2024-10-30 03:2:47 Author: securityboulevard.com(查看原文) 阅读量:4 收藏
Handling large volumes of sensitive data in testing environments is challenging. You need to protect customer information, financial records, and other confidential data without compromising security or violating regulations. At the same time, you have to keep data relationships intact and make sure testing accurately reflects real-world scenarios. The risks multiply when data moves between systems, making it harder to maintain security, data integrity, and compliance. Without test data management best practices, it’s easy to lose control—data relationships can break, sensitive information might be exposed, and compliance becomes a constant worry.
Managing test data in on-prem environments is even more challenging. Moving data between systems in these setups demands strict security and compliance measures that fit your organization’s infrastructure. Sensitive data needs protection, but testing accuracy can’t be sacrificed. In this article, we cover essential test data management best practices to help you handle large volumes of sensitive data in non-production environments—keeping your test data secure, compliant, and realistic for effective testing
1. Challenge: Limited Capabilities of In-built Data Masking
Many organizations rely on native database tools like SQL Server’s dynamic masking or Oracle’s built-in masking solutions. While these tools provide basic masking capabilities, they often apply masking dynamically—masking the data only when queried, without permanently altering the underlying data. This is problematic in non-production environments where test data needs to be consistently masked.
Additionally, native tools are limited to individual databases. In a multi-database environment, such as a healthcare system managing patient records across multiple platforms (SQL Server for billing, Oracle for medical histories), native tools fail to maintain consistent data protection across systems. Dynamic masking also doesn’t support complex test scenarios where data must be manipulated consistently across environments.
Test Data Management Best Practice: Use Advanced Static Masking Tools
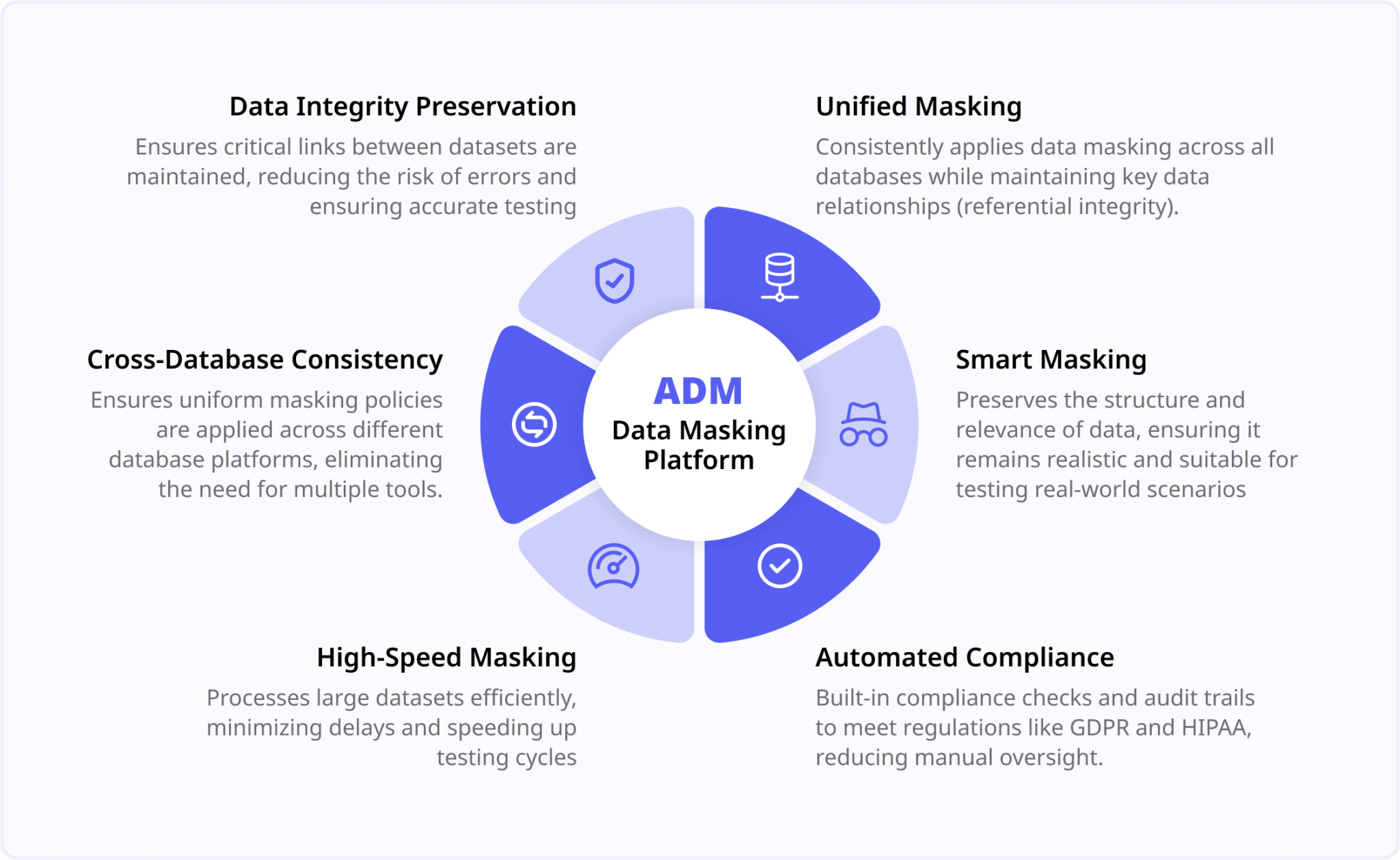
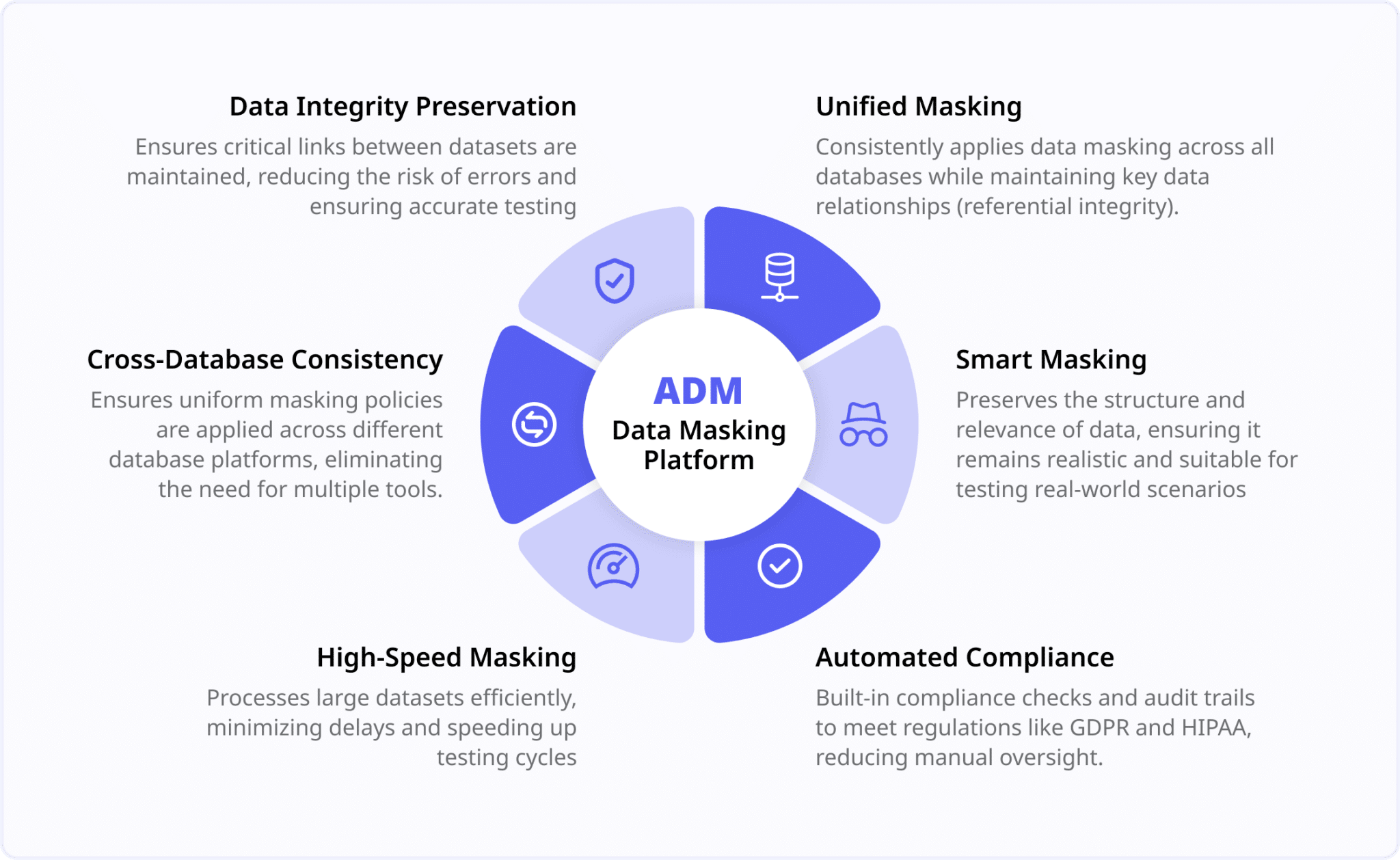
Using advanced static data masking tools ensures that sensitive data is permanently transformed, maintaining consistency across databases without the need for manual intervention. This approach reduces the risk of exposure, supports multi-database environments, and preserves data relationships. The advantage is that masking is applied across the board, ensuring compliance with regulations like HIPAA or GDPR and facilitating more seamless test environments.


2. Challenge: Inconsistent Data Quality in Test Environments
In multi-database environments, test data quality often suffers when using traditional methods like data scrambling or encryption. Scrambling sensitive data by replacing it with random characters or encrypting fields renders it unusable for testing, as testers can no longer recognize the structure, patterns, or logic of the original data.
For example, in an e-commerce environment, scrambling customer addresses and transaction histories for testing purposes may create test data that no longer follows realistic patterns (such as formatting, logic for city names, or ZIP code structures). This leads to incomplete testing and missed bugs because the test data no longer mirrors real-world scenarios.
Test Data Management Best Practice: Smart Masking to Ensure Realistic Test Data
Smart masking ensures that while sensitive data is anonymized, it retains the logical patterns and structures of the original production data. For example, customer names can be replaced with fictitious names that maintain the same format, while preserving valid ZIP codes and phone number formats. This approach allows testers to work with realistic data, significantly improving testing accuracy and the ability to detect issues that could otherwise be missed. Smart masking creates test environments that reflect actual production conditions, leading to more reliable software before it goes live.
3. Challenge: Broken Data Relationships Disrupt Development Cycles
When data relationships break across systems—such as customer records not matching up with transaction histories—developers are left with test environments that no longer reflect real-world scenarios. This leads to test failures, missed bugs, and unreliable results.
For development teams, broken referential integrity means wasting time troubleshooting data issues instead of focusing on feature testing or performance improvements. Inconsistent data across databases makes it hard to recreate production-like conditions, slowing down development cycles and increasing the risk of errors when deploying to production.
Test Data Management Best Practice: Unified Masking to Preserve Referential Integrity
Using unified masking ensures that sensitive data is consistently masked across all systems, while maintaining the relationships between datasets. By preserving referential integrity, developers can work in environments that mirror production, reducing manual fixes and enabling a more efficient development process.
4. Challenge: Ensuring Compliance in Test Environments
Many organizations struggle to ensure that their non-production environments are compliant with regulations like GDPR, HIPAA, or PCI-DSS. Using sensitive data in test environments without proper masking or anonymization can lead to severe penalties, even if the data exposure occurs outside of production.
For example, a global financial services company that stores customer data across multiple regions must ensure that all test data complies with GDPR. If sensitive data like customer names or financial information is exposed during testing, the company faces fines and penalties, regardless of whether the breach happens in production or test environments.
Test Data Management Best Practice: Automate Compliance and Auditing in Non-Production Environments
To mitigate compliance risks, automate compliance checks and audit trails within your non-production environments. Implementing automated tools ensures that sensitive data is properly masked at all times, and that audit logs are maintained to demonstrate compliance with regulations. This approach not only reduces the risk of non-compliance but also streamlines auditing processes, ensuring that your organization is always prepared for regulatory scrutiny.
5. Challenge: Manual Masking Scripts Require Constant Maintenance
Many organizations rely on manual masking scripts to protect sensitive data across multiple databases- often scattered across departments or systems. These scripts often need constant updates and maintenance to keep up with evolving systems and regulatory requirements. When working with multiple databases (e.g., SQL Server, Oracle, PostgreSQL), the need for separate scripts for each platform increases complexity and the risk of errors, leading to potential data exposure or compliance issues.
Test Data Management Best Practice: Use a Database-Agnostic Masking Tool
To eliminate the need for multiple manual scripts, implement a database-agnostic masking tool that works across all databases. This solution automates the masking process, ensuring consistency across platforms without the need for platform-specific scripts. By reducing manual intervention, a database-agnostic tool minimizes maintenance overhead and helps keep sensitive data secure while ensuring compliance with regulations like GDPR and HIPAA.
6. Challenge: Masking Operations Take Too Long
Organizations managing large datasets often find that running data masking operations can take hours or even days. This is particularly true when using methods like encryption, which introduces additional processing overhead. The high processing load delays testing, impacts system performance, and forces teams to schedule masking jobs infrequently—sometimes only once a month.
For instance, a large enterprise managing terabytes of customer data might only run masking jobs monthly due to the time required. This results in outdated test data that doesn’t reflect recent production changes, creating a disconnect between testing and real-world conditions.
Test Data Management Best Practice: Use High-Speed Masking and Run Masking During Low-Load Times
By using high-speed masking tools that can process large datasets efficiently, you can reduce the time it takes to mask sensitive data from days to hours. Scheduling these operations during off-peak hours ensures that system performance is unaffected while keeping test environments up to date with fresh, masked data. This approach allows your team to work with accurate, current data in test environments, improving both the quality of testing and the speed at which it can be completed.
Implement Test Data Management Best Practices – with ADM Platform
Applying these best practices manually or with disjointed tools can lead to inefficiencies and errors. To streamline your test data management, ADM provides a an automated platform for sensitive data discovery and masking to rapidly generate compliant test data.
ADM Data Masking Platform
Conclusion: Streamlining Test Data Management for Complex Data Environments
Implementing test data management best practices in multi-database environments ensures data security, accuracy, and compliance. By using tools that offer unified masking, preserve data integrity, and automate compliance, you eliminate manual effort and avoid issues like broken data relationships or slow test cycles. ADM simplifies this process, helping you keep test environments secure, compliant, and realistic, so your development team can work more efficiently with accurate data.
Implement best practices with ADM
Discover how ADM test data management platform generates realistic, secure and compliant test data
The post Test Data Management Best Practices: Handling Sensitive Data Across Multiple Databases first appeared on Accutive Security.
*** This is a Security Bloggers Network syndicated blog from Articles - Accutive Security authored by Paul Horn. Read the original post at: https://accutivesecurity.com/test-data-management-best-practices-handling-sensitive-data-across-multiple-databases/
如有侵权请联系:admin#unsafe.sh