
cquery最近改动
- 原作者创建了organization,我据此把几个插件分离了:emacs-cquery和vscode-cquery,等候吉日再来一次
git filter-branch --index-filter减小主repo的体积 - 检索Doxygen注释标记,及可选的普通(行注释
//块注释/**/)。在initialization options里配置"enableComments": 2, - cache文件(
cacheDirectory目录下的文件)原来为JSON,现在支持序列化成MessagePack,请在initialization options里配置**“cacheFormat”: “msgpack”,` - 感谢bennyyip添加了archlinuxcn/cquery-git,Arch Linux用户要体验cquery更加方便了
- 光标处符号的类型信息改进了,根据romix的提议,对于函数,找出函数类型和返回值类型字串形式第一个不同的位置,多半是插入函数名的位置。但参数名插入仍然困难,都怪C的inside-out类型表示语法
参见wiki中的Initialization options,邀请大家多编辑wiki为后人提供方便。
Unified Symbol Resolution优化
Clang Index使用Unified Symbol Resolution标识程序中的function/variable/type等。cache文件中一个函数可能存储为这样:
|
|
对于C++程序,嵌套几个namespace、class后USR就会很长,占用不少空间。原作者提起clangd用了SHA-1 (std::array<uint8_t, 20>)来省空间,我感觉160-bit太浪费了,想找个64-bit non-cryptographic hash,经quininer推荐选取了SipHash 64-bit,能用uint64_t代替原来的std::string usr,省空间。
悲伤
|
|
rapidjson也能序列化int64_t/uint64_t,而不会因为使用了double导致精度丢失到53-bit。JavaScript的Number类型真是一个陷阱。
用hash做主键,在这里非常合适。因为假使两个键冲突,观察到的后果也就是两个变量/函数(他们的数量远多于类型)合并了,所有功能都能照常使用。不会有blockchain hash冲突的灾难性后果。
在LLVM上观察cache空间占用,stat -c %s .vscode/cquery_cached_index/**/*.mpack | awk '{s+=$1}END{print s}',从720055341字节降到265784325字节。
根据khng300索引Linux kernel的结果:
|
|
层级diff
因为性能问题,cquery当前只在用户保存文档时调用libclang重新索引用到当前文件的translation units,对于.cc/.cpp通常只会编译一个translation unit。打开文件后进行修改,文件的buffer版本就和索引时版本不同了。类型/函数/变量的交叉引用信息仍为索引时的版本,怎么对应到buffer版本呢?index版本和buffer版本的映射是双向的:
- buffer到index。用户在buffer某处使用definition/references等功能,需要把buffer光标位置映射到index版本,查找符号信息
- index到buffer。对于hover/references等功能,找到一个符号所有出现的位置后,需要把index映射到buffer版本,显示出来
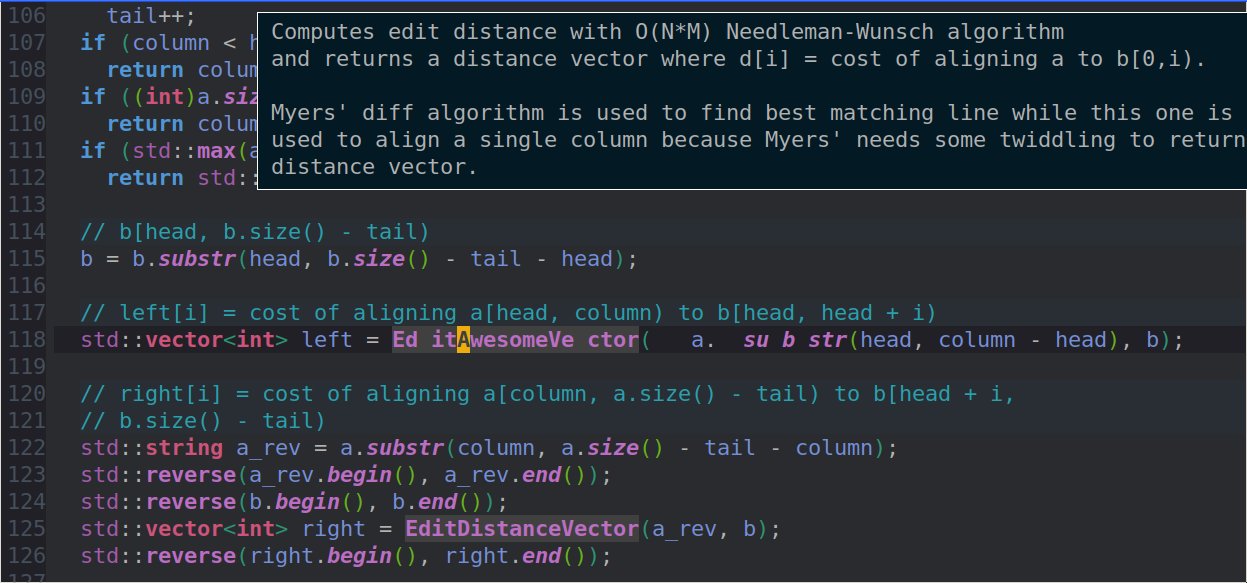
对于一个编辑中的文件,很可能无法编译通过,甚至难以保证能语法分析成功,我今天加了一些文档diff算法,启发式地处理这个问题。以按buffer 光标行列找index对应行列为例。
- 先用Paul Heckel’s diff algorithm找出index与buffer的映射关系,实质上把文档分块了
- 对于一个行文本,用Eugene Wimberly Myers’ O(ND) diff algorithm找块间最相似的行
- 对于行文本和列位置,在找到的最相似的行中找最合适的列
这样就把index的一个行列位置转换到buffer的行列位置。
Paul Heckel’s diff algorithm
大意是如果一个行在index中只出现一次,在buffer中也只出现一次,可以看作一个锚点,认为buffer中出现的行号映射到index中出现的行号。
之后处理锚点邻接的行,如果在index和buffer中相同,那么也认为buffer中出现的行号到index出现的行号有一个映射关系。据此把所有邻接行都标记上映射关系。对于这种类型的flood fill,只需要从上到下扫描和从下到上扫描两遍文档。
块间找最相似的行
如果询问的buffer行i恰好有个到index的Paul Heckel映射关系buffer_to_index[i],直接返回。否则就上下找到最接近的含有映射关系的行up,down,在映射后的区间[buffer_to_index[up],buffer_to_index[down]]内用edit distance找和buffer[i]最相似的行j。
把buffer第i行第c列映射到index第j行最优列
再用一次edit distance,在index[j]中找一个列w,使得align(buffer_line[0:c], index_line[0:w]) + align(buffer_line[c:], index_line[w:])最小。可以认为index行的第w列即对应buffer行的第c列。这实际上是Hirschberg’s algorithm的一步。
取到最小值的可能有多个列,我用了一个简单的方法。一般询问是关于buffer一个区间对应index中的哪一个区间。对于区间起点,我希望映射后的位置尽可能靠后;对于区间终点,希望映射后的位置尽可能靠前。
实现了以上buffer到index的双向映射后,可以用index版本给正在编辑中的buffer版本提供信息了。效果见下图,编辑了光标处的函数名,textDocument/documentHighlight依然可用:
其他
Emacs用户请关注这些repo和issue:
- emacs-cquery,添加到Melpa
- lsp-mode
- lsp-ui
- 对于spacemacs用户,请关注我呼吁支持lsp、添加cquery到c-c++ layer的issue
Vim用户还没有很好看的UI,需要人拯救。
另外,把字符单位从UTF-16换成Unicode codepoint,Microsoft和JavaScript受害者真是对UCS-2/UTF-16孜孜不倦。感谢Riatre的分析。这个问题修不好,我们在Emacs或VSCode里使用emoji会有很大阻碍。
cquery中Language Server Protocol中物件的序列化仍挺麻烦的。TypeScript中interface可以继承,我也在Emacs lsp-mode里看到了有些TextDocumentIdentifier带有子类VersionedTextDocumentIdentifier的版本字段。这个在C++里序列化就不方便了。
如果要进一步优化启动时cache加载速度,需要考虑lmdb之类存储。
https://microsoft.github.io/language-server-protocol/specification#versionedtextdocumentidentifier
interface VersionedTextDocumentIdentifier extends TextDocumentIdentifier