STAMINA:把恶意软件转换成图像的深度神经网络
星期二, 五月 12, 2020
近日,微软和英特尔合作开发了一个全新的检测和分类恶意软件的人工智能研究项目——STAMINA。
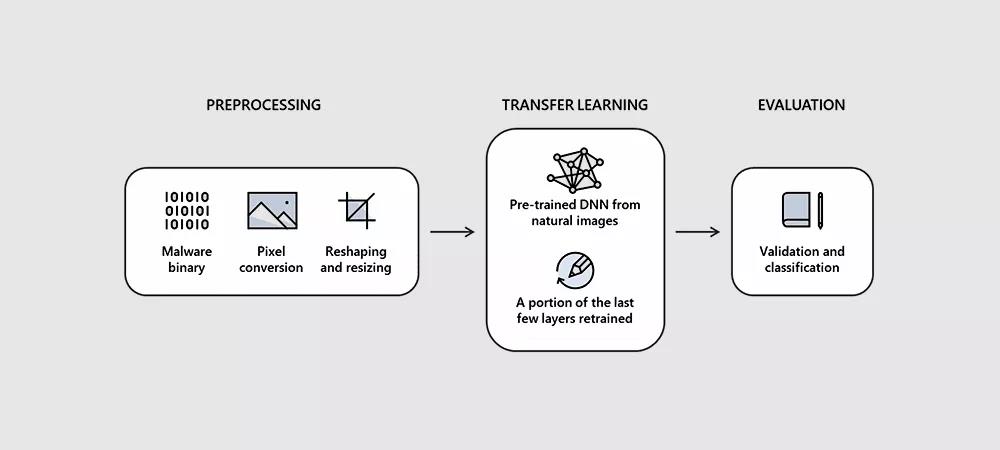
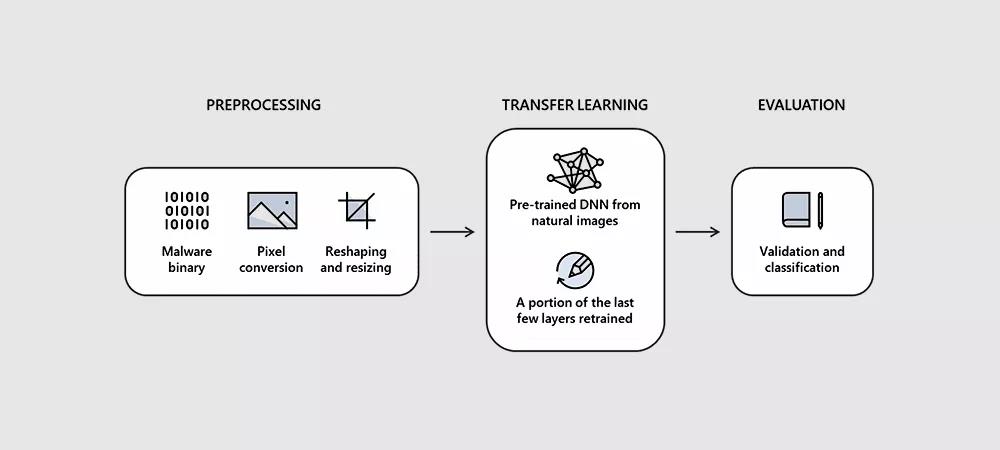
STAMINA(STAtic Malware-as-Image Network Analysis)能够将恶意软件样本转换为灰度图像,然后扫描识别获取特定恶意软件样本的纹理和结构模式。
英特尔和微软研究团队表示,整个过程遵循几个简单步骤。第一个步骤包括获取输入文件并将其二进制代码转换为原始像素数据流。
然后,研究人员将这些一维的像素流转换为二维照片,以便使用常规图像分析算法对其进行分析。
通过下面这张换算表根据文件大小来确定图像宽度、图像高度是动态的,通过将原始像素流除以所选宽度值得到。
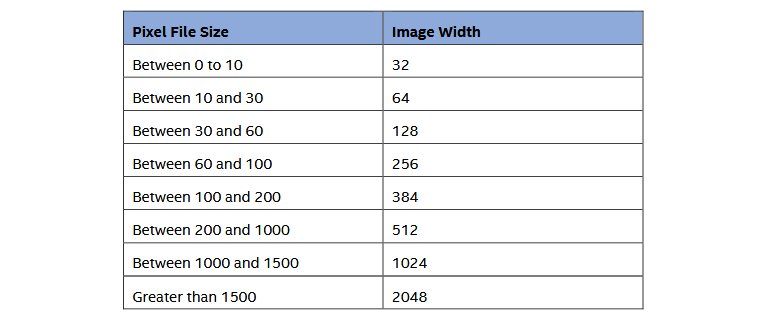
图片来源:英特尔,微软
在将原始像素流组合成二维图像后,研究人员随后将生成的照片调整为较小的尺寸。
英特尔和微软团队表示,调整原始图像的大小不会“对分类结果产生负面影响”,这是必要的步骤,因为计算资源没有必要处理包含数十亿像素的原始图像,调整图像大小可以大大加快处理速度。
然后,将驻留的图像输入经过训练的深度神经网络(DNN),该网络会扫描图像(恶意软件株的二维表示)并将其分类为“干净”或“已感染”。
微软表示,它提供了220万个受感染PE(便携式可执行文件)文件哈希的样本,作为该研究的素材。
研究人员使用60%的已知恶意软件样本来训练原始DNN算法,使用20%的文件来验证DNN,其余20%用于实际测试过程。
研究团队表示,STAMINA在识别和分类恶意软件样本方面,STAMINA达到了99.07%的准确性,误报率为2.58%。
两位代表Microsoft威胁防护情报小组参加研究的Microsoft研究人员Jugal Parikh和Marc Marino说:
这个结果令人振奋,有助于推动业界将深度学习用于恶意软件分类。
该研究是Microsoft使用机器学习技术改进恶意软件检测工作的一部分。
STAMINA使用了深度学习技术,而深度学习是机器学习(ML)的子集,机器学习(ML)是人工智能(AI)的一个分支,是指能够从以非结构化或未标记格式存储的输入数据中自行学习的智能计算机网络。在STAMINA的用例中,数据是随机的恶意软件二进制文件。
微软上周在一篇博客文章中表示,虽然STAMINA在处理较小文件时是准确快速的,但处理大文件仍有问题:
对于更大尺寸的应用程序,由于需要将数十亿像素转换为JPEG图像并调整大小,STAMINA的效率降低了。
但是,这很可能无关紧要,因为该项目处理的主要是小型文件,效果很好。
微软威胁防护安全研究主管Tanmay Ganacharya在本月初接受采访时表示,微软现在严重依赖机器学习来检测新兴威胁,STAMINA使用的机器学习模块有别于已经在客户或者微软服务器系统中部署的模块。
Ganacharya透露,微软正在使用客户端机器学习模型引擎、云端机器学习模型引擎、机器学习模块来捕获行为序列或捕获文件本身的内容。
根据目前公布的测试结果,STAMINA可能很快就会成为微软用来检测分析恶意软件的机器学习模块之一。
微软使用机器学习分析恶意软件有一个得天独厚的优势,那就是它拥有来自数亿Windows Defender客户端安全软件的庞大数据。
Ganacharya说:
任何人都可以开发模型,但是标记的数据,数据的数量和质量确实有助于正确地训练机器学习模型,从而决定了模型的有效性。
而且,这是微软的优势,因为我们确实拥有大量“传感器”,这些传感器通过电子邮件、身份、端点以及各种应用组合在一起,将大量有趣的情报输送给我们。
白皮书地址:
https://www.intel.com/content/www/us/en/artificial-intelligence/documents/stamina-deep-learning-for-malware-protection-whitepaper.html
相关阅读
如有侵权请联系:admin#unsafe.sh