2024-11-21 17:14:0 Author: mp.weixin.qq.com(查看原文) 阅读量:0 收藏
今天分享我实验室白泽智能团队(Whizard AI)的最新研究 Neural Dehydration: Effective Erasure of Black-box Watermarks from DNNswith Limited Data,该工作提出了一种与水印类型无关的通用移除攻击,成功破解了当下10款主流的黑盒模型水印,在保持目标模型可用性的同时,对数据的依赖性也极低(例如只需要使用2%的训练数据),甚至在完全零数据的场景下也能实现水印移除。目前该工作已被网络安全领域顶级会议 ACM Conference on Computer and Communications Security (CCS) 2024 录用。
DNN黑盒水印
近年来,深度神经网络(DNN)得到了广泛应用。然而,构建一个强有力的DNN往往需要海量数据和强大算力的支持。一旦这些模型发生泄露或者被窃取,则会给模型拥有者带来巨大的经济损失。为此,如何保护DNN的知识产权,成为近年来广泛研究的课题。
除了参数加密、结构混淆等主动式防御手段之外,近期兴起的另一类响应式手段是向模型添加水印,即:模型所有者在不影响模型功能的前提下,向模型中嵌入一个唯一的水印信息;当发生版权纠纷时,所有者可以从可疑模型中提取水印信息以验证产权所属。
根据验证阶段对可疑模型的访问权限,现有的DNN模型水印可以分为白盒水印与黑盒水印两大类。白盒水印将水印信息嵌入至模型参数,后续通过白盒参数提取水印并进行验证。黑盒水印则通过模型学习特定的“输入-输出”关联,只需通过黑盒访问发送特定样本以验证输出,即可验证所有权。相较于白盒水印,黑盒水印的灵活度更高,适用场景更广泛,更利于所有者验证版权。本文便是围绕黑盒水印的实际鲁棒性展开研究。
现有攻击的局限性
黑盒模型水印容易遭受移除攻击(removal attacks)的威胁。具体而言,攻击者在获取含水印的预训练模型后,可以通过修改模型参数等方法,破坏模型内部的水印信息,从而得到一个躲避水印验证的代理模型。
现有的移除攻击包括剪枝、微调、遗忘等形式。然而,如论文Table 1所示,作者发现它们并不能对水印构成实际威胁:现有攻击往往只能有效移除一小部分水印,且攻击成本巨大,它们会极大地损害模型的性能(如剪枝和微调),抑或依赖于数据集、对目标水印的先验知识(如微调和遗忘),这并不符合现实的攻击条件。
Dehydra攻击
现有的黑盒水印机制往往依赖于模型过参数化(over-parameterization)的性质,去特别地记忆一批水印样本到目标标签的映射。针对这点观测,作者尝试利用模型内部的信息去恢复并遗忘潜在的水印,类似于化学中的脱水反应(dehydration reaction)。
具体地,作者设计了一个两阶段的通用攻击框架:在水印恢复阶段,通过模型反演技术,对目标水印模型进行逐类逆向,恢复出接近真实水印数据的样本;在水印遗忘阶段,通过微调来故意遗忘这些“水印”样本,从而破坏模型内部水印信息,实现水印的有效移除。整体攻击流程如论文Fig.2上半部分所示。
为了保持模型的可用性,并进一步降低数据依赖,作者还提出了目标类别检测和逆向样本切分这两种改进方案,以进一步优化攻击流程,如论文Fig.2下半部分所示。
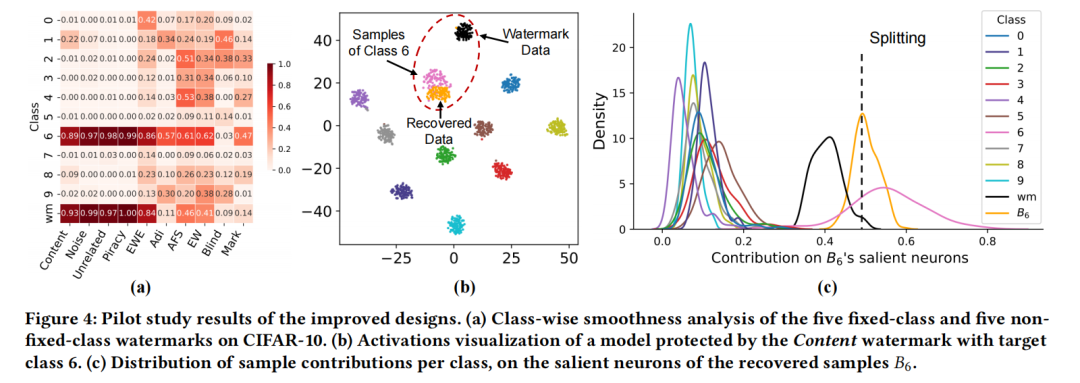
目标类别检测用于区分潜在水印是否具有固定的目标类别,若是,则进一步检测其目标类别。该方案基于的洞察是由固定类水印植入引发的标签平滑度差异:由于水印样本通常为分布外样本,且在训练过程中频繁采样,因此作者推测,对于固定类别的水印,模型的损失表面在目标类样本处比在其他类样本处更为平滑。基于这一洞察,作者先进行了预实验,通过评估不同水印模型在不同类别样本的平滑度SmoothAcc,验证了目标类别在平滑度上的显著优势,如论文Fig.4(a)所示。于是,作者可以通过评估每个类别逆向样本的SmoothAcc,并利用top-2类别之间的SmoothAcc差距来检测水印类型以及潜在的目标类别。这一改进可以有针对性地对固定类别的水印进行更有效的移除,同时减少对模型正常性能的影响。
逆向样本切分可以将逆向的样本切分为代理水印样本和代理正常样本,并相应地改进水印遗忘的微调过程。该方案基于的洞察是正常样本的主导现象,即逐类逆向样本应该比该类的水印样本更接近正常样本。在预实验中,作者将水印模型的神经元激活进行可视化,如论文Fig.4(b)所示,发现逆向恢复的样本(橙色簇)比真实水印样本(黑色簇)更接近目标类别的正常样本(粉色簇)。基于这一发现,作者提出了一种神经元级别的切分标准:对于每个类别,提取显著神经元,并选择贡献值最大的子集作为代理正常数据,其余作为代理水印数据。基于这一切分,可以在后续微调过程中,使用代理正常数据以保持模型的原始性能,同时使用代理水印数据来遗忘水印信息。这一改进使得Dehydra攻击能够在零数据场景下,仅依赖恢复和切分得到的代理水印数据,就能实现水印的移除。
实验:攻击效果
在10种主流DNN水印(包括固定类别和非固定类别)上的实验证明了Dehydra攻击的有效性。如下图所示,在只使用2%干净训练数据集的场景下,Dehydra攻击可以在几乎不影响模型可用性的情况下(实心柱),有效移除水印信息(纹理柱)。
此外,作者也在少量迁移数据,以及完全零数据的两个场景下进行了评测,同样验证了Dehydra的有效性与实用性。
结语
本文提出了Dehydra这种与水印类型无关的水印移除攻击,它能同时保持攻击有效性和模型可用性,且在低数据依赖甚至零数据的情况下也能移除水印。这篇工作揭示了现有黑盒模型水印的现实鲁棒性仍有缺陷,为未来的水印技术研究提供了新的挑战和改进方向。
团队简介
白泽智能团队负责人为张谧教授。团队主要研究方向为AI安全、模型安全,在S&P、USENIX Security、CCS、TPAMI、ICML、NeurIPS、KDD等网络安全和AI领域国际顶会顶刊已发表论文30余篇。
张谧教授个人主页:https://mi-zhang-fdu.github.io/index.chn.html
白泽智能团队(Whizard AI):https://whitzard-ai.github.io/
撰稿:陈沛仪,陆逸凡
排版:高泽晨
责编:邬梦莹
审核:张琬琪,洪赓,潘旭东,林楚乔
复旦白泽战队
一个有情怀的安全团队
还没有关注复旦白泽战队?
公众号、知乎、微博搜索:复旦白泽战队也能找到我们哦~
如有侵权请联系:admin#unsafe.sh