文章探讨了Kubernetes中GPU设备插件的重要性及其在AI/ML、渲染和科学计算中的应用。尽管这些插件提升了GPU资源利用率和性能,但其高权限和硬件依赖性也带来了安全风险,包括特权提升、资源隔离不足和供应链漏洞。文章建议通过最小化权限、强化RBAC配置、限制HostPath访问及加强监控等措施来提升安全性。 2025-3-27 19:49:39 Author: www.sentinelone.com(查看原文) 阅读量:60 收藏
GPU device plugins in Kubernetes have become indispensable for artificial intelligence (AI) and machine learning (ML) workloads. They enable seamless integration of graphics processing unit (GPU) resources, accelerating computationally heavy tasks such as model training, real-time inference, and big-data processing.
As organizations scale their AI and ML operations, these plugins simplify resource management while maximizing GPU utilization. However, this growing dependency on GPU-enabled environments also requires careful attention to security configurations. While essential for high-performance computing, GPU device plugins can inadvertently introduce serious security risks if configured incorrectly.
Research indicates that GPU resources should follow the same principles as CPU and memory management in Kubernetes, where resource allocation is abstracted from the underlying hardware. Currently, the proliferation of device plugins creates a complex ecosystem that exposes unnecessary implementation details to users. This blog post aims to bridge the gap between enabling high-performance computing and maintaining robust security in Kubernetes environments.

Device Plugins in Kubernetes
In modern cloud-native environments, Kubernetes has become the de facto standard for container orchestration. One of its most powerful yet often overlooked features is the device plugin framework, which enables pods to access specialized hardware resources.
While this capability drives innovation in areas like GPU computing and field-programmable gate array (FPGA) acceleration, it also introduces unique security considerations that security teams must understand and address. Use cases for GPU device plugins are commonly found in the following:
AI/ML:
- Training and Inference – Deep learning models can be trained faster and served at scale in real-time inference workloads.
- Parallel Data Processing – Large datasets can be processed more quickly by leveraging GPU cores in parallel.
Rendering:
- Media & Entertainment – Tasks like 3D rendering, video encoding, and virtual reality (VR) simulation require substantial GPU power.
- Container Integration – GPU plugins help packaging these workloads into containers for better portability and manageability.
Scientific Computing:
- Research – Genome sequencing, astrophysical simulations, and climate modeling leverage GPUs to handle massive computations.
- Scale & Efficiency – GPU plugins enable high-performance computing (HPC) workloads at scale, drastically reducing compute times.
Architectural Overview | How Device Plugins Integrate with Kubernetes
Kubernetes device plugins integrate seamlessly with the Kubernetes API, enabling workloads to access specialized hardware such as GPUs. The integration process begins with deploying the device plugin as a DaemonSet on every node containing the target hardware. Once running, the plugin registers with Kubernetes’ device plugin API, advertising available GPUs as extended resources. This allows Kubernetes to treat them as schedulable resources, ensuring that pods can request and utilize GPUs by specifying resource limits in their manifests.
To make the Kubernetes API work seamlessly with the device plugins, the following components are part of the process:
- DaemonSet Deployment – A GPU device plugin typically runs as a DaemonSet on every node equipped with a GPU.
- Device Plugin API Registration – Once running, the plugin registers with Kubernetes’ device plugin API, advertising available GPUs as extended resources.
- Scheduler Integration – Kubernetes then treats these GPUs as requestable resources. Pods specify GPU resource requests in their manifests.
- Container Runtime Interaction – The plugin works with container runtimes (e.g., containerd, CRI-O) to allocate GPU devices, mount compute unified device architecture (CUDA) libraries, and facilitate kernel-level driver interactions.
- Device Discovery & Health Monitoring – Continuous monitoring ensures pods only use healthy GPU devices, improving reliability and performance.
More information on common Kubernetes components can be found here.
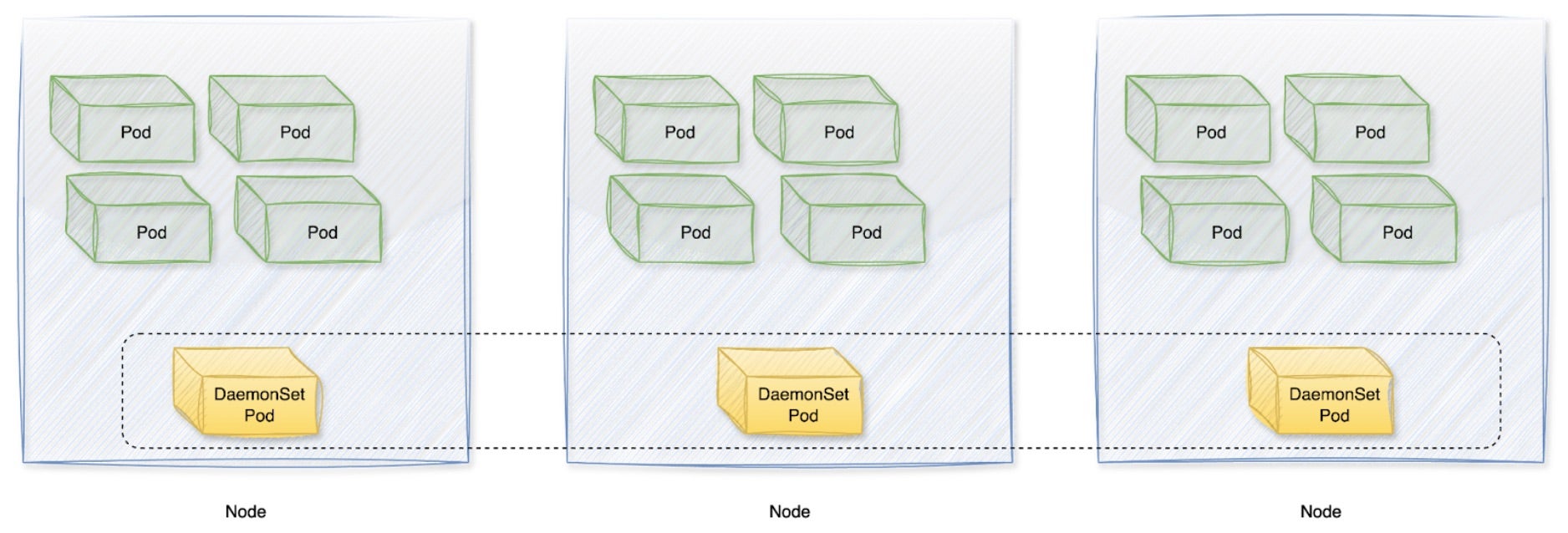
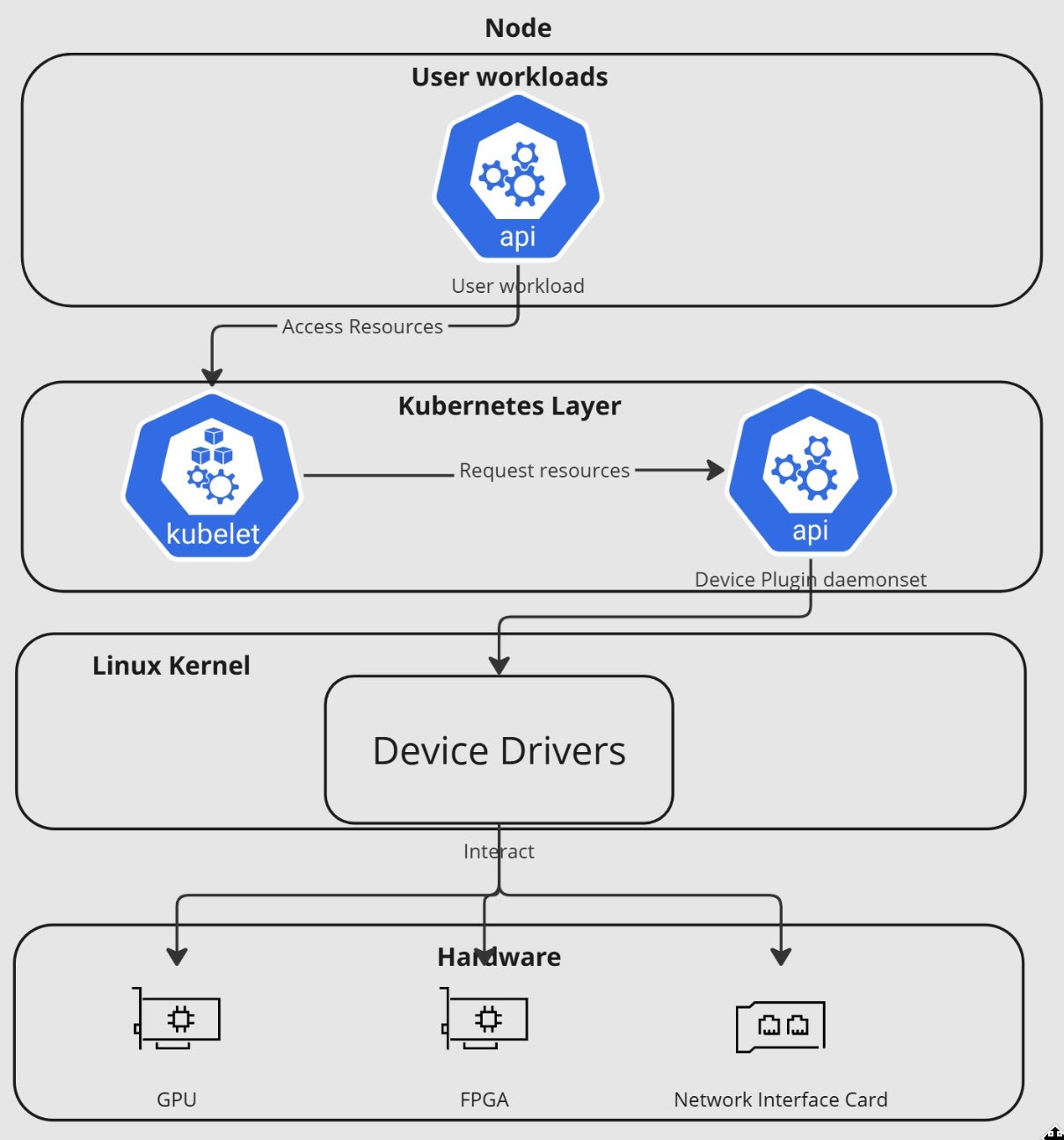
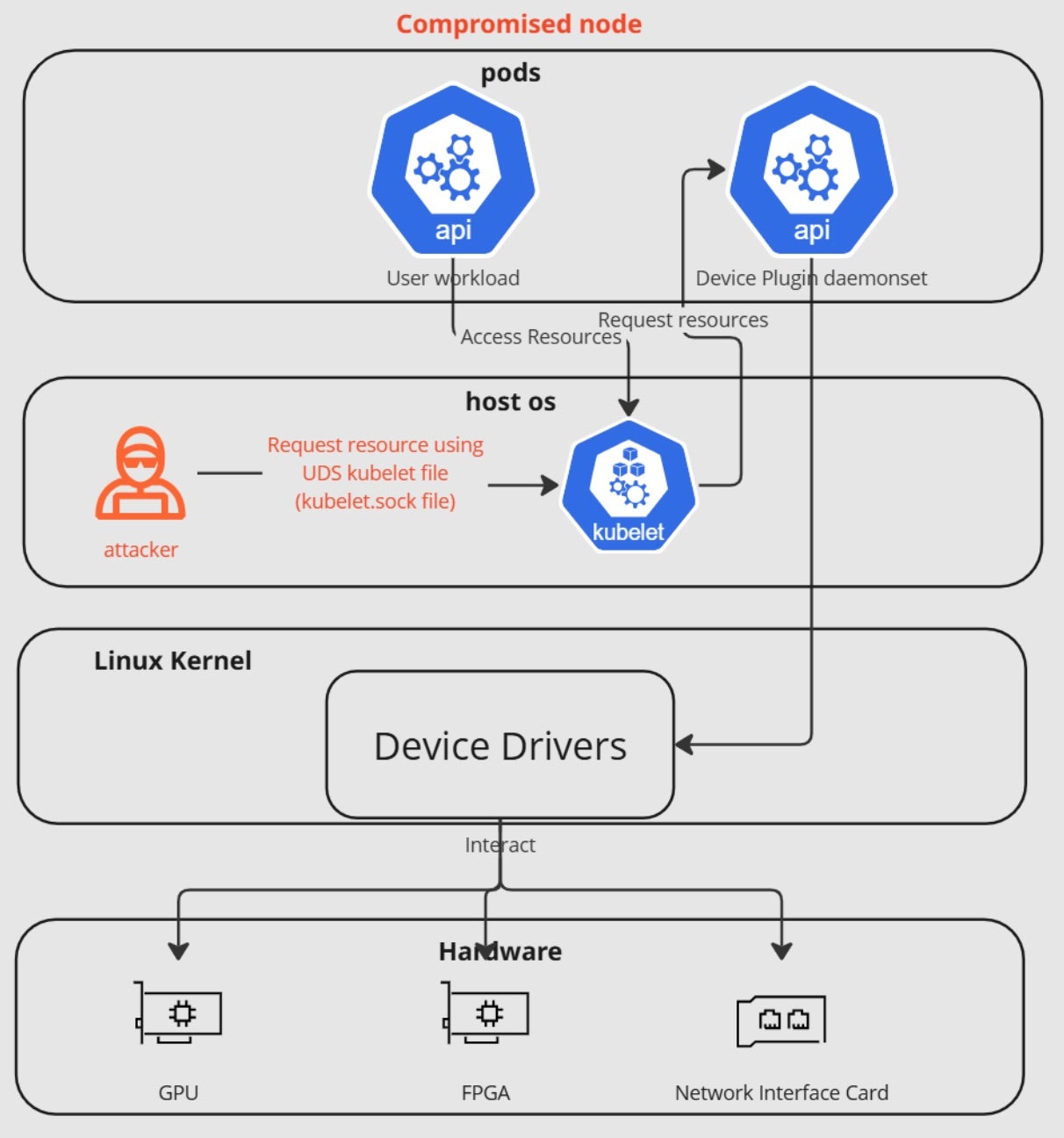
Going inside each node, we can see that device plugins are daemons that run on Kubernetes nodes, advertising specialized hardware resources to the kubelet using a Unix domain socket. The process follows several key steps to ensure efficient and reliable GPU utilization while maintaining Kubernetes’ declarative resource management model:
- Registration – The plugin registers itself with the kubelet through the
/var/lib/kubelet/device-plugins/directory, creating a Unix domain socket. - Resource Advertisement – The plugin advertises its available resources and their properties to the kubelet. For example, a GPU plugin might report the number and types of available GPUs.
- Health Monitoring – The kubelet maintains a constant connection with the plugin, monitoring its health through periodic ListAndWatch RPCs.
- Resource Allocation – When a pod requests a specific device resource, the kubelet communicates with the relevant plugin to allocate and set up the device for the pod.
Security Challenges of GPU Device Plugins in Kubernetes
While the Kubernetes device plugin framework enables efficient access for GPU-intensive workloads driving specialized use cases including AI/ML, it also introduces security risks if not properly managed.
Unlike CPU-bound applications, GPU workloads necessitate direct communication with GPU hardware, libraries, and drivers – often at a kernel or driver level – complicating integration with container runtimes and Kubernetes itself. The confluence of hardware dependencies, container orchestration, and privileges makes GPU device plugins a distinct and potentially high-risk attack vector. This risk is magnified by the fact that these plugins operate as DaemonSets, so inherent risks scale and impact across nodes which increases the attack surface.
This architecture introduces several potential security risks that organizations should consider the following.
Privilege Escalation Vectors
Device plugins typically require privileged access to manage hardware resources. This elevated access level means a compromised plugin could potentially be used as a privilege escalation vector. A common misconception is that GPU plugins inherit Kubernetes’ default security protections, however their reliance on elevated privileges and shared resources increases the risk of privilege escalation and host compromise.
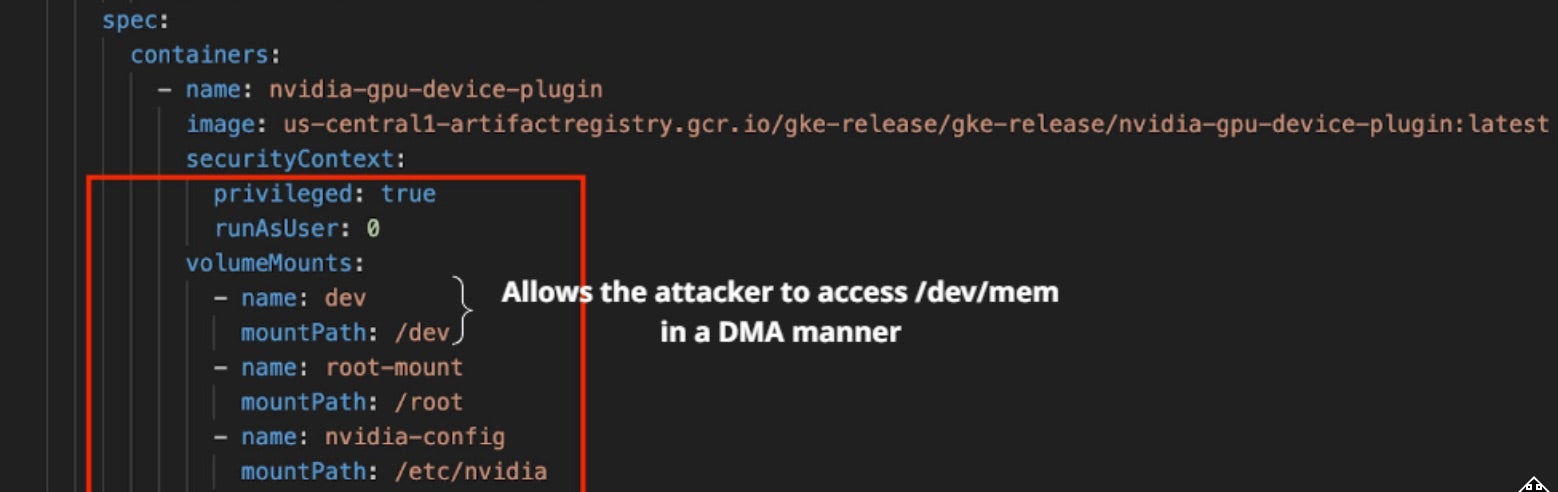
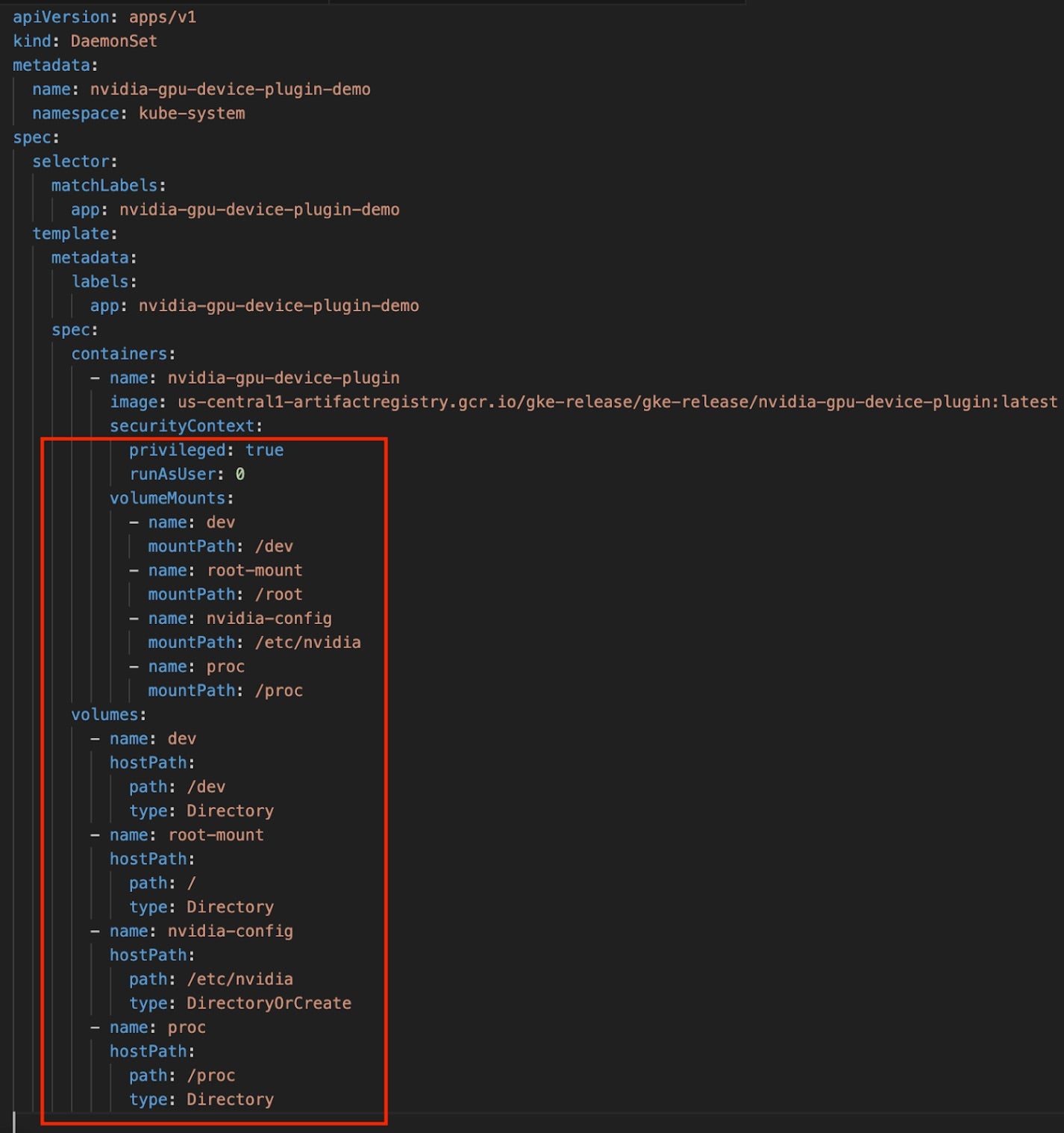
These elevated privileges (root access, HostPath mounts) can be used to bypass certain isolation boundaries if misconfigured. The following elevated privileges are demonstrated in the figure below:
- HostPath Mounts – The snippet shows that the pod mounts sensitive host directories (
/dev,/,/etc/nvidia,/proc), which can expose the host’s device files, filesystem, and process information. - Root Access – By specifying
privileged: trueandrunAsUser: 0(i.e., root), it emphasizes that the container bypasses many default security restrictions, potentially leading to an expanded attack surface.
The combination of these privileges and the need for device plugins to expose raw device access opens several attack vectors wherein an attacker can perform Container Escape via Device Access. A major attack vector is Direct Memory Access (DMA) attacks, where an attacker leverages exposed hardware to read or modify system memory, potentially bypassing container boundaries and accessing sensitive data.
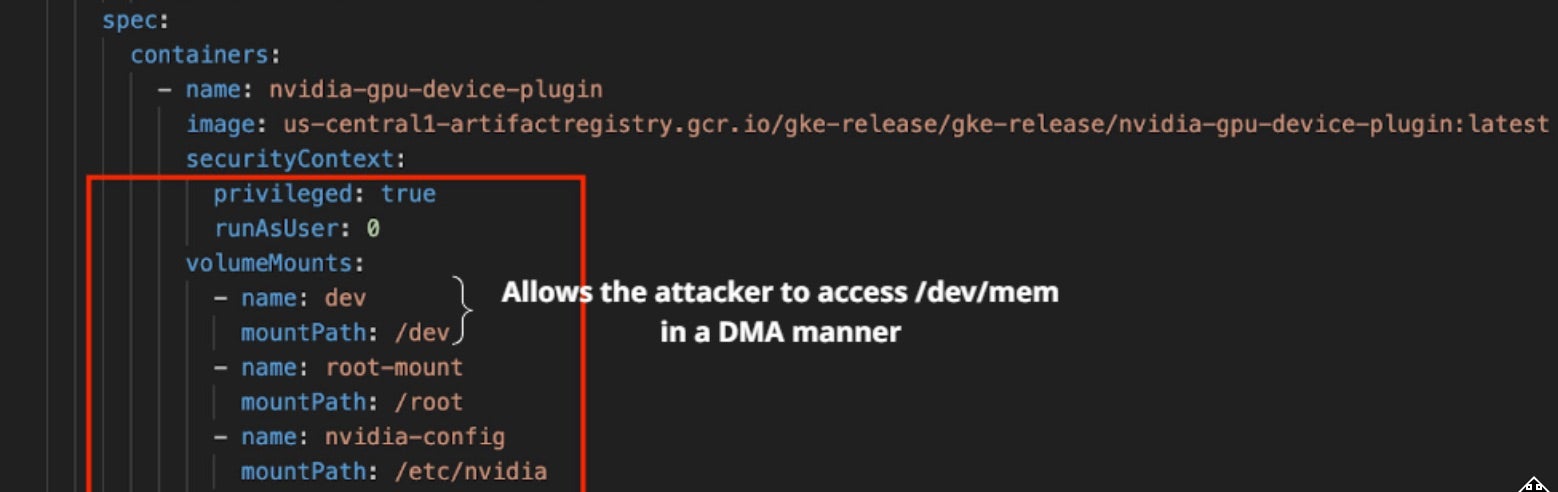
Further examples of attack vectors enabled by device access accessible via elevated privileges are to target driver vulnerabilities and device firmware: If a device driver has security flaws, attackers can exploit them to gain unauthorized access, execute arbitrary code, or crash the system. Additionally, if an attacker were to manipulate device firmware through exposed interfaces, they could be allowed to install persistent backdoors, corrupt hardware operations, or even physically damage devices.
A final example of leveraging elevated privileges is to manipulate the device plugin’s Unix domain socket (UDS) communication channel with the kubelet, which can be exploited if not properly secured. Exploiting vulnerabilities in the communication with the kubelet via Unix domain sockets enables attackers to intercept data, inject malicious requests, or even register fake plugins to advertise phantom resources. Leveraging this channel can also lead to full compromise of the underlying node through privileged access.
Resource Isolation Challenges
While Kubernetes provides strong container isolation, device access often requires bypassing some of these isolation mechanisms. Another common misconception is that GPU resources are inherently isolated.
In reality, without robust policies (e.g., MIG, strong cgroup configs), GPU memory and processes can bleed across tenants, potentially exposing sensitive data or enabling lateral movement. The lack of isolation and sharing of hardware resources, for example GPUs, increases the concern of data leakage.
One vulnerability that arises when GPU memory is not properly cleared between allocations is that sensitive information from one pod can potentially be accessed by another. In a similar vein, shared memory regions that are not adequately isolated between containers can enable cross-container access to confidential data.
Timing attacks can also be launched through these shared hardware resources, where attackers exploit subtle variations in processing time to infer private information from other pods. These kinds of vulnerabilities can lead to side-channel attacks, where attackers indirectly gain access to sensitive data through the way resources are shared and processed.
Supply Chain Risks
Third-party device plugins, like many other Kubernetes components, can introduce supply chain vulnerabilities. Malicious or compromised plugins could provide attackers with direct access to node hardware and potentially sensitive data processed by these devices.
An example of an attack enabled by a malicious or compromised plugin is resource spoofing, where the scheduling and allocation of hardware resources is manipulated. A malicious plugin could falsely report available resources, leading to oversubscription, where more workloads are assigned to a GPU or other hardware than it can handle. This can degrade performance, cause application failures, and create instability across the cluster.
Alternatively, an attacker could deliberately under-report available resources, hoarding them for unauthorized use (aka resource hijacking) such as cryptomining or running hidden workloads.
Finally, malicious plugins could fabricate fake hardware resources, tricking Kubernetes into making faulty scheduling decisions, disrupting critical applications, or launching denial-of-service (DoS) attacks.
Why Securing GPU Device Plugins Is Challenging
Securing GPU device plugins in Kubernetes is uniquely challenging due to their privileged mode and hardware interaction requirements. The following points underscore why organizations must pay special attention to plugin-level configuration and security boundaries:
Elevated Privileges
- Hardware-Level Access – Directly accessing /dev device nodes and loading/unloading GPU drivers typically requires root privileges.
- Attack Surface – In multi-tenant or zero-trust environments, a compromised GPU pod can escalate privileges and move laterally throughout the cluster.
Lack of Standardized GPU Rate Limiting
- Resource Monopolization – Kubernetes does not natively throttle GPU use like it does CPU and memory.
- DoS Risks – An attacker or misconfigured workload can consume GPU cycles, starving high-priority AI inference tasks.
The Privileged DaemonSet Dilemma
- Broad Permissions – DaemonSets often run with heightened privileges across all GPU nodes.
- Rapid Propagation – A single compromised DaemonSet image can quickly proliferate to every GPU node.
Overexposed HostPath Mounts
- Root Filesystem Access – Some GPU plugins rely on wide-ranging HostPath mounts for device registration or driver manipulation.
- Persistence & Tampering – Attackers can install backdoors or modify driver parameters if HostPath is writable.
Default Service Account Misuse
- RBAC Oversight – Many deployments default to the default or an over-permissioned service account, making it easier for attackers to pivot.
- Multi-Tenant Danger – Sharing a single, powerful service account across different workloads spreads risk unnecessarily.
Blind Spots in Monitoring and Observability
- Limited GPU Metrics – Most of the monitoring tools track CPU/memory but provide minimal GPU telemetry.
- Hidden Attacks – Cryptomining or other rogue GPU workloads can remain under the radar without specialized GPU monitoring.
Shared Resource Risks
- Data Leakage – Multiple pods sharing a GPU can potentially access shared buffers or memory if isolation is weak.
- Data Integrity – An attacker with direct GPU access can tamper with partial model outputs or intermediate data.
Magnified Impact of Breaches
- Critical Workloads – AI, ML, and HPC tasks often define core business operations. Losing GPU availability can halt essential services.
- Cascading Failures – A single exploited GPU plugin may disrupt entire pipelines from training to production inference.
Device plugins management
- Plugins management – Installation process is done without any connection to proper package management, no SBOM integration, and device verification process which can cause installation of rogue device plugins due to installation of unauthorized plugin
The Way Forward | A Holistic Security Approach
Securing GPU workloads requires more than traditional security measures. A holistic security approach considers privilege management, runtime restrictions, and proactive monitoring to mitigate risks. Here are eight key strategies to help organizations fortify their GPU environments against sophisticated attacks, ensuring both operational efficiency and security in high-performance computing and AI-driven workloads.
Privilege Reduction
- Use container runtimes or orchestrators that support GPU pass-through without full root privileges.
- Apply kernel security modules (SELinux, AppArmor) and seccomp profiles to restrict system calls.
RBAC and Dedicated Service Accounts
- Create a dedicated service account for GPU plugins, granting only the necessary permissions.
- Periodically audit and prune old roles, bindings, and certificates to prevent privilege creep.
Secure DaemonSet Deployment
- Limit file system access to read-only where possible.
- Leverage admission controllers (OPA/Gatekeeper, Kyverno) for policy enforcement of privileged containers.
- Verify the device plugin against the installed hardware
HostPath Hardening
- Restrict HostPath usage to read-only unless absolutely needed.
- Use Pod Security Standards (PSS) or advanced policies to disallow broad HostPath mounts in production.
GPU Rate Limiting and Scheduling
- Explore MIG (NVIDIA) or advanced schedulers (Volcano, Slurm) for isolating GPU resources.
- Investigate custom resource definitions (CRDs) that offer finer-grained GPU control.
Enhanced Observability and Monitoring
- Deploy GPU-specific metrics exporters (e.g., NVIDIA DCGM Exporter).
- Integrate with Prometheus or Grafana to watch for unusual GPU activity.
Defense-in-Depth and Zero Trust
- Apply microsegmentation, network policies, and intrusion detection (eBPF-based Falco or Sysdig).
- Treat GPU nodes as high-value targets, assuming potential compromise.
Incident Response and Recovery
- Maintain hardened base images; proactively scan for vulnerabilities.
- Automate backups of critical GPU plugin configs, regularly test DR (disaster recovery) procedures
Conclusion
GPU device plugins significantly enhance Kubernetes clusters by offering the raw computational power needed for AI, ML, rendering, and scientific workloads. Yet, their privileged nature and deep integration with GPU hardware can also be a liability if misconfigured. The threat vectors, ranging from insecure HostPath mounts to compromised DaemonSets, are real and can lead to cluster-wide breaches.
A holistic security strategy unifies the best of Kubernetes-native defenses (i.e., RBAC, PodSecurityPolicies, admission controllers) with GPU-specific hardening (i.e., MIG, GPU monitoring exporters, minimal privilege setups). As enterprises continue to adopt GPU-accelerated solutions, staying informed on evolving security patterns, driver updates, and plugin versions will be crucial to minimizing exposure.
By aligning operational efficiency with strong security principles, teams can enjoy the full performance benefits of GPUs without inviting undue risk into their Kubernetes environments.
如有侵权请联系:admin#unsafe.sh