
作者:果胜
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]
在IoT,云计算,基于容器的弹性计算大量铺开的趋势面前,目前的信息资产和相关漏洞出现了爆炸式的增长。基于人工的告警响应-审计已经不可能满足安全防御的需要。由于必须将有限的资源和工时向易于受到攻击的薄弱环节集中。当前的安全工作已经开始逐步向情报驱动的智能安全发展。同时,对于红队和渗透测试人员来说,获取更多的漏洞情报,将自己的基础设施和工具链条隐藏在已知威胁情报之外也是提高行动成功率的重要措施。故而具备更强的威胁情报和反情报能力是攻防活动中的一个重点。
在当前的安全市场中,国内外都已经出现了大量的威胁情报平台和软件供应商,整个市场已经颇为繁荣。但是在实际的安全工作中,威胁情报的应用仍然存在很多困难,许多产品难以快速的转化为实际工作中的生产力,而往往只具备酷炫的面板。目前的实践中,国内许多中小型企业直接放弃了威胁情报在安全中的应用,而大型互联网公司则更倾向于自建威胁情报运营平台。这实际上也指向了一个结论:如果不能在本地结合自身业务对互联网威胁情报平台的海量数据进行提取,则威胁情报的对安全工作的指导意义会大幅下降。
具体来说,威胁情报的本地生产主要包含以下内容:
-
获取与自身资产相关的IOC(hash,ip,url....)
互联网上有海量的IOC信息,但是其中绝大多数都与实际面临的威胁无关,在本地生产威胁情报的第一步在于通过将安全设备中的告警信息(或其他渠道获取的信息,如社交媒体,SRC等)汇总,并提炼其中的IOC指标,这些IOC将作为安全人员生产威胁情报的原始材料 -
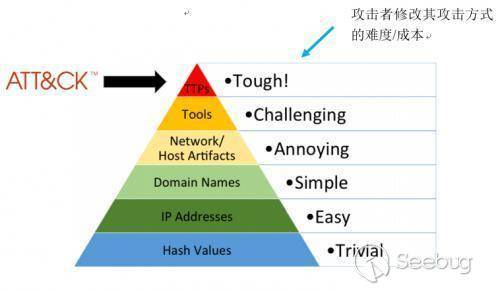
基于痛苦金字塔(Pyramid of Pain)逐步扩张IOC
痛苦金字塔是一个用于描述IOC价值的模型,该模型以从塔基到塔尖的形式,表现了IOC指标的价值高低。一般情况下,安全分析的初始阶段只能获得ip地址一类较低价值的IOC指标,并通过人工或自动分析系统(如沙箱)逐步丰富作为原始材料的IOC信息,获取更多关联的IOC指标
- 基于标准分享格式(MISP/STIX等)集成威胁情报
目前已经存在MISP,STIX等多个威胁情报共享标准,最终的威胁情报信息可以转换为此类标准导入MISP等威胁情报平台进入流通环节。
当前已经存在大量开源的威胁情报工具,github提供了一个很好的源对此进行汇总,如下:
https://github.com/hslatman/awesome-threat-intelligence
但是目前大部分的开源工具的水平距离商业平台仍有较大差距,只能满足某一特定步骤的情报收集和处理,故而开源工具+少量开发是较为合理的轻量级方案,一般使用于以下情况:
- 资源有限的组织和企业(例如一个人的安全部)
- 独立的安全研究人员(威胁猎人/威胁情报奖励计划参与者等)
- 红队的威胁情报采集人员
在此处使用threatingestor+cortex做一个演示
-
threatingestor
threatingestor是inquest实验室推出的一个威胁情报采集框架,该框架可以从社交媒体,消息队列,博客,自定义插件等渠道采集可用于威胁情报的IOC信息,并以编排剧本的方式灵活的配置采集和处理信息的具体步骤 -
cortex
cortex是大名鼎鼎的开源威胁情报分析平台thehive项目的组成部分,该项目作为thehive平台的后端分析引擎,可以自动的对IOC信息进行处理分析,方便安全分析人员实施其工作。目前cortex比主项目thehive具有更好的API SDK和文档支持,更加方便与第三方代码集成。如已经与thehive有很完善的对接方案,也可以考虑通过thehive调用cortex分析IOC。
目前官方提供了docker镜像方便快速的搭建cortex引擎及其依赖环境,docker-compose.yml文件如下:
version: "2"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.0
environment:
- http.host=0.0.0.0
- transport.host=0.0.0.0
- xpack.security.enabled=false
- cluster.name=hive
- script.inline=true
- thread_pool.index.queue_size=100000
- thread_pool.search.queue_size=100000
- thread_pool.bulk.queue_size=100000
cortex:
image: thehiveproject/cortex:latest
depends_on:
- elasticsearch
ports:
- "0.0.0.0:9001:9001"使用docker-compose up命令即可安装和启动环境,之后访问 http://127.0.0.1
:9001 更新数据库之后即可进入登录页面:

在建立非admin帐号后使用新账户重新登录,开始配置分析器。在账户的Analyzers选项卡下配置和启动任务所需的分析器,如图:
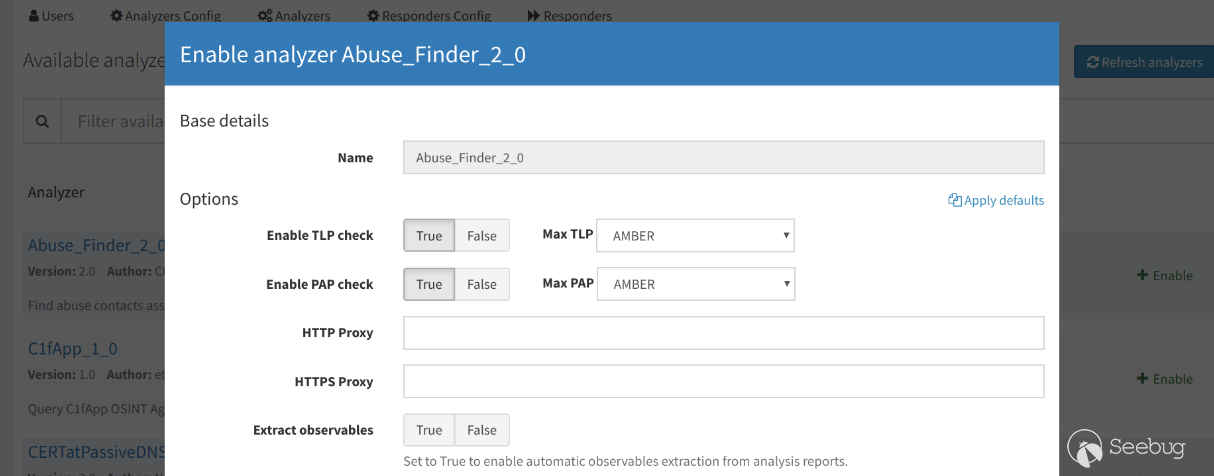
配置成功后即可在New Analysis下建立分析任务,或使用为账户生成的API KEY调用API进行分析任务。
备注:
主项目thehive提供的官方docker-compose.yml文件无法正常的启动,由于主项目thehive连接cortex需要提供可用的apikey,故通过docker-compose启动的环境thehive将无法正常连接cortex,需人工在cortex中生成key之后修改thehive容器内的配置文件并重启服务,或者将apikey作为手工启动thehive容器的参数才可以正常使用平台
thehive项目官方提供了cortex4py作为cortex平台的客户端SDK,基于该SDK和轻量级消息队列beanstalkd可以建立一个自动化分析服务,概念代码如下:
python
import json
import greenstalk
from cortex4py.api import Api
from cortex4py.query import *
#连接cortex
api = Api('http://127.0.0.1:9001', '**APIKEY**')
def analyzeIOC(ipaddress):
# 获取可用的ip分析器
ip_analyzers = api.analyzers.get_by_type('ip')
jobs = []
# 执行分析器
for analyzer in ip_analyzers:
job = api.analyzers.run_by_name(analyzer.name, {
'data': ipaddress,
'dataType': 'ip',
'tlp': 1,
'message': 'honeypot',
}, force=1)
jobs.append(job)
count = 0
while True:
#等待所有任务执行完毕(成功或失败)
for job in jobs:
if api.jobs.get_by_id(job.id).status == 'Success':
count = count + 1
elif api.jobs.get_by_id(job.id).status == 'Failure':
count = count + 1
else:
pass
if count == len(jobs):
break
else:
count = 0
results = []
for job in jobs:
#获取分析结果
report = api.jobs.get_report(job.id).report)
results.append(report.get('full', {}))
return results
# 待分析任务消息队列
task_queue = greenstalk.Client('127.0.0.1', 11300,watch='cortex-task')
# 分析结果消息队列
result_queue = greenstalk.Client('127.0.0.1', 11300,use='cortex-result')
while True:
#读取消息队列中等待分析的ip
job = task_queue.reserve()
task_queue.delete(job)
#开始分析任务
results = analyzeIOC(json.loads(job.body)["ip"])
for result in results:
#将结果写入消息队列
result_queue.put(json.dumps({'data':str(result)}))通过该样例服务,即可从消息队列中读取蜜罐等安全设备或其他来源采集到的IOC,并将其提交到cortex。由cortex平台的插件自动化的通过shodan/virustotal/Robext等多种OSINT技术丰富ip地址等较低价值的IOC,并将这些OSINT平台的数据采集结果写入到结果消息队列中,通过后续步骤提取DOMAIN/URL等更高级的IOC,完成痛苦金字塔的攀爬。
为了在本地自动化生产威胁情报,我们需要通过threatingestor建立一个自动化的工作流。threatingestor是一个易于配置和扩展的框架,可以通过配置文件快速自定义一个任意的工作流,可以设计一个如下的工作流:
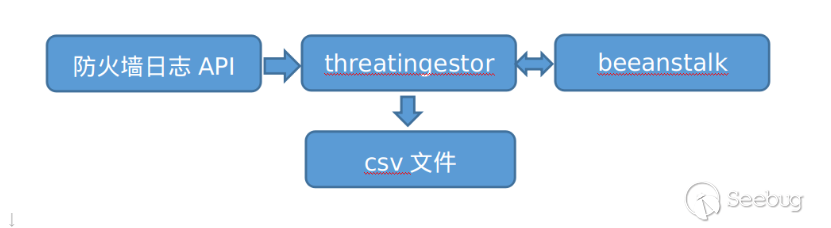
即防火墙日志->通过thretingestor提取IOC写入beanstalk->通过自定义服务使用cortex丰富IOC->将结果写入消息队列->通过thretingestor分析OSINT结果并写入csv文件。实现这个工作流的配置文件如下:
general:
#基本配置
daemon: true
sleep: 3600 #每3600s执行一次采集任务
state_path: state.db
sources:
#通过firewall采集IOC
#web模块通过http协议采集数据并自动提取IOC
- name: firewall_source
module: web
url: http://172.17.0.3:9001/api/v1/get/data?key=********
#从beanstalk消息队列读取cortex平台采集的结果
#通过OSINT丰富IOC
- name: cortex-result
module: beanstalk
paths: [data]
host: 127.0.0.1
port: 11300
queue_name: cortex-result
operators:
#制定处理cortex-result插件采集的IOC
#将结果写入csv文件中
- name: csv
module: csv
allowed_sources: [cortex-result]
filename: output.csv
#读取firewall提供的IOC并写入消息队列中
- name: cortex-task
module: beanstalk
host: 127.0.0.1
port: 11300
queue_name: cortex-task
allowed_sources: [firewall_source]
filter: is_ip #只允许ip类的IOC进入下一步流程
ip: {ipaddress}运行
threatingestor test.yml
即可使得threatingestor驱动起预先设计的工作流,部分结果如下:
IPAddress,116.*.*.186,...
Hash,0636e1e6dd371760aeaf808ed839236e73a9e74d,...
URL,http://***.xyz/,... Domain,***.xyz,...
可见整个采集-分析-存储流程被自动化完成,cortex平台挖掘出的IOC可用于生成安全规则或用于更多的安全分析
写作本文的目的是抛砖引玉,即证明通过开源工具建立一个轻量级的自动化威胁情报生产方案是可能的。实际上还有很多可扩展的玩法,例如基于CuckooSandbox API自动化分析蜜罐样本,基于networkX自动绘制IOC的关联关系等,限于篇幅在此不详细叙述。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1210/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1210/