文章探讨了内存作为AI和计算的关键瓶颈,并介绍了MIT Ryan Williams的一项突破性成果:任何时间t的计算可用约√t的空间模拟。作者将这一数学方法与古代记忆系统(如I-Ching的六十四卦)结合,提出了一种新的内存调度模型,并开发了一个原型工具以优化内存使用。 2025-7-6 17:7:41 Author: hackernoon.com(查看原文) 阅读量:16 收藏
Memory is the real bottleneck in AI and computing. Whether you're training large language models, running complex simulations, or orchestrating microservices, it's often RAM, not CPU, that dictates the true scale of what you can achieve.
So, what if you could dramatically shrink your active memory footprint? What if you could do "exponentially less remembering" while still crunching massive datasets? MIT's Ryan Williams just proved this is possible, solving a 50-year-old puzzle in computer science by demonstrating that any computation running in time t can be simulated with roughly √t space.
But here’s what really fascinated me: many indigenous cultures have been doing something remarkably similar for millennia, compressing vast knowledge systems into human memory using song, dance, and story. I touched a bit on this in my other Hackernoon article Artificial Cultural Intelligence.
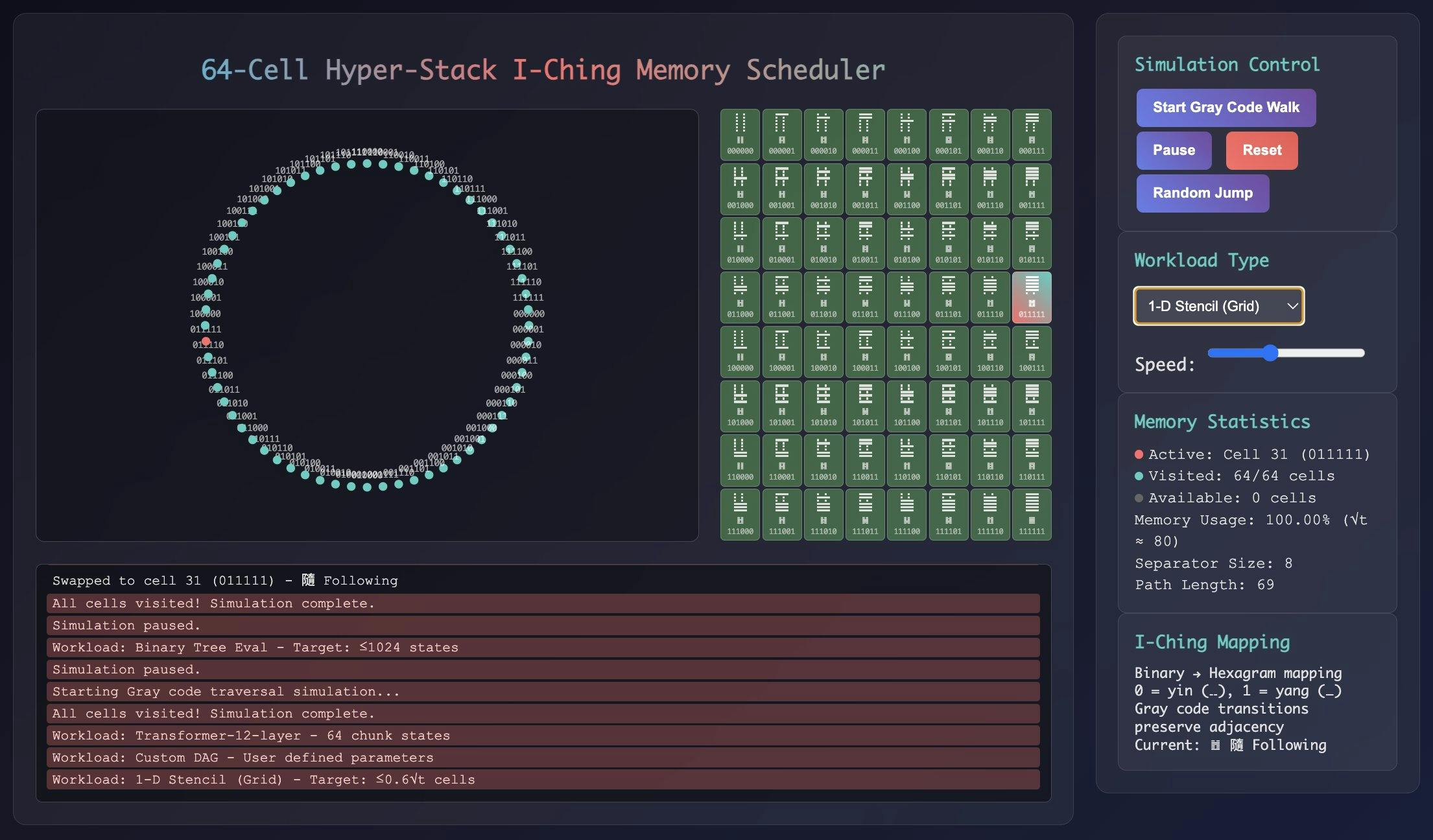
So this made me wonder: Could we combine the mathematical elegance of Williams' breakthrough with the embodied wisdom of these ancient practices? Could the hexagrams of the I-Ching—essentially a 6-bit binary code—offer a new mental model for memory scheduling? I ended up prototyping something I'm calling the 64-Cell Hyper-Stack Scheduler (HSS).
Williams' result, more formally expressed as:
For every function t(n) ≥ n, TIME[t(n)] ⊆SPACE[O(√t(n) log t(n))]
...is a big deal. Most prior time-space separations were theoretical or weak, but this one is tight and constructive. Essentially, any decision problem solvable by a multitape Turing machine in time t(n) can also be solved by a (possibly different) multitape Turing machine using only O(√t(n) log t(n)) space.
In practical terms, my understanding is that it means you can shrink active memory from t down to √t (plus some log factors). That's the difference between fitting your models on self-hosted GPUs and needing to rent $20,000 servers. For engineers and developers, this translates directly to:
- Cost Savings: Less RAM, fewer expensive machines.
- Scalability: Fit larger problems into existing hardware.
- Efficiency: Potentially faster execution due to improved cache utilization.
Beyond the raw numbers, I had a hunch that hex-based schemas might reveal something further for us. They might help enforce locality, predict spillover, and even help you debug complex workloads faster by providing a visual, intuitive map of your memory states. Because we already have evidence of hexagonal structures influencing technology from cell towers, to pathfinder algorithms, to geospatial analysis systems.
The Breakthrough in Plain English (and Code)
The old assumption in computer science was that if an algorithm takes t time steps, you'd likely need about t space to track its state. Williams’ proof breaks this by demonstrating you can recursively split your problem into smaller chunks (often using balanced separators in planar graphs), allowing you to reuse the same memory cells logarithmically. Think of it like this: instead of needing a unique note for every single step of a journey, you can develop a system that efficiently reuses a smaller set of notes by strategically pausing, storing, and then resuming your progress through complex terrain.
What Ancient Memory Systems Teach Us About Data Compression
Long before SSDs and DRAM, Indigenous cultures mastered data compression via "old school" techniques:
- Songlines (in Australia): Vast networks of stories mapped onto landscapes. Singing the song literally helps you remember the route, offloading complex navigational data into a memorable, embodied pattern. In more recent times, we've seen the power of song show up for improving memory of moments with dementia patients.
- Dance as Database: Some cultures encode taxonomies, rituals, and histories in choreographed dance sequences, storing information in muscle memory and shared physical patterns. See research here.
- Story Stacking: Narrative layering allows humans to recall massive genealogies, legal precedents, and procedures without written records, building complex information structures through mnemonic devices. We know indigenous cultures thrived off of oral storytelling traditions. However, the modern version of this may very well be meme culture.
What struck me is that these methods also implicitly reuse limited working memory, offloading complexity into embodied, recursive patterns. From what I can see, this parallels Williams' mathematical approach to memory reuse.
Why Hexagons and the I-Ching?
My choice of the I-Ching's hexagrams wasn't arbitrary. It was driven by three core reasons:
- Optimal Packing: Hexagons are known to have tile space with minimal boundary per area. Think of beehives or the structure of graphene. This geometric efficiency can translate to better memory organization.
- Binary Elegance: Each I-Ching hexagram is a perfect 6-bit binary code (yin = 0, yang = 1). Leibniz himself recognized this centuries before the advent of digital computers. This makes them inherently computable.
- Gray-Code Adjacency: Moving between adjacent hexagrams means flipping only one bit. This "Gray-code" (a way of counting in binary where each step changes just one digit, making it useful for error reduction in digital systems) property is crucial for low-overhead transitions between memory states, minimizing the cost of switching contexts.
This combination seemed like a natural bridge between Williams’ recursion and a more intuitive, visual memory model.
Building the 64-Cell Hyper-Stack Scheduler

I wanted something tangible you could see and use, so I built a small, interactive prototype.
Here's what it does:
- Maps workloads onto a 6-D hypercube (64 vertices = 64 hexagrams).
- Uses Gray-code walks to keep transitions efficient and minimize "cost" when moving between memory states.
- Visualizes which cells are active, which are being split for recursive operations, and which are being reused.
- Lets you simulate workload traversal in near real-time, allowing you to observe memory behavior.
For an example workload of 100,000 time steps, the prototype demonstrated active memory usage of approximately 0.6sqrtt, with a slowdown factor of roughly 4x compared to a linear memory approach. Even in this early form, it's surprisingly intuitive: you can visually track where your memory is being allocated and reused.
How You Might Use It in Your Projects
The concepts behind the Hyper-Stack Scheduler can be adapted for various real-world scenarios:
- Model Checkpointing: Map transformer layers, RNN states, or other deep learning model components onto hex-cells for more efficient checkpointing and fine-tuning.
- Embedded Systems: Fit complex state machines and algorithms into tiny RAM footprints, critical for IoT devices and other resource-constrained environments.
- Debugging Complex Systems: Use the visual adjacency of hexagrams to track state transitions and spot anomalies or bottlenecks in your memory usage patterns more intuitively.
If you're eager to experiment, the scheduler code is open (ping me!), and can be adapted for your specific workloads.
Open Questions & Next Steps
While promising, there are always caveats:
- The √t bound is asymptotic; real-world gains will depend heavily on your specific graph structure and workload characteristics.
- The constant factors in separator recursion still add some overhead that needs to be optimized for practical applications.
- Any cognitive benefits from hexagram visualization for debugging are, so far, anecdotal but warrant further exploration.
Final Thoughts: Ancient Wisdom, Modern Code
This project started with a simple question: "could ancient knowledge systems inspire better computing?" After combing through Williams’ theorem and prototyping the Hyper-Stack Scheduler, I'm convinced the answer is "yes." But if you're curious to explore the boundaries of algorithmic memory compression with me — or just want to see how 3,000-year-old symbols can help you debug your code in 2025—check out the scheduler and share your feedback.
👉 Try the prototype here: hyper64i.vercel.app
💬 Hit me up if you want to collaborate or fork the project.
如有侵权请联系:admin#unsafe.sh