0x00 引言
本文讨论出发点为(商业)蜜罐利用js脚本调用jsonp接口的过程与检测&防御手法.本文不提供任何成品插件以及检测,只会提供示例代码.
0x01 概述
由于最近参与做了一些hw前的演习项目,在这个过程中,时不时有别的攻击队踩了蜜罐导致被防守方反向溯源.
之前多多少少了解过几个当前市场的(商业)web蜜罐,知道大致关键技术点如下:
- 配置jsonp接口信息
- 配置蜜罐网站信息
- 仿站(提供目标站点扒取页面静态文件,功能无法正常使用)
- 二次修改后的源码(功能可用正常使用,但是所有数据全部为假数据,或者是精简以后的源码)
- 等待踩蜜罐
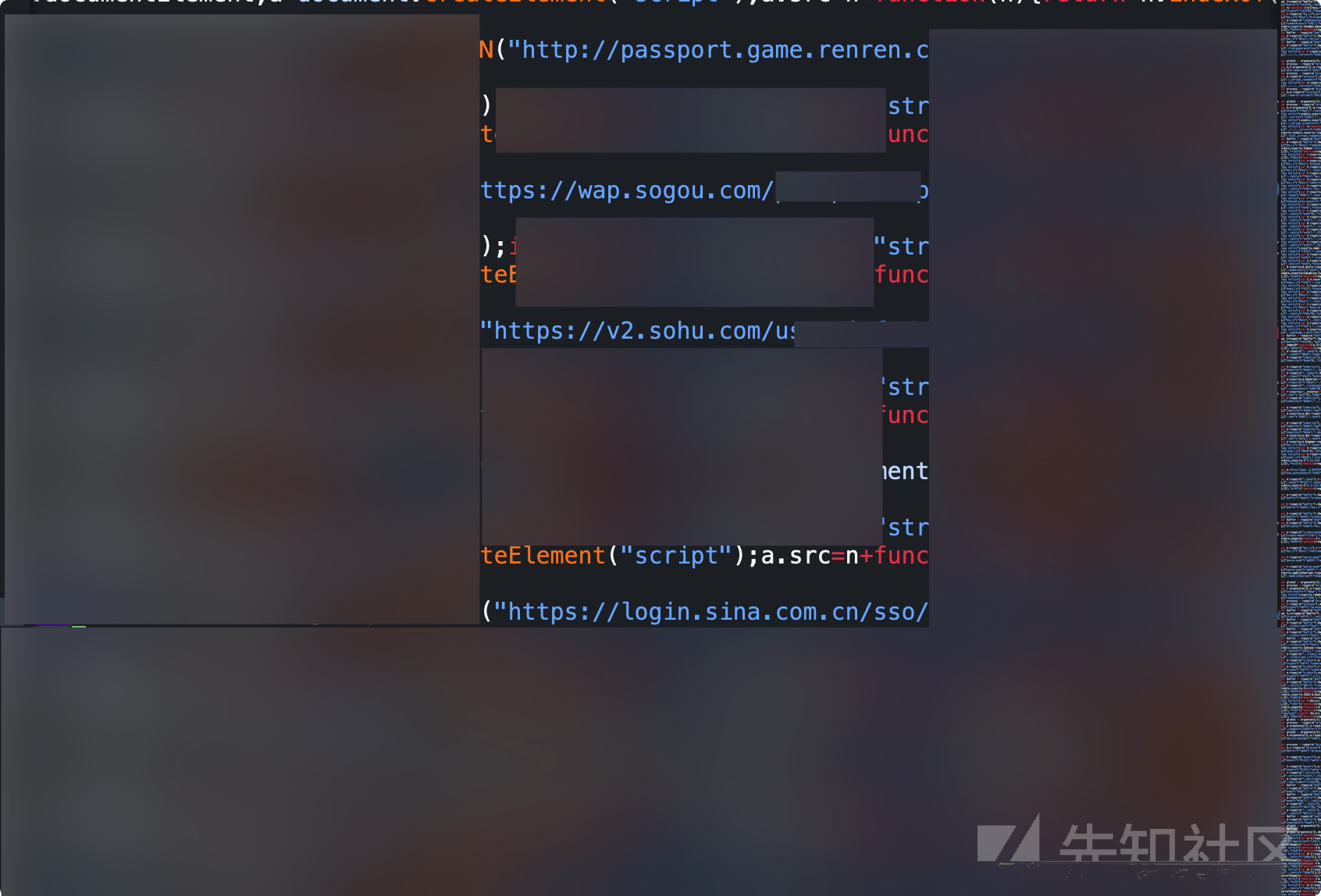
在配置蜜罐阶段的时候,其实就会将已经配置好的jsonp接口所生成的js文件(固定|动态)URL,插入到蜜罐中的静态文件里面.以此来达到只要你打开蜜罐网站,那么js将会自动加载并且执行调用所有jsonp接口的数据,然后将数据返回至后端.
下图为某蜜罐调用jsonp完成数据获取的部分截图:
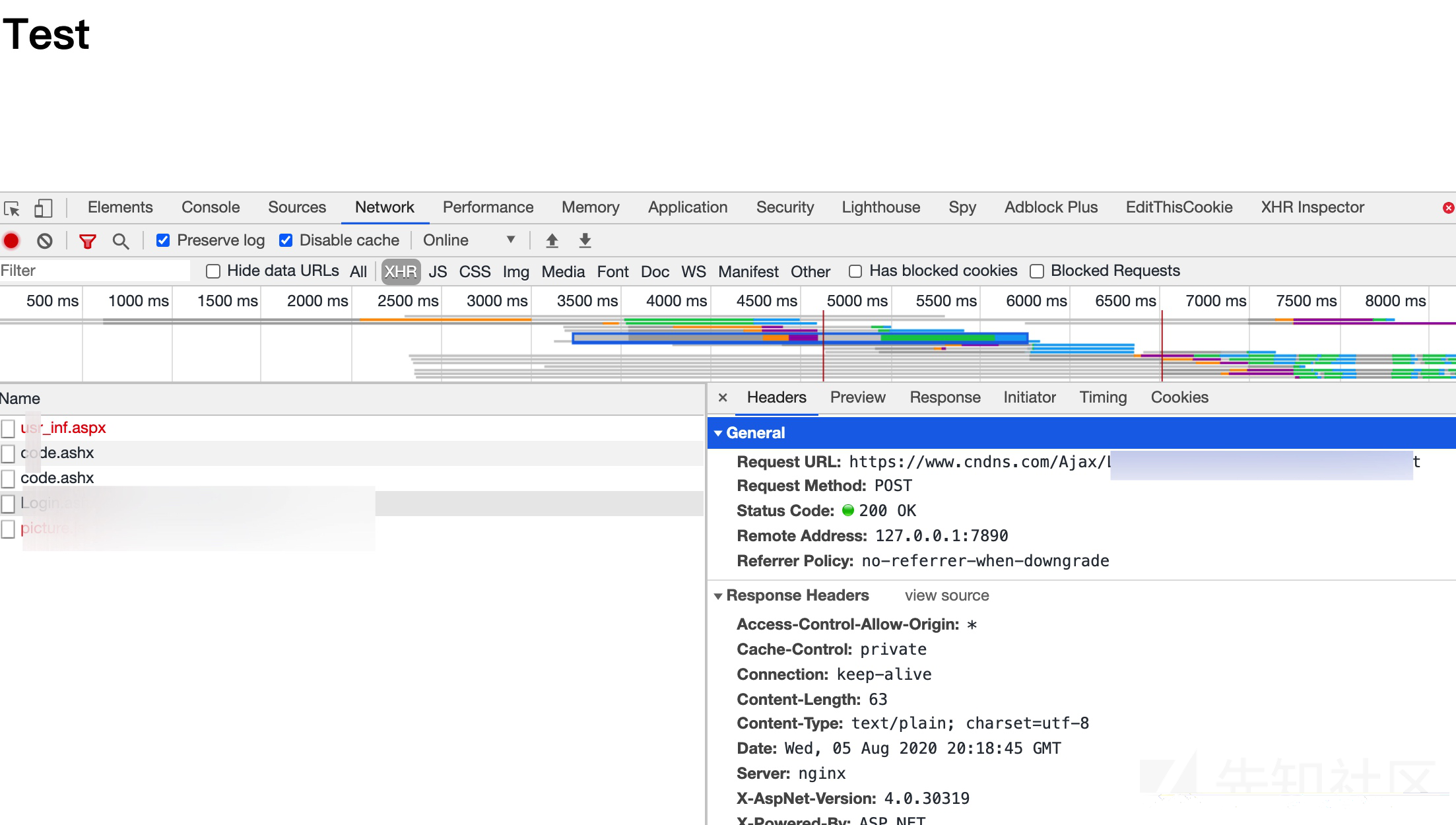
更多关于(商业)蜜罐的细节请参考各个商业蜜罐给出技术白皮书等信息.
0x02 插件实现
通过上文的概述,大家应该都大概简单的对此类蜜罐有了个大概的了解,那么针对以上这种类型的web蜜罐检查就很方便了,具体可以分为以下几个步骤:
- 打开网页
- 查看源代码
- 查找所有js文件
- 翻阅js文件是否有特征
如果以上4个步骤都是人工来执行,那么很多人在第一步的时候就已经中招了,你的信息已经被偷走了.当然可以直接跳到第二个步骤,不过也是很烦的一件事情.
对于浏览器插件有过使用或者编写过的小伙伴应该知道,浏览器的插件很多时候可以帮助我们完成很多事情,比如shodan的插件,在打开一个网站后可以自动去查询该网站的一些信息,那么我们也可以做一个类似的插件,但是除了要实现上述的4个功能点以外,还需要实现对于网页中发起请求的时候对请求的内容进行分析判断,如果判断出来为蜜罐js脚本,则阻断该js脚本加载的功能.以此来实现访问蜜罐,但是不会被偷取信息的功能.
首先要订阅一个json规则,结构如下:
{
"test111": [
{
"filename": "xss.min.js",
"content": "{{honeypotAny}}"
},
{
"filename": "xss2.min.js",
"content": "hello"
}
],
"test222": [
{
"filename": "{{honeypotAny}}",
"content": "word"
}
]
}上诉规则中,filename或者content的内容为{{honeypotAny}}为占位符,表示任意的意思,一般情况下写该js文件中存在的一些特征字符串来进行匹配.
在进行实际编写测试的时候,发现了一些小坑,如果该蜜罐在你访问之后才添加了该插件,或者第一次拦截以后再次访问,前端为了优化加载时间,将会从缓存中加载js文件,由此对浏览器所有缓存设置了个短时间内的缓存时间.
最终效果如下图所示:

插件部分核心如下:
var honeypotUrlCache = {};
var http = {};
var ruleStr = '{"test111":[{"filename":"xss.min.js","content":"hello"}],"test222":[{"filename":"main.js","content":"word"}]}'
var rule = JSON.parse(ruleStr);
// 给数组添加push2方法,用于向数组push不重复的数据
<………略………>
// XMLHttpRequest 请求方法包装
<………略………>
// 规则匹配,匹配成功将数据放入缓存
function checkForRule(url,content){
for(item in rule){
for(r1 in rule[item]){
if (rule[item][r1]["filename"] === '{{honeypotAny}}' && content.indexOf(rule[item][r1]["content"]) != -1){
honeypotUrlCache[url] = item;
return
}else if (url.indexOf(rule[item][r1]["filename"]) != -1){
if (rule[item][r1]["content"] === '{{honeypotAny}}') {
honeypotUrlCache[url] = item;
return
}else if (content.indexOf(rule[item][r1]["content"]) != -1) {
honeypotUrlCache[url] = item;
return
}
}
}
}
}
// 传入 URL 检查是否为蜜罐
function checkHoneypot(url){
let status = false
// 判断是否在历史检测出来中的缓存中存在
if (honeypotUrlCache.hasOwnProperty(url)) {
status = true
}else{
// 不存在就进行请求,然后解析内容用规则去匹配
http.get(url, function (err, result) {
checkForRule(url,result)
});
}
// 再次从缓存中检查
if (honeypotUrlCache.hasOwnProperty(url)) {
status = true
}
return status;
}
// 请求监听器
chrome.webRequest.onBeforeRequest.addListener(details => {
var t = (new Date()).getTime() - 1000;
chrome.browsingData.removeCache({
"since": t
},function(){})
if(details.type == 'script'){
if (checkHoneypot(details.url)) {
alert("蜜罐,快跑,当前蜜罐脚本已屏蔽!");
return {cancel: true};
}
}
}, {urls: ["<all_urls>"]}, ["blocking"]);0x03 思考
通过上述的插件我们实现了基于检测js文件内容的特征,来识别蜜罐以及拦截jsonp获取信息,那么我们考虑以下几个问题.
- 能否通过计算蜜罐特征文件的hash值进行匹配检测?
- 能否不基于检测js文件内容的特征,而是从本站向若干个外部网站同时或者短时间内发起请求进行检测?
- 如果遇到没有js文件,直接在html中使用script标签写入JavaScript内容进行调用jsonp的蜜罐如何检测?
- 如何针对非获取jsonp信息的蜜罐进行检测.
- ………………
其实引发的问题和思考有很多,归根到底就是如何反蜜罐,保证渗透过程中的隐蔽以及防止爆菊,本文仅仅是对使用jsonp获取信息的蜜罐进行了识别和检测,但是还是有一定的问题,如有的蜜罐在你访问的时候,蜜罐控制台就已经接收到了报警信息.
攻防无绝对,现在成熟的开源蜜罐以及商业越来越多,如果选择部署在内网,那么可以不仅限web蜜罐,也可以部署一些服务蜜罐,包括mysql、redis、docker等,综合下来一看,其实也可以成为一个防守方小型的被动式内网入侵感知平台.
那么攻击方在当前检测蜜罐方式资料很少的情况下,可能需要花费大量的时间去研究如何检测蜜罐,或者反日蜜罐.而且如果为商业蜜罐的情况下,可能只有以下几种途径来进行研究
- 实战中踩到了蜜罐,后知后觉被爆后去研究蜜罐的特征
- 给甲方做服务的期间顺便研究一发
- 小伙伴们直接的互相PY
- …………
0x04 项目地址
- github开源地址 AntiHoneypot-Chrome-simple
如有侵权请联系:admin#unsafe.sh