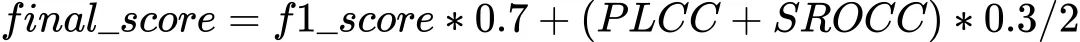
CVPR NTIRE Workshop下举办的AI生成图像质量评估竞赛由抖音与南开大学联合主办。该竞赛基于EvalMuse数据库,包含40,000对图像-文本对和100万细粒度标注。比赛分为图文匹配度评估和结构问题挖掘两个子赛道。 2025-2-7 06:48:0 Author: mp.weixin.qq.com(查看原文) 阅读量:356 收藏
CVPR NTIRE(New Trends in Image Restoration and Enhancement)Workshop 是计算机视觉顶会CVPR下极具影响力的国际学术研讨会,聚焦图像复原、图像增强、生成技术、质量评估的突破性进展。为了推进生成图像/视频领域的发展,建立生成图像/视频领域的质量评估“黄金标准”,抖音多媒体质量实验室/豆包大模型团队(字节跳动)联合南开大学在第十届CVPR NTIRE workshop上举办AI生成图像质量评估学术竞赛。
比赛介绍
论文🔗:https://arxiv.org/abs/2412.18150
赛事具体介绍
Track 1-生成图像质量评估-细粒度图文匹配度打分
比赛网址:https://codalab.lisn.upsaclay.fr/competitions/21220
数据介绍
训练数据:包含30k个image-text 对,这些图像是通过20+T2I生成模型、3000个prompts生成的。我们提供了图文匹配度打分(prompt level)和细粒度图文匹配度打分(element level)的标签来进行训练/测试(具体内容可见evalmuse paper)。
Validation阶段数据:约10k image-text pairs。
Test阶段数据:约5k image-text pairs。
以上数据可通过codalab比赛主页,参与对应比赛获取链接。
模型输出要求&baseline
Baseline可参考Fga-blip2仓库:https://github.com/DYEvaLab/EvalMuse例: 给定Prompt :musician plays guitar aerial shot , 给定element : musician,plays,guitar,aerial shot 模型需要输出
整体图文匹配度打分(可归一化到1-5) element维度是否命中,0代表未命中,及图像中不存在element对应的元素,1代表命中,及图像中存在element对应的元素。以上图为例,musician,plays,guitar均命中,应输出1,aerial shot未命中,应输出0.
评估指标
Final_Score = PLCC / 4 + SRCC / 4 + acc / 2
Track 2-生成图像质量评估-结构问题挖掘
比赛网址:https://codalab.lisn.upsaclay.fr/competitions/21269
数据介绍
训练数据说明:以json形式保存,字典的key为img_name,value为每张图片的标注信息
信息说明: prompt_en:生成图像的prompt,英文。 mos:图像的结构mos分数,范围为1-5分。 bbox_info:有结构问题的区域标注信息,列表格式,长度为3,元素为一个信息列表,分别代表每一个标注员的标注结果,若列表为空则代表该标注员认为当前图像中没有结构问题;若列表不为空,则其中元素为字典形式,记录每一个结构问题区域的bbox信息: bbox_type:bbox标注类型,值为1表示该标注为矩形bbox,值为2表示该标注为多边形bbox bbox:列表格式,元素为bbox顶点坐标 bbox_type=1 ,记录矩形的左上角、右下角坐标 bbox_type=2, 以顺时针顺序记录多边形顶点坐标
模型输出要求&baseline
评估指标
大赛奖励
本次大赛由将由抖音多媒体质量实验室提供奖金!总额在10w元人民币左右,具体奖项设定待定,届时会在比赛codalab网站上进行更新说明。 参赛队伍可自由选择是否发表竞赛相关论文,本次挑战赛将邀请排名靠前的参赛者向NTIRE研讨会提供论文,论文录用后将会发表在2025年CVPR研讨会论文集。 赛道排名前三的队伍将会获得CVPR NTIRE的获奖证书及由抖音多媒体质量实验室提供的奖金。两条赛道的奖金暂定如下: 第一名:2000-4000美元奖金 + 证书 第二名:1000-2000美元奖金 + 证书 第三名:500-1000美元奖金 + 证书
大赛要求
本次学术竞赛面向全社会开放,个人、高校、科研单位、企业等人员均可报名参加。
每支队伍只能提供一种方法进行最终排名。
为保证公平性,如果使用额外数据,请在最终方案报告中说明。
提交的方法必须本地可复现,提交API的方式不被允许。
大赛官网
图文匹配度赛道网址:
https://codalab.lisn.upsaclay.fr/competitions/21220
结构问题挖掘赛道网址:
https://codalab.lisn.upsaclay.fr/competitions/21269
EvalMuse项目主页:
https://shh-han.github.io/EvalMuse-project/
EvalMuse 开源项目地址:
https://github.com/DYEvaLab/EvalMuse
交流群
如链接过期,可联系
主办方
附:EvalMuse数据库介绍
具体介绍参考https://mp.weixin.qq.com/s/RWxspVh0SbisNKEb75jrOw
EvalMuse-40K是一个包含40,000对图像-文本对和超过100万细粒度人类标注的Benchmark,旨在全面评估T2I模型在图像-文本对齐方面的表现。该Benchmark的构建过程既复杂又细致,我们通过精心设计的数据集和标注体系,力求最大程度地反映T2I模型在实际应用中的表现。
EvalMuse-40K 的构建过程复杂而细致。我们首先从 DiffusionDB 中收集了2,000个真实用户的提示,这些提示反映了用户的多样化需求。同时,我们生成了2,000个合成提示,涵盖了物体数量、颜色、材质、环境设置、活动属性等多个方面,以全面评估T2I模型在不同任务中的表现。
接下来,我们使用20种不同的扩散模型生成了40,000张图像,确保了图像的多样性和质量。在数据标注阶段,我们对这些图像-文本对进行了细致的人工标注,涵盖图像-文本对齐评分、元素级别的匹配检查和结构问题标记。标注过程分为预标注、正式标注和重新标注三个阶段,以确保数据的可靠性和准确性。
与现有的文本到图像(T2I)模型的Benchmark相比,EvalMuse-40K 提供了一个更大规模、更细粒度的评估数据库。超过100万细粒度人类标注,使得 EvalMuse-40K 在数据集规模和多样性上远超许多现有Benchmark。与业界一些相关Benchmark的比较见下表:
关注我们,了解更多精彩
如有侵权请联系:admin#unsafe.sh