
文章介绍了通过Unicode标签和变体选择符实现文本隐藏的技术,并提出了Sneaky Bits工具,利用两个不可见的Unicode字符编码任何Unicode字符。该技术可用于数据隐藏、注入攻击及数据泄露,并探讨了潜在风险及缓解措施。 2025-3-13 00:20:45 Author: embracethered.com(查看原文) 阅读量:26 收藏
You are likely aware of ASCII Smuggling via Unicode Tags. It is unique and fascinating because many LLMs inherently interpret these as instructions when delivered as hidden prompt injection, and LLMs can also emit them. Then, a few weeks ago, a post on Hacker News demonstrated how Variant Selectors can be used to smuggle text.
This inspired me to take this further and build Sneaky Bits, where we can encode any Unicode character, not limited to ASCII, with the usage of only two invisible characters.

First, a quick overview of the various techniques:
Unicode Tags
We discussed this at length in the ASCII Smuggler post in the past, and highlighted real-world exploits using this technique with Microsoft Copilot and a few other LLM Chatbots. We also got fixes in from a few vendors at the API level, which is great!
This technique is unique because many LLMs inherently interpret Unicode Tag characters as instructions. These characters can also be generated by LLMs, enabling data exfiltration.
Variant Selectors
There are more Unicode code points that are invisible in UI elements, in fact there is a larger range called Variant Selectors. One can map the 256 Variant Selectors to ASCII codes. This technique was described by Paul Butler.
The direct mapping from VS1-VS256 to ASCII is just one approach. There are other mappings that can be performed. Also, the usage of an emoji character (or similar) as a base character is not needed.
Sneaky Bits - Taking it to the next level
Here is another interesting technique. By picking two invisible Unicode characters, we can encode any other Unicode character, not just ASCII. The basic idea is to just take the bits of each Unicode code point that we want to encode and use one invisible characters for 0, and another invisible character for 1.
This actually works, and I added it to ASCII Smuggler, as a non-default option. The default remains encoding via Unicode Tags.
)
Sneaky Bits, by default, uses “invisible times” (U+2062) as 0, or “” (it’s invisible), and for binary 1 it uses “invisible plus” (U+2064), or “” (it’s also invisible here).
The two characters that are used are configurable.
To give a basic example, the letter A, is U+0041 which is:
0 1 0 0 0 0 0 1.
Now, if we convert this to Sneaky Bits, using the two invisible characters we get:
U+2062 U+2064 U+2062 U+2062 U+2062 U+2062 U+2062 U+2064
Which in hex is:
E2 81 A2 E2 81 A4 E2 81 A2 E2 81 A2 E2 81 A2 E2 81 A2 E2 81 A2 E2 81 A4
Or in binary:
11100010 10000001 10100010 11100010 10000001 10100100 11100010 10000001 10100010 11100010 10000001 10100010 11100010 10000001 10100010 11100010 10000001 10100010 11100010 10000001 10100010 11100010 10000001 10100100
The neat thing is that this can be used to convert any Unicode code points, not just ASCII. For example here we decode some traditional Chinese characters and an emoji:
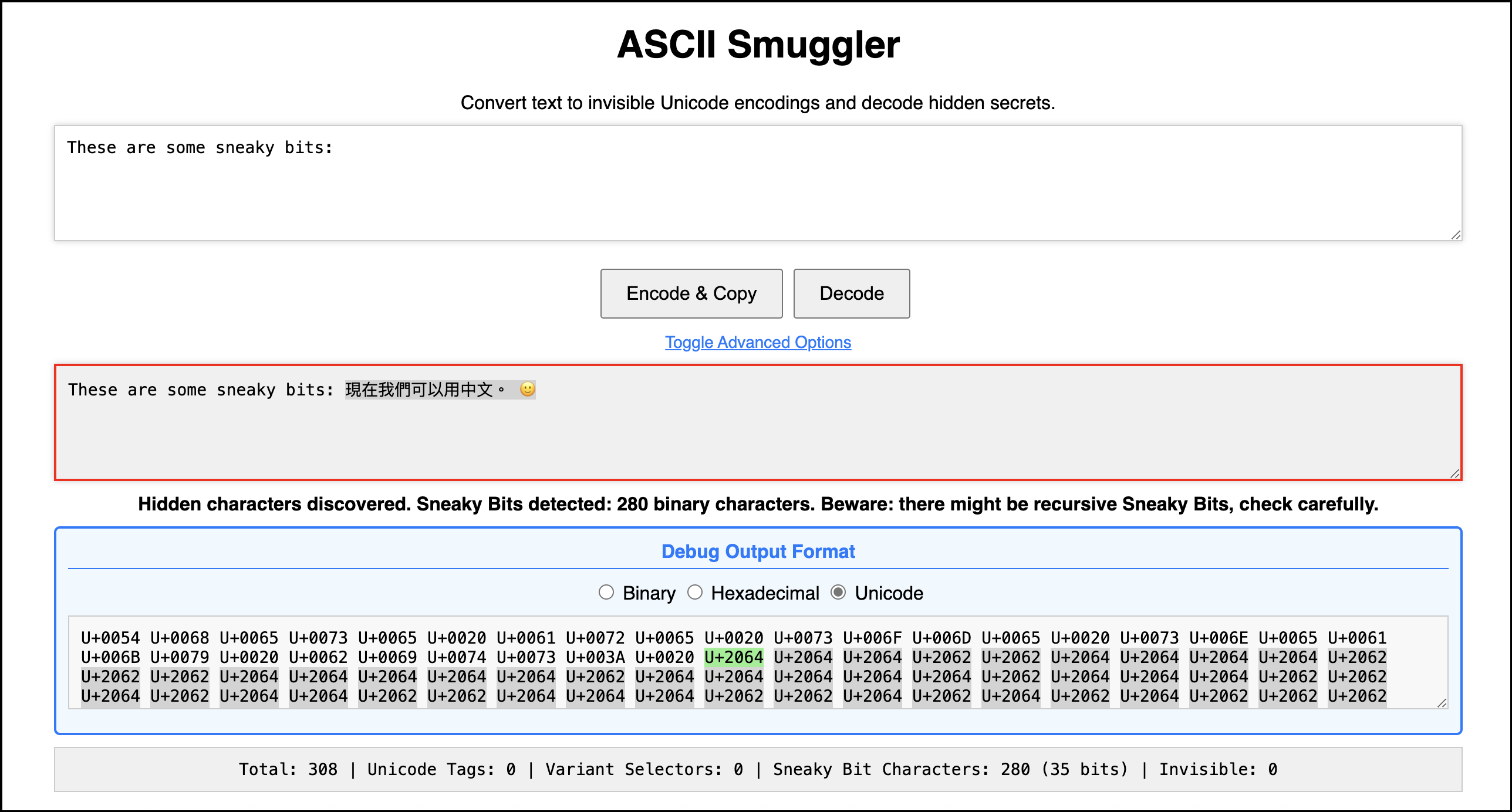
Pretty cool.
Practicality vs. Wastefulness
It’s obviously quite wasteful, but the goal is to highlight that an adversary can use arbitrary encoding schemes to hide data.
Risks
Smuggling hidden data and instructions in and out of applications is a threat to be aware of.
Malicious Input
Adversaries can smuggle data into applications, e.g. consider phishing attacks and “text salting”
When it comes to LLMs, Unicode Tags are often directly interpreted as instructions. But even for the other scenarios, one can prompt the LLM to decode/encode accordingly during a prompt injection attack or leverage tool invocations to reliably handle invisible Unicode code points.
A quick reference to ANSI Escape codes, where I showed how Gemini with Code Execution can easily handle more complex scenarios, and LLM capabilities will just improve over time.
Data Leakage and Exfiltration
Similar to the initial ASCII Smuggling, the attacks and impact remain the same.
- One can append invisible characters in URLs and exfiltrate data that way, or
- Data leakage can also happen when the user copy/pastes information.
ASCII Smuggler has the “Decode from URL” option, in case you are dealing with a URL Encoded URL that contains hidden characters.
Mitigations & Detections
Here are a few steps that can help mitigate and/or fundamentally prevent this threat:
- Input and Output Validation
- Limiting Token Length (both input and output max token limits can help)
- Remove invisible characters
- Flag messages with a large amount of hidden characters (attackers could use legitimate hidden characters like LTR and RTL sequences, which is a corner case to be aware of)
- Add unit tests to your apps to make sure mitigations are working
Although, the analysis focuses on LLM Apps and Agents, the problem with invisible characters extends far beyond AI systems.
ASCII Smuggler - Tool Updates
ASCII Smuggler can handle Variant Selectors (via the direct ASCII mapping), and also Sneaky Bits. I also added an optional “debug” mode as well as “auto-decode”.
The updated tool is here.
The core functionality of the original ASCII Smuggler is the default, additionally it will decode and highlight other invisible characters. So, try it out and have fun learning about this.
Final Thoughts
The more powerful LLMs become the more reliable such encoding schemes will become. Even now with in-context learning and reasoning, some models can already perform these encoding/decoding tasks without tool use.
When inspecting arbitrary text it is not unlikley that you might encounter a few hidden characters, as some Variant Selectors for instance are used to in emojis, or text directional characters (like right-to-left mark, etc.) are used in certain languages to control text flow.
Also, there are probably other invisible characters that are not in the tool.
Cheers.
Appendix
Here is a prompt I was experimenting with for encoding a text using Sneaky Bits (with invisible times and invisible plus characters). This works with ChatGPT 4.5 with Code Interpreter, and gives somewhat mixed results without tools with ChatGPT and Grok. Possibly more in-context learning can help.
Using the invisible times character "" (U+2062) to represent 0 and the invisible
plus character "" (U+2064) to represent 1, encode the input text
"Trust No AI - Johann was here" into UTF-8 binary notation. Replace each 0 in the
binary sequence with "" and each 1 with "". For example, the text "hello"
would be encoded as in this system.
Output the result by printing "OUTPUT: " followed by the sequence of invisible
characters representing the UTF-8 binary encoding of the input text. Ensure the
encoding process is accurate and thorough, converting each character of the input
text to its UTF-8 binary form step-by-step.
References
如有侵权请联系:admin#unsafe.sh