬至这一重要节日的习俗,特别是享受饺子与汤圆等美食。
视频表达了冬至节气的特色意义,以及人们对新一年开始的寓意。内容上,显现出浓浓的节日气氛与家庭温暖,可能会触动那些寻求传统节日体验和家的感觉的观众。
视频还可能激发观众对中华传统文化的兴趣,以及对家人团聚时的美好记忆。通过美食与节日的结合,观众可感受到温馨和幸福,为冬至节日的到来营造了欢乐与期盼。
B.3.2. 顺序用户行为数据(Sequential User Behavior Data)
用户的曝光序列为<|item_begin|><s_a_1023><s_b_5426><s_c_6422><|item_end|>, <|item_begin|><s_a_3168><s_b_7950><s_c_4134><|item_end|>,......;
其中长播列表是<|item_begin|><s_a_4988><s_b_7436><s_c_2477><|item_end|>, <|item_begin|><s_a_5087><s_b_7888><s_c_4759><|item_end|>,......;
点赞列表是<|item_begin|><s_a_3168><s_b_7950><s_c_4134><|item_end|>, <|item_begin|><s_a_250><s_b_2310><s_c_4925><|item_end|>,......
B.3.3. 用户综合事实数据(点赞、收藏、评论 … )
Interleaved User Persona Grounding Data
平台上有一名用户,她创作内容涵盖:8 个其他,1 个美食,1 个数码,1 个明星娱乐。
她近期的搜索记录包括:怎么拍游戏视频、黑白头像可爱、......。
她近期的购买记录包括:商品<|item_begin|><item_a_6133><item_b_5060><item_c_5431><|item_end|>,具体类型为【女装-裤子-休闲裤】,花费 290 元。
她近期在视频<|item_begin|><item_a_3316><item_b_7440><item_c_2022><|item_end|>下评论了"这个短剧叫什么名字啊";
在视频<|item_begin|><item_a_7822><item_b_1648><item_c_5756><|item_end|>下评论了"嘻嘻嘻,真的吗?我也喜欢玩蛋仔派对,早就关注你了";......。
她点赞了视频<|item_begin|><item_a_5743><item_b_930><item_c_1231><|item_end|>......;
收藏了视频<|item_begin|><item_a_468><item_b_8186><item_c_5877><|item_end|>......;
分享了视频......。她关注的博主类型有:【其他】占 47.58%,【颜值】占 16.52%,【明星娱乐】占 8.37%,......。
她近期观看的直播类型包括:【闲聊互动-热闹闲聊】分类下的直播点赞了 6 次,评论了 59 次;......
她过去 30 天观看时间最长的 1 种短剧类型分别是:[解密_悬疑]看了 30.0 分钟
B.4. Pre-training 数据配比和 Token Budgets
Table 13 | Data mixture for Pre-training. The table presents the distribution across general domains and recommendation domains, showing the sampling weight of each dataset and the subtotal ratio for each category.
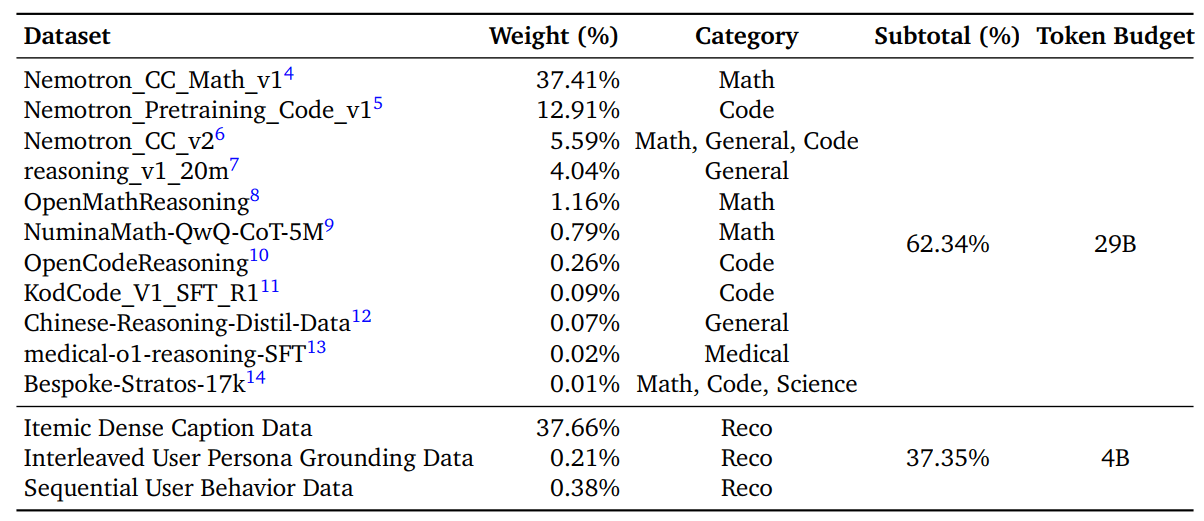
Table 14 | Data Composition and Token Budgets for Pre-training Stages. This table illustrates the training configurations for the Open and Pro model variants across different stages, specifying the parameter focus, data domain distribution, and allocated token budgets.

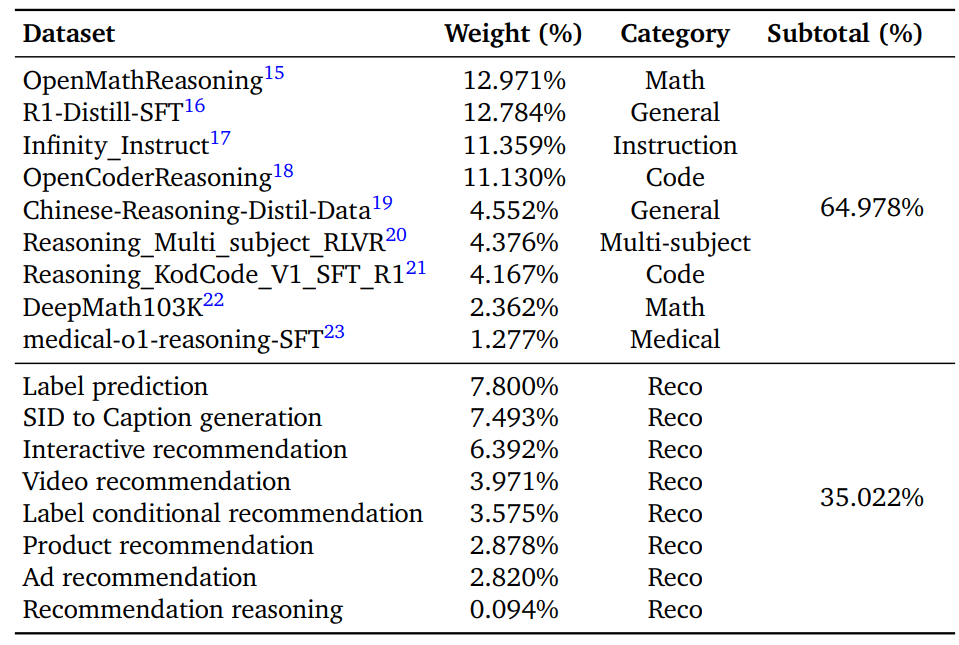
B.5. SFT 数据配比和 Token Budgets
Table 15 | Data Mixture for Multi-task SFT. The table presents the distribution across reasoning and recommendation domains, showing the sampling weight of each dataset and the subtotal ratio for each category.
![]()
![]()
如有侵权请联系:admin#unsafe.sh