NTT DATA与Train合作发布报告,探讨生成式AI和合成数据在医疗与药研中的应用潜力。该技术助力加速临床试验、提升医院效率,并用于医学教育及罕见病治疗开发。 2025-3-20 16:45:59 Author: www.securityinfo.it(查看原文) 阅读量:10 收藏
Mar 20, 2025 Approfondimenti, In evidenza, Software, Tecnologia
A differenza di altri settori, la medicina non può affidarsi a modelli di AI generativa generalisti. La necessità di precisione, affidabilità e sicurezza impone infatti l’uso di sistemi specificamente progettati per il contesto clinico e rigorosamente validati.
I modelli generici, spesso addestrati su dataset di ampia portata ma non specifici, non sono in grado di garantire il livello di accuratezza richiesto per supportare diagnosi e decisioni terapeutiche.
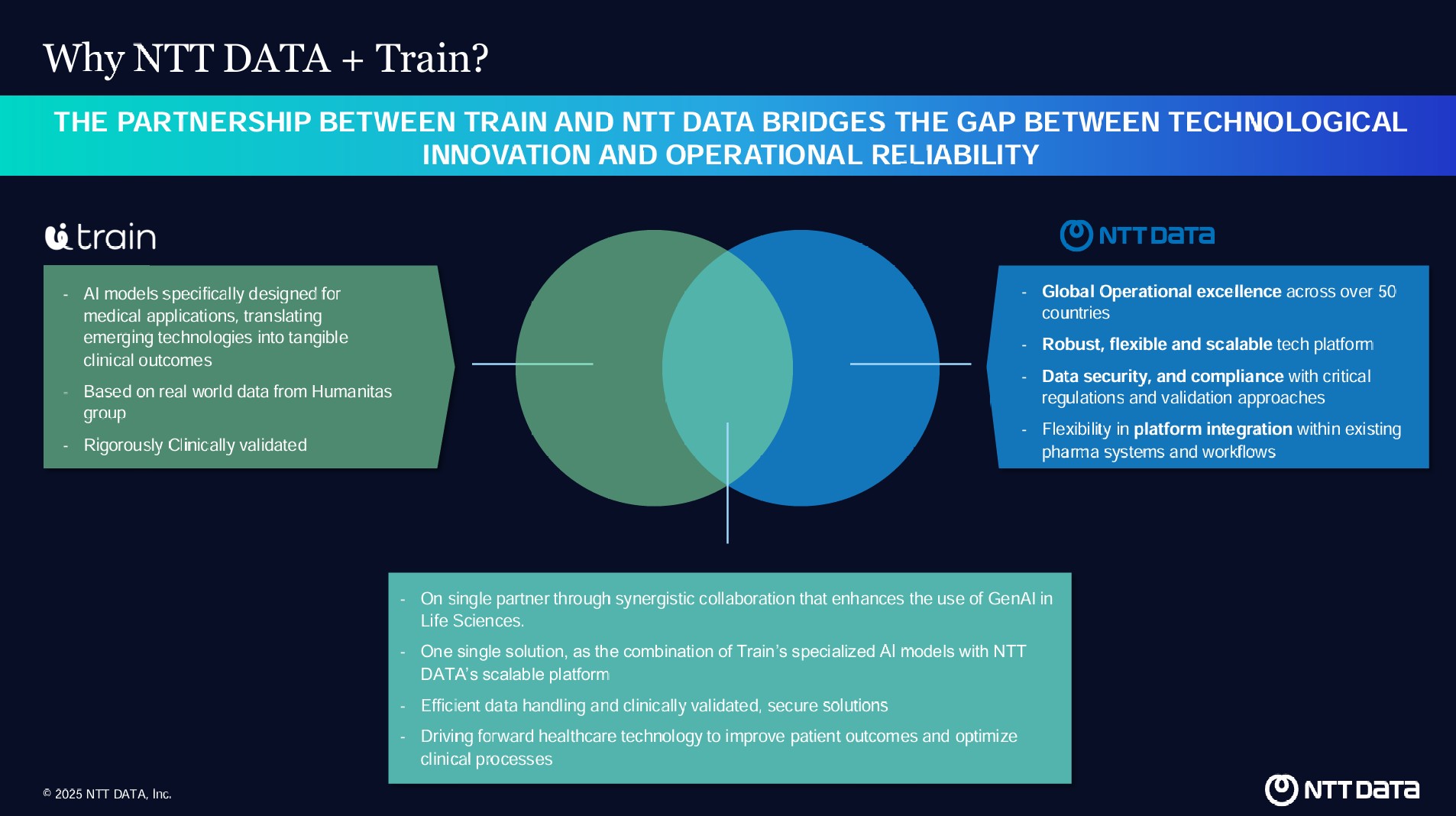
È da queste premesse che nasce la collaborazione tra NTT DATA e Train. Il primo è uno dei maggiori fornitori di servizi IT e consulenza a livello globale, con oltre 190.000 professionisti operanti in più di 50 Paesi e un fatturato annuo che supera i 30 miliardi di dollari.
Il secondo, Train, è invece uno spin-off dell’IRCCS Istituto Clinico Humanitas, fondato nel 2023 con l’obiettivo di sviluppare intelligenza artificiale generativa per il settore medico.

NTT DATA e Train hanno presentato il report “Generative AI and synthetic data for clinical application”, un’analisi sul ruolo dell’IA nella medicina e nella ricerca farmaceutica.
Il suo punto di forza è la capacità di validare clinicamente i propri modelli di IA grazie alla collaborazione con esperti del settore e a un solido background scientifico, con 42 partner internazionali, 25 pubblicazioni scientifiche e 10 programmi di ricerca in corso. Oltre oviamente alla mole di dati reali generati dal gruppo Humanitas.
La partnership tra NTT DATA e Train ha portato alla realizzazione del report “Generative AI and synthetic data for clinical application”, un’analisi approfondita sul ruolo dell’intelligenza artificiale generativa nella medicina e nella ricerca farmaceutica.
Analisi che è stata illustrata ieri da Emanuele Corbetta (Head of Life Sciences di NTT DATA Italia), Saverio D’Amico (CEO e Co-Founder di Train) e Matteo Della Porta (CSO e Co-Founder di Train e Head of leukemia unit di Humanitas).
L’intelligenza artificiale generativa e il valore dei dati sintetici
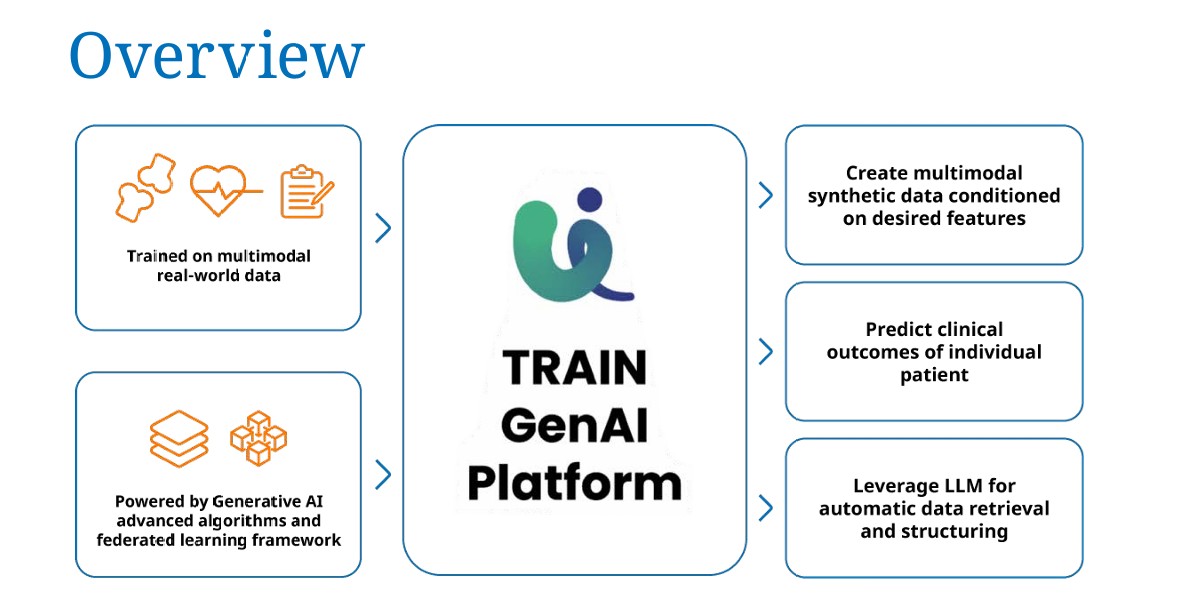
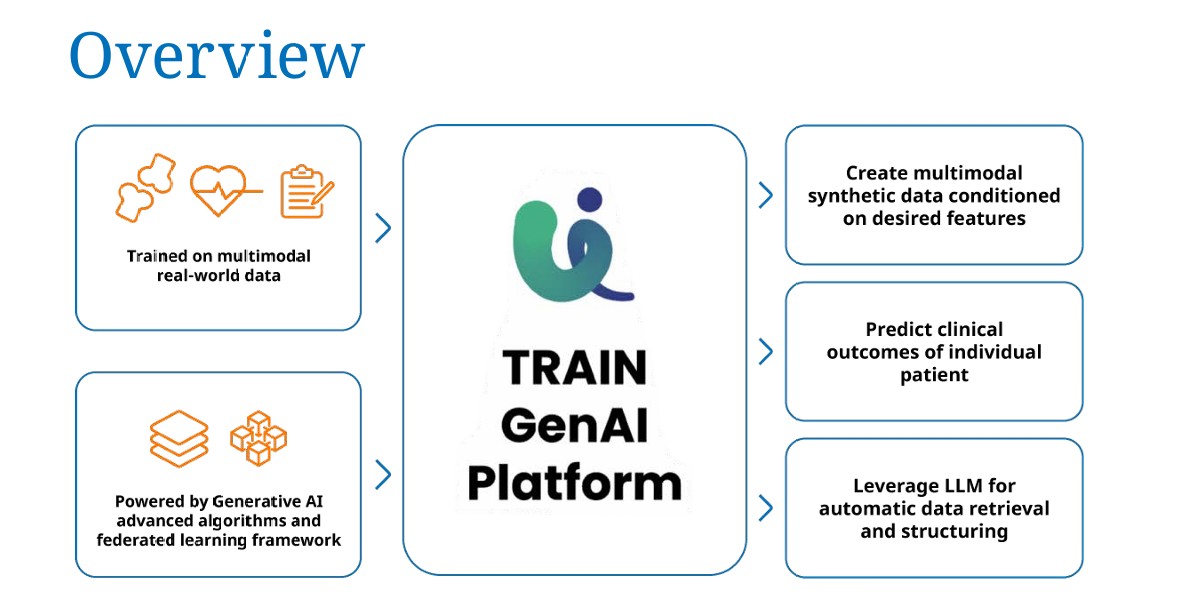
Il documento evidenzia il potenziale dei dati sintetici nel supportare la medicina, accelerare la sperimentazione clinica e migliorare l’efficienza dei processi ospedalieri.
La prima cosa da dire è che nel campo della data science, si distingue tra modelli discriminativi e generativi. I primi servono a classificare i dati, identificando pattern e separando le informazioni in base a criteri predefiniti. I secondi, invece, hanno la capacità di creare nuovi dati che riproducono le caratteristiche statistiche di quelli reali.
È grazie a questi ultimi che si possono realizzare i dati sintetici, strumenti fondamentali per la ricerca clinica, l’addestramento di modelli AI e lo sviluppo di nuove terapie.
La generazione di dati sintetici avviene attraverso tecnologie avanzate come le Generative Adversarial Networks (GAN), i Variational Autoencoders (VAE) e i modelli Transformer come GPT.
Questi sistemi sono in grado di produrre dati artificiali che imitano fedelmente quelli reali, pur non contenendo informazioni sensibili, garantendo così privacy e sicurezza.
L’uso dei dati sintetici offre vantaggi significativi ma presenta anche alcune sfide. Sebbene siano strumenti estremamente utili per la ricerca, non possono sostituire completamente i dati reali, poiché potrebbero non rappresentare con precisione eventi rari o anomalie cliniche.
Inoltre, i modelli e gli algoritmi utilizzati per la loro creazione devono essere costantemente validati per evitare distorsioni o errori di interpretazione.
Oltre al loro utilizzo nei trial clinici e nella medicina personalizzata, che combina dati multimodali di singoli pazienti per guidare le decisioni cliniche, i dati sintetici trovano un’applicazione innovativa anche nell’educazione medica.
Attraverso simulazioni realistiche, gli studenti possono essere esposti a una grande varietà di casi clinici, compresi quelli rari, aumentando così la loro capacità diagnostica e la comprensione delle patologie.
Questa tecnologia permette dunque di creare scenari sempre più sofisticati, migliorando l’apprendimento e la preparazione dei futuri medici.
Malattie rare: un nuovo approccio grazie all’AI
Il report pone l’accento anche sulle sfide che le malattie rare rappresentano per la ricerca medica, a causa della difficoltà nel reclutare un numero sufficiente di pazienti per condurre trial clinici affidabili.
Train ha allora sviluppato una piattaforma basata su AI generativa che rende più sostenibile lo sviluppo di terapie per queste patologie.
Attraverso la creazione di gemelli digitali personalizzati e dati sintetici, la tecnologia di Train consente di generare gruppi di controllo virtuali, migliorando il reclutamento dei pazienti reali e accelerando il processo di sperimentazione.
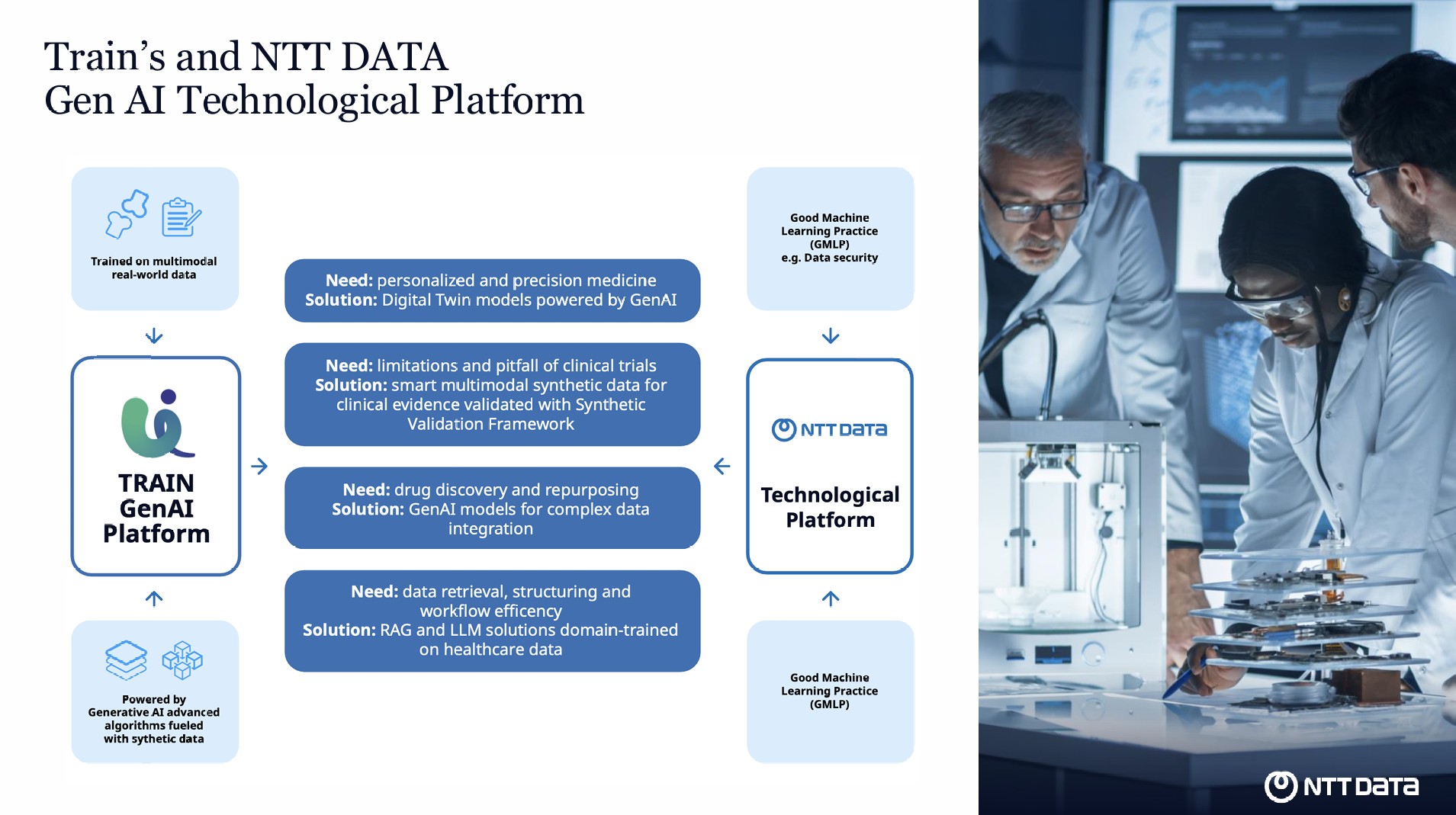
Il framework di validazione sintetica SAFE (Synthetic vAlidation FramEwork), sviluppato da Train, garantisce la qualità e l’affidabilità dei dati generati, assicurando che siano statisticamente e clinicamente validi.
Questo approccio non solo riduce i tempi e i costi dei trial clinici ma amplia anche le possibilità di trattamento per pazienti con patologie rare, spesso escluse dagli studi tradizionali per mancanza di dati sufficienti.
Il ruolo di NTT DATA: tecnologia e sicurezza
L’integrazione di soluzioni di intelligenza artificiale nel settore sanitario richiede piattaforme tecnologiche avanzate, in grado di garantire sicurezza, scalabilità e conformità alle normative sulla privacy.
NTT DATA offre un’infrastruttura tecnologica robusta e flessibile, che consente alle aziende farmaceutiche e agli istituti di ricerca di adottare modelli di AI generativa in modo efficace e sicuro.
Tra le sue caratteristiche distintive vi sono l’interoperabilità con i sistemi sanitari esistenti e la capacità di gestire una quantità di dati destinata a esplodere col tempo.
A ciò si aggiunge un’esperienza utente avanzata per facilitare l’adozione da parte dei team interdisciplinari e una governance dell’AI studiata per garantire trasparenza e affidabilità nei modelli di machine learning.
La sicurezza è un elemento centrale, con un approccio privacy-by-design che assicura la conformità alle normative più stringenti, mentre l’Explainable AI permette di comprendere il funzionamento degli algoritmi, aumentando la fiducia da parte delle aziende farmaceutiche e degli enti regolatori.
In conclusione, non resta che gettare uno sguardo al domani. L’adozione di digital twin e dati sintetici validati apre nuove prospettive per la medicina personalizzata, superando le limitazioni dei trial clinici tradizionali.
L’integrazione di modelli di IA generativa per l’analisi di dati complessi facilita inoltre la scoperta di nuovi farmaci e l’ottimizzazione dei processi ospedalieri, accelerando l’innovazione nel settore della salute.
Grazie a questa sinergia, l’intelligenza artificiale generativa si candida a essere un alleato strategico per la medicina, aprendo la strada a trattamenti sempre più mirati. La cui efficacia potrà essere dimostrata solo dal tempo e dai risultati ottenuti.
Altro in questa categoria
如有侵权请联系:admin#unsafe.sh