Every time your favorite app crashes or a website goes down, there's usually someone franticall 2025-9-1 14:53:48 Author: securityboulevard.com(查看原文) 阅读量:0 收藏
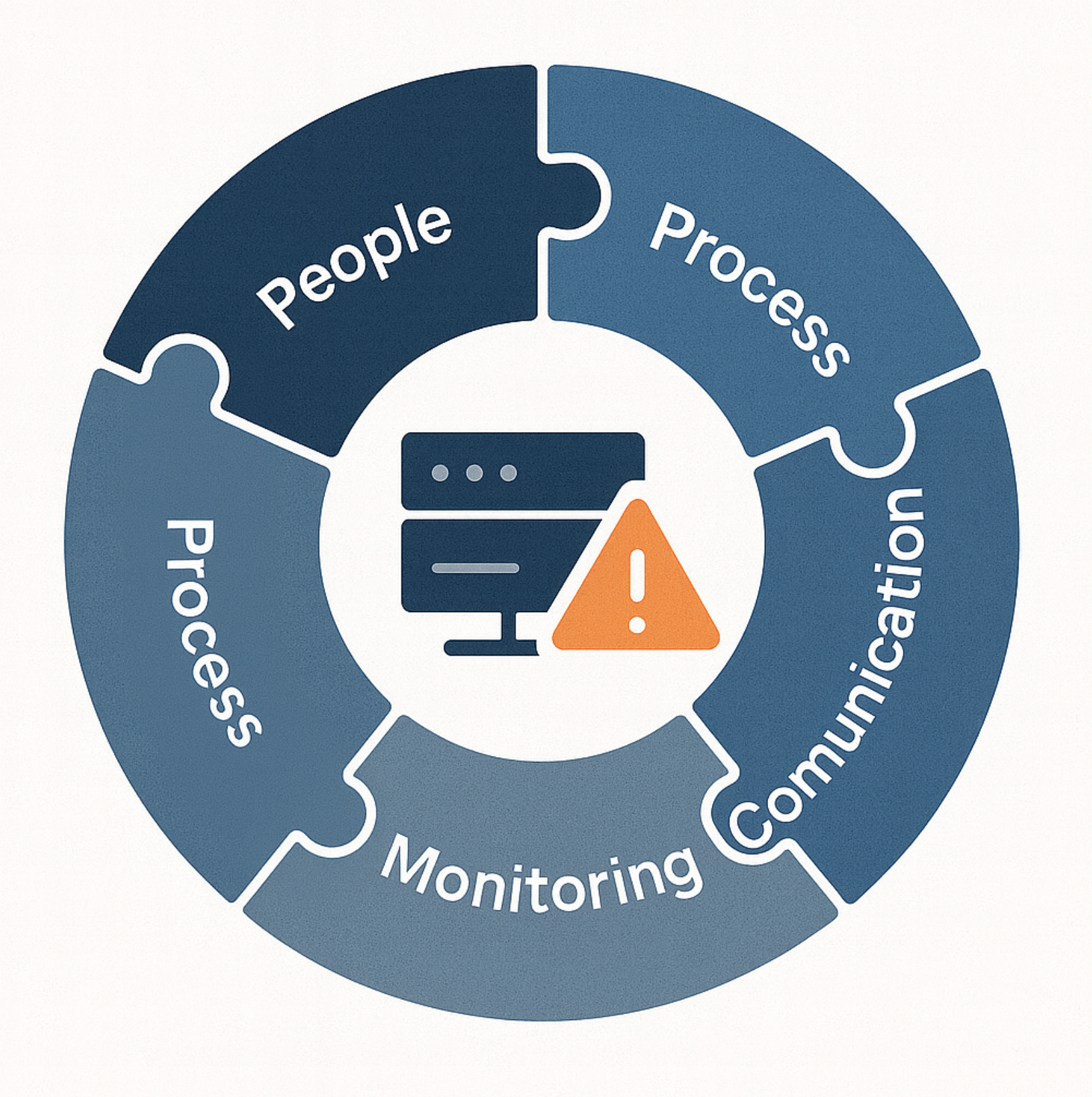
Every time your favorite app crashes or a website goes down, there's usually someone frantically typing away trying to figure out what went wrong. After dealing with countless incidents across different companies, I've noticed the same patterns keep showing up.
It's tempting to blame the technology when things break – "the server crashed" or "there was a bug in the code." But here's what I've learned: incidents rarely happen because of just one thing going wrong.

The Real Culprits Behind Most Incidents
People: We're Only Human After All
Let's be honest – humans make mistakes. It's not about being careless or incompetent, it's just part of being human.
I've seen experienced engineers accidentally delete the wrong database table at 2 AM during a maintenance window. Why? They were tired, working odd hours, and muscle memory kicked in. The person wasn't bad at their job – they were just human.
Other people-related factors that cause incidents:
- Lack of training: New team members don't know the systems well enough yet
- Communication gaps: Bob thought Alice was handling the deployment, Alice thought Bob was
- Time pressure: When deadlines are tight, shortcuts get taken
- Knowledge hoarding: Only one person knows how the legacy system works, and they're on vacation
The solution isn't to replace humans with robots (yet). It's about building systems that account for human nature.
Process Problems: When "How We Do Things" Falls Apart
Many incidents happen because there wasn't a clear process – or there was one, but nobody followed it.
Take deployment processes. I've seen companies where pushing code to production involves:
- Developer makes changes
- Developer tests locally (maybe)
- Developer pushes to production
- Hope nothing breaks
This isn't really a process – it's organized chaos waiting to become an incident.
Good processes include:
- Clear step-by-step procedures for common tasks
- Review requirements (code reviews, security checks)
- Testing phases before production
- Rollback plans when things go wrong
- Documentation that actually gets updated
But here's the catch – processes only work if people actually use them. And sometimes the process itself is the problem, like when it's so complicated that everyone finds ways around it.
Technology: When the Machines Rebel
Yes, technology fails too. Servers crash, networks go down, software has bugs. But technology failures are often symptoms of deeper issues.
Common technology-related incident causes:
- Unhandled edge cases: The code works fine until someone enters a 50-character name in a field that only accepts 20
- Resource limits: The system works great with 100 users but falls over at 1,000
- Dependencies: Your app is fine, but the payment processor you rely on is having issues
- Configuration errors: Someone changed a setting and forgot to update the backup system
- Technical debt: Old code that nobody wants to touch finally breaks
The tricky part about technology incidents is they often reveal problems that have been building up for months or years. That server that finally crashed? It's been running at 95% capacity for six months.
Communication Breakdown: When Nobody Knows What's Happening
Poor communication causes more incidents than most people realize. Not just during the incident itself, but in the days and weeks leading up to it.
Here's a typical scenario: The marketing team schedules a big campaign launch. They expect 10x normal traffic. The infrastructure team never gets told about this. The servers can't handle the load. Everything crashes right when the campaign goes live.
Communication issues that lead to incidents:
- Teams working in silos without sharing information
- Assumptions about what other people know
- Important information buried in long email chains
- No clear ownership of critical systems
- Changes made without notifying affected teams
I've noticed that the best companies have really boring meetings where people just talk about what they're working on. It sounds mundane, but it prevents a lot of fires.
Monitoring Gaps: Flying Blind
You can't fix what you don't know is broken. Many incidents happen because nobody realized there was a problem until customers started complaining.
Monitoring challenges include:
- Alert fatigue: So many alerts that the important ones get ignored
- Blind spots: Critical systems that aren't monitored at all
- Delayed detection: Finding out about problems hours after they started
- Wrong metrics: Monitoring CPU usage but not response times
- Dashboard overload: Lots of pretty charts that nobody actually looks at
Good monitoring tells you about problems before they become incidents. Great monitoring helps you understand why the problem happened in the first place.
The Perfect Storm Effect
Most serious incidents happen when multiple things go wrong at the same time. Here's a real example I witnessed:
- A developer pushed code with a memory leak (technology issue)
- The code review process was skipped due to time pressure (process failure)
- The monitoring system didn't catch it because the alert thresholds were set wrong (monitoring gap)
- When servers started crashing, the on-call engineer's phone was on silent (people/communication issue)
- By the time anyone noticed, it was peak business hours and customers were angry
Any one of these issues alone might have been manageable. Together, they created a major incident that took hours to resolve.
What Actually Prevents Incidents
After dealing with this stuff for years, here's what I've seen work:
Build empathy for human limitations. Create systems that make it hard to make mistakes. Use confirmation prompts for dangerous actions. Build in delays for irreversible changes.
Make processes simple and obvious. If your process requires a PhD to understand, people will ignore it. Good processes feel natural to follow.
Assume technology will fail. Plan for failure from the beginning. Use redundancy, implement circuit breakers, design for graceful degradation.
Over-communicate rather than under-communicate. Share information widely. Make it easy for teams to know what others are working on.
Monitor what matters and act on what you monitor. Don't just collect data – use it to make decisions.
The Real Secret
Here's what I've learned after years of post-incident reviews:
The companies with the fewest incidents aren't necessarily the ones with the best technology. They're the ones with the best culture.
They've created environments where:
- People feel safe reporting problems early
- Mistakes are learning opportunities, not blame sessions
- Processes evolve based on real experience
- Teams work together instead of throwing problems over the fence
- Everyone understands that preventing incidents is everyone's job
Incidents will always happen. The goal isn't to eliminate them completely – it's to learn from them and get better at preventing the next one. And most importantly, create systems that fail gracefully when things inevitably go wrong.
Because they will go wrong. The question is whether you're ready for it.
*** This is a Security Bloggers Network syndicated blog from Deepak Gupta | AI & Cybersecurity Innovation Leader | Founder's Journey from Code to Scale authored by Deepak Gupta - Tech Entrepreneur, Cybersecurity Author. Read the original post at: https://guptadeepak.com/why-incidents-keep-happening-and-its-usually-not-what-you-think/
如有侵权请联系:admin#unsafe.sh