The artificial intelligence landscape is undergoing a seismic shift. While text-based Large Language Models (LLMs) have dominated headlines and captured our imagination, a new paradigm is emerging that promises to revolutionize how we interact with AI: multimodal artificial intelligence. This evolution marks a fundamental change in how machines process and understand our world.
The Natural Evolution: From Text to Multiple Modalities
Humans don't communicate solely through text – we interpret facial expressions, analyze tone of voice, and process visual information simultaneously. This multifaceted approach to communication is what makes human interaction so rich and nuanced. Now, AI is following suit, evolving beyond the constraints of text-only models to embrace a more holistic approach to understanding and generating content.
Multimodal AI systems can process and generate multiple forms of data – text, images, audio, video, and documents – in unified models that more closely mirror human cognitive processes. We're already seeing impressive demonstrations of this technology, from foundational models that can generate videos or short films from written descriptions such as Meta’s Movie Gen, Pika Labs, or Runway’s Gen-3 Alpha, to platforms capable of real-time voice conversations that understand both words and emotional undertones like OpenAI’s GPT-4o. These developments aren't just technical achievements – they're reshaping how we think about artificial intelligence and its capabilities.
Multimodal AI Potential to Transforming Industries
The potential applications of multimodal AI are vast and transformative. In healthcare, systems that can simultaneously analyze medical images, patient voice recordings, and clinical documentation could revolutionize diagnostic processes. Early research shows promising results in detecting cognitive conditions like Alzheimer's disease
Multimodal AI has the potential to
The creative industry stands to benefit significantly as well. Content creators can now envision AI platforms that generate coordinated audio-visual experiences from simple text descriptions. Film production workflows could be streamlined with AI-generated b-roll footage, while virtual assistants could become more empathetic by understanding not just words, but tone and facial expressions.
The Data Challenge: Managing Multimodal Complexity
However, the journey toward truly effective multimodal AI isn't without its hurdles. The primary challenge lies in data management – specifically, the need for diverse, high-quality datasets that span multiple modalities. While traditional LLMs could rely on text sources like Wikipedia and books, multimodal systems require a much broader spectrum of data, including podcasts, videos, medical imaging, and even biometric data from wearable devices.
This expanded data requirement introduces new complexities in data quality control. Poor-quality inputs in any modality can compromise the entire system's performance. For instance, mislabeled video data might confuse visual recognition capabilities, while degraded audio could impair speech recognition accuracy. The old programming adage "garbage in, garbage out" takes on new significance in the multimodal era.\
Introducing Encord - the multimodal data development platform
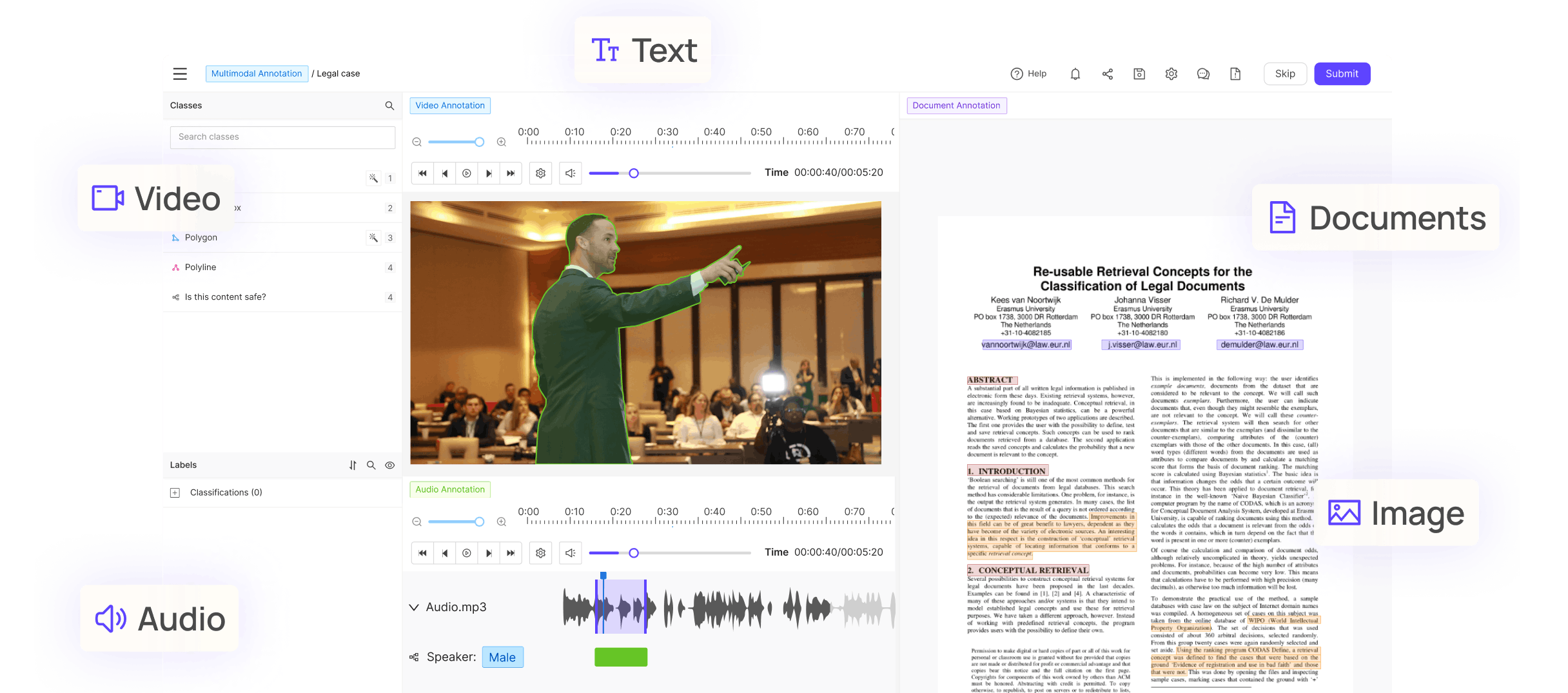
As the industry evolves, new platforms are emerging to address the unique challenges of multimodal AI development. At Encord, we're excited to announce our contribution to this revolution by launching a truly multimodal AI data development platform that enables teams to manage, curate, and label multiple data types within a single unified interface.
Our platform addresses one of the most significant pain points in multimodal AI development: the fragmentation of data preparation workflows. Instead of juggling multiple tools for different data types, teams can now handle images, videos, audio files, documents, and DICOM files in one seamless environment. This consolidation significantly reduces development time and improves data quality consistency.

A standout feature is our multimodal annotation and workflow orchestration capability, which allows teams to view and annotate multiple file types simultaneously, all in one platform. This unlocks a variety of use cases that previously were only possible through cumbersome workarounds. A few of these include analyzing PDF reports alongside images, videos, or DICOM files to improve the accuracy and efficiency of annotation workflows by empowering labelers with extreme context. The platform also supports human-in-the-loop workflows and natively integrates with state-of-the-art models like SAM for automated labeling, making it ideal for both traditional AI development and emerging applications like RLHF (Reinforcement Learning from Human Feedback) for generative AI.
The Road Ahead
The transition to multimodal AI represents more than just a technological advancement – it's a fundamental shift in how we think about artificial intelligence. As these systems become more sophisticated in processing multiple data streams simultaneously, they move us closer to achieving more general forms of artificial intelligence that can understand and interact with the world in ways that feel more natural and human-like.
However, success in this new era will depend heavily on our ability to manage and curate diverse data types effectively. Organizations that invest in robust data infrastructure and adopt comprehensive multimodal development platforms will be best positioned to capitalize on these emerging opportunities.
The future of AI is multimodal, and it's arriving faster than many might have anticipated. Organizations that invest in robust data infrastructure and adopt comprehensive multimodal development platforms will be best positioned to capitalize on these emerging opportunities. How about you and your AI team - are you ready?
如有侵权请联系:admin#unsafe.sh