2024-10-10 03:0:17 Author: hackernoon.com(查看原文) 阅读量:7 收藏
Authors:
(1) Liang Wang, Microsoft Corporation, and Correspondence to ([email protected]);
(2) Nan Yang, Microsoft Corporation, and correspondence to ([email protected]);
(3) Xiaolong Huang, Microsoft Corporation;
(4) Linjun Yang, Microsoft Corporation;
(5) Rangan Majumder, Microsoft Corporation;
(6) Furu Wei, Microsoft Corporation and Correspondence to ([email protected]).
Table of Links
3 Method
4 Experiments
4.1 Statistics of the Synthetic Data
4.2 Model Fine-tuning and Evaluation
5 Analysis
5.1 Is Contrastive Pre-training Necessary?
5.2 Extending to Long Text Embeddings and 5.3 Analysis of Training Hyperparameters
B Test Set Contamination Analysis
C Prompts for Synthetic Data Generation
D Instructions for Training and Evaluation
5 Analysis
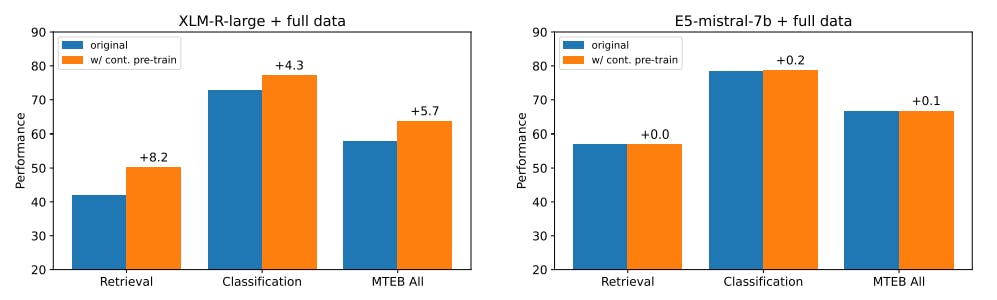
5.1 Is Contrastive Pre-training Necessary?

Weakly-supervised contrastive pre-training is one of the key factors behind the success of existing text embedding models. For instance, Contriever [18] treats random cropped spans as positive pairs for pre-training, while E5 [46] and BGE [48] collect and filter text pairs from various sources.

如有侵权请联系:admin#unsafe.sh