2024-10-22
16 min read

Vectorize is a globally distributed vector database that enables you to build full-stack, AI-powered applications with Cloudflare Workers. Vectorize makes querying embeddings — representations of values or objects like text, images, audio that are designed to be consumed by machine learning models and semantic search algorithms — faster, easier and more affordable.
In this post, we dive deep into how we built Vectorize on Cloudflare’s Developer Platform, leveraging Cloudflare’s global network, Cache, Workers, R2, Queues, Durable Objects, and container platform.
What is a vector database?
A vector database is a queryable store of vectors. A vector is a large array of numbers called vector dimensions.
A vector database has a similarity search query: given an input vector, it returns the vectors that are closest according to a specified metric, potentially filtered on their metadata.
Vector databases are used to power semantic search, document classification, and recommendation and anomaly detection, as well as contextualizing answers generated by LLMs (Retrieval Augmented Generation, RAG).
Why do vectors require special database support?
Conventional data structures like B-trees, or binary search trees expect the data they index to be cheap to compare and to follow a one-dimensional linear ordering. They leverage this property of the data to organize it in a way that makes search efficient. Strings, numbers, and booleans are examples of data featuring this property.
Because vectors are high-dimensional, ordering them in a one-dimensional linear fashion is ineffective for similarity search, as the resulting ordering doesn’t capture the proximity of vectors in the high-dimensional space. This phenomenon is often referred to as the curse of dimensionality.
In addition to this, comparing two vectors using distance metrics useful for similarity search is a computationally expensive operation, requiring vector-specific techniques for databases to overcome.
Query processing architecture
Vectorize builds upon Cloudflare’s global network to bring fast vector search close to its users, and relies on many components to do so.
These are the Vectorize components involved in processing vector queries.

Vectorize runs in every Cloudflare data center, on the infrastructure powering Cloudflare Workers. It serves traffic coming from Worker bindings as well as from the Cloudflare REST API through our API Gateway.
Each query is processed on a server in the data center in which it enters, picked in a fashion that spreads the load across all servers of that data center.
The Vectorize DB Service (a Rust binary) running on that server processes the query by reading the data for that index on R2, Cloudflare’s object storage. It does so by reading through Cloudflare’s Cache to speed up I/O operations.
Searching vectors, and indexing them to speed things up
Being a vector database, Vectorize features a similarity search query: given an input vector, it returns the K vectors that are closest according to a specified metric.
Conceptually, this similarity search consists of 3 steps:
Evaluate the proximity of the query vector with every vector present in the index.
Sort the vectors based on their proximity “score”.
Return the top matches.
While this method is accurate and effective, it is computationally expensive and does not scale well to indexes containing millions of vectors (see Why do vectors require special database support? above).
To do better, we need to prune the search space, that is, avoid scanning the entire index for every query.
For this to work, we need to find a way to discard vectors we know are irrelevant for a query, while focusing our efforts on those that might be relevant.
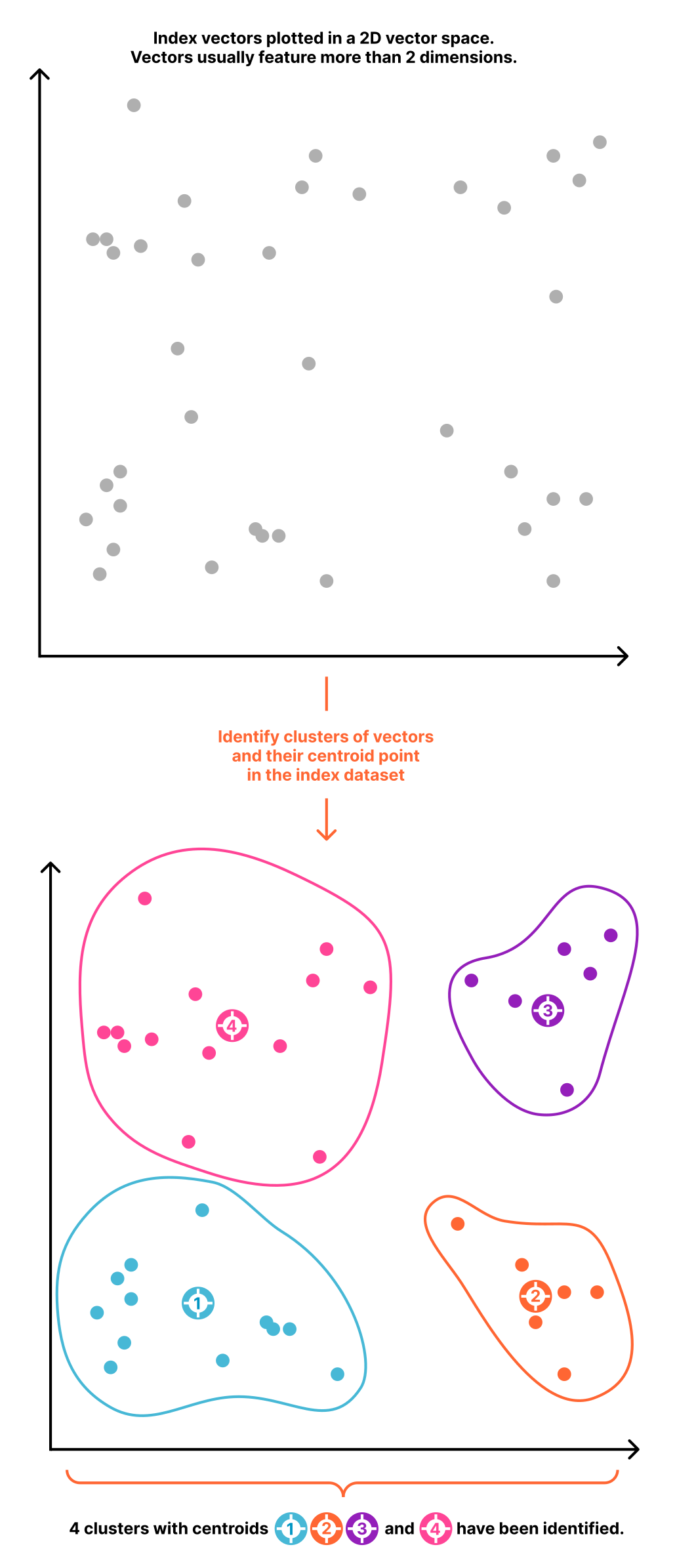
Indexing vectors with IVF
Vectorize prunes the search space for a query using an indexing technique called IVF, Inverted File Index.
IVF clusters the index vectors according to their relative proximity. For each cluster, it then identifies its centroid, the center of gravity of that cluster, a high-dimensional point minimizing the distance with every vector in the cluster.

Once the list of centroids is determined, each centroid is given a number. We then structure the data on storage by placing each vector in a file named like the centroid it is closest to.
When processing a query, we then can then focus on relevant vectors by looking only in the centroid files closest to that query vector, effectively pruning the search space.

Compressing vectors with PQ
Vectorize supports vectors of up to 1536 dimensions. At 4 bytes per dimension (32 bits float), this means up to 6 KB per vector. That’s 6 GB of uncompressed vector data per million vectors that we need to fetch from storage and put in memory.
To process multi-million vector indexes while limiting the CPU, memory, and I/O required to do so, Vectorize uses a dimensionality reduction technique called PQ (Product Quantization). PQ compresses the vectors data in a way that retains most of their specificity while greatly reducing their size — a bit like down sampling a picture to reduce the file size, while still being able to tell precisely what’s in the picture — enabling Vectorize to efficiently perform similarity search on these lighter vectors.
In addition to storing the compressed vectors, their original data is retained on storage as well, and can be requested through the API; the compressed vector data is used only to speed up the search.
Approximate nearest neighbor search and result accuracy refining
By pruning the search space and compressing the vector data, we’ve managed to increase the efficiency of our query operation, but it is now possible to produce a set of matches that is different from the set of true closest matches. We have traded result accuracy for speed by performing an approximate nearest neighbor search, reaching an accuracy of ~80%.
To boost the result accuracy up to over 95%, Vectorize then performs a result refinement pass on the top approximate matches using uncompressed vector data, and returns the best refined matches.
Eventual consistency and snapshot versioning
Whenever you query your Vectorize index, you are guaranteed to receive results which are read from a consistent, immutable snapshot — even as you write to your index concurrently. Writes are applied in strict order of their arrival in our system, and they are funneled into an asynchronous process. We update the index files by reading the old version, making changes, and writing this updated version as a new object in R2. Each index file has its own version number, and can be updated independently of the others. Between two versions of the index we may update hundreds or even thousands of IVF and metadata index files, but even as we update the files, your queries will consistently use the current version until it is time to switch.
Each IVF and metadata index file has its own version. The list of all versioned files which make up the snapshotted version of the index is contained within a manifest file. Each version of the index has its own manifest. When we write a new manifest file based on the previous version, we only need to update references to the index files which were modified; if there are files which weren't modified, we simply keep the references to the previous version.
We use a root manifest as the authority of the current version of the index. This is the pivot point for changes. The root manifest is a copy of a manifest file from a particular version, which is written to a deterministic location (the root of the R2 bucket for the index). When our async write process has finished processing vectors, and has written all new index files to R2, we commit by overwriting the current root manifest with a copy of the new manifest. PUT operations in R2 are atomic, so this effectively makes our updates atomic. Once the manifest is updated, Vectorize DB Service instances running on our network will pick it up, and use it to serve reads.
Because we keep past versions of index and manifest files, we effectively maintain versioned snapshots of your index. This means we have a straightforward path towards building a point-in-time recovery feature (similar to D1's Time Travel feature).
You may have noticed that because our write process is asynchronous, this means Vectorize is eventually consistent — that is, there is a delay between the successful completion of a request writing on the index, and finally seeing those updates reflected in queries. This isn't always ideal for all data storage use cases. For example, imagine two users using an online ticket reservation application for airline tickets, where both users buy the same seat — one user will successfully reserve the ticket, and the other will eventually get an error saying the seat was taken, and they need to choose again. Because a vector index is not typically used as a primary database for these transactional use cases, we decided eventual consistency was a worthy trade off in order to ensure Vectorize queries would be fast, high-throughput, and cheap even as the size of indexes grew into the millions.
Coordinating distributed writes: it's just another block in the WAL
In the section above, we touched on our eventually consistent, asynchronous write process. Now we'll dive deeper into our implementation.
The WAL
A write ahead log (WAL) is a common technique for making atomic and durable writes in a database system. Vectorize’s WAL is implemented with SQLite in Durable Objects.
In Vectorize, the payload for each update is given an ID, written to R2, and the ID for that payload is handed to the WAL Durable Object which persists it as a "block." Because it's just a pointer to the data, the blocks are lightweight records of each mutation.
Durable Objects (DO) have many benefits — strong transactional guarantees, a novel combination of compute and storage, and a high degree of horizontal scale — but individual DOs are small allotments of memory and compute. However, the process of updating the index for even a single mutation is resource intensive — a single write may include thousands of vectors, which may mean reading and writing thousands of data files stored in R2, and storing a lot of data in memory. This is more than what a single DO can handle.
So we designed the WAL to leverage DO's strengths and made it a coordinator. It controls the steps of updating the index by delegating the heavy lifting to beefier instances of compute resources (which we call "Executors"), but uses its transactional properties to ensure the steps are done with strong consistency. It safeguards the process from rogue or stalled executors, and ensures the WAL processing continues to move forward. DOs are easy to scale, so we create a new DO instance for each Vectorize index.

WAL Executor
The executors run from a single pool of compute resources, shared by all WALs. We use a simple producer-consumer pattern using Cloudflare Queues. The WAL enqueues a request, and executors poll the queue. When they get a request, they call an API on the WAL requesting to be assigned to the request.
The WAL ensures that one and only one executor is ever assigned to that write. As the executor writes, the index files and the updated manifest are written in R2, but they are not yet visible. The final step is for the executor to call another API on the WAL to commit the change — and this is key — it passes along the updated manifest. The WAL is responsible for overwriting the root manifest with the updated manifest. The root manifest is the pivot point for atomic updates: once written, the change is made visible to Vectorize’s database service, and the updated data will appear in queries.
From the start, we designed this process to account for non-deterministic errors. We focused on enumerating failure modes first, and only moving forward with possible design options after asserting they handled the possibilities for failure. For example, if an executor stalls, the WAL finds a new executor. If the first executor comes back, the coordinator will reject its attempt to commit the update. Even if that first executor is working on an old version which has already been written, and writes new index files and a new manifest to R2, they will not overwrite the files written from the committed version.
Batching updates
Now that we have discussed the general flow, we can circle back to one of our favorite features of the WAL. On the executor, the most time-intensive part of the write process is reading and writing many files from R2. Even with making our reads and writes concurrent to maximize throughput, the cost of updating even thousands of vectors within a single file is dwarfed by the total latency of the network I/O. Therefore it is more efficient to maximize the number of vectors processed in a single execution.
So that is what we do: we batch discrete updates. When the WAL is ready to request work from an executor, it will get a chunk of "blocks" off the WAL, starting with the next un-written block, and maintaining the sequence of blocks. It will write a new "batch" record into the SQLite table, which ties together that sequence of blocks, the version of the index, and the ID of the executor assigned to the batch.
Users can batch multiple vectors to update in a single insert or upsert call. Because the size of each update can vary, the WAL adaptively calculates the optimal size of its batch to increase throughput. The WAL will fit as many upserted vectors as possible into a single batch by counting the number of updates represented by each block. It will batch up to 200,000 vectors at once (a value we arrived at after our own testing) with a limit of 1,000 blocks. With this throughput, we have been able to quickly load millions of vectors into an index (with upserts of 5,000 vectors at a time). Also, the WAL does not pause itself to collect more writes to batch — instead, it begins processing a write as soon as it arrives. Because the WAL only processes one batch at a time, this creates a natural pause in its workflow to batch up writes which arrive in the meantime.
Retraining the index
The WAL also coordinates our process for retraining the index. We occasionally re-train indexes to ensure the mapping of IVF centroids best reflects the current vectors in the index. This maintains the high accuracy of the vector search.
Retraining produces a completely new index. All index files are updated; vectors have been reshuffled across the index space. For this reason, all indexes have a second version stamp — which we call the generation — so that we can differentiate between retrained indexes.
The WAL tracks the state of the index, and controls when the training is started. We have a second pool of processes called "trainers." The WAL enqueues a request on a queue, then a trainer picks up the request and it begins training.
Training can take a few minutes to complete, but we do not pause writes on the current generation. The WAL will continue to handle writes as normal. But the training runs from a fixed snapshot of the index, and will become out-of-date as the live index gets updated in parallel. Once the trainer has completed, it signals the WAL, which will then start a multi-step process to switch to the new generation. It enters a mode where it will continue to record writes in the WAL, but will stop making those writes visible on the current index. Then it will begin catching up the retrained index with all of the updates that came in since it started. Once it has caught up to all data present in the index when the trainer signaled the WAL, it will switch over to the newly retrained index. This prevents the new index from appearing to "jump back in time." All subsequent writes will be applied to that new index.
This is all modeled seamlessly with the batch record. Because it associates the index version with a range of WAL blocks, multiple batches can span the same sequence of blocks as long as they belong to different generations. We can say this another way: a single WAL block can be associated with many batches, as long as these batches are in different generations. Conceptually, the batches act as a second WAL layered over the WAL blocks.
Vectorize supports metadata filters on vector similarity queries. This allows a query to focus the vector similarity search on a subset of the index data, yielding matches that would otherwise not have been part of the top results.
For instance, this enables us to query for the best matching vectors for color: “blue” and category: ”robe”.
Conceptually, what needs to happen to process this example query is:
Identify the set of vectors matching
color: “blue”by scanning all metadata.Identify the set of vectors matching
category: “robe”by scanning all metadata.Intersect both sets (boolean AND in the filter) to identify vectors matching both the color and category filter.
Score all vectors in the intersected set, and return the top matches.
While this method works, it doesn’t scale well. For an index with millions of vectors, processing the query that way would be very resource intensive. What’s worse, it prevents us from using our IVF index to identify relevant vector data, forcing us to compute a proximity score on potentially millions of vectors if the filtered set of vectors is large.
To do better, we need to prune the metadata search space by indexing it like we did for the vector data, and find a way to efficiently join the vector sets produced by the metadata index with our IVF vector index.
Indexing metadata with Chunked Sorted List Indexes
Vectorize maintains one metadata index per filterable property. Each filterable metadata property is indexed using a Chunked Sorted List Index.
A Chunked Sorted List Index is a sorted list of all distinct values present in the data for a filterable property, with each value mapped to the set of vector IDs having that value. This enables Vectorize to binary search a value in the metadata index in O(log n) complexity, in other words about as fast as search can be on a large dataset.
Because it can become very large on big indexes, the sorted list is chunked in pieces matching a target weight in KB to keep index state fetches efficient.

A lightweight chunk descriptor list is maintained in the index manifest, keeping track of the list chunks and their lower/upper values. This chunk descriptor list can be binary searched to identify which chunk would contain the searched metadata value.
Once the candidate chunk is identified, Vectorize fetches that chunk from index data and binary searches it to take the set of vector IDs matching a metadata value if found, or an empty set if not found.

We identify the matching vector set this way for every predicate in the metadata filter of the query, then intersect the sets in memory to determine the final set of vectors matched by the filters.
This is just half of the query being processed. We now need to identify the vectors most similar to the query vector, within those matching the metadata filters.
Joining the metadata and vector indexes
A vector similarity query always comes with an input vector. We can rank all centroids of our IVF vector index based on their proximity with that query vector.
The vector set matched by the metadata filters contains for each vector its ID and IVF centroid number.
From this, Vectorize derives the number of vectors matching the query filters per IVF centroid, and determines which and how many top-ranked IVF centroids need to be scanned according to the number of matches the query asks for.
Vectorize then performs the IVF-indexed vector search (see the section Searching Vectors, and indexing them to speed things up above) by considering only the vectors in the filtered metadata vector set while doing so.
Because we’re effectively pruning the vector search space using metadata filters, filtered queries can often be faster than their unfiltered equivalent.
Query performance
The performance of a system is measured in terms of latency and throughput.
Latency is a measure relative to individual queries, evaluating the time it takes for a query to be processed, usually expressed in milliseconds. It is what an end user perceives as the “speed” of the service, so a lower latency is desirable.
Throughput is a measure relative to an index, evaluating the number of queries it can process concurrently over a period of time, usually expressed in requests per second or RPS. It is what enables an application to scale to thousands of simultaneous users, so a higher throughput is desirable.
Vectorize is designed for great index throughput and optimized for low query latency to deliver great performance for demanding applications. Check out our benchmarks.
Query latency optimization
As a distributed database keeping its data state on blob storage, Vectorize’s latency is primarily driven by the fetch of index data, and relies heavily on Cloudflare’s network of caches as well as individual server RAM cache to keep latency low.
Because Vectorize data is snapshot versioned, (see Eventual consistency and snapshot versioning above), each version of the index data is immutable and thus highly cacheable, increasing the latency benefits Vectorize gets from relying on Cloudflare’s cache infrastructure.
To keep the index data lean, Vectorize uses techniques to reduce its weight. In addition to Product Quantization (see Compressing vectors with PQ above), index files use a space-efficient binary format optimized for runtime performance that Vectorize is able to use without parsing, once fetched.
Index data is fragmented in a way that minimizes the amount of data required to process a query. Auxiliary indexes into that data are maintained to limit the amount of fragments to fetch, reducing overfetch by jumping straight to the relevant piece of data on mass storage.
Vectorize boosts all vector proximity computations by leveraging SIMD CPU instructions, and by organizing the vector search in 2 passes, effectively balancing the latency/result accuracy ratio (see Approximate nearest neighbor search and result accuracy refining above).
When used via a Worker binding, each query is processed close to the server serving the worker request, and thus close to the end user, minimizing the network-induced latency between the end user, the Worker application, and Vectorize.
Query throughput
Vectorize runs in every Cloudflare data center, on thousands of servers across the world.
Thanks to the snapshot versioning of every index’s data, every server is simultaneously able to serve the index concurrently, without contention on state.
This means that a Vectorize index elastically scales horizontally with its distributed traffic, providing very high throughput for the most demanding Worker applications.
Increased index size
We are excited that our upgraded version of Vectorize can support a maximum of 5 million vectors, which is a 25x improvement over the limit in beta (200,000 vectors). All the improvements we discussed in this blog post contribute to this increase in vector storage. Improved query performance and throughput comes with this increase in storage as well.
However, 5 million may be constraining for some use cases. We have already heard this feedback. The limit falls out of the constraints of building a brand new globally distributed stateful service, and our desire to iterate fast and make Vectorize generally available so builders can confidently leverage it in their production apps.
We believe builders will be able to leverage Vectorize as their primary vector store, either with a single index or by sharding across multiple indexes. But if this limit is too constraining for you, please let us know. Tell us your use case, and let's see if we can work together to make Vectorize work for you.
Try it now!
Every developer on a free plan can give Vectorize a try. You can visit our developer documentation to get started.
If you’re looking for inspiration on what to build, see the semantic search tutorial that combines Workers AI and Vectorize for document search, running entirely on Cloudflare. Or an example of how to combine OpenAI and Vectorize to give an LLM more context and dramatically improve the accuracy of its answers.
And if you have questions about how to use Vectorize for our product & engineering teams, or just want to bounce an idea off of other developers building on Workers AI, join the #vectorize and #workers-ai channels on our Developer Discord.
Cloudflare's connectivity cloud protects entire corporate networks, helps customers build Internet-scale applications efficiently, accelerates any website or Internet application, wards off DDoS attacks, keeps hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.