TL;DR: Bishop Fox has released raink, a command-line 2025-1-14 16:12:0 Author: bishopfox.com(查看原文) 阅读量:11 收藏
TL;DR: Bishop Fox has released raink, a command-line tool using a novel LLM-based listwise ranking algorithm.Originally showcased at RVASec 2024, raink solves complex ranking problems, including linking code diffs to security advisories.
In June 2024, Bishop Fox presented Patch Perfect: Harmonizing with LLMs to Find Security Vulns at RVASec where we showed how we use a novel LLM-based algorithm to associate code diffs in software patches with their corresponding security advisories in the context of N-day vulnerability analysis. Now, we’re open-sourcing Bishop Fox's new tool raink: an implementation of our listwise ranking algorithm as a command line tool.
This blog post will show how raink can be used to solve general ranking problems that are otherwise difficult for LLMs to process. We'll show raink works by illustrating its use in a relatively simple problem (ranking domains) and then we'll briefly close with suggested usage for vulnerability identification in a patch diffing scenario.
Rainking TLDs
AI can feel magical when you simply "throw a problem at it" (even without fully defining the problem constraints) and still get a meaningful result. For example: Which top-level domain (TLD) is the most math-y?
When I saw this post, I itched to automate my way to an answer. How do you determine whether a given term is math-related? Do you interpret the term strictly? Do you treat it as an acronym or initialism? And importantly, how do you decide if one term is more math-y than another? It's a fuzzy problem that feels like "I know it when I see it."
On a small scale, a normal interactive ChatGPT session works great for this. Here's a random sample of 10 TLDs I pulled from a DNS registrar. We can simply ask for an answer without addressing any of the nuance noted above:
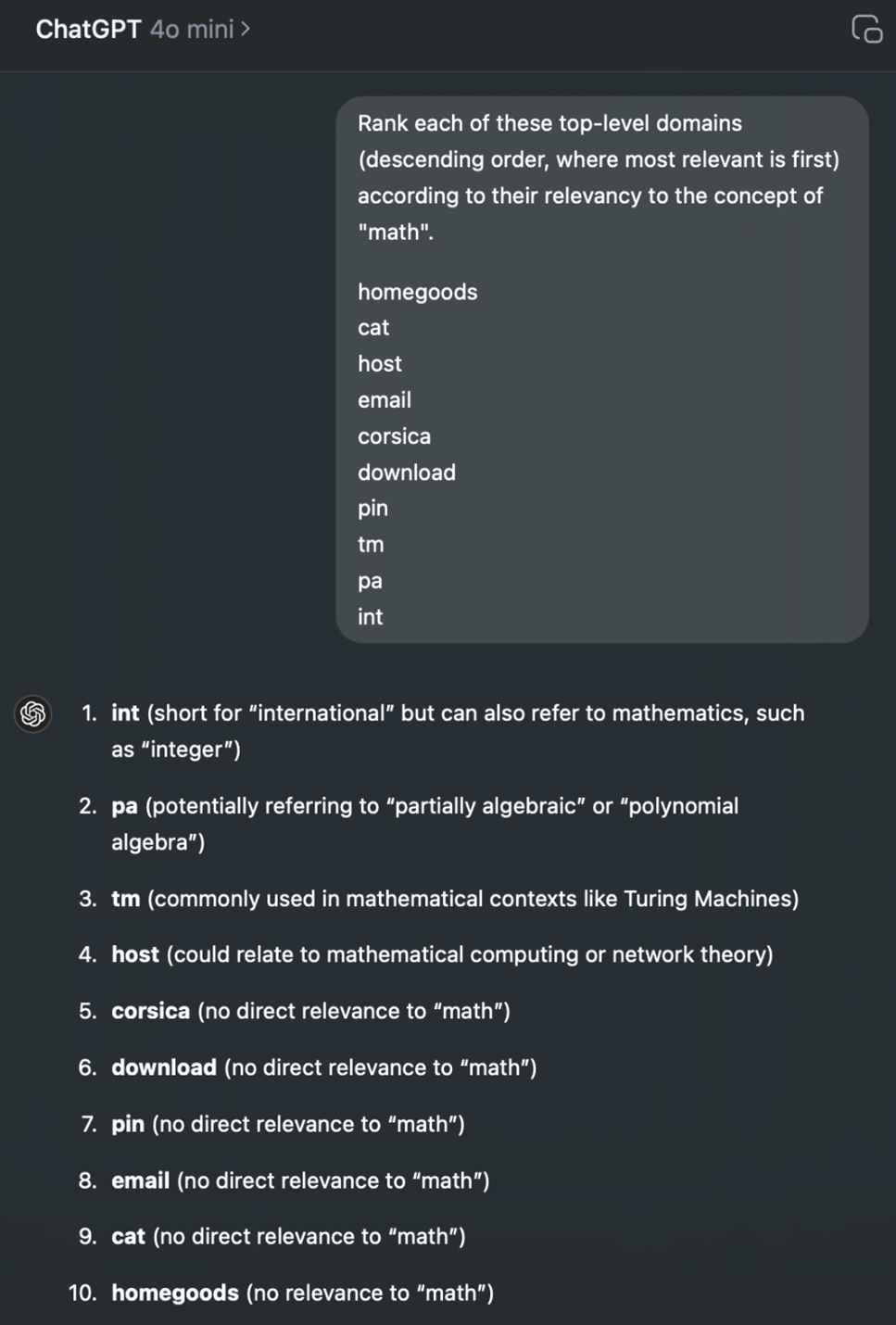
Results check out. I'd have picked "int" myself. Cool, let's drop in all 1445 available TLDs from IANA and get the math-iest one!
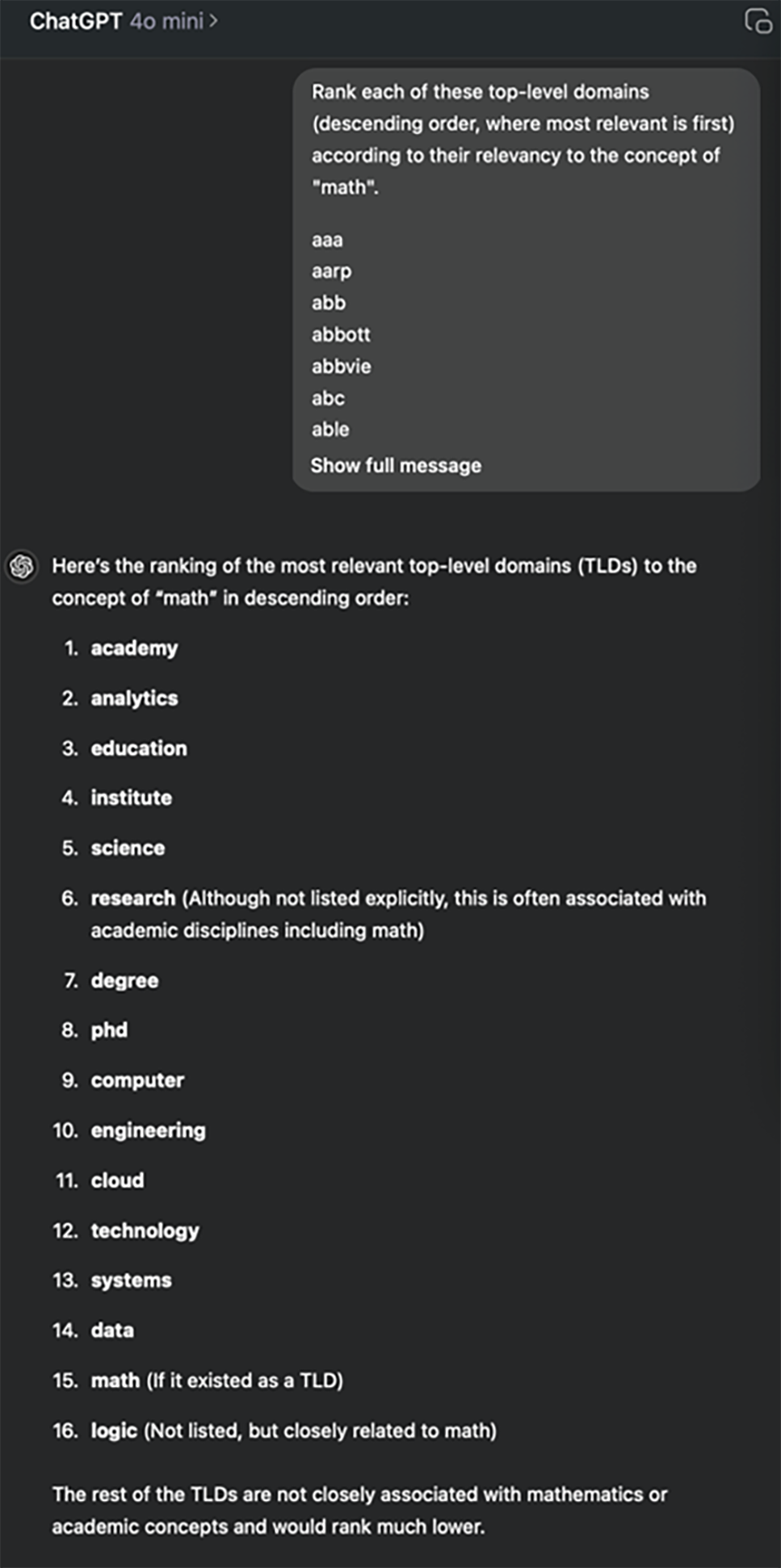
Okay, a few problems:
- ChatGPT admits that several results weren't actually in the original list. Appreciated but unhelpful.
- We only got 16 results. (The model resists further prompting for all results on the grounds that it "would be a very extensive process.")
We could try a more capable model or write a better prompt—but if you've used LLMs with any regularity, you'll know by experience that no matter what we try, we won't completely stop hallucinations or get the full original input list back. It seems that an LLM has a finite ability to "remember" all the data you've given it, and in some cases, you might provide more data than it can even fit in its context window:

No fear—we've got a computer science degree. Let's simply divide and conquer.
If we split up our large list of TLDs into multiple smaller lists, we can sort each one and then combine the results into a final sorted list, right? This sounds easy at first, but it gets tricky. Sorting a small list works fine as we initially proved—but how do we combine two sorted lists together? That is, how do we compare the top item from list A to the top item in list B since their rankings are only meaningful relative to the peers in their respective, separate lists?
We could try defining the problem a bit more clearly and give the LLM a prescribed scoring algorithm to produce a numerical "objective" score for each list item that can be deterministically sorted. I'll save you some time and report my experience with this approach: LLMs don't do particularly well at assigning scores. They tend to be inconsistent and also inflate the scores toward the upper end of whatever scale you're working with.
The TLD-R on Document Ranking
In the face of these challenges, let's be thankful that we're far from the first to tackle the problem of document ranking. A brief history:
- Google developed PageRank, one of the earliest algorithms for ranking, to determine the “importance” of web pages. It works by treating the internet as a giant graph where each link is a vote of confidence. Pages with more links—especially from other important pages—get higher scores. Simple and strictly numerical.
- Later came Learning to Rank (LTR), which builds on ideas like PageRank but adds machine learning to the mix. LTR uses training data to teach ML models how to rank items based on features like relevance or context. It introduced the concept of comparing items relatively
and generally uses one of three main approaches:
- Pointwise: Treats each item on its own, predicting a single “relevance score” for each. It’s similar to a basic classification problem: “How relevant is item X?” You then sort by these predicted scores.
- Pairwise: Compares two items at a time (“Is A better than B?”) and combines those outcomes into a full sorted list. This boils the ranking task down to simple, repeated yes/no choices but can be more time-intensive when comparing every possible pair.
- Listwise: Looks at a set of items all at once, trying to directly improve the final ordering in one shot. It can be more accurate but is harder to implement because it deals with the complexity of ranking the full list rather than individual items or pairs.
- Most recently, a 2024 paper (also by Google) introduced Pairwise Ranking Prompting (PRP) leveraging the power of LLMs. Instead of training models or assigning scores, PRP uses simple prompts to ask an LLM, “Which of these two is better?” This approach simplifies ranking tasks and achieves state-of-the-art performance using open-source models, showing that even moderately sized LLMs can outperform larger commercial alternatives like GPT-4 for ranking problems.
The PRP paper specifically address the challenges we've run into with our TLD ranking problem (these problems should sound familiar!). A few direct quotes edited for clarity:
- Pointwise relevance prediction requires the model to output calibrated pointwise predictions so that they can be used for comparisons in sorting. This is very difficult to achieve across prompts. (i.e., it’s hard for an LLM to generate a consistent objective score for a single item in isolation.)
- There are frequent prediction failures due to the difficulty of the listwise ranking task for LLMs, taking the following patterns:
- Missing: When LLMs only output a partial list of the input documents.
- Rejection: LLMs refuse to perform the ranking task and produce irrelevant outputs.
- Repetition: LLMs output the same document more than once.
- Inconsistency: The same list of documents have different output rankings when they are fed in with different order or context.
The PRP researchers opt for a pairwise approach for its simplicity and robustness (significantly reducing the task complexity for LLMs and resolving the calibration issue), while noting efficiency concerns since the pairwise approach is generally more computationally complex than either pointwise or listwise. Consider these two variants of PRP whose respective complexities O(N2) and O(N log N) both underperform listwise’s O(N):
- PRP-Allpair enumerates every possible pair of documents and prompts the LLM to decide which document in the pair is more relevant. Each document’s overall relevance score is its total “wins” in pairwise matchups. Although this can achieve high accuracy, it requires O(N2) LLM calls for N documents.
- PRP-Sorting uses standard sorting algorithms (like Heapsort or Quicksort), but replaces the usual “compare two items” step with an LLM-based comparator. Instead of comparing all pairs exhaustively, the algorithm only compares the pairs needed during sorting, leading to a more efficient O(N log N) complexity.

So, the pairwise approach works really well but takes a ton of LLM API calls. Could we reduce our LLM calls while still getting a result that's "good enough"?
Listwise or Bust
The listwise approach has potential, but we've got to solve a few issues. Let's introduce a few concepts to fix the problems outlined in the PRP paper:
- Batching: Break the original list into relatively small subsets that will fit in the context window and not overwhelm the model. This helps with the Missing and Rejection problems.
- Validation: Check the output from LLM calls and implement retries as needed. This helps with the Missing, Rejection, and Repetition problems.
- Repetition: Re-run the process multiple times on shuffled input, so each item is sufficiently compared against many other items (but not every other item, as in PRP-Allpair). This helps with the Inconsistency problem.
Here's how the algorithm of Bishop Fox's new raink tool works:
- Initial Batching and Ranking
- Shuffle all items.
- Divide them into small batches (e.g., groups of 10). Decrease the batch size until the batches safely fit within the context window (which can depend on the size of tokenized input items).
- Rank each batch individually to get a local ordering, while validating that the LLM call gave us back all the items that we put in (and retrying otherwise).
- Save each item's relative position in its batch to use as a numerical score.
- Repeated Passes
- Run step 1 (shuffle-batch-rank) multiple times (e.g., 10 passes).
- Average each item's relative position from each pass to form an initial ranking.
- Refinement
- Select the top portion (e.g., the upper half) based on the current ranking.
- Repeat steps 1 and 2 (multi-pass shuffle-batch-rank) on this upper subset.
- Continue refining recursively until you isolate the top item.
- Rebuild the Full List
- Merge your refined ordering with the rest of the items, producing the final sorted list.
The three primary arguments to the algorithm are:
- Batch size: How many items can fit in a batch
- Pass number: How many times to repeat shuffle-batch-rank
- Refinement ratio: How large of an upper section to recursively refine
The refinement step helps ensure that we’re spending our energy well—i.e., more aggressively comparing the items that appear most relevant, rather than performing a full pairwise comparison of every item to every other item. LLM calls can also be made in parallel for each pass of shuffle-batch-rank.
To The Test
With a batch size of 10 items, using 10 repeated passes, while recursively refining the upper half of the list, we get a ranked list in under 2 minutes using GPT-4o mini.
raink -f tlds-iana.lst -r 10 -s 10 -p 'Rank each of these top-level domains (descending order, where most relevant is first) according to their relevancy to the concept of "math".'
Here are the top 5% math-iest TLDs according to raink:
1 edu 11 analytics 21 int 31 accountants 2 university 12 degree 22 iq 32 id 3 academy 13 prime 23 ma 33 accountant 4 education 14 cal 24 zero 34 guru 5 school 15 mm 25 mu 35 py 6 institute 16 mt 26 scholarships 36 science 7 mit 17 college 27 financial 37 plus 8 courses 18 solutions 28 training 38 technology 9 phd 19 study 29 ieee 39 expert 10 engineering 20 data 30 engineer 40 foundation
Hard to argue with “edu” as a math-related TLD. You can pick up on this model’s bias: some of the top results lean heavy on math as an academic concept, with applied concepts (accountants, etc.) coming in a bit lower in the list. We can tune the prompt very easily with more direction for our LLM comparator if needed, but for a first pass it clearly works as intended.
For Vulnerability Identification
We’ve shown that raink can be used to sort a list of objects with regard to how closely they relate to some given topic. Instead of TLDs that relate to the concept of math, consider that we could feed in functions that changed in a software patch and try to find which ones most closely relate to a given security advisory. Or perhaps ranking Semgrep results in terms of which seem most impactful for an analyst to investigate.
To apply raink for vulnerability identification while patch diffing: we can pass in the text from a recent security advisory, along with the list of code changes generated from a Ghidriff patch diff, and ask it to rank the changed functions that are most likely related to the issue described in the advisory:
raink -f code-diffs.jsonl -r 20 -s 3 -p "$(echo -e "Which of these code diffs most likely fixes the issue described in following security advisory?\n\n```\n$(cat advisory.txt)\n```\nNote the following truncated strings diff (noting any that may relate to the given CWE type):\n\n$(cat strings.txt)\n\nHere are the code diffs:\n\n")"
After five consecutive runs in the above configuration, raink is able to successfully identify the fixed function:
- As the top-ranked item, 60% of the time (3/5 times).
- Within the top 7% ranked items, on average.
We see a lot of potential for efficiency gain among offensive security engineers using raink in this manner; we'll save detailed results on patch diffing for a future blog post. In the meantime, download raink on GitHub, and check out our talk Patch Perfect for some of the successes we’ve had applying LLMs to N-day vulnerability identification.
Subscribe to Bishop Fox's Security Blog
Be first to learn about latest tools, advisories, and findings.
如有侵权请联系:admin#unsafe.sh