2024-11-5 19:57:0 Author: mp.weixin.qq.com(查看原文) 阅读量:3 收藏
原文标题:F-ACCUMUL: A Protocol Fingerprint and Accumulative Payload Length Sample-Based Tor-Snowflake Traffic-Identifying Framework
原文作者:Junqiang Chen, Guang Cheng, Hantao Mei
原文链接:https://doi.org/10.3390/app13010622
发表会议/期刊:Appl.Sci.
笔记作者:宋坤书@安全学术圈
1、背景介绍
随着互联网用户对隐私问题的日益关注,多种匿名技术被用于实现匿名访问,Tor是目前最流行的匿名通信系统,被广泛用于保护用户隐私。Tor还提供了隐藏服务(Hidden Service,HS),使用多跳反向代理或资源共享存储技术为网络的服务端提供匿名保护。高度的匿名性为一些非法活动提供了滋生的温床,也给网络监管带来了极大的障碍。为了应对Tor的负面影响,研究人员开始大量使用流量分析来判断用户是否正在连接Tor或者正在访问什么服务,这已经成为Tor去匿名化最有潜力的方法之一。同时,网站指纹(Website Fingerprint,WF)也是Tor流量分析的重要分支。
流量分析给Tor的匿名性带来了巨大的威胁;因此,Tor开发了一些对抗审查的PT工具来帮助人们抵御Tor网络中的流量攻击。Tor引入了许多集成可插拔传输(Pluggable Transport,PT)技术,包括Obfs4、Meek等。用户可以混淆自己的流量并秘密连接到Tor,从而绕过审查。基于WebRTC技术的 Snowflake是PT的最新版本,它可以在Tor客户端和Tor网络之间建立加密连接,目前很少有研究人员对其进行研究。WebRTC是一种先进的开源协议框架,被广泛用于在浏览器之间建立多媒体传输隧道,这是一种点对点的实时通信。WebRTC广泛应用于许多实时通信应用程序,因此审查无法通过阻止WebRTC通信实例来阻止Snowflake。
目前的研究更多地集中在Tor流量的识别和分类上,而不是Tor PT流量。随着网络审查能力的提高,越来越多的用户选择使用Tor PT进行匿名通信,对Tor PT的研究将是未来的一个趋势。之前的工作为Tor流量的研究提供了方向和参考,但由于Tor-Snowflake的发展和变化,现有的一些方法已经不再适用。部分研究通过密钥消息序列识别Tor PT下的隐藏服务访问行为,但密钥消息的起始和结束位置难以确定,会显著影响识别的有效性。本文以新兴的Tor-Snowflake PT为研究对象,因为对其流量识别和隐藏业务流量的识别研究较少。
2、Motivation
Snowflake通过WebRTC数据传输通道传输流量,采用UDP作为传输层框架协议。作为一种规避审查的新兴PT技术,Snowflake被越来越多的用户使用,但对其流量识别的研究却很少。由于Snowflake基于UDP协议进行数据传输,而其他流行的Tor PT如Obfs4、Meek等基于TCP进行数据传输,现有的针对Obfs4和Meek的流量识别方法大多不适用于Snowflake。另外,Snowflake依赖WebRTC协议框架进行通信线路构建,产生的流量会很大程度上与其他基于WebRTC的应用混淆,给监管带来极大挑战。本文对Snowflake协议进行分析,提出一种基于规则匹配和DTLS握手指纹特征的Tor-Snowflake流量识别框架。通过该框架可以识别用户是否正在使用Snowflake访问Tor,还可以确定用户是否正在使用Snowflake访问HS。
3、Snowflake协议的通信原理
可插拔传输(PT)技术可以通过加密填充、域前置或隧道技术将Tor流量混淆为后台流量。Snowflake是基于WebRTC的Tor PT,建立在Flashproxy的基础上,它的通信过程中也包括域前置。Snowflake的基础是在对等体之间建立WebRTC连接,并通过审查区域外的自愿浏览器向Tor网络发送访问请求。Snowflake所依赖的核心技术WebRTC是一个支持浏览器之间点对点连接的Web框架和协议套件。本文通过两个方面来介绍Snowflake的通信原理:Snowflake的通信过程和基于UDP的加密传输协议DTLS。
3.1 Snowflake通信过程
Snowflake由三个主要部分组成:Snowflake客户端(Client)、Snowflake代理(Proxy)和中间人(Broker)。Snowflake使用这些组件来协商通信,并建立WebRTC连接,以隐藏和转发到Tor网络的流量。Snowflake的通信过程可以分为三个主要阶段:准备阶段、会合阶段和WebRTC连接建立阶段,其通信过程如下图所示:
准备阶段:Snowflake客户端对一组特定的STUN域发起DNS请求,在获得DNS响应后,等待一段时间,然后再对特定的域名前置服务器发送请求,最后根据域名前置服务的IP地址进行后续的会合阶段; 会合阶段:在此阶段,Snowflake客户端(Client)和代理(Proxy)通过中间人(broker)来交换WebRTC连接所需要的信息; WebRTC连接建立阶段:信令交换、连接建立、安全加密和点对点通信。
3.2 基于UDP的加密传输协议DTLS
针对UDP协议不需要通信双方认证、不能保证消息可靠传输的问题,DTLS为UDP提供了一种端到端的安全数据传输通道,利用PSK(Pre-Shared Key,预共享密钥)和ECC实现握手过程中的加密,通过cookie认证机制和证书实现通信双方的身份认证,通过添加序列号、缓存乱序到达的消息段、重发机制实现可靠传输。DTLS连接建立过程可以分为两个阶段:初始握手阶段和数据传输阶段。
DTLS初始握手阶段 与TLS类似,客户端和服务器实现DTLS握手,传输多种类型的握手消息。它允许用户验证自己的身份,并协商连接中使用的密钥、密码和其他加密参数。在这些握手消息中,Client Hello消息和Server Hello消息中包含了大量的指纹信息。由于DTLS握手信息没有加密,因此这些指纹中存在一些可以显著识别不同应用程序的特征。因此,本文提出了一种基于DTLS握手阶段指纹信息的雪花流量识别方法 DTLS数据传输阶段 虽然在此过程中通信内容都是加密的,但传输信息的载荷长度、方向和时间间隔等特征仍可以揭示连接建立过程,根据这些特征的信息,本文提出的在Tor-Snowflake场景中识别HS流量的方法。
4、Tor-Snowflake流量识别框架体系结构
本文提出了一个框架,用于标识Snowflake流量和基于Snowflake的Tor HS访问活动。该框架分为三部分:Snowflake流量识别框架的概括及预识别方法、基于DTLS握手信息的Snowflake流量识别方法和基于DTLS数据传输消息累积载荷特征提取的Snowflake场景下的HS访问活动识别方法。
4.1 Snowflake流量识别框架及预识别方法
本节为Tor-Snowflake提出了一个流量识别框架,其过程如下:首先,通过自动化脚本控制客户机,并将客户机生成的流量捕获到pcap文件中;然后,采用基于规则的匹配方法对雪花访问行为进行预识别;根据雪花通信前DNS查询的特殊行为模式对pecp文件进行分析。在此基础上,对可疑UDP流进行过滤,提取DTLS协议的握手指纹特征。将这些特征组合并输入到ML模型中,训练分类器,得到雪花的识别结果;此外,本文提取了相关的统计特征,并使用提出的ACCUMUL方法对Snowflake的DTLS流进行处理;最后,使用提取的特征来训练基于机器学习算法的雪花流量分类模型,以识别Tor-Snowflake场景中的HS访问活动。Tor-Snowflake流量识别框架F-ACCUMUL如下图所示:
Tor-Snowflake流量预识别由两个主要规则组成:
第一条规则,提取数据包中单个用户在短时间内向STUN服务器发起的DNS查询,如果这些DNS查询指向多个STUN服务器,并且这些STUN服务器在torrc的Snowflake硬编码列表中,则说明用户很可能正在使用Snowflake尝试访问Tor,此时转而执行第二条预识别规则。 第二条规则建立在第一条的基础上,在客户端得到上述STUN服务器的DNS响应后,继续向torrc中硬编码的domain-fronting服务器地址发起DNS查询。
4.2 基于DTLS握手指纹的Snowflake识别
雪花数据传输依靠WebRTC技术建立通信隧道,使用DTLS实现安全可靠的加密数据传输。本文提出了一种基于DTLS握手指纹信息的雪花流量识别方法,将提取的指纹信息作为特征,应用机器学习方法构建雪花分类识别模型。
基于框架第一步用户预识别的结果,本文对过滤后的可疑流量进行解析,根据五元组信息合并UDP流,并从中提取DTLS消息协议。根据DTLS握手协议层格式规范,对DTLS握手消息进行解析,并分别从握手信息Client Hello和Server Hello中提取指纹信息。提取的DTLS握手指纹信息如下表所示:
本文对采集到的指纹特征进行独热编码,使用机器学习中的随机森林算法(Random Forest algorithm,RF),因为随机森林算法比较容易比较不同特征对分类结果的影响程度,因此选择它来构建一个多分类模型,实现基于DTLS指纹信息特征的Snowflake流量识别和特征重要度排序。
4.3 基于DTLS数据报文的Tor-Snowflake HS接入识别
本文提出了一种基于DTLS数据传输阶段消息累计总有效载荷采样的方法,从累计消息有效载荷长度中提取固定数量的m个附加特征,并结合常见的流量分类特征(如通信数据包的统计特征、数据包间隔时间的统计特征、输入输出消息数量比和大小比)来识别Tor-Snowflake HS访问活动。由于连接建立过程仅存在于Snowflake流量的DTLS数据传输阶段开始时,因此提取此阶段的前n条消息并执行本文提出的特征选择方法。
当Snowflake与对等点完成通信隧道的建立后,将客户端产生的Tor通信数据消息封装在WebRTC的数据通道中进行传输。由于Tor HS活动与一般访问活动在连接建立上存在差异,本文对雪花PT DTLS数据传输阶段的消息进行了分析,提出了一种基于DTLS数据传输阶段消息累积总有效载荷采样的方法:从累计消息有效载荷长度中提取固定数量的m个附加特征,并结合常见的流量分类特征(如通信数据包的统计特征、数据包间隔时间的统计特征、输入输出消息数量比和大小比)来识别Tor-Snowflake HS访问活动。由于连接建立过程仅存在于Snowflake流量的DTLS数据传输阶段开始时,因此提取此阶段的前n条消息并执行本文提出的特征选择方法。
基于标识的Snowflake数据流,解析DTLS数据传输消息以提取消息的加密有效负载长度。所构成的长度序列。表示消息的有效载荷长度,的正负值表示消息的传输方向,当时为输出消息,时为输入消息。数据传输阶段的累计消息负载可以表示为,其中表示消息位置索引,,当时,我们得到m个等间隔采样点在A序列的分段线性插值函数中进行采样。通过该方法,可以从不同长度的雪花流中提取固定数量的可识别特征。每个采样点包含了之前所有报文长度序列的累积特征,隐含了连接构建过程中报文长度和传输方向的信息。此外,采样点序列的位置也能在一定程度上反映出信息传输阶段不同连接构造过程的差异。在本文中,这种基于DTLS数据传输阶段累积消息有效载荷长度的线性插值采样的特征提取方法称为ACCUMUL。
5、评估
文中针对Snowflake流量指纹识别以及提取消息数n和采样点频率m的最优组合进行了实验,并通过定量的评估方法分析了Snowflake流量识别和Tor-Snowflake场景下隐藏服务(HS)识别的有效性。以准确率、召回率、F1得分以及流量识别耗时作为评估标准。
5.1 实验设置
实验主机:Ubuntu 22.04和Tor 0.4.6.10。
流量收集工具:python scapy库。
捕获的流量:每次访问的完整Tor或Tor HS连接建立过程流量。
5.2 指纹模型识别效果及特征重要性对比
基于采集并合成的WebRTC DTLS握手指纹数据集,本文对基于snowflake的Tor流量识别进行了相应的实验。本文对提取握手指纹特征识别雪花流量的不同机器学习算法进行了对比实验,发现该方法提取的指纹特征对于Random Forest、XGBoost、AdaBoost、LinearSVM和KNN五种机器学习算法表现良好,且结果相似。流量识别效果如下图所示:
实验结果表明,该指纹识别方法对Tor-Snowflake流量识别效果显著,不同算法的平均识别准确率达到99.8%以上。该方法可适用于多种机器学习模型,识别仅需处理少量DTLS握手报文。且该方法提取指纹特征和训练分类模型所花费的时间较少,对Tor-Snowflake流量识别具有较好的实时性。
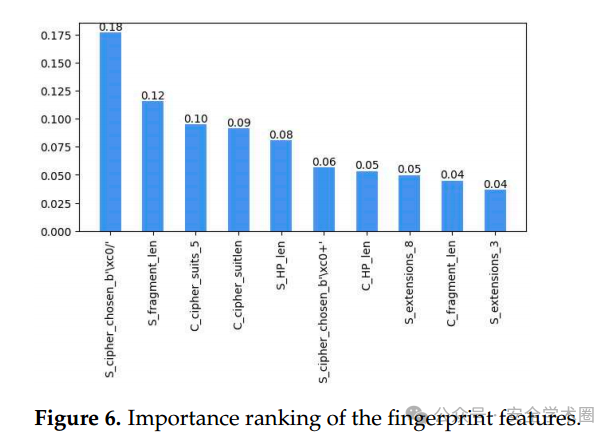
根据随机森林(RF)算法,指纹特征的重要性排序如下图所示:
其中,Server Hello的片段长度、密码套件以及Client Hello中的密码套件长度对Snowflake流量识别模型也有很大的影响,这四个特征加起来可以达到50%左右的重要性。从实验结果来看,服务器端的片段长度会随着应用程序的不同而变化,Client Hello消息的密码套件内容和长度往往因客户端应用程序的不同而不同。这些指纹特征可以有效指导Tor-Snowflake流量的识别。
5.3 参数的最优组合
本文提出的雪花场景Tor HS识别方法的关键在于选择数据传输阶段的前n条消息以及选择的累计有效载荷长度采样频率为m的消息数。选择合适的消息数n可以提高整个框架的识别效率,并保持良好的识别精度。另外,对于m值的选取,随着m的增大,采样点之间的间隔距离变小,采样造成的损失也会变小。另一方面,大量的特征会对计算时间消耗产生负面影响,这会降低学习效率,增加过拟合的风险。为了获得最佳的参数组合,本文使用随机森林算法构建模型进行测试,实验结果下表所示:
根据最优参数组合的要求,即准确率越高、n和m的个数越小、训练耗时越少、达到模型识别效果和特征提取耗时之间的平衡。从实验结果看,对于(n,m),最优的参数组合为(300,40)。
5.4 不同机器方法在Tor-Snowflake HS识别中的比较
本文使用相同的五种机器学习算法来训练模型,并使用十倍交叉验证方法检查有效性。选择DTLS数据传输的前300个消息,并通过采样40个样本点来构建数据集,以获得累积的消息有效负载长度。实验结果以混淆矩阵的形式构建,并计算准确率、准确率、召回率和f1分数,不同模型的识别性能如下表所示:
从表中可以看出,在使用RF和KNN建立模型时,本文提出的方法ACCUMUL在Tor-Snowflake场景下的HS流量识别准确率均达到99%以上,即通过ACCUMUL方法提取特征构建的模型可以有效识别网络中的Tor-Snowflake HS访问活动。其中,RF算法在大部分评价指标上都表现出更好的效果。KNN算法与RF的结果接近,但其模型训练时间消耗较少。XGBoost和AdaBoost算法也有不错的表现,但线性分类器SVM的表现相对较差。综上所述,非线性分类器在识别Tor-Snowflake HS访问活动方面有很好的表现,选择KNN进行HS流量识别框架的模型训练是更为合适的。
6、总结
本文的主要贡献有以下三点:
提出了一种规则匹配技术来快速预识别Snowflake流量。在此基础上,提出了一种基于DTLS握手指纹的Snowflake流量准确识别方法。 提出了一种基于累积长度和统计特征的隐藏服务(HS)识别方法。 实验结果表明,提出的方法可以在很少的时间消耗下准确识别Snowflake流量,并有效地识别Tor-Snowflake隐藏服务流量。
局限性:
提出的基于Snowflake握手指纹的识别方法可能会被PT开发人员通过消除或变形Snowflake DTLS握手阶段的指纹信息来抵抗。 提出的框架使用机器学习算法,不涉及深度学习算法。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh